【Pytorch教程】:DQN 强化学习
Pytorch教程目录
Torch and Numpy
变量 (Variable)
激励函数
关系拟合(回归)
区分类型 (分类)
快速搭建法
批训练
加速神经网络训练
Optimizer优化器
卷积神经网络 CNN
卷积神经网络(RNN、LSTM)
RNN 循环神经网络 (分类)
RNN 循环神经网络 (回归)
自编码 (Autoencoder)
DQN 强化学习
生成对抗网络 (GAN)
为什么 Torch 是动态的
GPU 加速运算
过拟合 (Overfitting)
批标准化 (Batch Normalization)
目录
- Pytorch教程目录
- 什么是 DQN
-
- 强化学习与神经网络
- 神经网络的作用
- 更新神经网络
- DQN 两大利器
- DQN 强化学习
-
- 模块导入和参数设置
- 神经网络
- DQN体系
- 训练
- 全部代码
什么是 DQN
强化学习中的一种强大武器, Deep Q Network 简称为 DQN. Google Deep mind 团队就是靠着这 DQN 使计算机玩电动玩得比我们还厉害.
强化学习与神经网络
之前我们所谈论到的强化学习方法都是比较传统的方式, 而如今, 随着机器学习在日常生活中的各种应用, 各种机器学习方法也在融汇, 合并, 升级. 而我们今天所要探讨的强化学习则是这么一种融合了神经网络和 Q learning 的方法, 名字叫做 Deep Q Network. 这种新型结构是为什么被提出来呢? 原来, 传统的表格形式的强化学习有这样一个瓶颈.
神经网络的作用
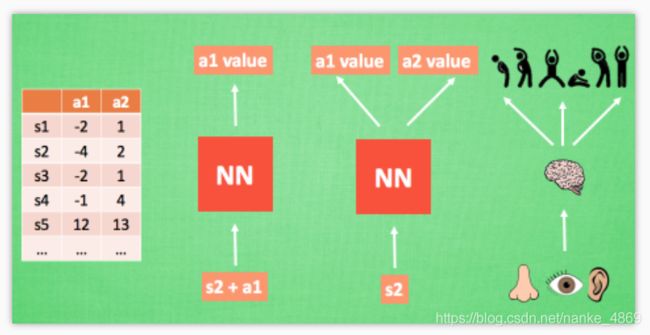
我们使用表格来存储每一个状态 state, 和在这个 state 每个行为 action 所拥有的 Q 值. 而当今问题是在太复杂, 状态可以多到比天上的星星还多(比如下围棋). 如果全用表格来存储它们, 恐怕我们的计算机有再大的内存都不够, 而且每次在这么大的表格中搜索对应的状态也是一件很耗时的事.
不过, 在机器学习中, 有一种方法对这种事情很在行, 那就是神经网络. 我们可以将状态和动作当成神经网络的输入, 然后经过神经网络分析后得到动作的 Q 值, 这样我们就没必要在表格中记录 Q 值, 而是直接使用神经网络生成 Q 值.
还有一种形式是这样, 我们只输入状态值, 输出所有的动作值, 然后按照 Q learning 的原则, 直接选择拥有最大值的动作当做下一步要做的动作. 我们可以想象, 神经网络接受外部的信息, 相当于眼睛鼻子耳朵收集信息, 然后通过大脑加工输出每种动作的值, 最后通过强化学习的方式选择动作.
更新神经网络

接下来我们基于第二种神经网络来分析
我们知道, 神经网络是要被训练才能预测出准确的值. 那在强化学习中, 神经网络是如何被训练的呢?
- 首先, 我们需要 a1, a2 正确的Q值, 这个 Q 值我们就用之前在 Q learning 中的
Q 现实来代替. - 同样我们还需要一个
Q 估计来实现神经网络的更新. 所以神经网络的参数就是 新 N N = 老 N N + α ( Q 现 实 − Q 估 计 ) 新NN=老NN+\alpha(Q现实-Q估计) 新NN=老NN+α(Q现实−Q估计)

-
我们通过 NN 预测出
Q(s2, a1)和Q(s2,a2)的值, 这就是Q 估计. 然后我们选取Q 估计中最大值的动作来换取环境中的奖励 reward. -
而
Q 现实中也包含从神经网络分析出来的两个 Q 估计值, 不过这个Q 估计是针对于下一步在 s’ 的估计. -
最后再通过刚刚所说的算法更新神经网络中的参数.
但是这并不是 DQN 会玩电动的根本原因. 还有两大因素支撑着 DQN 使得它变得无比强大. 这两大因素就是 Experience replay 和 Fixed Q-targets.
