A Survey on Vision Transformer(视觉注意力机制的前沿与作用机制分析综述-持续更新)
文章目录
- 摘要
- 一、Tranformer
-
- 1.1Transformer Formulation(结构)
- 二、 Vision Transformer
-
- 2.1 Pure Transformer
- 2.2 Hybrid Model(Transformers with CNN)
- 2.3 关于模型结构的总结
- 三、Tasks for Vision Transformer
-
- 3.1 Self-supervised Representation Learning(自监督)
-
- 3.2 Generative Based Approach(基于通用技术)
- 3.3 Contrastive Learning Based Approach(基于对比学习)
- 3.4 Low level Vision Tasks(代理任务)
-
- 3.4.1 图像生成
- 3.4.2 图像处理
- 3.5 High/Mid level Vision Tasks(高级视觉任务)
-
- 3.5.1 Object detection
- 3.5.2 Segmentation
-
- Transformer用于全景分割
- Transformer用于实例分割
- Transformer用于语义分割
- Transformer用于医学图像分割
- 3.6 Video Processing
- 3.7 Multi-Modal Tasks(多模态任务)
- 3.8 总结
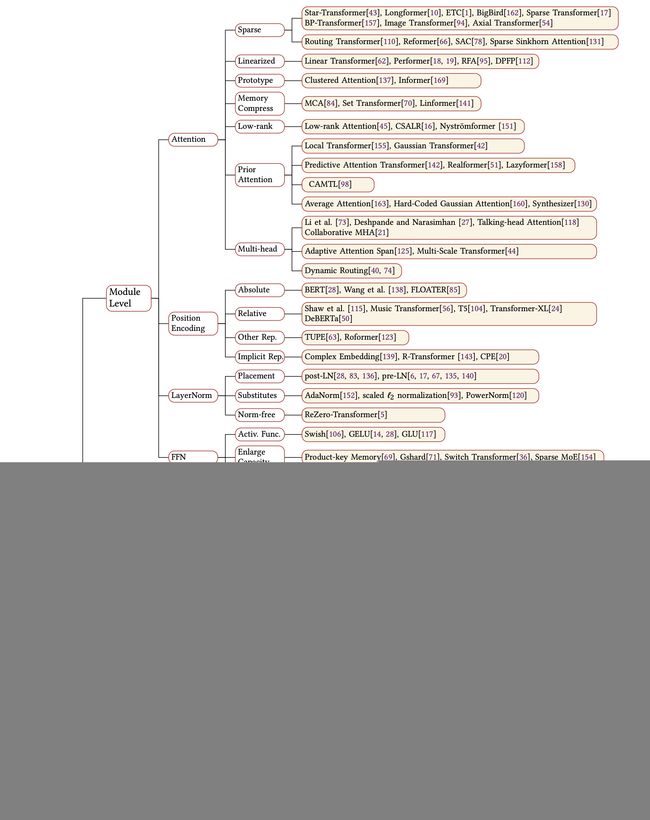
- 四、Efficient Transformer(去除模型冗余度)
-
- 4.1 Pruning and Decomposition(修剪压缩)
- 4.2 Knowledge Distillation(知识蒸馏)
- 4.3 Quantization(量化)
- 4.4 Compact Architecture Design(精巧模型设计)
- 4.5 总结
- 五、Conclusions and Discussion
-
- 5.1 挑战
- 5.2 展望
- 参考文献
摘要

本篇论文由多个在transformer不同领域的牛人一起编写,文章包含以下内容:
- 基本工作原理
- 代理任务(low-level tasks & pretext tasks),中高级视觉任务(mid/high level task)三个任务层级等应用层面上介绍transformer的前沿进展;
- 介绍transformer的结构优化(剪枝/分解/知识蒸馏/模型结构压缩)等加速transformer运算和优化存储的前沿方法;
- 对视觉注意力机制做了总结和期望,并提出了一个问题:
Can transformer obtains satisfactory results with a very simple computational paradigm and massive data training?
我想,这个问题或许已经有答案了,最近的工作MLPMixer通过全连接层达到了很好的效果,加上ConvNet等非注意力机制的模型的亮眼表现,向我们摆出了一个可能的事实:注意力机制并不是一个all you need模型,对于模型的整体结构以及结构内的组件设计,比我们选择什么模型更重要~

