LeetCode+剑指 链表相关
☺☺☺
(1)剑指06: 从尾到头打印链表
输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。
示例 1:
输入:head = [1,3,2]
输出:[2,3,1]
限制:
0 <= 链表长度 <= 10000
法1:思路:栈,利用栈先进后出的特性。
放入栈中的是节点
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
vector<int> reversePrint(ListNode* head) {
stack<ListNode*> node; //存放各节点的地址
vector<int> res; //存放输入结果
ListNode* p=head;
while(p!=NULL){//注意判断结点空的NULL
node.push(p); //节点地址放入node栈中
p=p->next;
}
while(!node.empty()){//
p=node.top();
res.push_back(p->val);
node.pop();
}
return res;
}
};
法2
思路:遍历链表,同时把值放入vector中,最后用reverse翻转。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
vector<int> reversePrint(ListNode* head) {
vector<int> res; //存放结果
while(head!=NULL){
res.push_back(head->val);
head=head->next;
}
reverse(res.begin(),res.end());
return res;
}
};
暂时不用。。。
同法1,用栈,不过放入栈中的是值,而不是节点。
class Solution {
public:
vector<int> reversePrint(ListNode* head) {
stack<int>temp;
vector<int> num;
if(head == NULL){
return num;
}else{
while(head){
temp.push(head->val);
head = head->next;
}
while(!temp.empty()){
num.push_back(temp.top());
temp.pop();
}
}
return num;
}
}
☺☺☺
(2)剑指24. 反转链表(LC206)
知识点!!
重点理解:
1->2->3->4->5->null
翻转后是
5->4->3->2->1->null
其实每个链表后面的null我们是看不到的,所以它就不算一个结点。
例:
1->2
刚开始pNode->1
pr->pNode(实质上是pr通过pNode指向了pNode指向的结点)
现在pNode移动了,指向2
问?pr指向谁?
答:pr指向1
定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。
示例:
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
法1:双指针(简单版本)
双指针 tmp、head
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* tmp = NULL;
while (head!=NULL)
{
ListNode* pnext = head->next; //定义一个pnext指向head的下一个节点
head->next = tmp; //改变指向
tmp = head; //移动tmp
head = pnext; //移动head
}
return tmp;
}
};
思路:同上(双指针),变个表达方式。
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* ReverseList(ListNode* pHead) {
ListNode* pReverHead=NULL; //定义一个备用的指针。指向翻转后链表的头节点。
ListNode* pNode=pHead; //定义一个指向头节点的指针
ListNode* pPrev=NULL;
while(pNode!=NULL){
ListNode* pNext=pNode->next;
if(pNext==NULL){
pReverHead=pNode;
}
pNode->next=pPrev;
pPrev=pNode;
pNode=pNext;
}
return pReverHead;
}
};
☺☺☺
(3)92. 反转链表 II 【中等】
反转从位置 m 到 n 的链表。请使用一趟扫描完成反转。
说明:
1 ≤ m ≤ n ≤ 链表长度。
示例:
输入: 1->2->3->4->5->NULL, m = 2, n = 4
输出: 1->4->3->2->5->NULL
看遍评论区所有答案,找到一个最好理解的!(翻译的某java哈哈)
**分析
第一步:找到待反转节点的前一个节点。
第二步:反转m到n这部分。
第三步:将反转的起点的next指向反转的后面一部分。
第四步:将第一步找到的节点指向反转以后的头节点。
如下图所示:
