基于BERT模型的文本分类研究 TensorFlow2实现(内附源码)【自然语言处理NLP-100例】
- 运行环境:python3
- 作者:K同学啊
- 精选专栏:《深度学习100例》
- 推荐专栏:《新手入门深度学习》
- 选自专栏:《Matplotlib教程》
- 优秀专栏:《Python入门100题》
大家好,我是K同学啊!
在上一篇文章中讲解了BERT是什么,这一篇文章中我应用BERT进行一个文本分类的实战,使用的是THUCTC数据集,实现了财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐等10类文本的高效分类,最后的分类准确率达到了83.3%,项目情况如下:
自然语言处理100例:基于BERT模型的文本分类
-
- 一、导入并整理数据
- 二、数据集划分
- 三、构建模型
- 四、训练模型
- 五、模型评估
-
- 1. Loss图与Accourcy图
- 2. 其他评价参数
- 3. 混淆矩阵
一、导入并整理数据
data_path = "./5-data/data.txt"
model_path = "bert-base-chinese"
max_length = 32
batch_size = 128
learning_rate = 2e-5
num_classes = 10 # 类别数
# 准备数据
df_raw = pd.read_csv(data_path,sep="\t",header=None,names=["text","label"])
class_names = ["财经","房产","股票","教育","科技","社会","时政","体育","游戏","娱乐"]
# 标签数字化
df_label = pd.DataFrame({"label":class_names,"y":list(range(10))})
df_raw = pd.merge(df_raw,df_label,on="label",how="left")
df_raw.head(3)
| text | label | y | |
|---|---|---|---|
| 0 | 中华女子学院:本科层次仅1专业招男生 | 教育 | 3 |
| 1 | 两天价网站背后重重迷雾:做个网站究竟要多少钱 | 科技 | 4 |
| 2 | 东5环海棠公社230-290平2居准现房98折优惠 | 房产 | 1 |
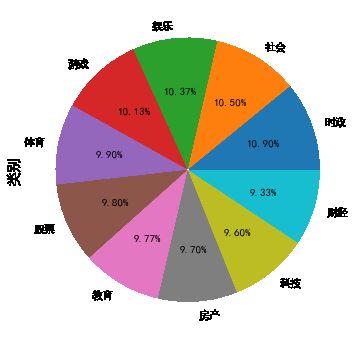
查看数据每一个类别的比例
# 源码内可阅读
plt.show()
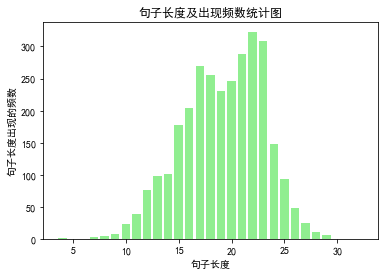
查看数据长度分布
# 源码内可阅读
plt.show()
# 源码内可阅读
plt.show()
分位点为0.9的句子长度:24。

二、数据集划分
train_data, x = train_test_split(df_raw,
stratify=df_raw['label'], #按照df['label']中的类别比例分配
test_size=0.1,
random_state=42)
val_data, test_data = train_test_split(x,
stratify=x['label'],
test_size=0.5,
random_state=43)
train_data.head(3)
| text | label | y | length | |
|---|---|---|---|---|
| 603 | 美国普利策奖全部奖项将允许网络媒体参选 | 时政 | 6 | 19 |
| 2373 | 09考研强化复习策略:提纲挈领 变中稳进 | 教育 | 3 | 20 |
| 1759 | 嫌犯仰仗家中藏獒拒捕 并以自残相威胁 | 社会 | 5 | 18 |
# tokenizer
tokenizer = BertTokenizer.from_pretrained(model_path)
# 调整数据格式
def map_example_to_dict(input_ids, attention_masks, token_type_ids, label):
return {
"input_ids": input_ids,
"token_type_ids": token_type_ids,
"attention_mask": attention_masks,
}, label
def encode_examples(ds):
input_ids_list = []
token_type_ids_list = []
attention_mask_list = []
label_list = []
for index, row in ds.iterrows():
bert_input = tokenizer.encode_plus(row["text"],
add_special_tokens = True, # add [CLS], [SEP]
max_length = max_length, # max length of the text that can go to BERT
pad_to_max_length = True, # add [PAD] tokens
return_attention_mask = True, # add attention mask to not focus on pad tokens
truncation=True)
input_ids_list.append(bert_input['input_ids'])
token_type_ids_list.append(bert_input['token_type_ids'])
attention_mask_list.append(bert_input['attention_mask'])
label_list.append(row["y"])
return tf.data.Dataset.from_tensor_slices((input_ids_list, attention_mask_list, token_type_ids_list, label_list)).map(map_example_to_dict)
三、构建模型
# 配置数据集
ds_train_encoded = encode_examples(train_data).shuffle(10000).batch(batch_size)
ds_val_encoded = encode_examples(val_data).batch(batch_size)
ds_test_encoded = encode_examples(test_data).batch(batch_size)
# 初始化模型
model = TFBertForSequenceClassification.from_pretrained(model_path, num_labels=num_classes)
# 设置优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate,epsilon=1e-08, clipnorm=1)
# 关于Loss不清楚的可以参考文章:https://mtyjkh.blog.csdn.net/article/details/122309754
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(optimizer=optimizer,
loss=loss,
metrics=[metric])
All model checkpoint layers were used when initializing TFBertForSequenceClassification.
