ResNet——CNN经典网络模型详解(pytorch实现)
1、前言
ResNet(Residual Neural Network)由微软研究院的Kaiming He等四名华人提出,通过使用ResNet Unit成功训练出了152层的神经网络,并在ILSVRC2015比赛中取得冠军,在top5上的错误率为3.57%,同时参数量比VGGNet低,效果非常突出。ResNet的结构可以极快的加速神经网络的训练,模型的准确率也有比较大的提升。同时ResNet的推广性非常好,甚至可以直接用到InceptionNet网络中。
下图是ResNet34层模型的结构简图。

2、ResNet详解
在ResNet网络中有如下几个亮点:
- 提出residual结构(残差结构),并搭建超深的网络结构(突破1000层)
- 使用Batch Normalization加速训练(丢弃dropout)
在ResNet网络提出之前,传统的卷积神经网络都是通过将一系列卷积层与下采样层进行堆叠得到的。但是当堆叠到一定网络深度时,就会出现两个问题。
- 梯度消失或梯度爆炸。
- 退化问题(degradation problem)。
在ResNet论文中说通过数据的预处理以及在网络中使用BN(Batch Normalization)层能够解决梯度消失或者梯度爆炸问题。如果不了解BN层可参考这个链接
。但是对于退化问题(随着网络层数的加深,效果还会变差,如下图所示)并没有很好的解决办法。
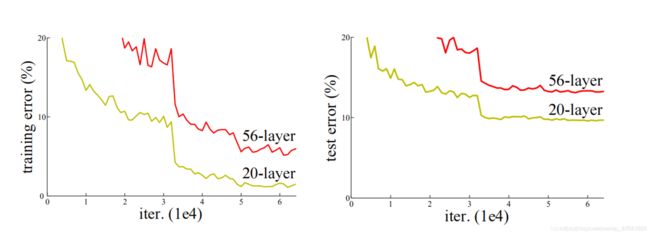
所以ResNet论文提出了residual结构(残差结构)来减轻退化问题。下图是使用residual结构的卷积网络,可以看到随着网络的不断加深,效果并没有变差,反而变的更好了。

残差结构(residual)
残差指的是什么?
其中ResNet提出了两种mapping:一种是identity mapping,指的就是下图中”弯弯的曲线”,另一种residual mapping,指的就是除了”弯弯的曲线“那部分,所以最后的输出是 y=F(x)+x
- identity mapping
顾名思义,就是指本身,也就是公式中的x,而residual mapping指的是“差”,也就是y−x,所以残差指的就是F(x)部分。
下图是论文中给出的两种残差结构。左边的残差结构是针对层数较少网络,例如ResNet18层和ResNet34层网络。右边是针对网络层数较多的网络,例如ResNet101,ResNet152等。为什么深层网络要使用右侧的残差结构呢。因为,右侧的残差结构能够减少网络参数与运算量。同样输入一个channel为256的特征矩阵,如果使用左侧的残差结构需要大约1170648个参数,但如果使用右侧的残差结构只需要69632个参数。明显搭建深层网络时,使用右侧的残差结构更合适。
 我们先对左侧的残差结构(针对ResNet18/34)进行一个分析。
我们先对左侧的残差结构(针对ResNet18/34)进行一个分析。
如下图所示,该残差结构的主分支是由两层3x3的卷积层组成,而残差结构右侧的连接线是shortcut分支也称捷径分支(注意为了让主分支上的输出矩阵能够与我们捷径分支上的输出矩阵进行相加,必须保证这两个输出特征矩阵有相同的shape)。如果刚刚仔细观察了ResNet34网络结构图的同学,应该能够发现图中会有一些虚线的残差结构。在原论文中作者只是简单说了这些虚线残差结构有降维的作用,并在捷径分支上通过1x1的卷积核进行降维处理。而下图右侧给出了详细的虚线残差结构,注意下每个卷积层的步距stride,以及捷径分支上的卷积核的个数(与主分支上的卷积核个数相同)。
 接着我们再来分析下针对ResNet50/101/152的残差结构,如下图所示。在该残差结构当中,主分支使用了三个卷积层,第一个是1x1的卷积层用来压缩channel维度,第二个是3x3的卷积层,第三个是1x1的卷积层用来还原channel维度(注意主分支上第一层卷积层和第二次卷积层所使用的卷积核个数是相同的,第三次是第一层的4倍)。该残差结构所对应的虚线残差结构如下图右侧所示,同样在捷径分支上有一层1x1的卷积层,它的卷积核个数与主分支上的第三层卷积层卷积核个数相同,注意每个卷积层的步距。
接着我们再来分析下针对ResNet50/101/152的残差结构,如下图所示。在该残差结构当中,主分支使用了三个卷积层,第一个是1x1的卷积层用来压缩channel维度,第二个是3x3的卷积层,第三个是1x1的卷积层用来还原channel维度(注意主分支上第一层卷积层和第二次卷积层所使用的卷积核个数是相同的,第三次是第一层的4倍)。该残差结构所对应的虚线残差结构如下图右侧所示,同样在捷径分支上有一层1x1的卷积层,它的卷积核个数与主分支上的第三层卷积层卷积核个数相同,注意每个卷积层的步距。
 为什么残差学习相对更容易,从直观上看残差学习需要学习的内容少,因为残差一般会比较小,学习难度小点。不过我们可以从数学的角度来分析这个问题,首先残差单元可以表示为:
为什么残差学习相对更容易,从直观上看残差学习需要学习的内容少,因为残差一般会比较小,学习难度小点。不过我们可以从数学的角度来分析这个问题,首先残差单元可以表示为:

