智慧交通day04-特定目标车辆追踪03:siamese在目标跟踪中的应用-SiamMask(2019)
与普通的视频跟踪网络不同的是,SiamMask可以同时完成视频跟踪和实例级分割的任务。如下图所示,与传统的对象跟踪器一样,依赖于一个简单的边界框初始化(蓝色)并在线操作。与ECO(红色)等最先进的跟踪器不同,SiamMask(绿色)能够生成二进制分割,从而更准确地描述目标对象。

3.5.1 网络结构
SiamMask的网络结构,提出了三分支的SiamMask网络。与之前的孪生网络十分相似的是,将模板图像与搜索图像输入网络,两者经过特征提取网络,特征提取网络如下表所示,生成15×15×256和31×31×256的featuremap,与SiamFC相似的是,将两个featuremap逐通道相互卷积,生成17×17×256的featuremap,将这个过程生成的像素值叫做RoW,如下图所示,蓝色的1×1×256的featuremap为heatmap的最大值,代表目标最有可能出现的位置。之后将featuremap输入三个分支中,图中h_{\psi}hψ,b_{\psi}bψ,s_{\psi}sψ 是1×1的卷积层,作用是改变通道的数量。
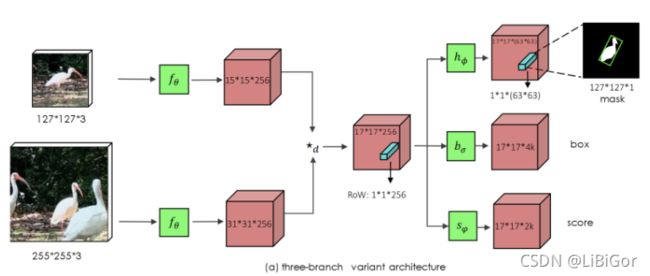
网络结构如下表所示:
在box分支中,17×17×256的featuremap经过1×1×(4k)的卷积层后生成17×17×4k的featuremap,这里k是每一个RoW生成k个anchors,这里实际上和SiamRPN相同,每四个一组,分别对应dx、dy、dw、dh四个值,代表着与groundtruth的距离。
在score分支中,17×17×256的featuremap经过1×1×(2k)的卷积层后生成17×17×2k的featuremap,这里k是每一个RoW生成k个anchors,这里实际上和SiamRPN相同,每两个一组,分别对应分类为目标和背景的标签结果。
在Mask分支中。17×17×256的featuremap经过1×1×(63×63)的卷积层后生成17×17×(63×63)的featuremap,从featuremap中取出与RoW位置相同的像素值,为1×1×(63×63),对其做上采样,生成127×127×1的图像,在这个图像中所有的像素值都取0或1,生成的相当于是一个二进制掩码,目标像素值为1,背景像素值为0,这样就完成了实例级分割的任务。
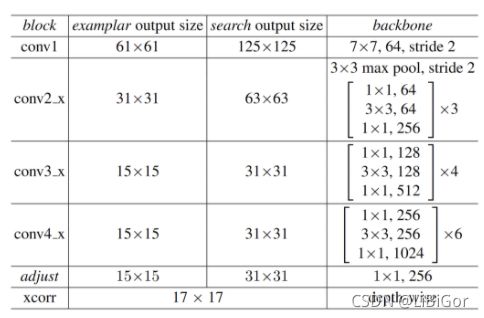
三分支中的网络结构如下表所示:
除了三分支的SiamMask之外,作者还提出了二分支的SiamMask网络,如上图所示,删掉了box分支,只保留score和Mask分支:
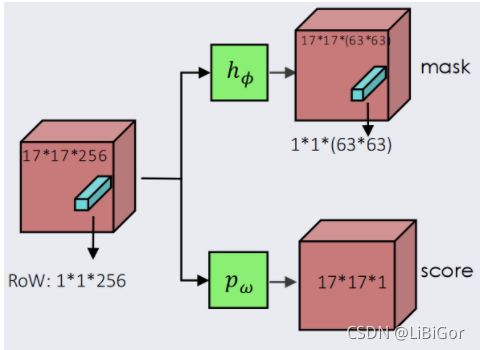
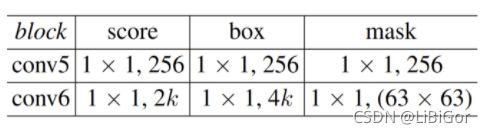
通过Mask分支生成的二进制掩码来生成相对应的bounding box,二分支中的网络结构如下表所示:
3.5.2 模型创新
- 改进的bounding box生成策略