DQN 两大利器

简单来说, DQN 有一个记忆库用于学习之前的经历. Q learning 是一种 off-policy 离线学习法, 它能学习当前经历着的, 也能学习过去经历过的, 甚至是学习别人的经历.
所以每次 DQN 更新的时候, 我们都可以随机抽取一些之前的经历进行学习. 随机抽取这种做法打乱了经历之间的相关性, 也使得神经网络更新更有效率.
Fixed Q-targets 也是一种打乱相关性的机理, 如果使用 fixed Q-targets, 我们就会在 DQN 中使用到两个结构相同但参数不同的神经网络, 预测 Q 估计 的神经网络具备最新的参数, 而预测 Q 现实 的神经网络使用的参数则是很久以前的. 有了这两种提升手段, DQN 才能在一些游戏中超越人类.
DQN 强化学习
模块导入和参数设置
这次除了 Torch 自家模块, 我们还要导入 Gym 环境库模块
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import gym
# 超参数
BATCH_SIZE = 32
LR = 0.01 # learning rate
EPSILON = 0.9 # 最优选择动作百分比
GAMMA = 0.9 # 奖励递减参数
TARGET_REPLACE_ITER = 100 # Q 现实网络的更新频率
MEMORY_CAPACITY = 2000 # 记忆库大小
env = gym.make('CartPole-v0') # 立杆子游戏
env = env.unwrapped
N_ACTIONS = env.action_space.n # 杆子能做的动作
N_STATES = env.observation_space.shape[0] # 杆子能获取的环境信息数
神经网络
DQN 当中的神经网络模式, 我们将依据这个模式建立两个神经网络, 一个是现实网络 (Target Net), 一个是估计网络 (Eval Net).
class Net(nn.Module):
def __init__(self, ):
super(Net, self).__init__()
self.fc1 = nn.Linear(N_STATES, 10)
self.fc1.weight.data.normal_(0, 0.1) # initialization
self.out = nn.Linear(10, N_ACTIONS)
self.out.weight.data.normal_(0, 0.1) # initialization
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
actions_value = self.out(x)
return actions_value
DQN体系
简化的 DQN 体系是这样, 我们有两个 net, 有选动作机制, 有存经历机制, 有学习机制.
class DQN(object):
def __init__(self):
# 建立 target net 和 eval net 还有 memory
def choose_action(self, x):
# 根据环境观测值选择动作的机制
return action
def store_transition(self, s, a, r, s_):
# 存储记忆
def learn(self):
# target 网络更新
# 学习记忆库中的记忆
接下来就是具体的啦, 在 DQN 中每个功能都是怎么做的.
class DQN(object):
def __init__(self):
self.eval_net, self.target_net = Net(), Net()
self.learn_step_counter = 0 # 用于 target 更新计时
self.memory_counter = 0 # 记忆库记数
self.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2)) # 初始化记忆库
self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR) # torch 的优化器
self.loss_func = nn.MSELoss() # 误差公式
def choose_action(self, x):
x = torch.unsqueeze(torch.FloatTensor(x), 0)
# 这里只输入一个 sample
if np.random.uniform() < EPSILON: # 选最优动作
actions_value = self.eval_net.forward(x)
action = torch.max(actions_value, 1)[1].data.numpy()[0, 0] # return the argmax
else: # 选随机动作
action = np.random.randint(0, N_ACTIONS)
return action
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, [a, r], s_))
# 如果记忆库满了, 就覆盖老数据
index = self.memory_counter % MEMORY_CAPACITY
self.memory[index, :] = transition
self.memory_counter += 1
def learn(self):
# target net 参数更新
if self.learn_step_counter % TARGET_REPLACE_ITER == 0:
self.target_net.load_state_dict(self.eval_net.state_dict())
self.learn_step_counter += 1
# 抽取记忆库中的批数据
sample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE)
b_memory = self.memory[sample_index, :]
b_s = torch.FloatTensor(b_memory[:, :N_STATES])
b_a = torch.LongTensor(b_memory[:, N_STATES:N_STATES+1].astype(int))
b_r = torch.FloatTensor(b_memory[:, N_STATES+1:N_STATES+2])
b_s_ = torch.FloatTensor(b_memory[:, -N_STATES:])
# 针对做过的动作b_a, 来选 q_eval 的值, (q_eval 原本有所有动作的值)
q_eval = self.eval_net(b_s).gather(1, b_a) # shape (batch, 1)
q_next = self.target_net(b_s_).detach() # q_next 不进行反向传递误差, 所以 detach
q_target = b_r + GAMMA * q_next.max(1)[0] # shape (batch, 1)
loss = self.loss_func(q_eval, q_target)
# 计算, 更新 eval net
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
训练
按照 Qlearning 的形式进行 off-policy 的更新. 我们进行回合制更行, 一个回合完了, 进入下一回合. 一直到他们将杆子立起来很久.