**

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* reverseBetween(ListNode* head, int m, int n) {
if(!head || !head->next || m<0 || n<0 || m>=n) return head;//异常情况处理
ListNode* res=new ListNode(0); //新建一个节点
res->next=head; //新节点的next指向头节点,这样头结点就可以随意移动了,最后res->next就可
ListNode* node = res;
//找到需要反转的那一段的上一个节点。
for (int i = 1; i < m; i++) {
node = node->next;
}
//node.next就是需要反转的这段的起点。
ListNode* nextHead = node->next;
ListNode* next = NULL;
ListNode* pre = NULL;
//反转m到n这一段
for (int i = m; i <= n; i++) {//翻转位置m~n处的链表
next = nextHead->next;
nextHead->next = pre;
pre = nextHead;//更新指针
nextHead = next;//更新指针
}
//将反转的起点的next指向next。
node->next->next = next;
//需要反转的那一段的上一个节点的next节点指向反转后链表的头结点
node->next = pre;
return res->next;
}
};
默写一遍:(简洁)
class Solution {
public:
ListNode* reverseBetween(ListNode* head, int m, int n) {
ListNode* res=new ListNode(0);
res->next=head;
ListNode* node=res;
for(int i=1; i<m; i++){
node=node->next;
}
ListNode* phead=node->next;
ListNode* pre=NULL;//定义一前一后指针
ListNode* pnext=NULL;
for(int i=m; i<=n; i++){
pnext=phead->next;
phead->next=pre;
pre=phead;
phead=pnext;
}
node->next->next=phead;
node->next=pre;
return res->next;
}
};
☺☺☺
(4)LC237. 删除链表中的节点
这是一道看不懂问题的题,看了评论能笑死人! 啥意思啊。越看越想笑。。
请编写一个函数,使其可以删除某个链表中给定的(非末尾)节点,你将只被给定要求被删除的节点。
现有一个链表 – head = [4,5,1,9],它可以表示为:
4 -> 5 -> 1 -> 9
示例 1:
输入: head = [4,5,1,9], node = 5
输出: [4,1,9]
解释: 给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9.
示例 2:
输入: head = [4,5,1,9], node = 1
输出: [4,5,9]
解释: 给定你链表中值为 1 的第三个节点,那么在调用了你的函数之后,该链表应变为 4 -> 5 -> 9.
说明:
链表至少包含两个节点。
链表中所有节点的值都是唯一的。
给定的节点为非末尾节点并且一定是链表中的一个有效节点。
不要从你的函数中返回任何结果。
题目出得很没有意思 一道简单题 题目描述很随意 还搞出4–5--1–9删掉5之后419 这样子很容易误导大家 让大家以为是遍历链表删除特定元素 你直接说给定链表中一个特定节点(不是尾节点)请删除该节点 有时候简洁更好 为了描述清楚用了很多图例反而没有达到描述清楚的效果
这个题的关键在于要删除它的当前节点,而不知道前一个结点,而每个节点比较关键的就是data,把当前节点的data换成下一节点的data,链接地址换成下一节点的链接地址,也就变相的把当前节点删除了
后来想想,这题牛!确实是那么一回事!
覆盖法
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
void deleteNode(ListNode* node) {
node->val = node->next->val;
node->next = node->next->next;
}
};
结果:
加粗样式
☺☺☺
(5)剑指18. 删除链表的节点
这个才是正常的删除节点。记得纸上画图!
给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。
返回删除后的链表的头节点。
注意:此题对比原题有改动
示例 1:
输入: head = [4,5,1,9], val = 5
输出: [4,1,9]
解释: 给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9.
示例 2:
输入: head = [4,5,1,9], val = 1
输出: [4,5,9]
解释: 给定你链表中值为 1 的第三个节点,那么在调用了你的函数之后,该链表应变为 4 -> 5 -> 9.
