C#数据结构与算法
一、数据结构介绍
为什么学习数据结构?
对于同样的问题,有的人写出来的程序效率高,而有的人却用很复杂的方法解决。
学习数据结构的目的是:能用最有效的方法解决绝大多数的问题。
学习数据结构的三个目的:
1.讲授常用的数据结构
这些数据结构形成了程序员基本数据结构工具箱(toolkit)。对于许多常见的问题,工具箱里的数据结构是理想的选择。就像.NET Framework 中 Windows 应用程序开发中的工具箱,程序员可以直接拿来或经过少许的修改就可以使用,非常方便。
2.讲授常用的算法
它和数据结构一样,是人们在长期实践过程中的总结,程序员可以直接拿来或经过少许的修改就可以使用。可以通过算法训练来提高程序设计水平。
3.通过程序设计的技能训练促进程序员综合能力的提高。
总结:数据结构是程序员的内功修炼的一部分。
基本概念和术语:
1.数据(Data)
计算机程序处理各种各样的数据,可以是数值数据,如整数、实数或复数;也可以是非数值数据,如字符、文字、图形、图像、声音等。
2.数据元素(Data Element)和数据项(Data Item)
数据元素是数据的基本单位,在计算机程序中通常被作为一个整体进行考虑和处理。一个数据元素可由若干个数据项(Data Item)组成。数据项是不可分割的、含有独立意义的最小数据单位,数据项有时也称为字段(Field)或域(Domain)。例如,一条学生记录就是一个数据元素。这条记录中的学生学号、姓名、性别、籍贯、出生年月、成绩等字段就是数据项。数据项分为两种,一种叫做初等项,如学生的性别、籍贯等,在处理时不能再进行分割;另一种叫做组合项,如学生的成绩,它可以再分为数学、物理、化学等更小的项。
3.数据对象(Data Object)
数据对象是性质相同的数据元素的集合, 是数据的一个子集。例如,整数数据对象是{0,±1,±2,±3,…},字符数据对象是{a,b,c,…}。
4.数据类型(Data Type)
数据类型是高级程序设计语言中的概念,是数据的取值范围和对数据进行操作的总和。数据类型规定了程序中对象的特性。程序中的每个变量、常量或表达式的结果都应该属于某种确定的数据类型。例如,C#语言中的字符串类型( String,经常写为 string)。一个 String 表示一个恒定不变的字符序列集合,所有的字符序列集合构成 String 的取值范围。我们可以对 String 进行求长度、复制、连接两个字符串等操作。
数据结构分类(Data Structure):
数据结构是相互之间存在一种或多种特定关系的数据元素的集合。在任何问题中,数据元素之间都不是孤立的,而是存在着一定的关系,这种关系称为结构(Structure)。根据数据元素之间关系的不同特性,通常有 4 类基本数据结构:
(1)集合(Set):如图(a)所示,该结构中的数据元素除了存在“同属于一个集合”的关系外,不存在任何其它关系。
(2)线性结构(Linear Structure):如图(b)所示,该结构中的数据元素存在着一对一的关系。
(3)树形结构(Tree Structure):如图(c)所示,该结构中的数据元素存在着一对多的关系。 (4)图状结构(Graphic Structure):如图(d)所示,该结构中的数据元素存在着多对多的关系。

