计算机视觉——YOLO(v1,v2,v3)
计算机视觉——YOLO(v1,v2,v3)
- 1、YOLO V1
-
- 1.1论文思想
- 1.2、YOLO V1 网络结构
- 1.3、YOLO V1 损失函数
- 1.4、YOLO V1 存在的问题
- 2、YOLO V2
-
- 2.1、Batch Normalization
- 2.2、High Resoul Classifier
- 2.3、Convolutional With Anchor Boxes
- 2.4、Dimension Clusters
- 2.5、Direct location prediction
- 2.6、Fine-Grnined Features
- 2.7、Multi-Scale Training
- 2.8、主干网络—BackBone:Darknet19
- 3、YOLO V3
-
- 3.1、主干网络—BackBone:Darknet-53
- 3.2、模型结构
- 3.3、YOLO v3 目标边界框的检测
- 3.4、YOLO v3 正负样本的匹配
- 3.5、YOLO v3 损失计算
-
- 3.5.1、置信度损失-Binary Cross Entropy
- 3.5.2、类别损失-Binary Cross Entropy
- 3.5.2、定位损失
本文章主要讲述yolo系列网络的理论知识,从yolov1->yolov2->yolov3->yolov3 SPP->yolov4,如果有不太明白的可以参考哔站这个up主的视频https://www.bilibili.com/video/BV1yi4y1g7ro?spm_id_from=333.999.0.0。
大神讲的是真的好。真的好,真的好!!!!
1、YOLO V1
1.1论文思想
先来大致了解一下论文思想。
- 将一副图像分成SxS个网格(grid cell),如果某一个object的中心落在这个网格中,则这个网格就负责预测这个object。
什么意思呢?假如有下面这张图片:

对于图像中狗这个object,存在于划分后的多个 grid cell中,人工标注的真实框就是图中的红色框的区域,,在红色中的这些grid cell中处在中心的grid cell是黄色位置,那么这个黄色的grid cell 就负责这个狗object的预测。
- 每个网格要预测B个(B一般取2)bounding box,每个bounding box除了要预测位置之外,还要附带预测一个confidence值。每个网格还要预测C个类别的分数。
什么意思呢?就是说分完网格以后每个网格预测两部分信息:
1、一部分是bounding box
每个bounding box 要预测 5 个参数值,一个位置信息包含4个参数,就是预测边界框的4个参数参数(x,y,w,h),还要预测一个confidence值,这个confidence是YOLO系列独有的。
2、一部分是预测C个类别对应的得分,有多好个类别,就有多好个参数。
| 假如我们现在用的是 Pascal VOC 数据集,这个数据集有20个类别,故有 |
|---|
| C = 20 |
| 假设 S = 7,所以input经过上边的操作,就会得到S x S = 7 x 7 个grid cell |
| 设 B = 2,即一个grid cell 预测两个 bounding box |
| 所以可以计算,这个input要预测的参数个数 |
| 参数个数=grid cell的个数 x (每个grid cell预测的bounding box个数 x 每个bounding box 要预测的参数个数 + C个类别参数 = 7 x 7 x (2 x 5 + 20 )= 7 x 7 x 30 |
也就是说,经过YOLO 的正向传播,你就会得到一个7 x 7 x 30 的特征矩阵,看下面这张图加深理解,就是直观的分析要下上面表格中的内容,为什么是一个grid cell 对应30个参数:
下图中一个黄色的长条对应的的就是一个grid cell对应的参数矩阵,后面的拆分就是参数的组成。