说明:
题目保证链表中节点的值互不相同
若使用 C 或 C++ 语言,你不需要 free 或 delete 被删除的节点
思路
构建头部 dummy 节点,(一个指针操作)
后面的操作就可以转化为一般化得链表节点移除问题。
只用了一个指针
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* deleteNode(ListNode* head, int val) {
ListNode* dummy=new ListNode(0); //新建一个节点
dummy->next=head;
ListNode* pre=dummy;
while(pre && pre->next){ //注意里面条件,考虑到尾节点
if(pre->next->val==val){//注意“==”
pre->next=pre->next->next;//跨过要删除的节点
}
pre=pre->next;
}
return dummy->next;
}
};
或者:
ListNode* deleteNode(ListNode* head, int val) {
ListNode* dummy=new ListNode(0);
dummy->next=head;
ListNode* tmp=dummy;
while(tmp->next){
if(tmp->next->val==val){
tmp->next=tmp->next->next;
break;
}
tmp=tmp->next;
}
return dummy->next;
}
思路同上,新建一个节点,双指针操作
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* deleteNode(ListNode* head, int val) {
ListNode* dummy=new ListNode(0);
dummy->next=head;
ListNode* pre=dummy; //定义一前一后节点
ListNode* cur=head;
while(cur){
if(cur->val==val){
pre->next=cur->next;
break;//不写也行
}
pre=cur;
cur=cur->next;
}
return dummy->next;
}
};
关于是否建立一个头部 dummy 节点。个人理解:像第(5)题,单纯删除一个节点,可能第一个节点也要删除,所以建立一个比它靠前的节点。
像下面的第(6)题,删除重复的节点,可以不用管第一个节点,不用考虑第一个节点是否需要删除。因为即使第一第二个节点相同,直接删第二个就行。
但建立不建立,不是必须的。
它们的共同点,都需要有一个while循环来驱使指针前进。
☺☺☺
(6)LC83. 删除排序链表中的重复元素Ⅰ
给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次。
示例 1:
输入: 1->1->2
输出: 1->2
示例 2:
输入: 1->1->2->3->3
输出: 1->2->3
法1:直接法(一个指针操作)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
//一个指针
ListNode* p=head;
while(p && p->next){
if(p->val==p->next->val){
p->next=p->next->next;
} //这样else的原因是有这种情况: 1 1 1 ,每次都判断一下
else p=p->next;
}
return head;
}
};
法2:双指针,,没有定义新节点
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if(head==NULL)
return head;
//双指针
ListNode* pre=head; //定义一个慢指针
ListNode* cur=head->next; //定义一个快指针
while(pre->next!=NULL){
if(pre->val==cur->val){ //元素相等
pre->next=cur->next; //跨过一个元素
cur=cur->next; //移动指针
}
else{ //注意if else 对立关系
pre=cur;
cur=cur->next;
}
}
return head;
}
};
☺☺☺
(7)LC82. 删除排序链表中的重复元素 II 【中等】
给定一个排序链表,删除所有含有重复数字的节点,只保留原始链表中 没有重复出现 的数字。
示例 1:
输入: 1->2->3->3->4->4->5
输出: 1->2->5
示例 2:
输入: 1->1->1->2->3
输出: 2->3
法1:双指针。新建一个头节点,因为第一个节点也有可能删除。
法1比法2好理解!
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (!head || !head->next)
return head;
ListNode* dummy = new ListNode(-1);
dummy->next = head;
ListNode* pre = dummy;
ListNode* cur = head;
while (cur && cur->next) {
if (cur->val == cur->next->val) {
while (cur->next && cur->val == cur->next->val) {
cur = cur->next;
}
pre->next = cur->next;
cur = cur->next;
} else {
pre = cur;
cur = cur->next;
}
}
return dummy->next;
}
};
法2:双指针(方法同上)
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};
*/
class Solution {
public:
ListNode* deleteDuplication(ListNode* pHead)
{
if (pHead==NULL){
return NULL;
}
ListNode* pre=new ListNode(1); //新建一个头结点,括号里面任何数字都可以(分配一个数的大小)
ListNode* p=pre;
ListNode* q=pHead;
pre->next=pHead;
while(q!=NULL && q->next!=NULL){
int i=0;
while(q->next->val==q->val && q->next!=NULL){
q=q->next;
i++;//用多少个重复的
}
if(i==0)
p=q;//保证第一个指针向右移
else
p->next=q->next; //如果重复,直接跳掉q值相同的后面
q=q->next;//q始终用移动
}
return pre->next;
}
};
☺☺☺
(8)剑指22. 链表中倒数第k个节点
输入一个链表,输出该链表中倒数第k个节点。为了符合大多数人的习惯,本题从1开始计数,即链表的尾节点是倒数第1个节点。例如,一个链表有6个节点,从头节点开始,它们的值依次是1、2、3、4、5、6。这个链表的倒数第3个节点是值为4的节点。
示例:
给定一个链表: 1->2->3->4->5, 和 k = 2.
返回链表 4->5.