什么是算法?
算法可以理解为有基本运算及规定的运算顺序所构成的完整的解题步骤。或者看成按照要求设计好的有限的确切的计算序列,并且这样的步骤和序列可以解决一类问题。
算法和数据结构的关系
数据结构可以认为是数据在程序中的存储结构,和基本数据操作。
算法可以是认为解决问题的,算法是基于数据结构的。
数据结构是问题的核心,是算法的基础。
算法的评价标准
运行时间(Running Time)。
占用空间(Storage Space)。
有时需要牺牲空间来换取时间,有时需要牺牲时间来换取空间。
其他方面:正确性(Correctness)、可读性(Readability)、健壮性(Robustness)
二、线性表
什么是线性表?
线性表是最简单、最基本、最常用的数据结构。线性表是线性结构的抽象(Abstract),线性结构的特点是结构中的数据元素之间存在一对一的线性关系。这种一对一的关系指的是数据元素之间的位置关系,即:
(1)除第一个位置的数据元素外,其它数据元素位置的前面都只有一个数据元素;
(2)除最后一个位置的数据元素外,其它数据元素位置的后面都只有一个元素。也就是说,数据元素是一个接一个的排列。因此,可以把线性表想象为一种数据元素序列的数据结构。
线性表就是位置有先后关系,一个接着一个排列的数据结构。
CLR中的线性表
c# 1.1 提供了一个非泛型接口IList接口,接口中的项是object,实现了IList解扣子的类有ArrayList,ListDictionary,StringCollection,StringDictionary;
c# 2.0 提供了泛型的IList
线性表的接口定义
interface IListDS
{
int GetLength();
void Clear();
bool IsEmpty();
void Add(T item);
void Insert(T item, int index);
T Delete(int index);
T this[int index] { get; }
T GetEle(int index);
int Locate(T value);
} 线性表的实现方式
线性表的实现方式有下面几种:
1.顺序表;
2.单链表;
3.双向链表;
4.循环链表;
顺序表
在计算机内,保存线性表最简单、最自然的方式,就是把表中的元素一个接一个地放进顺序的存储单元,这就是线性表的顺序存储(Sequence Storage)。线性表的顺序存储是指在内存中用一块地址连续的空间依次存放线性表的数据元素,用这种方式存储的线性表叫顺序表(Sequence List),如图所示。顺序表的特点是表中相邻的数据元素在内存中存储位置也相邻。
 顺序表的存储
顺序表的存储
假设顺序表中的每个数据元素占w个存储单元,设第i个数据元素的存储地址为Loc(ai),则有:
Loc(ai)= Loc(a1)+(i-1)*w 1≤i≤n 式中的Loc(a1)表示第一个数据元素a1的存储地址,也是顺序表的起始存储地址,称为顺序表的基地址(Base Address)。也就是说,只要知道顺序表的基地址和每个数据元素所占的存储单元的个数就可以求出顺序表中任何一个数据元素的存储地址。并且,由于计算顺序表中每个数据元素存储地址的时间相同,所以顺序表具有任意存取的特点。(可以在任意位置存取东西)
C#语言中的数组在内存中占用的存储空间就是一组连续的存储区域,因此,数组具有任意存取的特点。所以,数组天生具有表示顺序表的数据存储区域的特性。
顺序表的实现
class SeqList : IListDS
{
private T[] data;//用来存储数据
private int count = 0;//表示存了多少个数据
public SeqList(int size)//size就是最大容量
{
data = new T[size];
count = 0;
}
public SeqList():this(10)//默认构造函数 容量是10
{
}
public void Add(T item)
{
if(count==data.Length)//当前数组已经存满
{
Console.WriteLine("当前顺序表已经存满,不允许再存入");
}
else
{
data[count] = item;
count++;
}
}
public void Clear()
{
count = 0;
}
public T Delete(int index)
{
T temp = data[index];
for(int i=index+1;i=0&&index<=count-1)//索引存在
{
return data[index];
}
else
{
Console.WriteLine("索引不存在");
return default(T);
}
}
///
/// 取得数据的个数
///
/// 单链表
顺序表是用地址连续的存储单元顺序存储线性表中的各个数据元素,逻辑上相邻的数据元素在物理位置上也相邻。因此,在顺序表中查找任何一个位置上的数据元素非常方便,这是顺序存储的优点。但是,在对顺序表进行插入和删除时,需要通过移动数据元素来实现,影响了运行效率。线性表的另外一种存储结构——链式存储(Linked Storage),这样的线性表叫链表(Linked List)。链表不要求逻辑上相邻的数据元素在物理存储位置上也相邻,因此,在对链表进行插入和删除时不需要移动数据元素,但同时也失去了顺序表可随机存储的优点。
单链表的存储
链表是用一组任意的存储单元来存储线性表中的数据元素(这组存储单元可以是连续的,也可以是不连续的)。那么,怎么表示两个数据元素逻辑上的相邻关系呢?即如何表示数据元素之间的线性关系呢?为此,在存储数据元素时,除了存储数据元素本身的信息外,还要存储与它相邻的数据元素的存储地址信息。这两部分信息组成该数据元素的存储映像(Image),称为结点(Node)。把存储据元素本身信息的域叫结点的数据域(Data Domain),把存储与它相邻的数据元素的存储地址信息的域叫结点的引用域(Reference Domain)。因此,线性表通过每个结点的引用域形成了一根“链条”,这就是“链表”名称的由来。
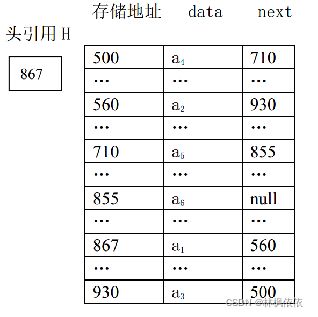
如果结点的引用域只存储该结点直接后继结点的存储地址,则该链表叫单链表(Singly Linked List)。把该引用域叫 next。单链表结点的结构如图所示,图中 data 表示结点的数据域。
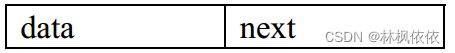
链式存储结构
下图是线性表(a1,a2,a3,a4,a5,a6)对应的链式存储结构示意图。
另外一种表示形式:

单链表结点定义:
///
/// 单链表的结点
///
///
{
private T data;//存储数据
private Node next;//指针 用来指向下一个元素
public Node()
{
data = default(T);
next = null;
}
public Node(T value)
{
data = value;
next = null;
}
public Node(T value,Node next)
{
this.data = value;
this.next = next;
}
public Node(Node next)
{
this.next = next;
}
public T Data
{
get { return data; }
set { data = value; }
}
public Node Next
{
get { return next; }
set { next = value; }
}
} 单链表的实现:
class LinkList:IListDS
{
private Node head;//存储一个头结点
public LinkList()
{
head = null;
}
public void Add(T item)
{
Node newNode = new Node(item);//根据新的数据创建一个新的结点
//如果头结点为空,那么这个新的结点就是头结点
if(head==null)
{
head = newNode;
}
else
{//把新来的结点放到 链表的尾部
//要访问到链表的尾结点
Node temp = head;
while(true)
{
if(temp.Next!=null)
{
temp = temp.Next;
}
else
{
break;
}
}
temp.Next = newNode;//把新来的结点放到链表的尾部
}
}
public void Insert(T item,int index)
{
Node newNode = new Node(item);
if(index==0)//插入到头结点
{
newNode.Next = head;
head = newNode;
}
else
{
Node temp = head;
for(int i=1;i<=index-1;i++)
{
//让temp向后移动一个位置
temp = temp.Next;
}
Node preNode = temp;
Node currentNode = temp.Next;
preNode.Next = newNode;
newNode.Next = currentNode;
}
}
public T Delete(int index)
{
T data = default(T);
if(index==0)//删除头结点
{
data = head.Data;
head = head.Next;
}
else
{
Node temp = head;
for(int i=1;i<=index-1;i++)
{
//让temp向后移动一个位置
temp = temp.Next;
}
Node preNode = temp;
Node currentNode = temp.Next;
data = currentNode.Data;
Node nextNode = temp.Next.Next;
preNode.Next = nextNode;
}
return data;
}
public int GetLength()
{
if (head == null) return 0;
Node temp = head;
int count = 1;
while(true)
{
if(temp.Next!=null)
{
count++;
temp = temp.Next;
}
else
{
break;
}
}
return count;
}
public void Clear()
{
head = null;
}
public bool IsEmpty()
{
return head == null;
}
public T this[int index]
{
get
{
Node temp = head;
for(int i=1;i<=index;i++)
{
//让temp向后移动一个位置
temp = temp.Next;
}
return temp.Data;
}
}
public T GetEle(int index)
{
return this[index];
}
public int Locate(T value)
{
Node temp = head;
if(temp==null)
{
return -1;
}
else
{
int index = 0;
while(true)
{
if(temp.Data.Equals(value))
{
return index;
}
else
{
if(temp.Next!=null)
{
temp = temp.Next;
}
else
{
break;
}
}
}
return -1;
}
}
} 双向链表
前面介绍的单链表允许从一个结点直接访问它的后继结点,所以, 找直接后继结点的时间复杂度是 O(1)。但是,要找某个结点的直接前驱结点,只能从表的头引用开始遍历各结点。如果某个结点的 Next 等于该结点,那么,这个结点就是该结点的直接前驱结点。也就是说,找直接前驱结点的时间复杂度是 O(n), n是单链表的长度。当然,我们也可以在结点的引用域中保存直接前驱结点的地址而不是直接后继结点的地址。这样,找直接前驱结点的时间复杂度只有 O(1),但找直接后继结点的时间复杂度是 O(n)。如果希望找直接前驱结点和直接后继结点的时间复杂度都是 O(1),那么,需要在结点中设两个引用域,一个保存直接前驱结点的地址,叫 prev,一个直接后继结点的地址,叫 next,这样的链表就是双向链表(Doubly Linked List)。双向链表的结点结构示意图如图所示。

