Redis系列——哨兵挂了,redis 还能正常工作吗?
前言
redis 主挂掉了,怎么将请求转移到从上去,如果从是多个,从是怎么进行选举的呢?
那么就要看我们今天的主角了,redis哨兵,redis哨兵能够帮助我们自动的完成选主和故障转移操作,这次还是会多画图,来加深大家都这个过程的记忆和理解。
redis哨兵都干了什么
redis哨兵是一个运行的特殊的redis进程,他主要有三个使命:
- 监控
- 选主
- 通知
监控的是什么
哨兵主要是监听主库和从库是否存活,怎么进行监控? 哨兵会定期的给从库发送PING命令,如果从库没有在设定的时间内回复哨兵,那么就会认为从库下线了。哨兵也会定期的给主库发送PING命令进行通信,如果主库也没有在设定的时间内回复哨兵,那么就会认为主库也“下线了”。【注意我这里只是为了说明下监控的方式,真正判断的主库下线不是这样的】。
看图说话:

可以看到图中redis-2 slave 是灰色,表示已经down掉了,此时并没有正常返回给哨兵响应,所以被标记为下线状态了。
主库的监控
这里为什么要单独来说下主库的监控呢?因为主库监控,不能说哨兵没有收到PING的响应,那么就认为主库就下线了,因为主库的选举是一个很复杂的过程,会有耗时和通信的开销,所以我们不能简单认为哨兵没有收到PING的响应,那么就直接判断主库下线了,然后就进行选举,如果是从库可以的,因为从库下线了,对于主从集群来说,影响不会很大。
在主库压力比较大,或者网络阻塞了,出现抖动了,这个是并没有在设定的时间内回复给哨兵响应,那么此时武断的认为主库"下线了",此时就出现了误判,明明不需要进行选主,不需要进行通知,此时白白浪费的资源、同时带来了开销。
看图说话:
在网络畅通的情况下,哨兵发了一个PING给主库

此时网络阻塞,变成了红色,PONG,没有在设定的时间内返回

网络恢复顺畅,哨兵重试,在设定的时间内返回响应

通过上面三幅图,其实就可以看出,网络阻塞的情况下,会出现误判的情况。
那么reids是怎么判断主库下线的呢?其实redis采用哨兵集群的方式,让哨兵集群中的每个哨兵都和主库进行通信,如果多数都没有在设定的时间内响应给哨兵,因为多个哨兵都出现网络不稳定的情况概率就大大降低了,那么此时这个主库就认为是下线了。下面我们来细细的说下这个过程,同时引入哨兵集群也解决了哨兵单点的问题。
主库的下线判断
这个过程分为主观下线和客观下线。
主观下线:指的是一个哨兵在设定的时间内,没有收到主库的响应,那么此时是这个哨兵主观的认为主库下线了,并不能认为真正的下线。
客观下线:指的是,当多数哨兵在设定的时间内,都没有收到主库的响应,那么此时就可以认为主库真的下线,称为客观事实了。
继续看图说话:
下图中只有哨兵B,没有在设定的时间内,收到响应,判断为主观下线了,但是其他哨兵A和哨兵C都能在设定的时间内收到响应,所以还是线上状态,少数服从多数,此时结论还是上线状态。

下图中哨兵B和哨兵C,都没有在设定的时间内收到响应,即使哨兵A收到正常的响应,那么此时已经构成多数情况下的主观下线,此时就可以判断为客观下线了。

选主
上面的我相信大家已经很清楚,redis的怎么判断主库的下线了,那么此时redis需要从剩下的所有的从库中再次选举出一个新的主库,来接收后面来的写请求。
reids哨兵会对从库们进行打分,谁的分数高,那么它就是新的master了,下面来详细说选主的过程。
哨兵在进行打分之前,先会在从库进行筛选,把不合格的从库筛选掉,留下优秀的种子选手来进行参赛打分。
那么筛选的依据是什么呢?
哨兵会把标记为下线的从库和主从之间网络不顺畅的从库筛选掉,看下图你就明白了:
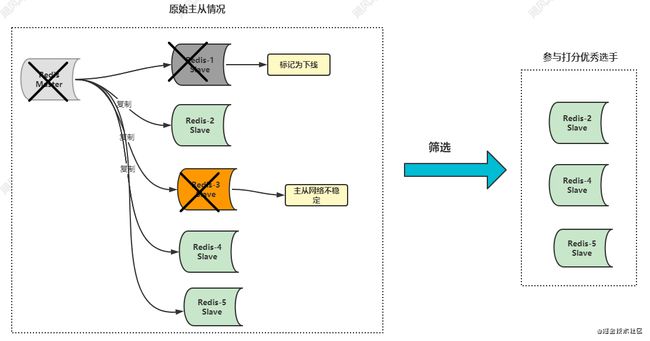
在主从模式下,如果主从之间网络断开的次数和超时时间超过down-after-milliseconds 的设置,那么就会认为该从库网络不健康了,不稳定了。
接下来就会从剩下的优秀从库内进行打分,打分最高者为新的Master,
打分会从三个层级进行打分,记住只会比较一个层级的分数,只要在当前的层级分数最高就可以了,如果分数相同,再比下一个层级,以此类推。
第一轮:比较从库的优先级
你可以手动设置从库的优先级,通过slave-priority进行设置,数字越小,级别越高。如果这个层次,有优先级级别最高的出现,那么就选此从库做为Master,选举就结束了,如果优先级相同,那么进入下一轮打分。 看图:

第二轮:与主库的同步进度越接近
肯定是从库的数据越新,那么选择它作为新的Master,才最有意义了。那怎么才能知道哪个从库才是最新的呢?
从库会记录自己同步主库的进度,这个参数为slave_repl_offset, 是累加的,也就是这个值越大,那么它们谁同步的数据就是最新的,得分就是最高的,选举就结束了,如果复制进度相同,那么还需要进入下一轮,比较ID。 看图:

第三轮:ID号越小,得分越高
比较自己的ID【redis在启动的时候,会给自己分配一个ID】,ID越小,自己得分就越高。

最多经历三轮打分,主库就会被重新选出,那么哨兵就会通知其他从库执行replicaof 指向新的主库,进行主从切换,这里有一个细节,需要注意,不知道你没有想到,就是由哪个哨兵来执行主从切换呢?
哨兵选举Leader
其实由哪个哨兵来进行发号施令,进行主从切换,这个哨兵是需要进行选举的其实由哪个哨兵来进行发号施令,进行主从切换,这个哨兵是需要进行选举的。
本篇前面说过,判断主库是否下线是需要进行主观下线和客观下线两个过程,自己先标记为主观下线,当多数都标记为主观下线的时候,那么就认为客观下线了,那么这个多数应该是多少呢,其实是通过quorum配置项配置的,如果我们有三个哨兵,quorum 配置为2 ,那么除了自己判断主观下线,还需要一个哨兵也需要判断为主观下线,那么此时才会进入客观下线了,这个判断的过程,其实就是一个投票的过程,包括自己给自己投一票,还包括向其他实例发送is-master-down-by-addr 命令,询问其他实例,自己判断的这个主库是不是下下了,如果得到对方的响应,那么自己的票数就累加,哨兵投过票了,就不会给其他哨兵再次投票了。
这里具体看图:
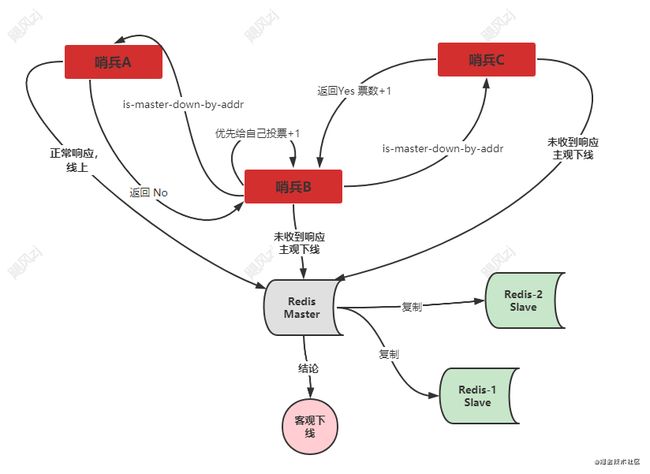
这个图只是简单的为了说明,哨兵B和哨兵C都发现了redis Master 为主观下线了,但是哨兵B 优先给其他哨兵发了is-master-down-by-addr命令,并得到了哨兵C的回复,那么加上自己给自己的投票,那么就是得票数为2 ,大于等于 quorum的配置值 2,此时主库标记为客观下线.
如果哨兵B 要想成为Leader,那么还要同时满足得到的票数大于等于哨兵(n/2 + 1)数量才可以成为leader,这里由于我们有三个哨兵,票数过半的话,也就是大于等于2,所以此时哨兵B可以成为Leader了。
所以称为leader要满足的条件为:
- 得到的票数要达到配置的quorum阀值。
- 获得哨兵半数以上的票数。
通知
哨兵B Leader 可以主持主从切换了,通知其他从库执行replicaof 到新的Master,主从切换完成之后,还会通知连接redis 的客户端,告诉它们新的Master的地址和端口。
这里在说下是怎么通知redis 客户端 Master要换新的ip和端口了呢?
其实redis客户端可以定于哨兵的主从切换事件,当完成主从切换后,哨兵就发送这个事件的结果,那么订阅了这个事件的redis客户端都会收到通知,此时redis客户端就可以更新到新的Master的地址了。
如果出现网络断开或者抖动,没有收到订阅事件的通知,那么其实还可以调用哨兵提供的接口,进行重新拉取。
通知模型:

总结
今天主要是熟悉哨兵的工作原理和过程,下面来做下总结:
哨兵都干了什么?
监控、选主、通知。
监控:
监控主从节点是否下线,从节点可以简单认为没有收到响应就直接下线,因为从节点下线一般不会影响到集群的使用。
主节点的下线,分为主观下线和客观下线,只有在多数都认为是主观下线了,才认为是客观下线了。
选主:
首先进行筛选,把标记为下线的从库,网络不稳定的从库晒出掉。
接下来进行打分,主要会分三个阶段:分别从 从库的优先级、复制进度、ID大小来进行打分。
通知:
通知其他从库执行replicaof 到新的Master,主从切换完成之后,还会通知连接redis 的客户端,告诉它们新的Master的地址和端口。
哨兵选举过程:
哨兵投票机制:
a:哨兵实例只有在自己判定主库下线时,才会给自己投票,而其他的哨兵实例会把票投给第一个来要票的请求,其后的都拒绝。
b:如果出现多个哨兵同时发现主库下线并给自己投票,导致投票选举失败,就会触发新一轮投票,直至成功。
哨兵成为Leader的必要条件:
a:获得半数以上的票数。
b:得到的票数要达到配置的quorum阀值。
注意的点
在master关掉 到 主从切换完成,通知完客户端,这个期间,所有的写请求是不能处理的,因为master已经挂掉了,如果采用的是读写分离,所有的读请求就是可以正常处理的,读请求会被分到从库上去。如果此时想让业务感知不到异常,可以采取相应的降级策略,可以让写请求先写入到mq中,等待恢复之后,再写入到新的master就可以了。
这里在强调一下哨兵进行主从切换的前提条件,必须要选择出哨兵Leader,由Leader进行通知从进行主从切换和通知客户端更换新的Master的地址和端口。
在这里举个例子,如果有5个哨兵,quorum 配置为2,那么要想成为Leader,那么获得票数必须要达到2 才能判断一个主库为客观下线,同时获得票数也要大于等于(n/2) + 1 的票数,也就是获得3以上才可以。如果此时有3个哨兵故障了,即使你获得了2票,能判断为客观下线,那么由于没有过半的哨兵数量,也是无法选举出Leader ,也就无法进行下面的过程了,此时集群就玩完了。
问题
这里给大家留一个问题,我们知道可以通过下面命令进行哨兵集群的搭建:
sentinel monitor 这里只是设置了 ip 和端口,以及quorum值,那么整个集群之间是怎么建立通信,进而能后续的选举leader做准备,同时它又是怎么获得从库的ip和端口列表,进而来做后续的从库的监控。
两个问题:
- 集群怎么建立通信的?
- 集群怎么获取的从库列表?
一直想整理出一份完美的面试宝典,但是时间上一直腾不开,这套一千多道面试题宝典,结合今年金三银四各种大厂面试题,以及 GitHub 上 star 数超 30K+ 的文档整理出来的,我上传以后,毫无意外的短短半个小时点赞量就达到了 13k,说实话还是有点不可思议的。
一千道互联网 Java 工程师面试题
内容涵盖:Java、MyBatis、ZooKeeper、Dubbo、Elasticsearch、Memcached、Redis、MySQL、Spring、SpringBoot、SpringCloud、RabbitMQ、Kafka、Linux等技术栈(485页)

《Java核心知识点合集(283页)》
内容涵盖:Java基础、JVM、高并发、多线程、分布式、设计模式、Spring全家桶、Java、MyBatis、ZooKeeper、Dubbo、Elasticsearch、Memcached、MongoDB、Redis、MySQL、RabbitMQ、Kafka、Linux、Netty、Tomcat、数据库、云计算等
《Java中高级核心知识点合集(524页)》

《Java高级架构知识点整理》


由于篇幅限制,详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
需要的小伙伴,可以一键三连,下方获取免费领取方式!