法2:双指针(快慢指针)快慢指针,先让fast比slow多走k步,然后一起走,当fast到尾部时,slow就是所求的倒数第k 个节点。
就像一个固定尺寸的尺子移动一样。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* getKthFromEnd(ListNode* pListHead, int k) {
if (pListHead==NULL || k==0){
return NULL;
}
ListNode* fast=pListHead;
ListNode* slow=pListHead;
for( int i=1;i<k;i++){ //从1开始好理解 //刚开始pA已经指向了头结点,走k-1步就行了
if(fast->next!=NULL){
fast=fast->next;
}
}
while(fast->next!=NULL){
fast=fast->next;//一起走
slow=slow->next;
}
return slow;
}
};
法1:倒数第k个节点,转化为正数第几个节点
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* getKthFromEnd(ListNode* head, int k) {
int len=0;
ListNode* p=head;
while(p!=NULL){ //计算链表的长度
len++;
p=p->next;
}
int r=len-k+1; //从倒数第k个节点,推导出正数第几个节点
p=head; //指针重新指向头节点
for(int i=1; i<r; i++){ //让指向指向第r个节点
p=p->next;
}
return p; //返回指向第r个节点的指针
}
};
☺☺☺
(9)19. 删除链表的倒数第N个节点【中等】
给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
示例:
给定一个链表: 1->2->3->4->5, 和 n = 2.
当删除了倒数第二个节点后,链表变为 1->2->3->5.
说明:
给定的 n 保证是有效的。
进阶:
你能尝试使用一趟扫描实现吗?
双指针
**解题思路
解题思路与官方所给方法相同,使用两个指针分别指向头节点和第n个节点,当后一个指针到达最后一个节点时,第一个指针正好位于倒数第n+1个节点处,删除第一个指针的下一个结点即可。
**
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* first = new ListNode(0);
first->next = head; //添加头节点,便于操作
ListNode* ptr = first; //搜索节点
ListNode* current = first; //中间节点
for (int i = 0; i < n; i++)//将该指针指第n个节点
{
current = current->next;
}
while (current->next != NULL) //到达最后一个节点
{
ptr = ptr->next;
current = current->next;
}
ListNode* p = ptr->next; //新建一个p是因为要释放p 否则 ptr->next = p->next->next; 即可
ptr->next = p->next; //删除ptr指向节点
delete p; //释放空间
return first->next;
}
};
☺☺☺
(10)剑指52. 两个链表的第一个公共节点(LC161)
输入两个链表,找出它们的第一个公共节点。
示例 1:
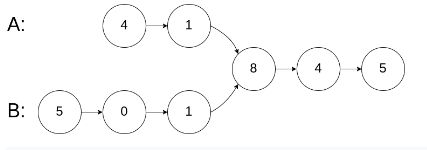
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Reference of the node with value = 8
输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 3:

输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
输入解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
解释:这两个链表不相交,因此返回 null。
法2 太浪漫了 两个结点不断的去对方的轨迹中寻找对方的身影,只要二人有交集,就终会相遇❤
我们使用两个指针 node1,node2 分别指向两个链表 headA,headB 的头结点,然后同时分别逐结点遍历,当 node1 到达链表 headA 的末尾时,重新定位到链表 headB 的头结点;当 node2 到达链表 headB 的末尾时,重新定位到链表 headA 的头结点。这样,当它们相遇时,所指向的结点就是第一个公共结点。
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if(!headA || !headB) return nullptr;
ListNode* p1 = headA, * p2 = headB;
while(p1 != p2) {
if(p1) p1=p1->next;
else p1=headB;
if(p2) p2=p2->next;
else p2=headA;
}
return p1;
}
};
法1
思路:找出2个链表的长度,然后让长的先走两个链表的长度差,然后再一起走;
第一个公共点之后的next都是一样的,所以必然有公共的尾部;;
原来公共结点的意思是两个链表相遇之后后面都是一样的,我还以为是交叉的两个链表
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2) {
int length1=GetLength(pHead1);
int length2=GetLength(pHead2);
ListNode* pNode1=pHead1;
ListNode* pNode2=pHead2;
int lengthDif=0;
if(length1>=length2){//如果第一个链表比第二个链表长
lengthDif=length1-length2; //求出长度差
for(int i=0;i<lengthDif;i++) //让两者起步相同
pNode1=pNode1->next;
}
if(length1<length2){//如果第一个链表比第二个链表短
lengthDif=length2-length1; //求出长度差
for(int i=0;i<lengthDif;i++)
pNode2=pNode2->next;
}
//之前有bug
while((pNode1!=nullptr)&&(pNode2!=nullptr)&&(pNode1!=pNode2)){ //注意不是:pNode1->val!=pNode2->val ,值相等不代表是同一个节点
// if(pNode1->val==pNode2->val)
// return pNode1;
pNode1=pNode1->next;
pNode2=pNode2->next;
}
ListNode* pCommonNode=pNode1;
return pCommonNode;
}
int GetLength(ListNode* pHead){ //求长度的函数
ListNode* pNode=pHead;
int length=0;
while(pNode!=nullptr){
length++;
pNode=pNode->next;
}
return length;
}
};
☺☺☺
(11)剑指23:链表中环的入口节点【中等】(LC142)
题目描述
给一个链表,若其中包含环,请找出该链表的环的入口结点,否则,输出null。
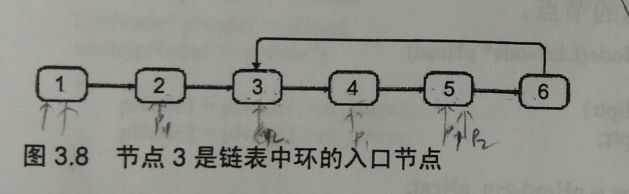
双指针
先说个定理:两个指针一个fast、一个slow同时从一个链表的头部出发fast一次走2步,slow一次走一步,如果该链表有环,两个指针必然在环内相遇,此时只需要把其中的一个指针重新指向链表头部,另一个不变(还在环内),这次两个指针一次走一步,相遇的地方就是入口节点。
为什么必然在环内相遇?假如该链表是循环链表,那我们可以定义两个指针,一个每次向前移动两个节点,另一个每次向前移动一个节点。这就和田径比赛是一样的,假如这两个运动员跑的是直道,那快的运动员和慢的运动员在起点位于同一位置,但快的运动员必将先到达终点,期间这两个运动员不会相遇。而如果绕圈跑的话(假设没有米数限制),跑的快的运动员在超过跑的慢的运动员一圈的时候,他们将会相遇,此刻就是循环链表。
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode* fast=head;
ListNode* low=head;
while(fast && fast->next){
fast=fast->next->next;
low=low->next;
if(fast==low){
low=head;//low从链表头出发
while(fast!=low){//fast从相遇点出发
fast=fast->next;
low=low->next;
}
return low;
}
}
return NULL;//一定得写
}
};
如果仅仅判断是否存在环(LC141)
定理:两个指针一个fast、一个slow同时从一个链表的头部出发fast一次走2步,slow一次走一步,如果该链表有环,两个指针必然在环内相遇,
class Solution {
public:
bool hasCycle(ListNode *pHead) {
ListNode*fast=pHead,*low=pHead;
while(fast&&fast->next){ //一定要写这两个条件
fast=fast->next->next;
low=low->next;
if(fast==low) //注意==
return true;
}
return false;
}
};
** 不能犯错:while(fast!=low)。因为一开始它们就不一样!进不去循环的。**
☺☺☺
以下连续3道题运用相同的代码块(归并排序?)
(12)剑指25. 合并两个排序的链表(LC21)
传说中的归并排序?