双向链表结点实现
public class DbNode
{
private T data; //数据域
private DbNode prev; //前驱引用域
private DbNode next; //后继引用域
//构造器
public DbNode(T val, DbNode p)
{
data = val;
next = p;
}
//构造器
public DbNode(DbNode p)
{
next = p;
}
//构造器
public DbNode(T val)
{
data = val;
next = null;
}
//构造器
public DbNode()
{
data = default(T);
next = null;
}
//数据域属性
public T Data
{
get { return data; }
set { data = value; }
}
//前驱引用域属性
public DbNode Prev
{
get { return prev; }
set { prev = value; }
}
//后继引用域属性
public DbNode Next
{
get { return next; }
set { next = value; }
}
}
双向链表插入示意图

循环链表
有些应用不需要链表中有明显的头尾结点。在这种情况下,可能需要方便地从最后一个结点访问到第一个结点。此时,最后一个结点的引用域不是空引用,而是保存的第一个结点的地址(如果该链表带结点,则保存的是头结点的地址),也就是头引用的值。带头结点的循环链表(Circular Linked List)如图所示。

三、栈和队列
栈和队列是非常重要的两种数据结构,在软件设计中应用很多。栈和队列也是线性结构,线性表、栈和队列这三种数据结构的数据元素以及数据元素间的逻辑关系完全相同,差别是线性表的操作不受限制,而栈和队列的操作受到限制。栈的操作只能在表的一端进行,队列的插入操作在表的一端进行而其它操作在表的另一端进行,所以,把栈和队列称为操作受限的线性表。
栈
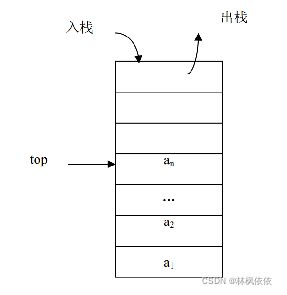
栈(Stack)是操作限定在表的尾端进行的线性表。表尾由于要进行插入、删除等操作,所以,它具有特殊的含义,把表尾称为栈顶( Top),另一端是固定的,叫栈底( Bottom)。当栈中没有数据元素时叫空栈(Empty Stack)。
栈通常记为: S= (a1,a2,…,an),S是英文单词stack的第 1 个字母。a1为栈底元素,an为栈顶元素。这n个数据元素按照a1,a2,…,an的顺序依次入栈,而出栈的次序相反,an第一个出栈,a1最后一个出栈。所以,栈的操作是按照后进先出(Last In First Out,简称LIFO)或先进后出(First In Last Out,简称FILO)的原则进行的,因此,栈又称为LIFO表或FILO表。栈的操作示意图如图所示。
BCL中的栈
C#2.0 以下版本只提供了非泛型的Stack类(存储object类型)
C#2.0 提供了泛型的Stack
重要的方法如下:
1,Push()入栈(添加数据)
2,Pop()出栈(删除数据,返回被删除的数据)
3,Peek()取得栈顶的数据,不删除
4,Clear()清空所有数 5,Count取得栈中数据的个数
栈的接口定义
public interface IStackDS
{
int Count { get; }
int GetLength();//求栈的长度
bool IsEmpty();//判断栈是否为空
void Clear();//清空操作
void Push(T item);//入栈操作
T Pop();//出栈操作
T Peek();//取栈顶元素
} 顺序栈
用一片连续的存储空间来存储栈中的数据元素(使用数组),这样的栈称为顺序栈(Sequence Stack)。类似于顺序表,用一维数组来存放顺序栈中的数据元素。栈顶指示器 top 设在数组下标为 0 的端, top 随着插入和删除而变化,当栈为空时,top=-1。下图是顺序栈的栈顶指示器 top 与栈中数据元素的关系图。
class SeqStack : IStackDS
{
private T[] data;
private int top;
public SeqStack(int size)
{
data = new T[size];
top = -1;
}
public SeqStack():this(10)
{
}
public int Count
{
get { return top + 1; }
}
public void Clear()
{
top = -1;
}
public int GetLength()
{
return Count;
}
public bool IsEmpty()
{
return Count == 0;
}
public T Peek()
{
return data[top];
}
public T Pop()
{
T temp = data[top];
top--;
return temp;
}
public void Push(T item)
{
data[top + 1] = item;
top++;
}
} 链栈
栈的另外一种存储方式是链式存储,这样的栈称为链栈(Linked Stack)。链栈通常用单链表来表示,它的实现是单链表的简化。所以,链栈结点的结构与单链表结点的结构一样,如图 3.3 所示。由于链栈的操作只是在一端进行,为了操作方便,把栈顶设在链表的头部,并且不需要头结点。
 链栈的结点
链栈的结点
class Node
{
private T data;
private Node next;
public Node()
{
data = default(T);
next = null;
}
public Node(T data)
{
this.data = data;
next = null;
}
public Node(Node next)
{
this.next = next;
data = default(T);
}
public Node(T data,Node next)
{
this.data = data;
this.next = next;
}
public T Data
{
get { return data; }
set { data = value; }
}
public Node Next
{
get { return next; }
set { next = value; }
}
} 链栈的类
class LinkStack : IStackDS
{
private Node top;//栈顶元素结点
public int count = 0;//栈中元素个数
public int Count
{
get { return count; }
}
public int GetLength()
{
return count;
}
public void Clear()
{
count = 0;
top = null;
}
public bool IsEmpty()
{
return count == 0;
}
///
/// 取得栈顶中的数据,不删除栈顶
///
///
/// 出栈 取得栈顶元素,然后删除
///
///
/// 入栈
///
///
public void Push(T item)
{
//把新添加的元素作为头结点(栈顶)
Node newNode = new Node(item);
newNode.Next = top;
top = newNode;
count++;
}
} 队列
队列(Queue)是插入操作限定在表的尾部而其它操作限定在表的头部进行的线性表。把进行插入操作的表尾称为队尾(Rear),把进行其它操作的头部称为队头(Front)。当队列中没有数据元素时称为空队列(Empty Queue)。
队列通常记为: Q= (a1,a2,…,an),Q是英文单词queue的第 1 个字母。a1为队头元素,an为队尾元素。这n个元素是按照a1,a2,…,an的次序依次入队的,出对的次序与入队相同,a1第一个出队,an最后一个出队。所以,对列的操作是按照先进先出(First In First Out)或后进后出( Last In Last Out)的原则进行的,因此,队列又称为FIFO表或LILO表。队列Q的操作示意图如图所示。
在实际生活中有许多类似于队列的例子。比如,排队取钱,先来的先取,后来的排在队尾。
队列的操作是线性表操作的一个子集。队列的操作主要包括在队尾插入元素、在队头删除元素、取队头元素和判断队列是否为空等。与栈一样,队列的运算是定义在逻辑结构层次上的,而运算的具体实现是建立在物理存储结构层次上的。因此,把队列的操作作为逻辑结构的一部分,每个操作的具体实现只有在确定了队列的存储结构之后才能完成。队列的基本运算不是它的全部运算,而是一些常用的基本运算。
BCL中的队列
C#2.0 以下版本提供了非泛型的Queue类
C#2.0 提供了泛型Queue
方法
1,Enqueue()入队(放在队尾)
2,Dequeue()出队(移除队首元素,并返回被移除的元素)
3,Peek()取得队首的元素,不移除
4,Clear()清空元素
属性
5,Count获取队列中元素的个数
队列接口定义
public interface IQueue
{
int Count { get; }//取得队列长度的属性
int GetLength();//求队列的长度
bool IsEmpty();//判断队列是否为空
void Clear();//清空队列
void Enqueue(T item);//入队
T Dequque();//出队
T Peek();//取队头元素
} 顺序队列
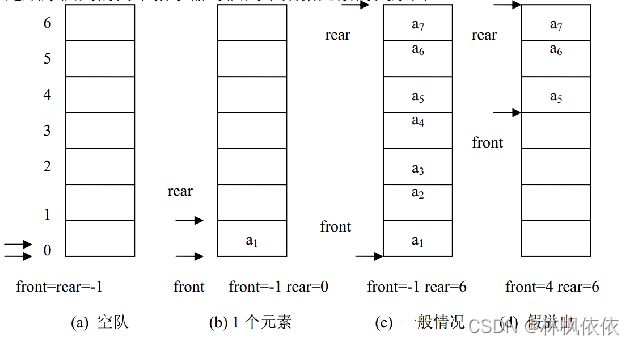
用一片连续的存储空间来存储队列中的数据元素,这样的队列称为顺序队列(Sequence Queue)。类似于顺序栈,用一维数组来存放顺序队列中的数据元素。队头位置设在数组下标为 0 的端,用 front 表示;队尾位置设在数组的另一端,用 rear 表示。 front 和 rear 随着插入和删除而变化。当队列为空时, front=rear=-1。
图是顺序队列的两个指示器与队列中数据元素的关系图。
顺序队列(循环顺序队列)
如果再有一个数据元素入队就会出现溢出。但事实上队列中并未满,还有空闲空间,把这种现象称为“假溢出”。这是由于队列“队尾入队头出”的操作原则造成的。解决假溢出的方法是将顺序队列看成是首尾相接的循环结构,头尾指示器的关系不变,这种队列叫循环顺序队列(Circular sequence Queue)。循环队列如图所示。

