Java实现网络爬虫-Java入门
1. 网络爬虫
1.1 名称
- 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
- 另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
1.2 简述
- 网络爬虫是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
- 如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
- 所以要想抓取网络上的数据,不仅需要爬虫程序还需要一个可以接受”爬虫“发回的数据并进行处理过滤的服务器,爬虫抓取的数据量越大,对服务器的性能要求则越高。
2. 流程
- 网络爬虫是做什么的? 他的主要工作就是 跟据指定的url地址 去发送请求,获得响应, 然后解析响应 , 一方面从响应中查找出想要查找的数据,另一方面从响应中解析出新的URL路径,然后继续访问,继续解析;继续查找需要的数据和继续解析出新的URL路径 .
- 这就是网络爬虫主要干的工作. 下面是流程图:
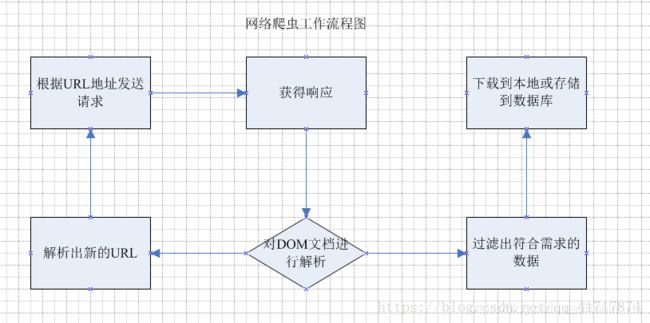
通过上面的流程图 能大概了解到 网络爬虫 干了哪些活 ,根据这些 也就能设计出一个简单的网络爬虫出来.
3. 实现思路
目标网站:
一个简单的爬虫 必需的功能:
- 发送请求和获取响应的功能 ;
- 解析响应的功能 ;
- 对 过滤出的数据 进行存储 的功能 ;
- 对解析出来的URL路径 处理的功能 ;
4. 实现代码
接下来直接上手代码
这里我使用的是一个简单的maven项目
依赖
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.11.3version>
dependency>
<dependency>
<groupId>commons-iogroupId>
<artifactId>commons-ioartifactId>
<version>2.5version>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
<version>4.5.5version>
dependency>
实现获取网页源码的方法
/**
* @param url 要抓取的网页地址
* @param encoding 要抓取网页编码
* @return
*/
public static String getHtmlResourceByUrl(String url, String encoding) {
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader reader = null;
StringBuffer buffer = new StringBuffer();
// 建立网络连接
try {
urlObj = new URL(url);
// 打开网络连接
uc = urlObj.openConnection();
// 建立文件输入流
isr = new InputStreamReader(uc.getInputStream(), encoding);
// 建立缓存导入 将网页源代码下载下来
reader = new BufferedReader(isr);
// 临时
String temp = null;
while ((temp = reader.readLine()) != null) {// 一次读一行 只要不为空就说明没读完继续读
// System.out.println(temp+"\n");
buffer.append(temp + "\n");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关流
if (isr != null) {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return buffer.toString();
}
保存页面的方法
public static void getJobInfo(String url, String encoding) {
// 拿到网页源代码
String html = getHtmlResourceByUrl(url, encoding);
try {
File fp = new File("D:/cskt/cskt.html");
OutputStream os = new FileOutputStream(fp); //建立文件输出流
os.write(html.getBytes());
os.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
得到网页中图片地址的方法
/**
* 得到网页中图片的地址
*
* @param htmlStr html字符串
* @return List
*/
private static List<String> getImgStr(String htmlStr) {
List<String> pics = new ArrayList<String>();
String img = "";
Pattern p_image;
Matcher m_image;
p_image = Pattern.compile(IMGURL_REG, Pattern.CASE_INSENSITIVE);
m_image = p_image.matcher(htmlStr);
while (m_image.find()) {
// 得到![]() 数据
img = m_image.group();
// 匹配
数据
img = m_image.group();
// 匹配![]() 中的src数据
Matcher m = Pattern.compile(IMGSRC_REG).matcher(img);
while (m.find()) {
String imgUrl = m.group(3);
