DeepLearning:使用Pytorch搭建神经网络
使用Pytorch搭建神经网络
文章目录
- 使用Pytorch搭建神经网络
-
- nn.Moudle
-
- nn.Moudle含义
- 代码实战
- 卷积层
-
- 卷积层含义
- 卷积层重要公式
- 不同卷积操作对比
- 代码实战
- 最大池化层(MaxPooling)
-
-
- 最大池化层含义
- 代码实战
-
- 非线性激活层
-
- 什么是非线性激活层?
- sigmoid激活函数
- 双曲正切函数
- ReLu函数(线性修正单元)
- 线性层及其它层
-
- 线性层
- 正则化层(BatchNorm)
-
- 正则化层优点
- 官方解释
- 代码实战
-
- torch.flatten
- Dropout层(Dropout Layers)
-
- Dropout的含义
- 为什么Dropout可以有效防止过拟合?
- Sequential容器
- 损失函数与反向传播
-
- 损失函数
-
- 损失函数含义
-
- L1Loss
-
- L1Loss参数
- L1LOSS代码实战
- MSELOSS
-
- MSELOSS参数
- MSELOSS代码实战
- CrossEntropyLoss(交叉熵损失函数)
-
- CrossEntropyLoss参数
- CrossEntropyLoss代码实战
- 损失函数作用
- 反向传播(BackWard)
- 优化器
nn.Moudle
nn.Moudle含义
nn.Moudle是所有神经网络模型的父类,我们自己定义的模型应当是nn.Moudle的子类,在我们编写自己的模型时,务必要记得继承该类。同时,我们必须重写init方法与forward前向传播方法,以完成我们自己的网络。
代码实战
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
上述代码定义了一个Model类,继承了nn.Moudle。
卷积层
卷积层含义
卷积层对于计算机视觉研究者十分重要,其核心理论在CS231N笔记中,目前我们只讨论编程细节。因为输入的特征图为图像,所以目前暂时只讨论CONV2D方法。
官网文档解释如下:

根据上图的公式,我们可以得知在torch.nn.Conv2d函数中有一些重要的参数如下,参数较为常见:

卷积层重要公式
假设我们的特征输入图各参数表示如下:
i n p u t : ( N , C i n , H i n , W i n ) input:\left( N,C_{in},H_{in},W_{in} \right) input:(N,Cin,Hin,Win)
其中N为BatchSize的数量,C为通道数,H,W为特征图长、宽。
假设我们的特征输出图各参数表示如下:
o u t p u t : ( N , C o u t , H o u t , W o u t ) output:\left( N,C_{out},H_{out},W_{out} \right) output:(N,Cout,Hout,Wout)
由卷积核的各个参数,我们可以得到输出图像的大小为:
H o u t = H i n + 2 × P − K S + 1 H_{out}=\frac{H_{in}+2×P-K}{S}+1 Hout=SHin+2×P−K+1
不同卷积操作对比
Blue maps are inputs, and cyan maps are outputs.

动态演示详见:https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
代码实战
import torch
import torchvision
from torch.utils.data import DataLoader
from torch import nn
dataset = torchvision.datasets.CIFAR10("../../data",train=False,transform=torchvision.transforms.ToTensor(),download=False)
dataloader = DataLoader(dataset,batch_size = 64)
class mrp(nn.Module):
def __init__(self):
super(mrp, self).__init__()
self.conv1 = nn.Conv2d(3,6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
output = self.conv1(x)
return output
mrp_net = mrp()
# print(mrp_net)
for data in dataloader:
imgs,targets = data
output = mrp_net(imgs)
print(output.shape)
结果输出如下:

上述代码是我们利用卷积层,把CIFAR10数据集的3通道,32×32大小的图像通过stride=1,padding=0,kernel_size=3转化成了30×30大小的特征输出图。
最大池化层(MaxPooling)
最大池化层含义
最大池化是找出感受野内的最大值,其步长stride大小默认与卷积核大小相同。官方解释如下:

常见参数:

对于上述参数,我们应该关注Ceil_mode,当该参数为True将感受野中最大值向上取整+1且当我们的感受野部分滑出特征图时,仍然可以在特征图中剩余部分找到符合要求的值为结果,若为False则就是向下取整即可,且一旦感受野超出了特征图区域,不再进行计算。
代码实战
①:当ceil_mode=True时:
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32)
input = torch.reshape(input,(-1,1,5,5))
class mrp(nn.Module):
def __init__(self):
super(mrp, self).__init__()
self.maxpool1 = nn.MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,x):
output = self.maxpool1(x)
return output
mrp_net = mrp()
output = mrp_net(input)
print(output)
在上述代码中,我们定义一个3*3的卷积核,那么默认步长也为3。我们预测输出结果如下:
| 2 | 3 |
|---|---|
| 5 | 1 |
实际运行输出结果:

input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32)
input = torch.reshape(input,(-1,1,5,5))
class mrp(nn.Module):
def init(self):
super(mrp, self).init()
self.maxpool1 = nn.MaxPool2d(kernel_size=3,ceil_mode=False)
def forward(self,x):
output = self.maxpool1(x)
return output
mrp_net = mrp()
output = mrp_net(input)
print(output)
实际运行输出结果:

非线性激活层
什么是非线性激活层?
在深度神经网罗中,神经元的输入经过线性求和之后可以用非线性的激活函数把它激活,正是因为非线性的激活函数才为神经网络带来了非线性,才可以拟合非线性决策边界来解决非线性的分类和回归问题。常见的激活函数如下:
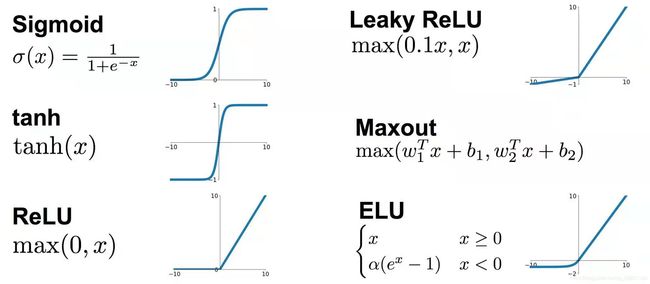
我仅介绍几个比较常见的:
sigmoid激活函数
函数公式如下:
S i g m o i d ( x ) = σ ( x ) = 1 1 + e − x Sigmoid(x)=\sigma (x)=\frac{1}{1+e^{-x}} Sigmoid(x)=σ(x)=1+e−x1
其函数图像如下:

该函数是挤压函数,可以把所有数值挤压在[0,1]之间,该函数可解释性好,可以类比神经细胞是否被激活。
但该函数存在3个主要问题(具体见CS231N笔记):
①饱和性会导致梯度消失。②激活后所有的输出值都是正数那么数据将不再是以0为中心分布,会有zig zag path现象。③分母中包含e这种指数级别的运算,十分消耗资源。
代码实战:
m = nn.Sigmoid()
input = torch.randn(2)
output = m(input)
双曲正切函数
函数公式如下:
T a n h ( x ) = t a n h ( x ) = e x + e − x e x − e − x Tanh(x)=tanh(x)=\frac{e^x+e^{-x}}{e^x-e^{-x}} Tanh(x)=tanh(x)=ex−e−xex+e−x
函数图像如下:

双曲正切函数与sigmoid类似,两者之间可以通过缩放、平移变换得到,双曲正切函数同样具有两边饱和和会产生梯度消失现象。好处是激活后得到的值关于0对称,解决了sigmoid的zigzagpath现象。
缺点:仍然在输入值趋向于无穷时产生梯度消失的不饱和现象。
代码实战:
ReLu函数(线性修正单元)
函数公式:
R e L U ( x ) = ( x ) + = m a x ( 0 , x ) ReLU(x)=(x)^+=max(0,x) ReLU(x)=(x)+=max(0,x)
函数图像如下:

Relu函数将x小于0的部分都抹平了,由于函数变成了折线而非直线故仍未非线性,特点是不会饱和且易于计算,消耗的计算资源也少。Relu函数比sigmoid和tanh函数的收敛快6倍以上(待编程验证)。
问题:Relu函数的输出并不关于0对称,且当x<0时,梯度为0,代表神经元死亡或瘫痪。
之所以产生上述现象是因为:①初始化不良:随机初始化的权重可能会产生所有都是0的现象,导致梯度也是0。②学习率太大,会跳入黑洞。我们可以为该函数增加一个偏置项0.01保证不会出现结果为0的现象。
代码实战:
m = nn.ReLU()
input = torch.randn(2)
output = m(input)
m = nn.ReLU()
input = torch.randn(2).unsqueeze(0)
output = torch.cat((m(input),m(-input)))
针对Relu函数我们可以使用LeakyRelu、PRelu、ERule函数进行改进,但是这些方法各有优缺点,此处不再赘述。
线性层及其它层
线性层
线性层一般也就是全连接层,一般用于模型最后分类映射。
函数公式:
y = x A T + b y=xA^T+b y=xAT+b
函数图像:

代码:
m = nn.Linear(20, 30)
input = torch.randn(128, 20)
output = m(input)
print(output.size())
#torch.Size([128, 30])
上述代码的作用是把128行20列的神经元全连接为128行30列的神经元。
正则化层(BatchNorm)
####正则化层含义
在正则化层中,我们可以强行将本层的输出结果变为标准正态分布。
正则化层优点
①显著改善过拟合,加快收敛效果②改善梯度(远离饱和区):通过BN层我们可以将单峰聚集现象分开,这样损失函数关于权重导数中的f’和x都不会为0,能够改善梯度消失现象。③可以使用大学习率:即不会掉入黑洞中。④对初始化不敏感:假如初始化在一小片,那么通过BN层可将其分开。(详见cs231N笔记)
####官网解释(以BatchNorm2d为例):

参数如下:
![]()
### 线性层(Linear Layers)
#### 线性层结构

官方解释

是否有偏置项b是由bias决定。
代码实战
我们可以用线性层来处理VGG16的最后一部分,即将(1×1)×4096的特征输入图全连接处理后输出为(1×1)×1000的特征输出图。

我们在CIFAR10数据集上验证,不过在这之前我们需要了解torch.flatten函数的作用。
torch.flatten
flatten函数可以将输入图像重新reshape成一维张量,代码演示如下:
t = torch.tensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]])
torch.flatten(t)
#tensor([1, 2, 3, 4, 5, 6, 7, 8])
torch.flatten(t, start_dim=1)#说明起始维度为1维,故从第1维到最后一维会展开,即按行展开。
#tensor([[1, 2, 3, 4],
# [5, 6, 7, 8]])
下面我们来使用nn.Linear:
dataset = torchvision.datasets.CIFAR10("../../data",train=False,transform=torchvision.transforms.ToTensor(),download=False)
dataloader = DataLoader(dataset,batch_size = 64)
class mrp(nn.Module):
def __init__(self):
super(mrp, self).__init__()
self.lnear1 = nn.Linear(196600,10)
def forward(self,x):
output = self.conv1(x)
return output
mrp_net = mrp()
# print(mrp_net)
for data in dataloader:
imgs,targets = data
#output = torch.reshape(imgs,(1,1,1,-1))
output = nn.Flatten(imgs)
output = mrp_net(output)
print(output.shape)
输出如下:
Dropout层(Dropout Layers)
Dropout的含义
Dropout指的是在训练过程中的每一步都随机掐死神经元,一般将该比例设置为0.5,即表示每次有一般的神经元可能会被保留或被掐死,掐死过后其前向传播和反向传播均被阻断,相当于神经网络结构中从未出现过该神经元,dropout可以有效防止过拟合。
为什么Dropout可以有效防止过拟合?
①由于随机掐死神经元,故可以打破特征之间的联合适应性,使得每个特征都独挡一面。②Dropout起到了模型集成的效果(每一层上神经元都有2种可能是否被保留,假设该层有n个神经元,那么会有2n种可能)相当于是在对2n个模型进行集成。
Sequential容器
在我看来,Sequential是堆叠网络结构来使用的,可以简化我们的代码,使我们的代码简洁易懂。
我们假设要复现下图中的神经网络:

当不使用Sequential时,代码如下:
class mrp(nn.Module):
def __init__(self):
super(mrp, self).__init__()
self.conv1 = nn.Conv2d(3,32,5,padding=2)
self.maxpool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(32,32,5,padding=2)
self.maxpool2 = nn.MaxPool2d(2)
self.conv3 = nn.Conv2d(32,64,5,padding=2)
self.maxpool3 = nn.MaxPool2d(2)
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(1024,64)
self.linear2 = nn.Linear(64,10)
def forwaed(self,x):
out = self.conv1(x)
out = self.maxpool1(out)
out = self.conv2(out)
out = self.maxpool2(out)
out = self.conv3(out)
out = self.maxpool3(out)
out = self.flatten(out)
out = self.linear1(out)
out = self.linear2(out)
return out
x = torch.ones((64,3,32,32))
mrp_net = mrp()
out = mrp_net(x)
print(out)
如果使用Sequential,代码如下:
class mrp(nn.Module):
def __init__(self):
super(mrp, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forwaed(self,x):
out = self.model1(x)
return out
x = torch.ones((64,3,32,32))
mrp_net = mrp()
out = mrp_net(x)
print(out)
可见使用nn.Moudle后,代码变得十分简洁。
损失函数与反向传播
损失函数
损失函数含义
我们知道,损失函数表示的是输入对应的输出与真实值之间的误差,当然这应该越小越好。
L1Loss
L1Loss的官方解释如下:

L1Loss参数

L1LOSS代码实战
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss_l1 = nn.MSELoss()
result_l1 = loss_mse(inputs,targets)
print(result_l1)
MSELOSS

MSELOSS参数

MSELOSS代码实战
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs,targets)
print(result_mse)
CrossEntropyLoss(交叉熵损失函数)

CrossEntropyLoss参数

CrossEntropyLoss代码实战
dataset = torchvision.datasets.CIFAR10("../../data",train=False,transform=torchvision.transforms.ToTensor(),download=False)
dataloader = DataLoader(dataset,batch_size = 1)
class mrp(nn.Module):
def __init__(self):
super(mrp, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forwaed(self,x):
out = self.model1(x)
return out
loss = nn.CrossEntropyLoss()
mrp_net = mrp()
for data in dataloader:
imgs, targets = data
outputs = mrp_net(imgs)
result_loss = loss(outputs,targets)
print(outputs)
print(targets)
损失函数作用
损失函数主要有两个作用:①计算实际输出和目标之间的差距。②为我们更新输出(为反向传播)提供一定的依据。
反向传播(BackWard)
具体理论部分参考CS231N笔记,具体代码如下:
for data in dataloader:
imgs, targets = data
outputs = mrp_net(imgs)
result_loss = loss(outputs,targets)
result_loss.backward()
优化器
优化器在Pytorch的torch.optim中,在反向传播后,我们需要用优化器对参数进行更新,且每次都需要清零,具体代码如下:
dataset = torchvision.datasets.CIFAR10("../../data",train=False,transform=torchvision.transforms.ToTensor(),download=False)
dataloader = DataLoader(dataset,batch_size = 1)
class mrp(nn.Module):
def __init__(self):
super(mrp, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forwaed(self,x):
out = self.model1(x)
return out
loss = nn.CrossEntropyLoss()
optim = torch.optim.SGD(mrp.parameters(),lr=0.01)
mrp_net = mrp()
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = mrp_net(imgs)
result_loss = loss(outputs,targets)
optim.zero_grad()
result_loss.backward()
optim.step()
running_loss = running_loss + result_loss
print(running_loss)