输入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的。
示例1:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
思路:新建一个头节点
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* pHead1, ListNode* pHead2) {
if(pHead1==NULL&&pHead2!=NULL)return pHead2;
if(pHead2==NULL&&pHead1!=NULL)return pHead1;
if(pHead2==NULL&&pHead1==NULL)return NULL;
ListNode* head=new ListNode(1);//头结点前面附加一结点(当原链表头结点可能会变化时都可以考虑新建
ListNode* root=head;//新链表结点指针
while(pHead1!=NULL&&pHead2!=NULL){
if(pHead1->val<pHead2->val){ //比较l1和l2各结点大小,归并
head->next=pHead1;
head=head->next;
pHead1=pHead1->next;
}
else{
head->next=pHead2;
head=head->next;
pHead2=pHead2->next;
}
}
if(pHead1==NULL){//处理剩余结点
head->next=pHead2;
}
if(pHead2==NULL){
head->next=pHead1;
}
return root->next;//返回头结点指针
}
};
☺☺☺
(13)23. 合并K个排序链表
基于合并2个排序链表
合并 k 个排序链表,返回合并后的排序链表。请分析和描述算法的复杂度。
示例:
输入:
[
1->4->5,
1->3->4,
2->6
]
输出: 1->1->2->3->4->4->5->6
思路:基于合并两个链表,取第一个链表与第二个链表合并,然后将合并的链表再与第三个链表合并,依次类型。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
int size = lists.size();
if (size == 0) {
return nullptr;
}
if (size == 1) {
return lists[0];
}
ListNode *p = lists[0];
for (int i = 1; i < size; ++i) {
p = mergeTwoLists(p, lists[i]);
}
return p;
}
ListNode* mergeTwoLists(ListNode* pHead1, ListNode* pHead2) {
ListNode* head=new ListNode(1);//头结点前面附加一结点(当原链表头结点可能会变化时都可以考虑新建
ListNode* root=head;//新链表结点指针
while(pHead1!=NULL&&pHead2!=NULL){
if(pHead1->val<pHead2->val){
head->next=pHead1;
head=head->next;
pHead1=pHead1->next;
}
else{
head->next=pHead2;
head=head->next;
pHead2=pHead2->next;
}
}
if(pHead1==NULL){//处理剩余结点
head->next=pHead2;
}
if(pHead2==NULL){
head->next=pHead1;
}
return root->next;//返回头结点指针
}
};
☟ tip:找到一个链表中间节点的方法,慢指针走1步,快指针走2步;当快指针走到尾,慢指针走到中间。
ListNode *slow = head, *fast = head, *pre = head;
while (fast && fast->next){
pre = slow;
slow = slow->next;
fast = fast->next->next;
}//退出循环时,fast或fast->next = nullptr,slow指向中部位置
pre->next = NULL; //将左右子链表断开处理
☺☺☺
(14)148. 排序链表【中等】
在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序。
示例 1:
输入: 4->2->1->3
输出: 1->2->3->4
示例 2:
输入: -1->5->3->4->0
输出: -1->0->3->4->5
思路
利用归并的思想,递归地将当前链表分为两段,然后mergeTwoLists,
分两段的方法是使用 fast-slow 法,用两个指针,一个每次走两步,一个走一步,知道快的走到了末尾,然后慢的所在位置就是中间位置,这样就分成了两段。
* 主要考察3个知识点,
* 知识点1:归并排序的整体思想
* 知识点2:找到一个链表的中间节点的方法
* 知识点3:合并两个已排好序的链表为一个新的有序链表
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* sortList(ListNode* head) {
if (!head || !head->next) return head;
ListNode *slow = head, *fast = head, *pre = head;
while (fast && fast->next){
pre = slow;
slow = slow->next;
fast = fast->next->next;
}//退出循环时,fast或fast->next = nullptr,slow指向中部位置
pre->next = NULL; //将左右子链表断开处理
ListNode* l=sortList(head); //这2步使用递归,画个图就明白
ListNode* r=sortList(slow);
return mergeTwoLists(l, r);
}
ListNode* mergeTwoLists(ListNode* pHead1, ListNode* pHead2) {
if(pHead1==NULL&&pHead2!=NULL)return pHead2;
if(pHead2==NULL&&pHead1!=NULL)return pHead1;
if(pHead2==NULL&&pHead1==NULL)return NULL;
ListNode* head=new ListNode(1);//头结点前面附加一结点(当原链表头结点可能会变化时都可以考虑新建
ListNode* root=head;//新链表结点指针
while(pHead1!=NULL&&pHead2!=NULL){
if(pHead1->val<pHead2->val){
head->next=pHead1;
head=head->next;
pHead1=pHead1->next;
}
else{
head->next=pHead2;
head=head->next;
pHead2=pHead2->next;
}
}
if(pHead1==NULL){//处理剩余结点
head->next=pHead2;
}
if(pHead2==NULL){
head->next=pHead1;
}
return root->next;//返回头结点指针
}
};
☺☺☺
(15)剑指35. 复杂链表的复制【中等】(LC138)
有点难,记住思路算了!