把循环顺序队列看作是一个泛型类,类名叫 CSeqStack
链队列
队列的另外一种存储方式是链式存储,这样的队列称为链队列(Linked Queue)。同链栈一样,链队列通常用单链表来表示,它的实现是单链表的简化。所以,链队列的结点的结构与单链表一样,如图所示。由于链队列的操作只是在一端进行,为了操作方便,把队头设在链表的头部,并且不需要头结点。
链队列结点类

public class Node
{
private T data;//数据域
private Node next;//引用域
//构造器
public Node(T val,Node p)
{
data = val;
next = p;
}
//构造器
public Node(Node p)
{
next = p;
}
//构造器
public Node(T val)
{
data = val;
next = null;
}
//构造器
public Node()
{
data = default(T);
next = null;
}
//数据域属性
public T Data
{
get { return data; }
set { data = value; }
}
//引用域属性
public Node Next
{
get { return next; }
set { next = value; }
}
} 把链队列看作一个泛型类,类名为 LinkQueue
栈和队列的应用举例:
编程判断一个字符串是否是回文。回文是指一个字符序列以中间字符为基准两边字符完全相同,如字符序列“ ACBDEDBCA”是回文。
算法思想:判断一个字符序列是否是回文,就是把第一个字符与最后一个字符相比较,第二个字符与倒数第二个字符比较,依次类推,第 i 个字符与第 n-i个字符比较。如果每次比较都相等,则为回文,如果某次比较不相等,就不是回文。因此,可以把字符序列分别入队列和栈,然后逐个出队列和出栈并比较出队列的字符和出栈的字符是否相等,若全部相等则该字符序列就是回文,否则就不是回文。
class Program
{
static void Main(string[] args)
{
string str = Console.ReadLine();
Stack stack = new Stack();
Queue queue = new Queue();
for(int i=0;i0)
{
if(stack.Pop()!=queue.Dequeue())
{
isHui = false;
break;
}
}
Console.WriteLine("是否是回文字符串:" + isHui);
Console.ReadKey();
}
} 四、串
在应用程序中使用最频繁的类型是字符串。字符串简称串,是一种特殊的线性表,其特殊性在于串中的数据元素是一个个的字符。字符串在计算机的许多方面应用很广。如在汇编和高级语言的编译程序中,源程序和目标程序都是字符串数据。在事务处理程序中,顾客的信息如姓名、地址等及货物的名称、产地和规格等,都被作为字符串来处理。另外,字符串还具有自身的一些特性。因此,把字符串作为一种数据结构来研究。
串的基本概念
串(String)由 n(n≥0)字符组成的有限序列。一般记为:
S=”c1c2…cn” (n≥0)
其中, S是串名,双引号作为串的定界符,用双引号引起来的字符序列是串值。 ci( 1≤i≤n)可以是字母、数字或其它字符, n为串的长度,当n=0 时,称为空串(Empty String)。
串中任意个连续的字符组成的子序列称为该串的子串(Substring)。包含子串的串相应地称为主串。子串的第一个字符在主串中的位置叫子串的位置。如串s1”abcdefg”,它的长度是 7,串s2”cdef”的长度是 4, s2是s1的子串, s2的位置是 3。
如果两个串的长度相等并且对应位置的字符都相等,则称这两个串相等。而在 C#中,比较两个串是否相等还要看串的语言文化等信息。
串的存储和代码实现
由于串中的字符都是连续存储的,而在 C#中串具有恒定不变的特性,即字符串一经创建,就不能将其变长、变短或者改变其中任何的字符。所以,这里不讨论串的链式存储,也不用接口来表示串的操作。同样,把串看作是一个类,类名为 StringDS。取名为 StringDS 是为了和 C#自身的字符串类 String 相区别。类StringDS 只有一个字段,即存放串中字符序列的数组 data。由于串的运算有很多,类 StringDS 中只包含部分基本的运算。串类 StringDS中的方法和属性:
class StringDS
{
public char[] data;//用来存放字符串中的字符
public StringDS(char[] array)
{
data = new char[array.Length];
for(int i=0;i
/// 如果两个字符串一样,那么返回0
/// 如果两个字符串小于s,那么返回-1
/// 如果两个字符串大于s,那么返回1
///
///
/// s[index])
{
return 1;
}
else
{
return -1;
}
}
else
{
if(this.GetLength()==s.GetLength())
{
return 0;
}
else
{
if(this.GetLength()>s.GetLength())
{
return 1;
}
else
{
return -1;
}
}
}
}
///
/// 截取字符串(从index开始,长度为length的字符串)
///
///
///
///
/// 连接两个字符串
///
///
///
///
/// 用于返回某个指定字符串值在字符串中首次出现的位置
///
///
/// C#中的串
在 C#中,一个 String 表示一个恒定不变的字符序列集合。 String 类型是封闭类型,所以,它不能被其它类继承,而它直接继承自 object。因此, String 是引用类型,不是值类型,在托管堆上而不是在线程的堆栈上分配空间。 String 类型还继承了 IComparable 、 ICloneable 、 IConvertible 、 IComparable
在 C#中,创建串不能用 new 操作符,而是使用一种称为字符串驻留的机制。
这是因为 C#语言将 String 看作是基元类型。基元类型是被编译器直接支持的类型,可以在源代码中用文本常量(Literal)来直接表达字符串。当 C#编译器对源代码进行编译时,将文本常量字符串存放在托管模块的元数据中。而当 CLR 初始化时, CLR 创建一个空的散列表,其中的键是字符串,值为指向托管堆中字符串对象的引用。散列表就是哈希表。当 JIT编译器编译方法时,它会在散列表中查找每一个文本常量字符串。如果找不到,就会在托管堆中构造一个新的 String 对象(指向字符串),然后将该字符串和指向该字符串对象的引用添加到散列表中;如果找到了,不会执行任何操作。
C#中的数组
数组是一种常用的数据结构,可以看作是线性表的推广。数组作为一种数据结构,其特点是结构中的数据元素可以是具有某种结构的数据,甚至可以是数组,但属于同一数据类型。数组在许多高级语言里面都被作为固定类型来使用。
数组是 n(n≥1)个相同数据类型的数据元素的有限序列。一维数组可以看作是一个线性表,二维数组可以看作是“数据元素是一维数组”的一维数组,三维数组可以看作是“数据元素是二维数组”的一维数组,依次类推。
C#支持一维数组、多维数组及交错数组(数组的数组)。所有的数组类型都隐含继承自 System.Array。Array 是一个抽象类,本身又继承自 System.Object。所以,数组总是在托管堆上分配空间,是引用类型。任何数组变量包含的是一个指向数组的引用,而非数组本身。当数组中的元素的值类型时,该类型所需的内存空间也作为数组的一部分而分配;当数组的元素是引用类型时,数组包含是只是引用。
Array类中的常用方法
public abstract class Array : ICloneable, IList, ICollection, IEnumerable
{
//判断Array是否具有固定大小
public bool IsFixedSize { get; }
//获取Array元素的个数
public int Length { get;}
//获取Array的秩(维数)
public int Rank { get; }
//实现IComparable接口,在Array中搜索特定元素
public static int BinarySearch(Array array, object value);
//实现IComparable 泛型接口,在Array中搜索特定元素
public static int BinarySearch(T[] array, T value);
//实现IComparable接口,在Array某个范围中搜索值