其中 XL和 XL+1分别表示的是第L个残差单元的输入和输出,注意每个残差单元一般包含多层结构。 F是残差函数,表示学习到的残差,而 h(XL)=XL表示恒等映射, F是ReLU激活函数。基于上式,我们求得从浅层 l到深层 L 的学习特征为:
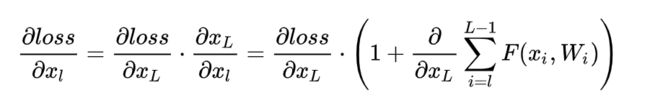 式子的第一个因子表示的损失函数到达L的梯度,小括号中的1表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。所以残差学习会更容易。要注意上面的推导并不是严格的证明。
式子的第一个因子表示的损失函数到达L的梯度,小括号中的1表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。所以残差学习会更容易。要注意上面的推导并不是严格的证明。
下面这幅图是原论文给出的不同深度的ResNet网络结构配置,注意表中的残差结构给出了主分支上卷积核的大小与卷积核个数,表中的xN表示将该残差结构重复N次。那到底哪些残差结构是虚线残差结构呢。
 对于我们ResNet18/34/50/101/152,表中conv3_x, conv4_x, conv5_x所对应的一系列残差结构的第一层残差结构都是虚线残差结构。因为这一系列残差结构的第一层都有调整输入特征矩阵shape的使命(将特征矩阵的高和宽缩减为原来的一半,将深度channel调整成下一层残差结构所需要的channel)。为了方便理解,下面给出了ResNet34的网络结构图,图中简单标注了一些信息。
对于我们ResNet18/34/50/101/152,表中conv3_x, conv4_x, conv5_x所对应的一系列残差结构的第一层残差结构都是虚线残差结构。因为这一系列残差结构的第一层都有调整输入特征矩阵shape的使命(将特征矩阵的高和宽缩减为原来的一半,将深度channel调整成下一层残差结构所需要的channel)。为了方便理解,下面给出了ResNet34的网络结构图,图中简单标注了一些信息。
 对于我们ResNet50/101/152,其实在conv2_x所对应的一系列残差结构的第一层也是虚线残差结构。因为它需要调整输入特征矩阵的channel,根据表格可知通过3x3的max pool之后输出的特征矩阵shape应该是[56, 56, 64],但我们conv2_x所对应的一系列残差结构中的实线残差结构它们期望的输入特征矩阵shape是[56, 56, 256](因为这样才能保证输入输出特征矩阵shape相同,才能将捷径分支的输出与主分支的输出进行相加)。所以第一层残差结构需要将shape从[56, 56, 64] --> [56, 56, 256]。注意,这里只调整channel维度,高和宽不变(而conv3_x, conv4_x, conv5_x所对应的一系列残差结构的第一层虚线残差结构不仅要调整channel还要将高和宽缩减为原来的一半)。
对于我们ResNet50/101/152,其实在conv2_x所对应的一系列残差结构的第一层也是虚线残差结构。因为它需要调整输入特征矩阵的channel,根据表格可知通过3x3的max pool之后输出的特征矩阵shape应该是[56, 56, 64],但我们conv2_x所对应的一系列残差结构中的实线残差结构它们期望的输入特征矩阵shape是[56, 56, 256](因为这样才能保证输入输出特征矩阵shape相同,才能将捷径分支的输出与主分支的输出进行相加)。所以第一层残差结构需要将shape从[56, 56, 64] --> [56, 56, 256]。注意,这里只调整channel维度,高和宽不变(而conv3_x, conv4_x, conv5_x所对应的一系列残差结构的第一层虚线残差结构不仅要调整channel还要将高和宽缩减为原来的一半)。
代码
注:
- 本次训练集下载在AlexNet博客有详细解说:https://blog.csdn.net/weixin_44023658/article/details/105798326
- 使用迁移学习方法实现收录在我的这篇blog中: 迁移学习 TransferLearning—通俗易懂地介绍(pytorch实例)
#model.py
import torch.nn as nn
import torch
#18/34
class BasicBlock(nn.Module):
expansion = 1 #每一个conv的卷积核个数的倍数
def __init__(self, in_channel, out_channel, stride=1, downsample=None):#downsample对应虚线残差结构
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)#BN处理
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x #捷径上的输出值
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
#50,101,152
class Bottleneck(nn.Module):
expansion = 4#4倍
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU(inplace=True)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU(inplace=True)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel*self.expansion,#输出*4
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, blocks_num, num_classes=1000, include_top=True):#block残差结构 include_top为了之后搭建更加复杂的网络
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)自适应