题目描述
输入一个复杂链表(每个节点中有节点值,以及两个指针,一个指向下一个节点,另一个特殊指针指向任意一个节点),返回结果为复制后复杂链表的head。(注意,输出结果中请不要返回参数中的节点引用,否则判题程序会直接返回空)
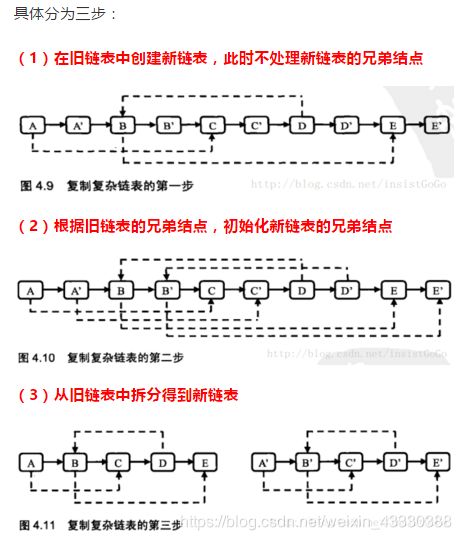
思路
三步法
/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution {
public:
//总的函数三步合一
Node* copyRandomList(Node* pHead){
CloneNodes(pHead);
ConnectRandomNodes(pHead);
return ReConnectNodes(pHead);
}
//第一步:复制结点与next指针
//复制原始链表的任一节点N并创建新节点N',再把N'链接到N的后边
void CloneNodes(Node* pHead){
Node* pNode=pHead;
while(pNode!=NULL){
Node* pCloned=new Node(0);
pCloned->val=pNode->val;
pCloned->next=pNode->next;
pCloned->random=NULL;
pNode->next=pCloned;
pNode=pCloned->next;
}
}
//第二步:复制random指针
//如果原始链表上的节点N的random指向S,则对应的复制节点N'的random指向S的下一个节点S'
void ConnectRandomNodes(Node* pHead){
Node* pNode=pHead;
while(pNode!=NULL){
Node* pCloned=pNode->next;
if(pNode->random!=NULL)
pCloned->random=pNode->random->next;
pNode=pCloned->next;
}
}
//第三步:拆分链表
//把得到的链表拆成两个链表,奇数位置上的结点组成原始链表,偶数位置上的结点组成复制出来的链表
Node* ReConnectNodes(Node* pHead){
Node* pNode=pHead;
Node* pClonedHead=NULL;
Node* pClonedNode=NULL;
//初始化
if(pNode!=NULL){
pClonedHead=pClonedNode=pNode->next;
pNode->next=pClonedNode->next;
pNode=pNode->next;
}
//循环
while(pNode!=NULL){
pClonedNode->next=pNode->next;
pClonedNode=pClonedNode->next;
pNode->next=pClonedNode->next;
pNode=pNode->next;
}
return pClonedHead;
}
};
☺☺☺
(16)2. 两数相加【中等】
给出两个 非空 的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。
您可以假设除了数字 0 之外,这两个数都不会以 0 开头
示例:
输入:(2 -> 4 -> 3) + (5 -> 6 -> 4)
输出:7 -> 0 -> 8
原因:342 + 465 = 807
其实不用思考从哪边开始,看那个输出结果,就是从左往右,进位在右边。
** h->next=new ListNode(1);**
ListNode(1)里的数字是几,就是新建一个为几的节点。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
ListNode* head=new ListNode(-1);//存放结果的链表
ListNode* h=head;//移动指针
int sum=0;//每个位的加和结果
bool carry=false;//进位标志
while(l1!=NULL||l2!=NULL)
{
sum=0;
if(l1!=NULL)
{
sum+=l1->val;
l1=l1->next;
}
if(l2!=NULL)
{
sum+=l2->val;
l2=l2->next;
}
if(carry) //是否有进位
sum++;
h->next=new ListNode(sum%10);
h=h->next;
carry=sum>=10?true:false;
}
if(carry) //处理最后一个进位
{
h->next=new ListNode(1);
}
return head->next;
}
};
☺☺☺
(17)328. 奇偶链表【中等】
给定一个单链表,把所有的奇数节点和偶数节点分别排在一起。请注意,这里的奇数节点和偶数节点指的是节点编号的奇偶性,而不是节点的值的奇偶性。请尝试使用原地算法完成。你的算法的空间复杂度应为 O(1),时间复杂度应为 O(nodes),nodes 为节点总数。