public static int BinarySearch(Array array, int index, int length, Object value);
//实现IComparable泛型接口,在Array中搜索值
public static int BinarySearch(T[] array, int index, int length, T value);
//Array设置为零、false或null,具体取决于元素类型
public static void Clear(Array array, int index, int length);
//System.Array的浅表副本
public object Clone();
//从第一个元素开始复制Array中的一系列元素 到另一个Array中(从第一个元素开始)
public static void Copy(Array sourceArray, Array destinationArray, int length);
//将一维Array的所有元素复制到指定的一维Array中
public void CopyTo(Array array, int index);
//创建使用从零开始的索引、具有指定Type和维长的多维Array
public static Array CreateInstance(Type elementType, params int[] lengths);
//返回ArrayIEnumerator
public IEnumerator GetEnumerator();
//获取Array指定维中的元素数
public int GetLength(int dimension);
//获取一维Array中指定位置的值
public object GetValue(int index);
//返回整个一维Array中的第一个匹配项的索引
public static int IndexOf(Array array, object value);
//返回整个Array中第一个匹配项的索引
public static int LastIndexOf(Array array, object value);
//反转整个一维Array中最后一个匹配项的索引
public static void Reverse(Array array);
//设置给一维Array中指定位置的元素
public void SetValue(object value, int index);
//对整个一维Array中的元素进行排序
public static void Sort(Array array);
} 练习题:
1. 设 s=”I am a teacher”,i=”excellent”,r=”student”。用 StringDS类中的方法求:
( 1) 串 s、i、r 的长度;
( 2) s.SubString(8, 4)、i.SubString(2, 1);
( 3) s.IndexOf(“tea”)、i.IndexOf(“cell”)、r.IndexOf(“den”)。
class Program
{
static void Main(string[] args)
{
StringDS s = new StringDS("I am a teacher");
StringDS i = new StringDS("excellent");
StringDS r = new StringDS("student");
Console.WriteLine(s.GetLength());
Console.WriteLine(i.GetLength());
Console.WriteLine(r.GetLength());
StringDS s2 = s.SubString(8, 4);
StringDS i2 = i.SubString(2, 1);
Console.WriteLine(s2.ToString());
Console.WriteLine(i2.ToString());
Console.WriteLine(s.IndexOf(new StringDS("tea")));
Console.WriteLine(i.IndexOf(new StringDS("cell")));
Console.WriteLine(r.IndexOf(new StringDS("den")));
Console.ReadKey();
}
}2. 串的替换操作是指:已知串 s、t、r,用 r 替换 s 中出现的所有与 t 相等的子串。写出算法,方法名为 Replace。
///
/// 串的替换操作
///
///
///
///
/// 验证结果:
StringDS s = new StringDS("I am a teacher");
StringDS t = new StringDS("a1");
StringDS r = new StringDS("*");
StringDS temp = new StringDS("");
temp = temp.Replace(s, t, r);
Console.WriteLine(temp.ToString());
Console.ReadKey();3. 已知下列字符串:
a=”THIS”,f=”A SMPLE” c=”GOOD”,d=”NE”,b=”︼”,g=”IS”,
s=a.Concat(b.Concat(a.SubString(3,2)).(f.SubString(2,7))),
t=f.Replace(f.SubString(3,6),c),
u=c.SubString(3,1).Concat(d),
v=s.Concat(b.Concat(t.ConCat(b.Concat(u))))。
问 s,t,v,GetLength(s),v.IndexOf(g),u.IndexOf(g)各是什么。
4. 设已知两个串为:
S1=”bc cad cabcadf”,S2=”abc”。试求两个串的长度,并判断 S2 串是否是 S1 串的子串,如果 S2 是 S1 的子串,指出 S2 在 S1 中的起始位置。
5. 已知:s=”(XYZ)+*”,t=”(X+Z)*Y”,试利用连接、求子串和替换等基本运算,将 s 转化为 t。
五、简单排序方法
排序
排序(Sort)是计算机程序设计中的一种重要操作,也是日常生活中经常遇到的问题。例如,字典中的单词是以字母的顺序排列,否则,使用起来非常困难。同样,存储在计算机中的数据的次序,对于处理这些数据的算法的速度和简便性而言,也具有非常深远的意义。
基本概念
排序是把一个记录(在排序中把数据元素称为记录)集合或序列重新排列成按记录的某个数据项值递增(或递减)的序列。
下表是一个学生成绩表,其中某个学生记录包括学号、姓名及计算机文化基础、C 语言、数据结构等课程的成绩和总成绩等数据项。在排序时,如果用总成绩来排序,则会得到一个有序序列;如果以数据结构成绩进行排序,则会得到另一个有序序列。
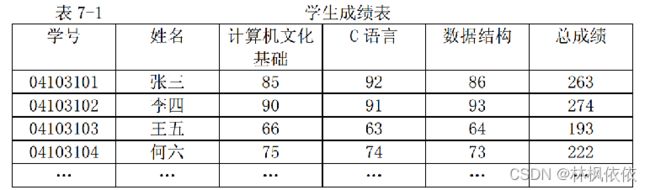
作为排序依据的数据项称为“排序项”,也称为记录的关键码(Keyword)。关键码分为主关键码(Primary Keyword)和次关键码(Secondary Keyword)。一般地,若关键码是主关键码,则对于任意待排序的序列,经排序后得到的结果是唯一的;若关键码是次关键码,排序的结果不一定唯一,这是因为待排序的序列中可能存在具有相同关键码值的记录。此时,这些记录在排序结果中,它们之间的位置关系与排序前不一定保持一致。如果使用某个排序方法对任意的记录序列按关键码进行排序,相同关键码值的记录之间的位置关系与排序前一致,则称此排序方法是稳定的;如果不一致,则称此排序方法是不稳定的。
由于待排序的记录的数量不同,使得排序过程中涉及的存储器不同,可将排序方法分为内部排序(Internal Sorting)和外部排序(External Sorting)两大类。
内部排序指的是在排序的整个过程中,记录全部存放在计算机的内存中,并且在内存中调整记录之间的相对位置,在此期间没有进行内、外存的数据交换。外部排序指的是在排序过程中,记录的主要部分存放在外存中,借助于内存逐步调整记录之间的相对位置。在这个过程中,需要不断地在内、外存之间交换数据。
直接插入排序
插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为O(n^2)。是稳定的排序方法。插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插入的位置),而第二部分就只包含这一个元素(即待插入元素)。在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中。
插入排序的基本思想是:每步将一个待排序的纪录,按其关键码值的大小插入前面已经排序的文件中适当位置上,直到全部插入完为止。

冒泡排序
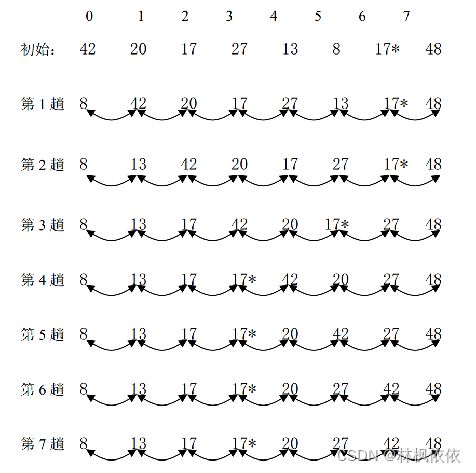
冒泡排序(Bubble Sort)的基本思想是:将相邻的记录的关键码进行比较,若前面记录的关键码大于后面记录的关键码,则将它们交换,否则不交换。
简单选择排序
简单选择排序(Simple Select Sort)算法的基本思想是:从待排序的记录序列中选择关键码最小(或最大)的记录并将它与序列中的第一个记录交换位置;然后从不包括第一个位置上的记录序列中选择关键码最小(或最大)的记录并将它与序列中的第二个记录交换位置;如此重复,直到序列中只剩下一个记录为止。