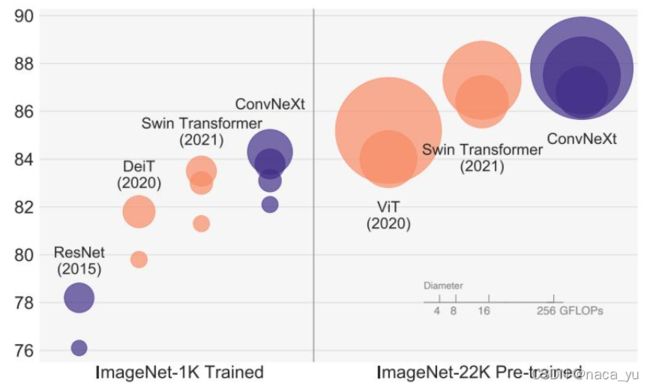
一、Tranformer
下图为本文所提到的各类模型:

1.1Transformer Formulation(结构)

如上图所示attention原理图,左图为注意力机制原理图,右图为多头注意力图,关于注意力机制,这里不再赘述,说说个人对于transformer各个结构的一个理解:
- self-attention机制:通过dot-product计算特征序列之间的相似性生成一个拥有全局视野的特征序列;
- 位置编码(position-embedding):源自NLP中,编码图像的位置信息,可以通过自学习或者cos固定编码获得;
- 多头注意力(multi-head attention):多个独立的attention计算,保证注意力的来源多样性,防止过拟合增加学习能力以提升attension能力,可以看作一种机器学习中的boost方法;
- FFN:维度映射,或用于下游任务;
- Residual Connection:类似于resnet中残差,可以加强信息传播能力(梯度)增加层数;
二、 Vision Transformer

上图为如今常用的视觉任务的backbone,按照基本结构,分为Pure CNN, Pure Transformer, Hybrid Model。

视觉注意力机制:作为代表,ViT结构如上图所示,关于ViT的讲解可看我的另一篇关于ViT的博客【视觉Transformer开山之作:Vision Transformer(ViT)论文解读与复现】
关于Transformer在视觉上的应用,主要有两个方向:一是pure- transformer结构:以 ViT, DeiT等为代表,另一种是以混合结构:CvT, CeiT等论文的工作。
2.1 Pure Transformer
以ViT为代表,其网络结构如上图所示,输入的训练图片以patch形式输入,将图片输出为(N, p² x c)的二维向量序列并加入位置向量,并添加一个分类向量为输入,最后未入(N+1, p² x c)以类似于词向量的形式输入,输出为编码后的特征向量与一个分类向量(class token),ViT虽然实现了从NLP任务到图像任务的直接迁移与去偏置假设化(inductive biases),但是其在imageNet这样偏小的数据集上并不能表现得比CNN好,而是要在更大的数据集上才能显示出优势。原因可能是由于ViT本身需要更多的数据学习CNN归纳偏置的问题。
为了解决ViT的中小数据集表现不佳的问题,DeiT通过知识蒸馏,将Teacher的学习分布教给Student小模型解决了上述问题,改进了传统transformer参数庞大等问题。
针对视觉注意力,有三个改进的方向:一个是增强图像块patch内部的局部性弥补transformer注重全局不足,一个是改进自注意力attension结构,使模型在层数上允许更庞大或者简化注意力计算等更加适合视觉任务,最后就是整体结构设计,如利用NAS或者从CNN结构得到灵感改进传统transformer全局结构设计,组件优化设计。
- 针对局部注意力:transformer在中小目标任务和分割任务等对分辨率要求较高的任务中表现不佳;
改进工作:TNT将patch继续划分为sub-patches,提出transformer-in-transformer architecture计算sub-patches之间的注意力;Twins and CAT交替地执行局部和全局注意力;Swin Transformers通过滑动窗口和二维位置编码提升窗口patch之间的交流,使其更适合做dense prediction的工作;Shuffle Transformer利用spatial shuffle而不是swin transformer的滑动窗口计算patch之间的交互; - 针对attension结构,是注意力机制的核心位置:transformer的注意力是直接从NLP领域完全搬过来的,不一定完全适合图像任务,因此部分工作体现在修改这部分结构。
改进工作:DeepViT提出一种跨head用来生成新的注意力图;KVT使用KNN选取与patch相似性最大的k个token缩小注意力图大小; - 针对整体结构优化:基于pyramid的结构(PVT , HVT , Swin Transformer and PiT),Neural architecture search (NAS)例如Scaling-ViT, ViTAS。
- 堆叠结构:1000层的Transformer-DeepNet
除此之外,其他的一些优化方向:positional encoding, normalization strategy(layer-norm,batch-norm…) , shortcut connection(Residual) and removing attention(对非必要注意力去除)。
总结来说,以上的工作,其一增强其在dense prediction能力通过改进输入patch或者引入特有的不同尺度注意力融合机制;其二建立大型模型:通过缓解transformer堆叠时后面注意力不变化的问题来暴力堆叠layer;其三:对于训练策略的改进:输入编码、归一化方法、注意力失活(类似于dropout)来整体增强。
2.2 Hybrid Model(Transformers with CNN)
以上部分包含了对于transformer局部注意力偏弱的弱点,pure-transformer通过加强局部窗口之间的连接、仿照FPN进行多尺度的融合等方式,加强了局部性。但是除此之外,引入CNN对于加强局部性也是一种可行的方法。
下面是一些混合模型的样例:
- CPVT:视觉 Transformer 受限于固定长度的位置编码,不能像 CNN 一样直接处理不同的输入尺寸,变换图片大小,位置编码和linear-projection就要重新训练,使用深度卷积替代位置编码,可以很容易地推广到比模型在训练期间看到的更长的输入序列。
- CvT, CeiT , LocalViT,CMT:这几篇文章分析了transformer直接迁移到视觉任务的一些缺点,它们都在FFN层后面加入卷积,从而promotes the correlation among neighboring tokens;
- LeViT(a Vision Transformer in ConvNet’s Clothing for Faster Inference):重新审视了CNN的各类结构并尝试应用于transformer中, 在当时top-1精度为80%的情况下LeViT比CPU上的EfficientNet快3.3倍。这篇文章值得一看。
- Visformer:探究transformer和CNN训练的差别之处,相比CNN,transformer需要更长的训练时间和更多的数据增强方法,给出了适应transformer的训练策略;
在混合结构中,主要集中于transformer的embedding部分、patch之间的临近交互等方面,方法主要分为:通过直接添加CNN结构,或者将CNN结构进行适应transformer的改造。通过混合结构,能够兼顾dense prediction任务和converge加速。是混合模型还是pure模型更好,无法比较,pure模型能够拥有良好的泛化性,并且对于这样一种新模型的探索也是必要的,近期的ConvNet通过将transformer的一些策略用于CNN也使CNN”起死回生“。混合结构对于图像领域任务或者部署模型时,其对超参数的鲁棒性,模型参数大小和inference速度等是其独有的优点。
两者的融合,有相近之处,未来极有可能会向着相互参考,不断螺旋上升,这很像马克思中关于事物的发展规律。
2.3 关于模型结构的总结
综合以上模型,我个人认为,CNN对于图像任务具有针对性,如今的各类结构无论是纯Transformer的模型还是混合模型,其实现在都有在借鉴CNN的灵感,最近刷榜的swin-transformer之所以能够在多个分割、检测任务上都表现SOTA,其主要原因和引入了二维位置编码和滑动窗口所致,而这两个改进则引入了ViT作者在避免的归纳偏置问题。
另一方面,由于Transformer结构对于图像的无偏性、参数量偏大等因素,导致了transforme训练时间长、对batch大小和梯度下降方式较为敏感的问题,而通过将embedding替换为CNN结构,较快的收敛速度并且对超参数减弱敏感性,这些在Visformer一文中有提出具体的论证。
三、Tasks for Vision Transformer
3.1 Self-supervised Representation Learning(自监督)
自监督学习,是最近的一个热门方向,其主要通过一种自监督的方式,将不带有标签的大量数据自行学习,通过代理任务学习样本丰富的特征以抽取样本的主要信息,从而达到在非人工标注下使模型学习的目的,同时模型具有良好的迁移性和扩展性。
3.2 Generative Based Approach(基于通用技术)
以iGPT为代表,iGPT和ViT类模型的区别主要体现在三个方面。1)iGPT的输入是通过对像素进行聚类的图像块序列,而ViT则是将图像统一划分为若干个patch;2)iGPT的架构是一个编码器-解码器框架,而ViT只有多个编码器;3)iGPT利用自动回归自监督损失进行训练,而ViT则通过监督图像分类任务进行训练。
3.3 Contrastive Learning Based Approach(基于对比学习)
对比学习属于自监督学习的一种,通过代理任务,使模型通过样本对比完成对样本属性的信息深层挖掘,从而完成对样本属性的字典建立,即对样本特征描述的关键词,对比学习重要性在与词典的一致性和全面性,扩展性。
尽管标准卷积网络的训练方法已经非常成熟和强大,但ViT的方法尚未建立,尤其是在自监督的情况下,训练变得更具挑战性,同时探究 ViT 训练不稳定的问题,在这种背景下,MoCo v3被提出以解决这个问题。
MoCo v3(Momentum Contrastive),是其中的代表,它主要讲的是ViT如何进行自监督训练,它改进了MoCo,作者提出了很多改进transformer无监督训练时稳定性提高的方法:如不训练 ViT 的 patch projection 层;为省去 lr search 的麻烦,建议直接用 AdamW;batch size > 2048 时训练不稳定的情况愈发明显,会造成性能下降。通过以上方法,给出了transformer在自监督训练时的一些建议方法和训练规范。
3.4 Low level Vision Tasks(代理任务)
很少有工作将transformer应用于低层次的视觉领域,如图像超分辨率和生成。这些任务通常以图像为输出(如高分辨率或去噪图像),这比分类、分割和检测等高级视觉任务更具挑战性,后者的输出是标签或方框。
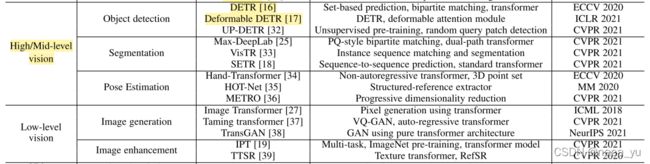