然后我们还要分析一下每一个bounding box 的5ge 参数(x,y,w,h)confidence 具体是什么
注意:这里的4个参数意义是和faster RCNN以一样的,但是值的相对对象是不一样的,因为在YOLO中是没有FAster RCNN中的 anchor box的概念的。
| x ,y | 预测目标边界框的中心坐标,这个坐标是相对于grid cell而言的,如下图,中心点的grid cell 是黄色的框,然后我们的x,y,是相对于黄色框的中心点坐标而言的,就是说变换的尺度被限制在0~1之间,只能在这里边调整,就是图中蓝色的点,不会超出黄色框 |
|---|---|
| w,h | 预测目标边界框的w,h,同样也是一个相对值,相对的目标是整幅图像的高和宽而言,也就是说在下图中白点的位置变换,尺度同样被限制在0~1之间 |
| x,y,w,h | 之所以这样是因为LOYO没有 anchor box的概念的,fasterRCNN有anchor box,就是计算anchor相对于真实gt的偏移量。 |
| confidence | 预测的目标边界框与真实目标边界框的交并比IOU乘 Pr(object) |
| Pr(object) | 这个值你可以理解成0,1两个值,当网格grid cell中有目标落在上边面为1,如果没有则为0,这样计算,如果Pr(object)为0,那么这个grid cell对confidence就等于0 |

- 测试过程中的输出
论文原文是这么说的:

在测试时,对于每一个目标的概率,我们是将条件类概率与个体框置信度预测相乘
上面我们说到过,多于每一个 bounding box ,我们有C个类别,最后的类别参数就会包含C个类别的分数

对于这个公式,经过变形,最后就得到了两部分相乘组成
| Pr(Classi) | 为某一目标的概率值 |
|---|---|
| IOUtruthpred | 预测边界框与真实边界框的覆盖程度 |
以上就是论文思想,然后看一下YOLO V1 的网络结构
1.2、YOLO V1 网络结构

卷积的过程就不解释了,直接看后边
最后一次卷积以后得到了一个7 x 7 深度为1024 的特征矩阵:
flatten展平处理,以进入全连接层
fc(4096)全连接,得到4096维的向量
在进行fc(1470)的全连接,得到1470的一维向量
然后做reshape的维度变换,变换到 7 x 7 x 30 的特征矩阵,这样就回到了上面提到了分成S x S 的grid cell,对应的30个值就是每一个grid cell对应的参数。
1.3、YOLO V1 损失函数
这个网络的损失函数由3部分组成:

分为bounding box损失,confidence损失,还有classes损失
在计算损失的时候,用误差平方损失函数和进行计算
1、bounding box损失:
- 对于x,y 的 loss计算 = 预测值-真实标签值的平方和
- 对于w,h的计算有所不同,要对与测试于真实值开根号再计算误差平方和。原因是考虑到大目标和小目标的问题,看下面的图

其中蓝色代表预测值,绿色代表真实值,然后看左边的图,如果我们直接用平方和,那么对于大小目标,横轴同样的偏差造成纵轴的损失就是一样的,想一下这种情况,对于同样的损失,如果是小目标,那么效果就是很差的,因为偏差一点,IOU就变了很多,但是在大目标上看,就没有多大影响,所以对于这样不行,不利于小目标的预测。怎么办:

看这张图,很显然如果做了开根号以后再计算平方误差,那么横轴同样的偏差,对小目标造成的损失要大于大目标的,这样就利于小目标的检测学习。
总结来说就是我们不想让同样的偏差对大小目标造成的误差一样。
2、confidence损失
直接预测值-真实值
但是值得注意的是,这个有两部分组成,一部分是有真实中目标的,一部分是没有真实目标的。所以说没有真实目标的减去的真实值是0,那么结果就会大,就符合误差的增减关系了
3、classes损失
预测值 - 真实值
然后,将3部分加在一起就是总的损失
1.4、YOLO V1 存在的问题
- 对群体性小目标的检测效果差(每一个grid cell只预测两个bounding box )
- 当目标出现了新的尺寸配置的时候,效果差
- 定位不准确(直接预测目标信息,没有anchor概念,没有回归预测。)
有了问题才好进行后面的版本的改进。
2、YOLO V2
YOLO v2针对YOLO v1做了如下尝试,就是对YOLO v1进行的改进