class Program
{
static void Main(string[] args)
{
int[] data = new int[] { 42, 20, 17, 27, 13, 8, 17, 48 };
SelectSort(data);
foreach(var temp in data)
{
Console.Write(temp + " ");
}
Console.ReadKey();
}
static void SelectSort(int[] dataArray)
{
for (int i = 0; i < dataArray.Length - 1; i++)
{
int min = dataArray[i];
int minIndex = i;//最小值所在索引
for (int j = i + 1; j < dataArray.Length; j++)
{
if (dataArray[j] < min)
{
min = dataArray[j];
minIndex = j;
}
}
if (minIndex != i)
{
int temp = dataArray[i];
dataArray[i] = dataArray[minIndex];
dataArray[minIndex] = temp;
}
}
}
}六、快速排序
快速排序由于排序效率综合来说在这几种排序方法中效率较高,因此经常被采用,再加上快速排序思想----分治法也确实实用,因此很多软件公司的笔试面试,包括像腾讯,微软等知名IT公司都喜欢考这个,还有大大小小的程序方面的考试如软考,考研中也常常出现快速排序的身影。
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
该方法的基本思想是:
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
详细步骤:
以一个数组作为示例,取区间第一个数为基准数。
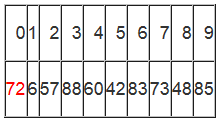
初始时,i = 0; j = 9; X = a[i] = 72
由于已经将a[0]中的数保存到X中,可以理解成在数组a[0]上挖了个坑,可以将其它数据填充到这来。
从j开始向前找一个比X小或等于X的数。当j=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8]; i++; 这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办了?简单,再找数字来填a[8]这个坑。这次从i开始向后找一个大于X的数,当i=3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3]; j--;
数组变为:

i = 3; j = 7; X=72
再重复上面的步骤,先从后向前找,再从前向后找。
从j开始向前找,当j=5,符合条件,将a[5]挖出填到上一个坑中,a[3] = a[5]; i++
从i开始向后找,当i=5时,由于i==j退出。
此时,i = j = 5,而a[5]刚好又是上次挖的坑,因此将X填入a[5]。
数组变为:
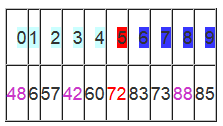
可以看出a[5]前面的数字都小于它,a[5]后面的数字都大于它。因此再对a[0…4]和a[6…9]这二个子区间重复上述步骤就可以了。
快速排序代码实现
class Program
{
static void Main(string[] args)
{
int[] data = new int[] { 42, 20, 17, 27, 13, 8, 17, 48 };
QuickSort(data,0,data.Length-1);
foreach(var temp in data)
{
Console.Write(temp + " ");
}
Console.ReadKey();
}
static void QuickSort(int[] dataArray,int left,int right)
{
if(leftx)
{
dataArray[j] = dataArray[i];
break;
}
else
{
i++;
}
}
}
//跳出循环 现在i=j i是中间位置
dataArray[i] = x;
QuickSort(dataArray, left, i - 1);
QuickSort(dataArray, i + 1, right);
}
}
} 快排总结
1. i =L; j = R; 将基准数挖出形成第一个坑a[i];
2.j--由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中;
3. i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中;
4.再重复执行2,3二步,直到i==j,将基准数填入a[i]中。
七、算法简介
算法的作用
算法解决了哪些问题?
互联网信息的访问检测,海量数据的管理;
在一个交通图中,寻找最近的路;
人类基因工程,dna有10万个基因,处理这些基因序列需要复杂的算法支持......
上面的算法是我们没有接触到,或者是封装到底层的东西,那么作为程序员,在日常编码过程中会在什么地方使用算法呢?
在你利用代码去编写程序,去解决问题的时候,其实这些编码过程都可以总结成一个算法,只是有些算法看起来比较普遍比较一般,偶尔我们也会涉及一些复杂的算法比如一些AI。
大多数我们都会利用已有的思路(算法)去开发游戏!
学习算法的好处
学习算法就像是去理解编程
可以让我们平时的编码过程变得更加通畅
并且会提高我们解决程序问题的能力
所以称之为内功修炼。
八、分治算法
分治策略是:对于一个规模为n的问题,若该问题可以容易地解决(比如说规模n较小)则直接解决,否则将其分解为k个规模较小的子问题,这些子问题互相独立且与原问题形式相同,递归地解这些子问题,然后将各子问题的解合并得到原问题的解。这种算法设计策略叫做分治法。
可使用分治法求解的一些经典问题:
(1)二分搜索
(2)大整数乘法
(3)Strassen矩阵乘法
(4)棋盘覆盖
(5)合并排序
(6)快速排序
(7)线性时间选择
(8)最接近点对问题
(9)循环赛日程表
(10)汉诺塔
eg:股票问题
| 天数 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
| 价格 |
100 |
113 |
110 |
85 |
105 |
102 |
86 |
63 |
81 |
101 |
94 |
106 |
101 |
79 |
94 |
90 |
97 |
| 变化 |
13 |
-3 |
-25 |
20 |
-3 |
-16 |
-23 |
18 |
20 |
-7 |
12 |
-5 |
-22 |
15 |
-4 |
7 |
方法一:暴力求解法
class Program
{
static void Main(string[] args)
{
//暴力求解法
int[] priceArray = { 100, 113, 110, 85, 105, 102, 86, 63, 81, 101, 94, 106, 101, 79, 94, 90, 97 };//股价数组
int[] priceFluctuationArray = new int[priceArray.Length - 1];//股价波动数组
for(int i=1;itotal)
{
total = totalTemp;
startIndex = i;
endIndex = j;
}
}
}
Console.WriteLine("股票最佳购买日是第" + startIndex + "天,最佳出售日是第" + (endIndex + 1)+"天");
Console.ReadKey();
}
} 方法二:分治法
class Program
{
//最大子数组的结构体
struct SubArray
{
public int startIndex;
public int endIndex;
public int total;
}
///
/// 用来取得从low到high之间的最大子数组
///
///
///
///
/// 九、树

1.空树;
2.只有一个根节点的树;
3.
什么是子树?什么是父子结点?什么是根节点?什么是度?(拥有子树的个数称为结点的度)
结点关系:孩子,兄弟。
什么是树的层次?
最大层是树的深度
什么是有序树和无序树?