if (!imgUrl.contains("http://") && !imgUrl.contains("https://")) {//没有这两个头
imgUrl = URL + imgUrl;
}
pics.add(imgUrl);
}
}
return pics;
}
中的src数据
Matcher m = Pattern.compile(IMGSRC_REG).matcher(img);
while (m.find()) {
String imgUrl = m.group(3);
if (!imgUrl.contains("http://") && !imgUrl.contains("https://")) {//没有这两个头
imgUrl = URL + imgUrl;
}
pics.add(imgUrl);
}
}
return pics;
}
下载图片的方法
/***
* 下载图片
*
* @param listImgSrc
*/
public static void Download(List<String> listImgSrc) {
int count = 0;
try {
for (int i = 0; i < listImgSrc.size(); i++) {
String url = listImgSrc.get(i);
String imageName = url.substring(url.lastIndexOf("/") + 1, url.length());
URL uri = new URL(url);
// 打开连接
URLConnection con = uri.openConnection();
//设置请求超时为5s
con.setConnectTimeout(5 * 1000);
// 输入流
InputStream is = con.getInputStream();
// 1K的数据缓冲
byte[] bs = new byte[1024];
// 读取到的数据长度
int len;
// 输出的文件流
String src = listImgSrc.get(i).substring(URL.length());
int index = src.lastIndexOf('/');
String fileName = src.substring(0, index + 1);
File sf = new File(SAVE_PATH + fileName);
if (!sf.exists()) {
sf.mkdirs();
}
OutputStream os = new FileOutputStream(sf.getPath() + "\\" + imageName);
System.out.println(++count + ".开始下载:" + url);
// 开始读取
while ((len = is.read(bs)) != -1) {
os.write(bs, 0, len);
}
// 完毕,关闭所有链接
os.close();
is.close();
System.out.println(imageName + ":--下载完成");
System.out.println();
}
} catch (Exception e) {
System.out.println("下载失败");
}
}
由于中间有些许类似的代码我就不显示了
汇总
package cn.lm.util;
import org.apache.http.client.ClientProtocolException;
import java.io.*;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @Author Ronin
* @Date 2019/11/20 14:50
* @Version 1.0
*/
public class WPC {
// 地址
private static final String URL = "http://www.ktbdqn.com/";
// 编码
private static final String ECODING = "utf-8";
// 获取img标签正则
private static final String IMGURL_REG = "]*?>" ;
//获取link标签正则
private static final String LINKURL_REG = "]*?>" ;
// 获取Img的src路径的正则
private static final String IMGSRC_REG = "(?x)(src|SRC|background|BACKGROUND)=('|\")/?(([\\w-]+/)*([\\w-]+\\.(jpg|JPG|png|PNG|gif|GIF)))('|\")";
// 获取Link的href路径的正则
private static final String LINKSRC_REG = "(?x)(href|HREF)=('|\")/?(([\\w-]+/)*([\\w-]+\\.(css|CSS|([\\w-]+/)*([\\w-]+\\.(css|CSS|([\\w-]+/)*([\\w-]+\\.(css|CSS)))))))('|\")";
// css本地保存路径
private static final String SAVE_CSS_PATH = "d:\\cskt\\";
// img本地保存路径
private static final String SAVE_PATH = "d:\\";
/**
* @param url 要抓取的网页地址
* @param encoding 要抓取网页编码
* @return
*/
public static String getHtmlResourceByUrl(String url, String encoding) {
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader reader = null;
StringBuffer buffer = new StringBuffer();