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel, channel, downsample=downsample, stride=stride))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel, channel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet34(num_classes=1000, include_top=True):
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
#train.py
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import json
import matplotlib.pyplot as plt
import os
import torch.optim as optim
from model import resnet34, resnet101
import torchvision.models.resnet
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),#来自官网参数
"val": transforms.Compose([transforms.Resize(256),#将最小边长缩放到256
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
data_root = os.getcwd()
image_path = data_root + "/flower_data/" # flower data set path
train_dataset = datasets.ImageFolder(root=image_path + "train",
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 16
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
validate_dataset = datasets.ImageFolder(root=image_path + "/val",
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=0)
#net = resnet34()
net = resnet34(num_classes=5)
# load pretrain weights
# model_weight_path = "./resnet34-pre.pth"
# missing_keys, unexpected_keys = net.load_state_dict(torch.load(model_weight_path), strict=False)#载入模型参数
# for param in net.parameters():
# param.requires_grad = False
# change fc layer structure
# inchannel = net.fc.in_features
# net.fc = nn.Linear(inchannel, 5)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
best_acc = 0.0
save_path = './resNet34.pth'
for epoch in range(3):
# train
net.train()
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
# print train process
rate = (step+1)/len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.4f}".format(int(rate*100), a, b, loss), end="")
print()
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device)) # eval model only have last output layer
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, val_accurate))
print('Finished Training')

#predict.py
import torch
from model import resnet34
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import json
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
img = Image.open("./roses.jpg")
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
# create model
model = resnet34(num_classes=5)
# load model weights
model_weight_path = "./resNet34.pth"
model.load_state_dict(torch.load(model_weight_path))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img))
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print(class_indict[str(predict_cla)], predict[predict_cla].numpy())
plt.show()

参考自:
太阳花的小绿豆