树的错误案例:
1.树只有一个根节点;
2.子树之间是不相交的;
3.一个结点不能有两个父结点。

树的存储结构
存储结构一般是 顺序存储和链式存储。
树的关系复杂 使用链式存储
1.双亲表示法
![]()
2.孩子表示法
![]()

3.孩子兄弟表示法
![]()

二叉树
什么是二叉树?


1.空二叉树
2.只有根结点
3.大于一个结点
什么是左右子树?
特殊二叉树
1.斜树(左斜树,右斜树)
2.满二叉树

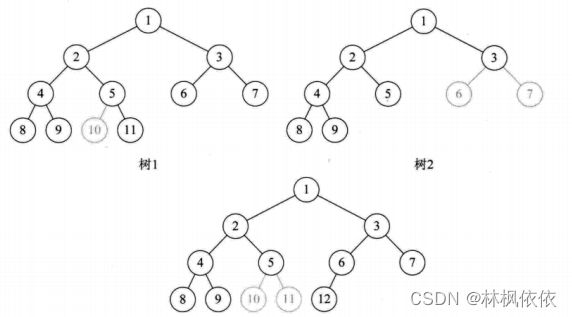
3.完全二叉树

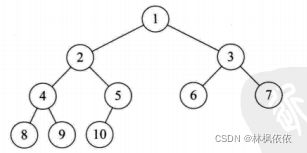
4.非完全二叉树
二叉树的性质

二叉树的存储结构
一般的树,是一对多的关系,使用顺序结构存储起来比较困难,但是二叉树是一种特殊的树,每个结点最多有两个子节点,并且子节点有左右之分,并且兄弟,父亲,孩子可以很方便的通过编号得到,所以我们使用顺序存储结构使用二叉树的存储。
二叉树存储 类型1:


二叉树存储 类型2:


二叉树存储 类型3:

注意:顺序存储一般只用于完全二叉树。
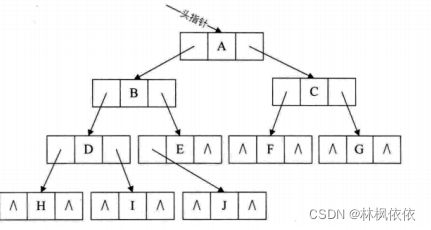
二叉树 二叉链表存储
二叉树每个结点最多有两个孩子,所以为它设计一个数据域和两个指针域,我们称这样的链表为二叉链表。
![]()
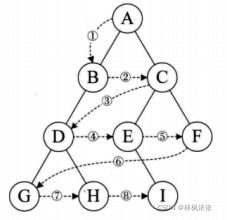
二叉树的遍历
二叉树的遍历是指从根结点出发,按照某种次序依次访问二叉树中的所有结点,使得每个结点被访问一次且仅被访问一次。
1.前序遍历
先输出当前结点的数据,再依次遍历输出左结点和右结点。

2.中序遍历
先遍历输出左结点,再输出当前结点的数据,再遍历输出右结点。

3.后序遍历
先遍历输出左结点,再遍历输出右结点,最后输出当前结点的数据。

4.层序遍历
从树的第一层开始,从上到下逐层遍历,在同一层中,从左到右对结点 逐个访问输出

class BiTree
{
private T[] data;
private int count = 0; //数量count代表当前保存了多少个数据
public BiTree(int capacity)//这个参数是当前二叉树的容量,容量就是最多可以存储的数据个数
{
data = new T[capacity];
}
public bool Add(T item)
{
if (count >= data.Length)
return false;
data[count] = item;
count++;
return true;
}
public void Traversal()
{
FirstTraversal(0);
Console.WriteLine("\n");
MiddleTraversal(0);
Console.WriteLine("\n");
LastTraversal(0);
Console.WriteLine("\n");
LayerTraversal();
}
///
/// 1.前序遍历
///
///
private void FirstTraversal(int index)
{
if (index >= count) return;
//得到要遍历的这个结点的编号
int number = index + 1;
if (data[index].Equals(-1)) return;
Console.Write(data[index] + " ");
//得到左子结点的编号
int leftNumber = number * 2;
int rightNumber = number * 2 + 1;
FirstTraversal(leftNumber - 1);
FirstTraversal(rightNumber - 1);
}
///
/// 2.中序遍历
///
///
private void MiddleTraversal(int index)
{
if (index >= count) return;
//得到要遍历的这个结点的编号
int number = index + 1;
if (data[index].Equals(-1)) return;
//得到左子结点的编号
int leftNumber = number * 2;
int rightNumber = number * 2 + 1;
MiddleTraversal(leftNumber - 1);
Console.Write(data[index] + " ");
MiddleTraversal(rightNumber - 1);
}
///
/// 3.后序遍历
///
///
private void LastTraversal(int index)
{
if (index >= count) return;
//得到要遍历的这个结点的编号
int number = index + 1;
if (data[index].Equals(-1)) return;
//得到左子结点的编号
int leftNumber = number * 2;
int rightNumber = number * 2 + 1;
LastTraversal(leftNumber - 1);
LastTraversal(rightNumber - 1);
Console.Write(data[index] + " ");
}
///
/// 4.层序遍历
///
private void LayerTraversal()
{
for(int i=0;i tree = new BiTree(10);
for (int i = 0; i < data.Length; i++)
{
tree.Add(data[i]);
}
tree.Traversal();
Console.ReadKey();
}
}