Some layers of TFBertForSequenceClassification were not initialized from the model checkpoint at bert-base-chinese and are newly initialized: ['classifier']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
四、训练模型
# fit model
bert_history = model.fit(ds_train_encoded, epochs=10, validation_data=ds_val_encoded)
Epoch 1/10
22/22 [==============================] - 20s 277ms/step - loss: 1.9059 - accuracy: 0.4585 - val_loss: 1.2277 - val_accuracy: 0.7933
Epoch 2/10
22/22 [==============================] - 4s 204ms/step - loss: 0.9633 - accuracy: 0.8230 - val_loss: 0.6662 - val_accuracy: 0.8467
Epoch 3/10
22/22 [==============================] - 5s 204ms/step - loss: 0.5279 - accuracy: 0.8900 - val_loss: 0.5360 - val_accuracy: 0.8600
Epoch 4/10
22/22 [==============================] - 5s 205ms/step - loss: 0.3482 - accuracy: 0.9200 - val_loss: 0.4698 - val_accuracy: 0.8667
Epoch 5/10
22/22 [==============================] - 5s 204ms/step - loss: 0.2514 - accuracy: 0.9448 - val_loss: 0.4263 - val_accuracy: 0.8867
Epoch 6/10
22/22 [==============================] - 5s 205ms/step - loss: 0.1654 - accuracy: 0.9689 - val_loss: 0.4706 - val_accuracy: 0.8800
Epoch 7/10
22/22 [==============================] - 5s 205ms/step - loss: 0.1139 - accuracy: 0.9841 - val_loss: 0.4517 - val_accuracy: 0.8867
Epoch 8/10
22/22 [==============================] - 4s 204ms/step - loss: 0.0841 - accuracy: 0.9863 - val_loss: 0.4967 - val_accuracy: 0.8933
Epoch 9/10
22/22 [==============================] - 5s 205ms/step - loss: 0.0684 - accuracy: 0.9878 - val_loss: 0.4540 - val_accuracy: 0.8933
Epoch 10/10
22/22 [==============================] - 5s 204ms/step - loss: 0.0493 - accuracy: 0.9948 - val_loss: 0.5542 - val_accuracy: 0.8867oss: 0.0481 - accura
五、模型评估
# evaluate test_set
test_loss, test_accuracy = model.evaluate(ds_test_encoded)
print("test_set loss:", test_loss)
print("test_set accuracy:", test_accuracy)
2/2 [==============================] - 0s 28ms/step - loss: 0.6915 - accuracy: 0.8333
test_set loss: 0.691510796546936
test_set accuracy: 0.8333333134651184
1. Loss图与Accourcy图
# 源码内可阅读
plt.show()
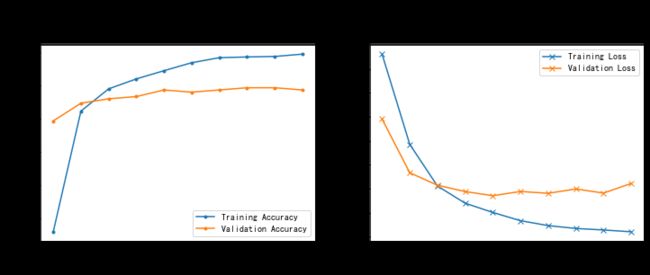
2. 其他评价参数
# 源码内可阅读
test_accuracy_report(model)
precision recall f1-score support
体育 1.00 0.93 0.97 15
娱乐 0.89 1.00 0.94 16
房产 0.71 0.86 0.77 14
教育 1.00 0.93 0.96 14
时政 0.87 0.76 0.81 17
游戏 1.00 0.73 0.85 15
社会 0.75 0.94 0.83 16
科技 0.92 0.80 0.86 15
股票 0.62 0.57 0.59 14
财经 0.69 0.79 0.73 14
accuracy 0.83 150
macro avg 0.84 0.83 0.83 150
weighted avg 0.85 0.83 0.83 150
Loss function: 0.691510796546936, accuracy: 0.8333333134651184
3. 混淆矩阵
# 源码内可阅读
plot_cm(test_label, test_pre)

源码领取地址:https://mp.weixin.qq.com/s/6K0ZInHfq-2acvbUwl5u3w