3.4.1 图像生成
3.4.2 图像处理
3.5 High/Mid level Vision Tasks(高级视觉任务)
3.5.1 Object detection


以上为Transformer作为backbone时主流的两种模型:

第一种如上图所示,以DETR为代表(CNN+Transformer),为了实现真正的端到端学习,去掉NMS等后处理方法,作者提出了set prediction这种直接预测方式,每次预测固定的目标,并将GT与预测值一一对应,避免了重复预测的问题。
第二种,一种纯Transformer结构,以TSP-FCOS和TSP-RCNN为例, 一种encoder-only结构并结合feature pyramids。
3.5.2 Segmentation
分割也是计算机视觉中的关键任务,包括实例分割、语义分割、全景分割等。
Transformer用于全景分割
通过在DETR的decoder部分附加带mask的head就可以天然的进行全景分割,Max-DeepLab就是直接使用一个mask transformer进行的全景分割,采用的是双流模型,融合了Transformer和CNN提取的结果。
Transformer用于实例分割
VisTR是基于Transformer进行视频实例分割的模型,通过输入图像序列获得预测的实例。主要提出了一种将预测结果与GT进行匹配的策略,为了获得每种实例的mask,VisTR使用实例分割模块的结果,从多个帧中积累mask的特征,最终使用3DCNN对mask序列进行分割。
Transformer用于语义分割
SETR是基于transformer用于语义分割的模型,使用了ViT类似的encoder结构,随后使用多级特征聚合模块(multi-level feature aggregation)进行像素级别的分割;Strudel则依赖与图像patch相对应的输出嵌入,并使用逐点的线性解码器或掩码Transformer。解码器从这些嵌入中 获取类标签。还有Xie等人在Transformer中使用轻量级的MLP decoder,这样避免使用较为复杂的deocder,也能输出多尺度特征。
Transformer用于医学图像分割
Swin-Unet是一个像UNet的纯Transformer用于医学图像分割的网络模型,采用编解码结构和skip connection提取和融合上下文特征;Valanarasu研究了将Transformer用于医学图像分割的可行性,并提出一个门控的轴向注意力模型来扩充self-attention的能力。 Cell-DETR则是基于做全景分割的DETR结构,增加了skip connection增强特征融合。
3.6 Video Processing
transformer在基于序列的任务,特别是在NLP任务上的表现令人惊讶。在计算机视觉(特别是视频任务)中,空间和时间维度的信息是有价值的,这就导致了其在一些视频任务中的应用,如帧合成、动作识别和视频检索任务中比较出色。
3.7 Multi-Modal Tasks(多模态任务)
多模态任务主要分为:video-text, image-text,audio-text,multi-sensor等任务中。transformer之所以能在跨模态任务中表现出色,重要原因是1. transformer没有引入对于样本本身的归纳偏置;2. 对于输入只需要分块处理,处理简单;3. Transformer是从NLP领域迁移,本身对主流的另一种模态就有适应性,综上,这是transformer在多模态任务上出色的重要原因。

以CLIP(Contrastive Language-Image Pre-training)为例,上图为结构图,下图为官方的demo通过搜索"two dog play in the snow"展示的结果。

CLIP作为一个zero-shot的模型,模型架构分为两部分,图像编码器和文本编码器,图像编码器可以是比如 resnet50,然后文本编码器可以是 transformer。所以目标函数就是最大化同一对图像和文本特征的内积,也就是矩阵对角线上的元素。
总之,目前基于transformer的多模态模型在统一各种模态的数据和任务方面显示了其结构上的优越性,这表明transformer在建立一个能够应对大量应用的通用代理任务方面的潜力。未来的研究可以在探索多模态transformer的有效训练或可扩展性方面进行。
3.8 总结
注意力被用到高层任务之前,关键问题是输入格式的问题。自适应聚合、可变形注意力等都应用到注意力模型本身的改进,这些都停留在初级阶段,进一步想,传统结构与注意力的结合、大型数据集预训练的模型与微调在下游任务的应用、引入先验知识等都是一些值得探究的任务。
四、Efficient Transformer(去除模型冗余度)