dqn = DQN() # 定义 DQN 系统
for i_episode in range(400):
s = env.reset()
while True:
env.render() # 显示实验动画
a = dqn.choose_action(s)
# 选动作, 得到环境反馈
s_, r, done, info = env.step(a)
# 修改 reward, 使 DQN 快速学习
x, x_dot, theta, theta_dot = s_
r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
r = r1 + r2
# 存记忆
dqn.store_transition(s, a, r, s_)
if dqn.memory_counter > MEMORY_CAPACITY:
dqn.learn() # 记忆库满了就进行学习
if done: # 如果回合结束, 进入下回合
break
s = s_
全部代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import gym
# Hyper Parameters
BATCH_SIZE = 32
LR = 0.01 # learning rate
EPSILON = 0.9 # greedy policy
GAMMA = 0.9 # reward discount
TARGET_REPLACE_ITER = 100 # target update frequency
MEMORY_CAPACITY = 2000
env = gym.make('CartPole-v0')
env = env.unwrapped
N_ACTIONS = env.action_space.n
N_STATES = env.observation_space.shape[0]
ENV_A_SHAPE = 0 if isinstance(env.action_space.sample(), int) else env.action_space.sample().shape # to confirm the shape
class Net(nn.Module):
def __init__(self, ):
super(Net, self).__init__()
self.fc1 = nn.Linear(N_STATES, 50)
self.fc1.weight.data.normal_(0, 0.1) # initialization
self.out = nn.Linear(50, N_ACTIONS)
self.out.weight.data.normal_(0, 0.1) # initialization
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
actions_value = self.out(x)
return actions_value
class DQN(object):
def __init__(self):
self.eval_net, self.target_net = Net(), Net()
self.learn_step_counter = 0 # for target updating
self.memory_counter = 0 # for storing memory
self.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2)) # initialize memory
self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR)
self.loss_func = nn.MSELoss()
def choose_action(self, x):
x = torch.unsqueeze(torch.FloatTensor(x), 0)
# input only one sample
if np.random.uniform() < EPSILON: # greedy
actions_value = self.eval_net.forward(x)
action = torch.max(actions_value, 1)[1].data.numpy()
action = action[0] if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE) # return the argmax index
else: # random
action = np.random.randint(0, N_ACTIONS)
action = action if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE)
return action
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, [a, r], s_))
# replace the old memory with new memory
index = self.memory_counter % MEMORY_CAPACITY
self.memory[index, :] = transition
self.memory_counter += 1
def learn(self):
# target parameter update
if self.learn_step_counter % TARGET_REPLACE_ITER == 0:
self.target_net.load_state_dict(self.eval_net.state_dict())
self.learn_step_counter += 1
# sample batch transitions
sample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE)
b_memory = self.memory[sample_index, :]
b_s = torch.FloatTensor(b_memory[:, :N_STATES])
b_a = torch.LongTensor(b_memory[:, N_STATES:N_STATES+1].astype(int))
b_r = torch.FloatTensor(b_memory[:, N_STATES+1:N_STATES+2])
b_s_ = torch.FloatTensor(b_memory[:, -N_STATES:])
# q_eval w.r.t the action in experience
q_eval = self.eval_net(b_s).gather(1, b_a) # shape (batch, 1)
q_next = self.target_net(b_s_).detach() # detach from graph, don't backpropagate
q_target = b_r + GAMMA * q_next.max(1)[0].view(BATCH_SIZE, 1) # shape (batch, 1)
loss = self.loss_func(q_eval, q_target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
dqn = DQN()
print('\nCollecting experience...')
for i_episode in range(400):
s = env.reset()
ep_r = 0
while True:
env.render()
a = dqn.choose_action(s)
# take action
s_, r, done, info = env.step(a)
# modify the reward
x, x_dot, theta, theta_dot = s_
r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
r = r1 + r2
dqn.store_transition(s, a, r, s_)
ep_r += r
if dqn.memory_counter > MEMORY_CAPACITY:
dqn.learn()
if done:
print('Ep: ', i_episode,
'| Ep_r: ', round(ep_r, 2))
if done:
break
s = s_