// 建立网络连接
try {
urlObj = new URL(url);
// 打开网络连接
uc = urlObj.openConnection();
// 建立文件输入流
isr = new InputStreamReader(uc.getInputStream(), encoding);
// 建立缓存导入 将网页源代码下载下来
reader = new BufferedReader(isr);
// 临时
String temp = null;
while ((temp = reader.readLine()) != null) {// 一次读一行 只要不为空就说明没读完继续读
// System.out.println(temp+"\n");
buffer.append(temp + "\n");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关流
if (isr != null) {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return buffer.toString();
}
public static void getJobInfo(String url, String encoding) {
// 拿到网页源代码
String html = getHtmlResourceByUrl(url, encoding);
try {
File fp = new File("D:/cskt/cskt.html");
OutputStream os = new FileOutputStream(fp); //建立文件输出流
os.write(html.getBytes());
os.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/***
* 下载图片
*
* @param listImgSrc
*/
public static void Download(List<String> listImgSrc) {
int count = 0;
try {
for (int i = 0; i < listImgSrc.size(); i++) {
String url = listImgSrc.get(i);
String imageName = url.substring(url.lastIndexOf("/") + 1, url.length());
URL uri = new URL(url);
// 打开连接
URLConnection con = uri.openConnection();
//设置请求超时为5s
con.setConnectTimeout(5 * 1000);
// 输入流
InputStream is = con.getInputStream();
// 1K的数据缓冲
byte[] bs = new byte[1024];
// 读取到的数据长度
int len;
// 输出的文件流
String src = listImgSrc.get(i).substring(URL.length());
int index = src.lastIndexOf('/');
String fileName = src.substring(0, index + 1);
File sf = new File(SAVE_PATH + fileName);
if (!sf.exists()) {
sf.mkdirs();
}
OutputStream os = new FileOutputStream(sf.getPath() + "\\" + imageName);
System.out.println(++count + ".开始下载:" + url);
// 开始读取
while ((len = is.read(bs)) != -1) {
os.write(bs, 0, len);
}
// 完毕,关闭所有链接
os.close();
is.close();
System.out.println(imageName + ":--下载完成");
System.out.println();
}
} catch (Exception e) {
System.out.println("下载失败");
}
}
/***
* 下载样式
*
* @param listCssSrc
*/
public static void DownCss(List<String> listCssSrc) {
int count = 0;
try {
for (int i = 0; i < listCssSrc.size(); i++) {
String url = listCssSrc.get(i);
String imageName = url.substring(url.lastIndexOf("/") + 1, url.length());
URL uri = new URL(url);
// 打开连接
URLConnection con = uri.openConnection();
//设置请求超时为5s
con.setConnectTimeout(5 * 1000);
// 输入流
InputStream is = con.getInputStream();
// 1K的数据缓冲
byte[] bs = new byte[1024];
// 读取到的数据长度
int len;
// 输出的文件流
String src = listCssSrc.get(i).substring(URL.length());
int index = src.lastIndexOf('/');
String fileName = src.substring(0, index + 1);
File sf = new File(SAVE_CSS_PATH + fileName);
if (!sf.exists()) {
sf.mkdirs();
}
OutputStream os = new FileOutputStream(sf.getPath() + "\\" + imageName);