以上是经过简化后的模型及其简化的技术类型,参数等。
尽管transformer模型在各种任务中取得了成功,但它们对内存和计算资源的高要求阻碍了它们在资源有限的设备(如手机)上的实施。这一节主要在压缩和transformer模型方面所进行的研究,以便有效地实施。这包括网络修剪、低秩分解、知识提炼、网络量化和紧凑型架构设计。表4列出了一些压缩基于transformer的模型的代表性工作。
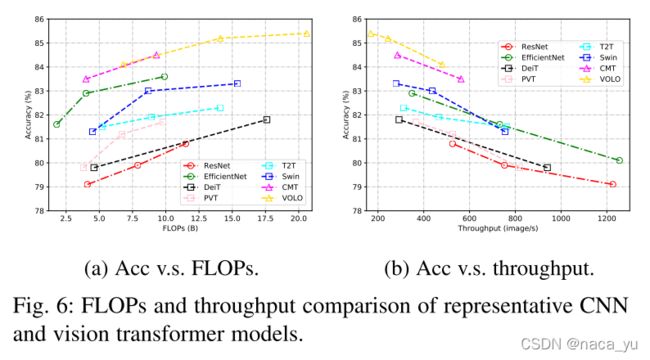
近期Transformer的一系列变体在Imagenet分类任务上取得了显著的效果提升,指标屡创新高。如果没有额外数据的输入,它们的性能仍然不如最新的SOTA CNN模型。由图可知,CMT等混合模型达到SOTA效果,对于pure-transformer和CNN结构,在同样的参数量下,Transformer需要更大的计算量。
4.1 Pruning and Decomposition(修剪压缩)
在基于transformer的预训练模型(如BERT)中,注意力头是冗余的,多个注意操作被并行执行,以独立地模拟不同patch之间的关系。然而,特定的任务并不要求使用所有的头,例如Michel等人提出了实验性的证据,即在测试时可以去除很大比例的注意力头,而不会对性能产生重大影响。Dalvi等人考虑到注意力头的冗余,在中定义了重要性分数来估计每个头对最终输出的影响,不重要的头可以被移除以实现高效部署。同时,还可以reducing the dimensions of linear projections来达到修建的地步。
与transformer模型中不同的注意头可以并行计算的概念不同,不同的层必须按顺序计算,因为下一层的输入取决于前几层的输出。Fan等人提出了一种逐层丢弃的策略来规范模型的训练,然后在测试阶段将整个层一起移除。
除此之外,matrix decomposition也是一种可参考的办法,通过对注意力矩阵分解,达到近似精确结果。
4.2 Knowledge Distillation(知识蒸馏)
知识蒸馏是比较热的方向,通过一个庞大模型”老师“,将知识”教授“给thinner and shallower的模型,使小模型学习其分布,以MOCO为代表。
4.3 Quantization(量化)
将原本高精度的模型参数浮点型进行量化转换到低位(如4bit),低精度模型,虽然降低了模型计算量和大小,但是引起了精度的降低,现在研究对如何专门量化transformer模型的兴趣越来越大。例如,Shridhar等人建议将输入嵌入二进制高维向量中,然后使用二进制输入表示法来训练二进制神经网络。Cheong等人用低位(如4位)表示transformer中的权重。
4.4 Compact Architecture Design(精巧模型设计)
上面讲述了通过通过知识蒸馏可以将模型简化并保持其大部分的性能,除此之外,我们还可以通过一开始就设计好一种紧凑的模型,这种方法以四个方向:
- 轻量化注意力计算结构:Jiang等人简化了self-attention的计算,提出span-based dynamic convolution结构,这种结构将全连接层与卷积层连接代替注意力计算。
- matrix decomposition:一种”Hamburger“的结构被提出,这种结构使用矩阵分解代替原始的注意力计算。
- NAS:通过NAS方法自动找出最优的组件组合,例如Su等人利用NAS中寻找最佳的patch size与linear projection、head的数量与维度组合去得到一个高效的结构。
- dot-product:dot-product是计算向量间相似性的一种有效方法,计算一个patch与其他N–1个patch的注意力时间复杂度为O(N),Katharopoulos等人提出一种Linear dot-product的方法近似表示原始的dot-product方法。