经过这些尝试是模型的性能大大提高,接下来就分析一些这些改进
2.1、Batch Normalization
首先是BN层,在每个卷积层之后加上BN层。估计是当时发表YOLO v1的时候留了一手,哈哈哈
原论文作者是这样解释的,在每一层卷积之后加上一个BN归一化层,这样到来的好处就是:
- 加速模型的收敛速度
- 消除其他形式的正则化
- 使用BN层可以消除dropout的操作。(drop的作用是减轻过拟合的作用)
总体而言,通过加上BN层的操作以后,有助于模型规范化,得到了2%以上的mAP提升。
2.2、High Resoul Classifier
这个操作是:使用了一个更高分辨率的分类器。
在YOLO v1中,作者采用的是 224 x 224 输入大小的分类器。在YOLO V2中采用一个更大的输入尺寸,448 x 448 的输入,带来的好处:
- 使用更大的分辨率的输入给模型带来了4%的mAP的提上
2.3、Convolutional With Anchor Boxes
原论文是这么说的:

上边已经讲到,在YOLO v1中作者是直接预测目标边界框的高度,宽度和中心坐标的,这样的定位性能并不是太高,在YOLO v2中,作者尝试使用基于Anchor的预测,预测anchor偏移量的形式来预测目标边界框。好处是:
- 简化目标边界框的预测问题
- 加速模型收敛
总的来说,这样做使得mAP有了一点点的下降,但是模型的召回率却有了将近10%的提上,召回率上去了,就证明能检测出来的目标更多了,而且准确路并没有多大的下降,这是很好的,有助于模型继续提升的空间。
2.4、Dimension Clusters
原论文这样说的:

在FASTER RCNN中不是得到了3个尺寸和3中比例的目标边界框嘛,但是也没有说为甚就是这3种尺寸没中比例,这里坐着给出,在训练的过程中,用K-means聚类的方法得到。
2.5、Direct location prediction
这一点是关于目标边界框预测的一些尝试。就是也加上了一个类似于anchor的概念。论文中称为 bounding box prior。
先来看一下在FASTER RCNN中,给出的边界框回归参数预测过程,有给出如下回归公式

其中:
ti:表示网络预测的第i个anchor边界框的回归参数
ti*表示第i个anchor对应的真实边界框GT Box回归参数
然后我们计算公式如下

先来看一下运用anchor以后的回归参数的预测过程。
1、首先我是不是预测出了一个边界框(x,y,w,h)
x:表示我们当前预测的x坐标,依此类推y,w,h
2、然后我们还有一个 anchor的边界框的坐标(xa,ya,wa,ha,)
xa:表示真实的边界框中心点a的x坐标
3、我们就看x,y,进行分析
tx:(预测的的x值 - anchor中心点xa值)/wa,依此类推,得到的就是预测的的边界框相对于anchor的回归参数[tx,ty,tw,th,]
t*:(真实的x值 - anchor中心点xa)/wa,依此类推,得到anchor对于此anchor对应的真实边界框GT Box对应的回归参数
4、学习的目的就是让预测的参数和真实的参数接近
4、最后计算损失:loss = t*- t
上边是FASTE RCNN用了anchor概念以后的预测过程,预测的是预测边界框相和真实边界框对于anchor box的偏移量然后进行损失计算学习参数,而我们之前讲的YOLO v1是直接通过预测边界框相对于真实边界框(相对于整副图像)计算的偏移量。
有了回归参数然后就是预测过程,预测的具体计算。
经过对基于anchor的预测模型的学习,作者发现这种方式在训练的前期是很不稳定的,经过研究,发现这种不稳定更多的是由于预测中心坐标想,y所导致的,预测的公式是:
x = (tx * wa) + xa
y = (ty * ha) + ya
就是说对于这个预测公式,他是没有任何限制的,所以预测出来的坐标可能会出现在图像的任意地方,这显然是不好的。为什么会这样,我们看一个例子:

1、首先对于每一个grid cell,设置anchor设置在每一个grid cell的左上角,如上图。
2、由于我们的公式并没有限制tx,ty的值,那么我们将anchor的中心坐标加上回归参数之后呢可能出现在图像的任意一个地方,可能是上图的右下角的黄色值。
3、但是这明显是不对的,因为右下角的黄色框应该是由右下角grid
cell的anchor中心点坐标加上回归参数得到的,轮不到左上角的anchor。
就造成了不稳定,为了改善这种情况,作者用了另外一种方法:
- 假设将anchor设置在每一个grid cell左上角的话,假设他的中心点坐标是(Cx,Cy)
- 假设预测的bounding box prior的宽高是(Pw,Ph)
- 在YOLO v2中作者给出了如下计算公式

就是给tx经过sigmoid函数映射,将tx限制在0~1之间,也就是将预测的中心点坐标固定在当前的 grid cell中了。
就是:让每一个anchor (prior)只去负责预测目标中心点落在某个grid cell区域内的目标。区域外的目标就不用管了。
总的来说,利用聚类方式生成bounding box prior,和直接预测bounding box中心坐标的方式,这样的改进使得模型提高了5%的mAP。
具体的预测过程我们在YOLO v3中讲解,v2,v3是一样的预测过程
2.6、Fine-Grnined Features
原论文是这样说的:

就是说在最终的预测特征图上结合更底层的特征信息,就是更靠前的卷积层输出的特征结果。
因为这些特征层更能显示一些图像的细节信息,这是在检测小目标所需要的
怎么结合的呢,还是引用上面提到的哔哩哔哩UP主的杰作:看下图

这是一个YOLO v2模型的整体框架
这里作重要的就是这个蓝色框的部分:
这里有一个细节,在进入PassThrough Layer之前进行一个1 x 1 x 64的卷积得到26 x 26 x 64的特征
他是将底层的26 x 26 x 64的特征和后面的 13 x 13 x 1024 的层结合,怎么结合的,这是一个最新的主流技术,yolo v5 focus结构也是这样的,哈哈哈,看下图这个例子:

- 假设这里有一个 4 x 4 的特征矩阵
- 首先将这个特征矩阵进行2倍分割
- 然后分割之后将相同位置的小方格进行组合
- 就得到4个 2 x 2的特征图
可以看到,原特征矩阵的长和宽变为原来的二分之一,深度变为原来的4倍。
经过PassThrough Layer得到一个 13 x 13 x 256的特征矩阵
然后在深度方向和一样宽度的高层特征图进行一个拼接,即深度相加
2.7、Multi-Scale Training
原论文是这样说的:

就是说进行多尺度训练。
在训练过程中,替换固定尺度的输入,提高鲁棒性怎么做?
每次迭代10个批次,将网络的输入尺寸进行一个随机的选择,对输入图像进行缩放,这个缩放因子是32
32是怎么来的:
看上边的网络结构,输入的是:416 x 416
最后一个特征层的输出是: 13 x 13
416/13 = 32
所以,我们随机选择的输入尺寸都是32的10~20的整数倍从320开始到608结束
{320,352,…………,608}
上面就是 YOLO v2的一些尝试,然后看一下 YOLO的主干网络
2.8、主干网络—BackBone:Darknet19
网络结构如下:

这里的输入是224 x 224输入为例:Darknet-19224x224)]only requires 5.58billion operations to process an image yetachieves 72.9% top-1 accuracy and 91.2%top-5 accuracy on ImageNet.
准确率很高。
网络的总体结构还是上面的这里就不做阐述了:
就是注意一下,最后做的就是一个简单的1 x 1 x 125 得卷积,这个125就是5个bounding box prior对应的参数。
3、YOLO V3
前边的YOLO v1,和YOLO v2就是做一下简单的介绍,YOLO v3相对与他两个在mAP上有了一个相当大的提升,模型也相对复杂,是值得学习的,后面的v4,v5也是对v3稍加改进,有在数据层面的,也有在模型层面稍加调整,理解好 v3还是有必要的,接下来就看v3吧。
3.1、主干网络—BackBone:Darknet-53
在v2中用的主干网络是Darknet-19,而v3中在主干网络部分进行了改进,运用Darknet-53,我来简单的介绍一下,同样看一下论文中的网络结构:

可以看到Darknet-53的top-1有了4个百分点的提升,检测速度也不低,每秒78张图片。
简单分析一下网络结构,之所以叫Darknet-53,是因为整个网络中用可53层Convolutional。
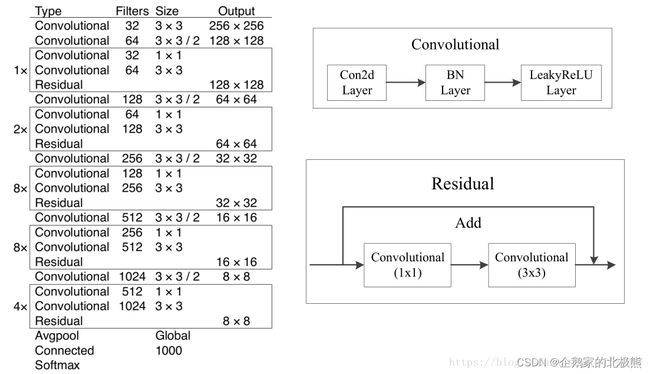
然后每一个上面每一个Residual对应的方框圈住的部分相当于一个残差结构。
1、为什么效果会比普通的残差结构更好?
是因为在网络中,去除了ResNet中的最大池化层,每一次的下采样都是用“步长为2的卷积层”实现的尺度的压缩的,这样做的好处就是更能融合全部的特征信息。
2、为什么速度快?
这个网络的参数个数远小于ResNet
3.2、模型结构
这个地方还是引用我上面提到的UP主https://blog.csdn.net/qq_37541097/article/details/81214953的博文里的图片。

通过这个图我们可以看到,对于每个入,考虑三个预测特征层的输出,然后每个预测特征层又有三种尺度的预测。每三种尺度的具体数值是通过K-mens算法得到的,那么一共得到9种尺度,每一个预测特征图三种。
还是用UP的杰作(有点剽窃的感觉了,因为我写博客也是为了加深自己的理解,捋一遍过程,就这样吧):

在YOLO V3中加入了一个 bounding box priors,这个就和我们之前Faster RCNN中的 anchors是一样的。
然后我们看一下在看一下预测的参数,这里以每一个预测特征层为例:
| 特征层size | N x N |
|---|---|
| grid cell 三个数 | N x N |
| 每一个grid cell的bounding box priors个数 | 3 |
| 每一个bounding box priors参数 | 位置参数4个,目标置信度confidence 1个,类别分数 C个(C就是类别数) |
| 总参数个数 | N x N [3 x (4 + 1 + C)] |
如果是对于 13x 13 的特征层基于COCO 数据集C=80 预测,就是:

然后你要注意Convolutional Set 里边的结构

经过 Convolutional Set ,输出两个分支,一个是进行此特征层的预测,另一个是进行了一个Convolutional + Up Sampling 后与底层特征层进行一个 Concateate,这个操作是在深度方向上进行拼接作为下一个预测特征层的预测,依此类推
然后每一个特征层的预测器,就是一个简单的Conv1 x 1的卷积。
因为三个特征层的尺度不一样对于输入是416 x 416的输入:
| 输入 | 416 x 416 |
|---|---|
| 第一个特征层13 x 13 | 预测较大的目标 |
| 第二个特征层 26 x 26 | 预测中等目标 |
| 第三个特征层 52 x 52 | 预测目标 |
这样就把预测大小目标的性能都考虑在内了。
3.3、YOLO v3 目标边界框的检测
对于目标边界框的预测,采用的是和YOLO V2一样的预测机制。详细的看一下。
在YOLO V2和YOLO V3中运用的anchor机制和FAster RCNN ,SSD还是有一点不一样的。
| 模型 | 网络预测众目标中心点的参数相对对象 | 宽高 |
|---|---|---|
| Faster RCNN,SSD | anchor | anchor |
| YOLO v1 | 当前grid cell中心点 | 整幅图像 |
| YOLO v2,v3 | 当前grid cell左上角点 | anchor |
我们以某一个特征层进行分析:
假设这就是三个特征层中的某一个预测特征层特征层
1、当对上图中红色的 grid cell进行预测的时候,会得到三个anchor,每一个anchor模板都会生成(4 +1 + C)个参数。
通过训练对于每一个anchor得到下面四个回归参数分别是:
| tx |
|---|
| ty |
| tw |
| th |
2、图中虚线的部分代表的是anchor,每一个anchor只需要关注anchor的宽度和高度
| 宽度Pw | Ph高度 |
|---|
在回归参数的预测过程中,我们是通过学习,学到回归参数,这个回归参数是基于anchor偏移量计算的,所以在预测过程中,我们关注的同样是关注anchor的宽度和高度。
3、图中蓝色的矩形框对应的是最终预测的目标边界框的大小和位置
4、有了回归参数然后看一下预测边界框的坐标的计算公式
| Cx,Cy | 当前grid cell 左上角点的 (x,y)坐标 |
|---|---|
| 预测的目标中心点的坐标x | bx = Sigmoid(tx)+ Cx |
| – | – |
| 预测的目标中心点的坐标x | by = Sigmoid(ty)+ Cy |
| 预测的目标边界框宽度w | bw =Pwet~w~ |
| 预测的目标边界框高度h | bh = bw =Phet~h~ |
这里的改进就是加上了Sigmoid函数:

这里的最好的地方就是在预测过程加上了Sigmoid函数对偏移量进行限制,使得偏移量维持在0~1之间,就是这个预测框只预测当前grid cell的object,作者会加速模型的收敛。
3.4、YOLO v3 正负样本的匹配
原论文是这么说的:

就是说对边界框参数进行训练的时候会计算损失,计算损失的时候对于不是前景的损失就不用计算了对不对,那就要区分哪些要计算,要计算的是正样本,哪些不计算为负样本,对于生成的所有bounding box prior怎么分配这个值呢,针对每一个GT 我们会分配一个正样本bounding box prior ,一张图片中有几个GT目标,就有几个正样本。
分配原则(怎么给这个bounding box prior打标签):
- 将与GT重合度最大的bounding box prior作为正样本
- 将与GT也重合但不是最大的bounding box prior但是由大于规定的某一IOU阈值,直接丢弃
- 其余的,也就是IOU小于规定的阈值的作为负样本
如果当前bounding box prior 既不是正样本,也不是负样本,那么他就既没有定位损失,也没有类别损失,只有confidence损失
现在有一个问题,如果按照作者给出的分配方式会造成正样本的数量很少,就做如下改进:
怎么改进看一个例子吧(还是引用UP主的杰作):
以一个特征层为例
之前我们说过,对于每一个预测特征图,都会有三个不同的预测特征图模板
蓝色——代真实的也边界框GT
黄色——代表不同尺寸模板Anchor Template