System.out.println(++count + ".开始下载:" + url);
// 开始读取
while ((len = is.read(bs)) != -1) {
os.write(bs, 0, len);
}
// 完毕,关闭所有链接
os.close();
is.close();
System.out.println(imageName + ":--下载完成");
System.out.println();
}
} catch (Exception e) {
System.out.println("下载失败");
}
}
/**
* 得到网页中图片的地址
*
* @param htmlStr html字符串
* @return List
*/
private static List<String> getImgStr(String htmlStr) {
List<String> pics = new ArrayList<String>();
String img = "";
Pattern p_image;
Matcher m_image;
p_image = Pattern.compile(IMGURL_REG, Pattern.CASE_INSENSITIVE);
m_image = p_image.matcher(htmlStr);
while (m_image.find()) {
// 得到![]() 数据
img = m_image.group();
// 匹配
数据
img = m_image.group();
// 匹配![]() 中的src数据
Matcher m = Pattern.compile(IMGSRC_REG).matcher(img);
while (m.find()) {
String imgUrl = m.group(3);
if (!imgUrl.contains("http://") && !imgUrl.contains("https://")) {//没有这两个头
imgUrl = URL + imgUrl;
}
pics.add(imgUrl);
}
}
return pics;
}
/**
* 得到网页中样式的地址
*
* @param htmlStr html字符串
* @return List
中的src数据
Matcher m = Pattern.compile(IMGSRC_REG).matcher(img);
while (m.find()) {
String imgUrl = m.group(3);
if (!imgUrl.contains("http://") && !imgUrl.contains("https://")) {//没有这两个头
imgUrl = URL + imgUrl;
}
pics.add(imgUrl);
}
}
return pics;
}
/**
* 得到网页中样式的地址
*
* @param htmlStr html字符串
* @return List
*/
private static List<String> getCssStr(String htmlStr) {
List<String> csss = new ArrayList<String>();
String css = "";
Pattern p_css;
Matcher m_css;
p_css = Pattern.compile(LINKURL_REG, Pattern.CASE_INSENSITIVE);
m_css = p_css.matcher(htmlStr);
while (m_css.find()) {
// 得到中的src数据
Matcher m = Pattern.compile(LINKSRC_REG).matcher(css);
while (m.find()) {
String cssUrl = m.group(3);
if (!cssUrl.contains("http://") && !cssUrl.contains("https://")) {//没有这两个头
cssUrl = URL + cssUrl;
}
csss.add(cssUrl);
}
}
return csss;
}
/**
* 主方法
* @param args
* @throws ClientProtocolException
* @throws IOException
*/
public static void main(String[] args) throws ClientProtocolException, IOException {
//保存网页源码
getJobInfo(URL, ECODING);
//获得html文本内容
String HTML = WPC.getHtmlResourceByUrl(URL, ECODING);
//获取图片src的url地址
List<String> imgSrc = WPC.getImgStr(HTML);
//下载图片
WPC.Download(imgSrc);
//获取样式href的url地址
List<String> cssSrc = WPC.getCssStr(HTML);
//下载css样式
WPC.DownCss(cssSrc);
}
}
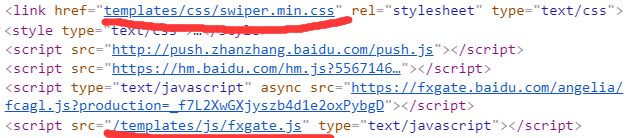
由于他这里调用的地址有些许不一样,加上 / 的话就是根目录,我们这里下载到D盘里面根目录就是D盘,所以我们把他爬下来会有些许变化所以我在上面定义了两个存储地址,图片img存储在根目录D盘下,样式css存储在跟html同目录下。
执行代码
运行后
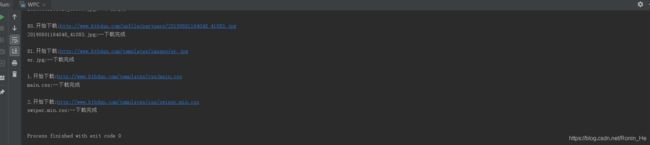
D盘下面会出现两个文件夹,如:
D:\cskt 目录下会出现如下:
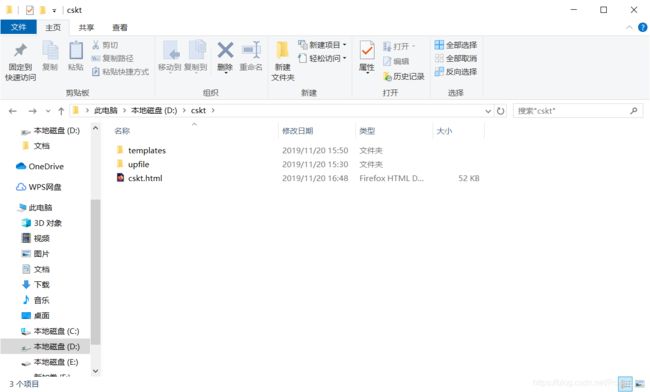
使用浏览器打开cskt.html会出现如下效果图:
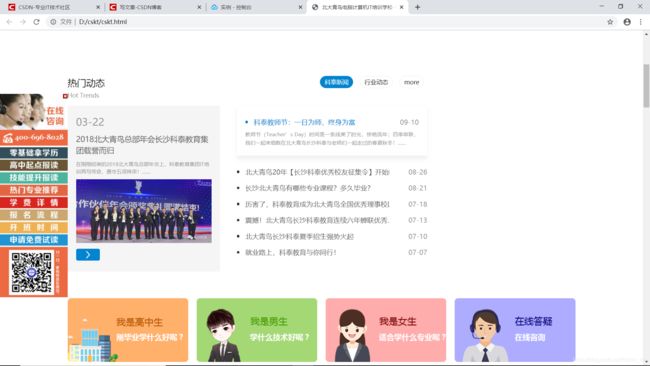
由于技术问题,暂时只能实现这些。