4.5 总结
由于与CNN相比,Transformer的性能很有竞争力,而且潜力巨大,因此正在成为计算机视觉领域的一个热门话题。为了发现和利用注意力机制的力量,正如本文总结的那样,近年来提出了许多方法。这些方法在广泛的视觉任务上表现出优异的性能,包括骨干、高/中层视觉、低层视觉和视频处理。尽管如此,在计算机视觉方面的潜力还没有被充分挖掘出来,这意味着仍有几个挑战需要解决。
前面的方法在如何试图识别模型中的冗余方面采取了不同的方法。修剪和分解方法通常需要预先定义的具有冗余的模型。具体来说,剪枝法侧重于减少模型中的部件(如层、头)的数量,而分解法则是用多个小矩阵表示一个原始矩阵。紧凑模型也可以直接手动(需要足够的专业知识)或自动(例如通过NAS)设计。获得的紧凑模型可以进一步通过量化方法用低比特表示,以便在资源有限的设备上有效部署。
总结来说:去除模型冗余度上,有以下方法和步骤:
- 预先设计低冗余度的模型(通过手工或者NAS自动寻找)
- 利用分解法表示原始矩阵
- 对大型模型的蒸馏和剪切
- 精简后的模型使用低比特表示进一步压缩
五、Conclusions and Discussion
由于与CNN相比,而且潜力巨大,多位科研工作者对transformer结构从底层的注意力结构如注意力头交互、点积计算方法,到高层的high-level任务的应用,近年来提出了许多方法。这些方法在广泛的视觉任务上表现出优异的性能,包括作为骨干使用、高/中层视觉、低层视觉和视频处理任务。
尽管如此,它在计算机视觉方面的潜力还没有被充分挖掘出来,这意味着仍有几个挑战需要解决:其中最突出的几个挑战,包括模型参数量问题,稳定性问题、训练方法问题等都没有较优的方法能够整体提高transformer的性能,并且对于完全从NLP领域迁移的transformer模型本身是否适合视觉任务也有待考察。
5.1 挑战
首先是泛化性和鲁棒性问题,因缺少归纳偏置,pure-transformer需要更大尺度的数据量学习图像领域知识,同时也导致了其对初始参数的设置较为敏感,鲁棒性也会变差,你可以想象一下,CNN好比一个见过图像的一岁小孩,Pure-transformer是一个什么都没见过的刚出生的小孩,让他去分辨一个东西,当然需要更多的引导,也更容易犯错。对于检测和分割等dense-prediction问题,ViT表现得比CNN差强人意,这时候其缺少局部性的缺点就显露出来了。
ViT的参数量过大问题:对于同等任务性能下,基本的ViT结构需要18billion的FLOPs,而GhostNet(CNN)则需要600million参数,这限制了其在低算力设备上的应用。
5.2 展望
- 模型效率:具体来说,transformer发hi否具有高性能和低资源成本。性能决定了模型是否可以应用于现实世界中的应用程序,而资源成本则会影响设备上的部署。因此确定如何在两者之间实现更好的平衡是未来研究的一个有意义的课题。
- 泛化性:大多数现有的vision transformer模型都是为只处理一项任务。许多NLP模型(如GPT-3)已经演示了transformer如何在一个模型中处理多个任务。CV领域的IPT还能够处理多个低级视觉任务,例如超分辨率、图像去噪和去噪。Perceiver和Perceiver IO[245]是可以在多个领域工作的先驱模型,包括图像、音频、多模式和点云。我们相信,只有一种模式可以涉及更多的任务。将所有视觉任务甚至其他任务统一到一个转换器(即,一个大统一模型)中是一个令人兴奋的话题。有各种类型的神经网络,例如
CNN、RNN和transformer。 - 在CV领域,CNN曾经是主流选择,但现在transformer变得越来越流行。CNN可以学习归纳偏见,如平移不变性和局部性,而ViT使用大规模训练来学习归纳偏见。从目前可用的证据来看,CNN在小数据集上表现良好,而Transformer在大数据集上表现更好。未来的问题是使用CNN还是transformer呢?
参考文献
- A Survey on Vision Transformer
- Efficient Transformers: A Survey
- 神经网络架构搜索(NAS)
- 模型量化(Model Quantization)
- Vision Transformer(ViT)