示例 1:
输入: 1->2->3->4->5->NULL
输出: 1->3->5->2->4->NULL
示例 2:
输入: 2->1->3->5->6->4->7->NULL
输出: 2->3->6->7->1->5->4->NULL
说明:
应当保持奇数节点和偶数节点的相对顺序。
链表的第一个节点视为奇数节点,第二个节点视为偶数节点,以此类推。
问题:在链表中,将所有奇数序号的结点放到前面,偶数序号的结点放在后面,要求就地解决
与问题“调整数组中奇数偶数顺序”区别在于前者调整结点,而后者调整的是值
O(n),O(1)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* oddEvenList(ListNode* head) {
if(!head) return head;
ListNode* odd = head; //奇数序列结点指针与头指针
ListNode* evenhead = head->next,*even = evenhead; //偶数序列结点指针与头指针
while(even && even->next){//偶数序列指针判断(循环时一般用后面的指针来判断是否结束循环) 对于走两步的指针p均需要判断p与p->next是否为空
odd->next = odd->next->next; //连接奇数序列结点,每次走两步 ,先连接前面的指针
even->next = even->next->next;//连接偶数序列结点
odd = odd->next; //指向下一个奇结点
even = even->next;
}
odd->next = evenhead; //连接奇序列链表和偶序列链表
return head;
}
};
☺☺☺
(18)234. 回文链表
请判断一个链表是否为回文链表。
示例 1:
输入: 1->2
输出: false
示例 2:
输入: 1->2->2->1
输出: true
法1:将链表的值放入数组中,然后在数组中采用双指针比较。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
bool isPalindrome(ListNode* head) {
if(head==NULL) return true;
if(head->next==NULL)return true;
ListNode *i=head;
vector<int> val;
//将链表值放入数组
while(i!=NULL){
val.push_back(i->val);
i=i->next;
}
int m=0,n=val.size()-1;
while(m<n){
if(val[m]!=val[n]) //前后移动比较
return false;
m++;
n--;
}
return true;
}
};
法2:用快慢指针法找到链表中部位置,然后翻转右半链表,判断右边链表与左边链表是否相等
发现有些题就是一些基础题的组合。比如这道题里面的定位到中心呀,翻转链表呀,都是前面题里面出现过的。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
bool isPalindrome(ListNode* head) {
if (!head || !head->next) return true; //异常情况处理,为空结点或者一个结点时
ListNode *slow = head, *fast = head;
while (fast && fast->next){//快慢指针法,让slow指向链表中部位置
slow = slow->next;
fast = fast->next->next;
} //退出时,fast为最后一个结点或者null,slow处在中间位置(与结点数有关,左子链表head~slow-1, 右子链表为slow~end,右子链表比左子链表长一或者相等)
//2个链表不断开也行,和上面(14)题一样,断开也行,不影响。
ListNode* right = reverseList(slow);//反转右边链表
ListNode* left = head;
while(left && right){//比较左右子链表是否相等
if(left->val == right->val){
left = left->next;
right = right->next;
}
else return false;
}
return true;
}
//函数:反转链表
ListNode* reverseList(ListNode* head) {
ListNode* tmp = NULL;
while (head!=NULL)
{
ListNode* pnext = head->next; //定义一个pnext指向head的下一个节点
head->next = tmp; //改变指向
tmp = head; //移动tmp
head = pnext; //移动head
}
return tmp;
}
};