分配步骤如下:
| 1、将每一个Anchor Template 与 其对应 GT 的左上角重合 |
|---|
| 2、重合好了以后,将GT和他对应的每一个Anchor Template进行一个IOU值的计算。 |
| 3、IOU-AT1=0.25,IOU-AT2=0.7,IOU-AT3=0.2 |
| 4、设置一个IOU阈值,这里我们设置成:IOU > 0.3,只要IOU>0.3的就都置为正样本,则正样本为IOU-AT2=0.7这个模板 |
| 5、然后将GT映射到预测特征图(grid网格)上 |
| 6、映射后GT的中心点落在哪个grid cell上,该cell对应的AT2就为正样本 |
| 7、如果第3步计算的AT-1,2,3的IOU都大于指定阈值,那么在当前的grid cell 中对应的3个anchor都会被置为正样本 |
以上面的方法分配,就达到了扩充正样本数量的目的,租主要的就是第7步的分配准则。
3.5、YOLO v3 损失计算
YOLOv3的损失函数主要分为三个部分:
| 目标定位偏移量损失 | Lloc(l , g) |
|---|---|
| 目标置信度损失 | Lconf(o , c) |
| 目标分类损失 | Lcla(O , C) |
如下
λ1,λ2,λ3,为平衡系数。

3.5.1、置信度损失-Binary Cross Entropy
目标置信度可以理解为预测目标矩形框内存在目标的概率。直接理解就是预测的框和真实的框的IOU越大,概率就越大
论文原文是讲:

就是说对于每一个bounding box 所预测的 objectness score 用的是逻辑回归,**源码中的逻辑回归的损失计算使用的“二值交叉熵损失”**给出下方公式:

| oi ∈ [0,1] | 表示预测目标边界框与真实目标边界框的IOU(原文是说只有0,1两个值) |
|---|---|
| c | 预测值 |
| c^i | c通过Sigmoid函数得到的预测置信度 |
| N | 正负样本个数 |
3.5.2、类别损失-Binary Cross Entropy
同样看原文:

就是说:只有正样本才有目标类别损失,在计算类别损失的时候,同样用“二值交叉熵损失”

| Oij∈ {0,1} | 表示预测目标边界框 i 中是否存在第 j 类目标,取0或1 |
|---|---|
| Cij | 预测值 |
| C^ij | Cij通过Sigmoid函数得到的目标概率 |
| Npos | 正样本个数 |
针对上面的计算公式看下面的例子
输入图片两个目标是猫

1、假设类别:【老虎,豹子,猫】
2、真实标签:
目标一:【0,0,1】
目标二:【0,0,1】
3、预测概率(经过Sigmoid处理)
目标一:【0.1, 0.8, 0.9】
目标二:【0.2, 0.7, 0.8】通过计算你可以发现,对于每一个输出值相加之和不等于一,因为经过了而值交叉熵损失计算,没有经过softmax处理,每一个类别输出的概率值是相对独立的。
3.5.2、定位损失
原论文提到:

就是说:目标定位损失采用的是Sum of Squared Error Loss,注意只有正样本才有目标定位损失
还是看边界框预测过程的图:
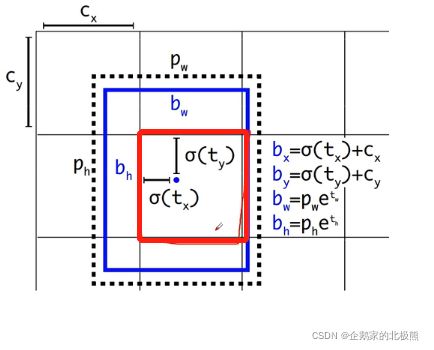
给出损失计算公式:


| tx,ty, | 网络预测的关于中心坐标的偏移参数 |
|---|---|
| tw,th | 网络预测的关于目标宽高的缩放因子 |
| Cx,Cy | 是对应Grid Cell 的左上角坐标 |
| Pw,Ph | 代表对应Anchor模板的宽度和高度 |
| gx,gx,gx,gx | 代表GT Boxes中心点的坐标x, y以及宽度和高度(映射在Grid网格中的) |
| g^ | 真实回归参数 |
根据上边的公式,对,仅对每一个正样本计算定位损失,然后求和,最后除以正样本总个数。
了解即可