设计了三种生成bounding box的策略如下图所示的红色、绿色和蓝色框
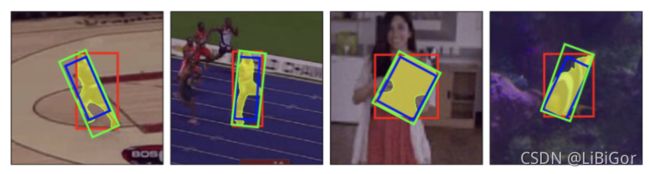
在之前的视频跟踪网络中,生成的都是平行于图片的x轴,y轴的bounding box。当然,SiamMask也能完成这样的任务,如图中红色框所示,在三分支的SiamMask网络中,box分支负责生成这样的bounding box。而在二分支的SiamMask网络中,利用Mask分支生成的二进制掩码取出目标所在的最小和最大的像素值,来生成Min-max的bounding box。
为了能够将bounding box尽可能的贴合物体,设计了MBR的生成策略,如图绿色框所示。同样,利用Mask分支生成的二进制掩码,求目标的最小包闭矩形,这样会导致生成的bounding box会有一定的倾斜。
还设计了一种策略Opt,如图中蓝色框所示。通过Mask分支生成的二进制掩码,求一个矩形区域使得矩形与目标像素的IoU最大,通过这种策略在一些计算目标与bounding box之间IoU的比赛中会提高SiamMask的成绩。
- 掩膜细化模型
下图为特征提取网络和Mask分支的结构图,网络忽略了box分支和score分支,经过特征提取网络生成的1×1×256的featuremap,首先经过反卷积生成15×15×32的featuremap,之后每一次反卷积都通过Ui 结合多层的特征,最后经过一个3×3的卷积层和Sigmoid层生成127×127×1的二进制掩码。
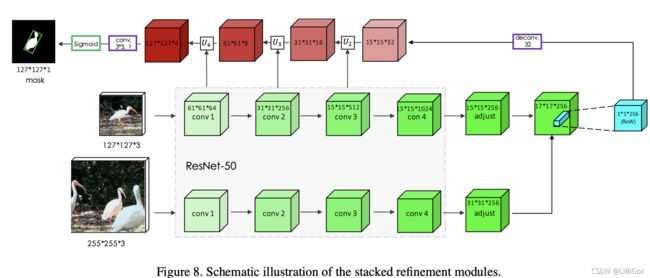
下图为细化模型的结构图,经过细化模型可以实现上采样的过程中结合特征提取的featuremap信息。

3.5.3 损失函数
Mask分支的损失函数:
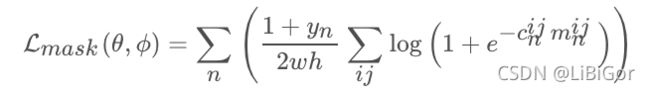
在Mask分支最后生成一个127×127×1的二进制掩码也需要对其进行标记,目标像素标记为+1,背景像素标记为-1,所以假设一个RoW中会有w×h个像素,cij为Mask中第n个RoW中第i,j个像素的真实标记,mij为对应的网络的输出。所以这里的Mask分支只会计算一个目标RoW在二进制掩码中的所有像素。
- 二分支:
二分支的SiamMask的损失函数如下式所示,其中λ1与λ2为超参数,λ1=32,λ2=1,L_{mask}Lmask 是上面讲的Mask分支的损失函数,L_{sim}Lsim是SiamFC的损失函数
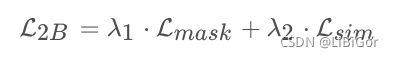
- 三分支:
三分支的SiamMask的损失函数如下式所示,其中λ1与λ2为超参数,λ1=32,λ2=λ3=1, L_{mask}Lmask是Mask分支的损失函数,L_{score}Lscore和L_{box}Lbox是SiamRPN的损失函数 L_{cls}Lcls和L_{reg}Lreg.
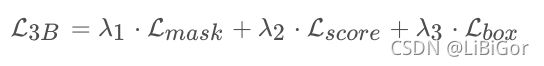
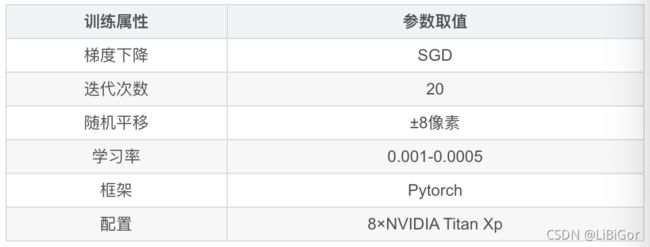
3.5.4 模型训练
siamMask是端到端训练模型,训练参数如下表所示: