pytorch分布式训练(二):torch.nn.parallel.DistributedDataParallel
之前介绍了Pytorch的DataParallel方法来构建分布式训练模型,这种方法最简单但是并行加速效果很有限,并且只适用于单节点多gpu的硬件拓扑结构。除此之外Pytorch还提供了DistributedDataParallel来构建分布式模型,并行加速程度更高,且支持多节点多gpu的硬件拓扑结构。
一、Overall Design
整体的系统方案设计intuition也非常直观:每个gpu上都有一个local的model和一个mini-batch的数据,进行数据分布式训练时,每个gpu进行当前设备上的forward pass和backward pass。不同gpu上的模型在构造时通过broadcast机制统一初始化参数,每次训练iteration结束后,不同gpu上的参数梯度汇总到一起取均值作为整个大batch的对应梯度,然后将该梯度分发给各个gpu上的模型进行更新。不同gpu上的模型初始值相同且每次更新值也相同,就能保证各个gpu上的model虽然使用不同数据进行训练,但是模型始终是“参数相同”的。结合基于随机梯度下降的优化算法原理,不难得到结论,多个gpu上的梯度汇总平均后再分发,相当于将同一个模型在单独gpu上使用大batch进行训练,即完成了数据并行的分布式训练。
基于上述设计理念,Pytorch实现了DistributedDataParallel这个API可以把一个普通的单gpu模型wrap成数据并行分布式模型,然后就可以类似单gpu模型那样进行训练了,通过下面的sample code来看,一行code就可以完成工作。
import torch
import torch.nn as nn
import torch.nn.parallel as parallel
import torch.optim as optim
# user defined model
net = model()
# wrap the model into distributed data parallel model
net = parallel.DistributedDataParallel(net)
opt = optim.SGD(net.parameters(), lr=0.1)
# training codes ommited
...
二、Gradient Average Design Details
这部分需要完成的工作很简单,就是把各个gpu上backward后每个参数的梯度拿到,然后汇总到一起取均值,再下发给各个设备。为了高效的完成这个过程,结合硬件的拓扑结构和计算特点,Pytorch设计了相应的策略。
各个gpu进行本地的前向传播后,需要进行反向传播计算所有参数的梯度,这个过程不妨称之为computation;不同gpu上相同参数的梯度需要通过gpu之间的通信汇总到一起计算均值,这个过程不妨称之为communication。神经网络是典型的有向无环图,反向传播是一个链式计算的过程,即求完一个再求另一个。那么如何安排computation和communication的相互顺序,首先考虑两种极端情况。
2.1. communication after every computation
此时每计算完一个参数的梯度,就进行一次各gpu之间的通信得到均值后再返回各gpu上覆盖原参数梯度。但是这样做会浪费gpu之间的带宽,因为单次communication的是有开销的。实验表明,各gpu之间的通信搬运大批量数据时候效率更高。定性的来说,n个相同大小的数据,分n次搬运每次搬一个的耗时要远大于一次搬运n个数据。例如,60M的torch.float32数据,通过不同的搬运次数和每次搬运数量来进行gpu之间的communication,搬运次数越多(每次搬运数据量越少)越耗时。
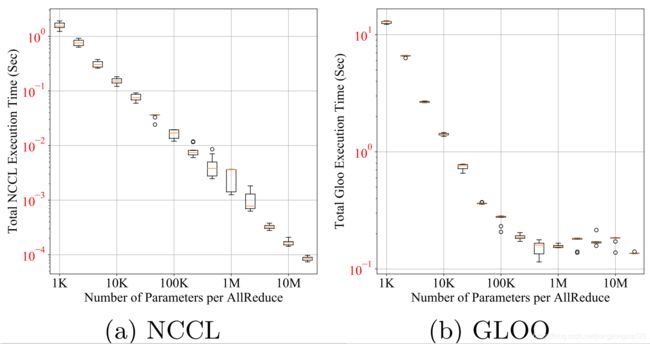
2.2 communication after all computation
等待各个gpu上所有参数的梯度computation全部结束后,再进行一次gpu之间的communication,计算所有参数的梯度均值后再写会各个gpu覆盖原始梯度。此时computation和communication成了串行结构,没有做到充分并行。
2.3 gradient buckets
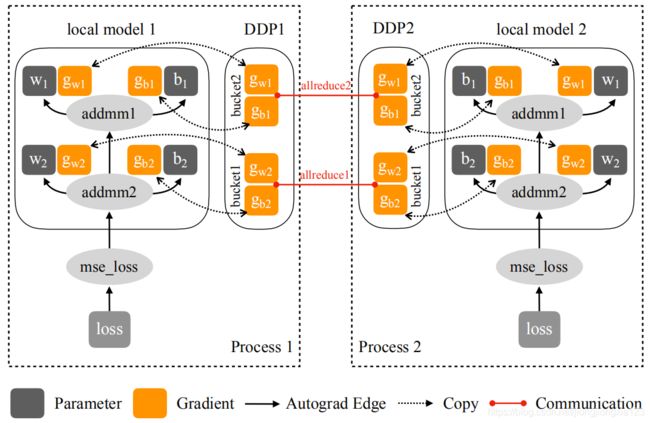
根据上面的分析,为了实现高效的gradient average,Pytorch设计了基于buckets的gradient average策略。具体来说,将模型的所有参数分进若干个buckets,每一个bucket里装一部分参数。在模型进行反向传播时,所有参数的梯度是一个接一个计算的,当所有gpu上某个相同bucket里面所有的参数梯度都计算完了,则可以进行当前bucket梯度的communication过程。与此同时,其他参数的梯度继续计算。理想情况下,上一bucket的communication结束后,刚好又有一个bucket的参数梯度都计算完了,则gpu通信无缝连接这一个bucket的通信工作,使得模型的反向传播和gpu之间梯度通信实现几乎百分百的并行,具体还有一些实现的细节。
2.3.1 参数顺序
在反向传播时,参数分配进若干个buckets的顺序是按照前向传播时参数调用的倒序排列的,这样可以几乎满足反向传播时梯度计算的先后顺序,使得先完成计算的参数梯度尽快进入某个bucket并进行gpu之间的通信。另外为了保证在个别情况下(两个参数 p 2 p_2 p2、 p 3 p_3 p3在逻辑上同时进行前向和反向传播,但是实际反向传播执行时,某个gpu上 p 2 p_2 p2的梯度 g 2 g_2 g2先于 p 3 p_3 p3的梯度 g 3 g_3 g3被计算,另外一个gpu上 p 3 p_3 p3的梯度 g 3 g_3 g3先于 p 2 p_2 p2的梯度 g 2 g_2 g2被计算)各个gpu的参数能够一一对应,在每个bucket中各个参数的先后顺序也是保持固定顺序的。

2.3.2 允许部分参数不计算梯度
按照gradient buckets的设计思路,同一个bucket中只有所有参数都完成了梯度计算后,该bucket才能准备进行communication。当所有gpu的该对应bucket都准备好后才能进行各gpu针对该bucket的通信。但是在网络中可能存在一些算子或子网络,在某些iteration里是不进行前向传播和反向传播的,而在其他iteration里是进行前向传播和反向传播的,例如添加了dropout的全连接层。当某个参数在当前iteration前向传播中没有参与计算,那么在反向传播时也就不会计算其梯度(因为当前iteration中该参数对应的算子没有出现在链接图中),那么该参数所在的bucket始终无法ready(下图中的 g 3 g_3 g3),也就卡住了后续的梯度更新环节,训练中止。
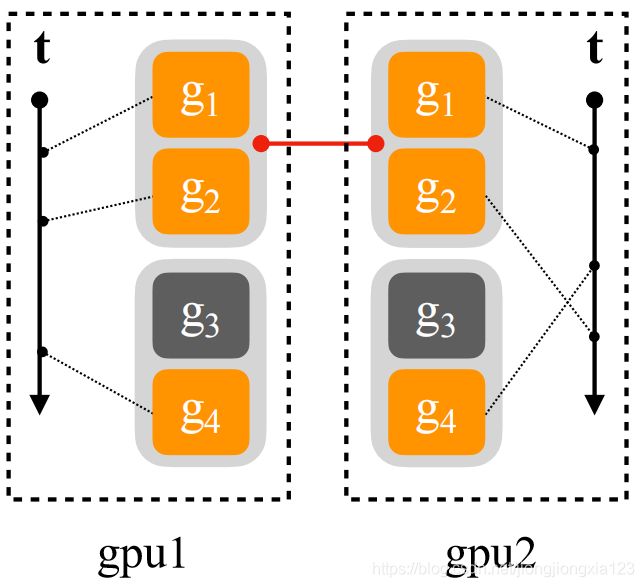
为了解决上述问题,设计了前向传播过程中遍历每一个参数,并且确认其对应的算子是否在前向传播过程中被调用。如果某个参数对应的算子在前向传播中被调用,则该算子对应的参数在反向传播中一定会计算梯度并被传入某个bucket中。否则就将该参数标记为unused_parameters并将他在其所在的bucket中的状态置位ready,此时该参数虽然没有梯度,但不会block整个bucket的ready状态。当前iteration完成后,再将所有参数的unused状态清空,等待下一次iteration。
2.3.3 允许梯度累积
在某些清空下,也许不需要每一次iteration都进行各个gpu之间的通信来计算梯度的均值。比如希望加快数据并行分布式训练的速度,可以累积几个iteration的bucket,再进行一次communication;或者进行超大batch的训练,即使切分为若干个子batch后将每个子batch分配到单个gpu上仍然超出了单个gpu的显存,则可以把每个子batch再拆分为n个子子batch,这些子子batch在单个gpu上进行n次iteration后,再进行一次gpu通信。
为实现上述目的,设计了允许梯度累积的策略。具体来说,Pytorch的DistributedDataParallel模块提供了额外的接口(no_sync上下文)来实现允许若干个iteration内进行梯度累积后再进行gpu通信,如下sample code:
...
net = parallel.DistributedDataParallel(net)
with net.no_sync():
# below input&output will not arise communication
for inp, exp in zip(inputs, gt_labels):
output = net(inp)
loss = loss_fn(output, gt_labels)
# with no_sync() environment, gradients will just
# be accumulated, not communicated across gpus
loss.backward()
one_more_output = net(one_more_input)
loss = loss_fn(one_more_output, one_more_gt_label)
# gradients after this mini-mini batch will be calculated,
# together with those accumulated before, communicated across gpus
loss.backward()
opt.step()
三、DistributedDataParallel执行过程
3.1 执行过程伪代码
在通过DistributedDataParallel构造一个分布式训练模型时,初始化函数里主要完成两步:向各个gpu上广播模型的初始化参数和状态;在每个算子中注册反向传播的hook函数。forward函数中除了模型的前向传播以外,还会遍历所有parameter,确定那些在本次iteration中没有参与训练的算子,并将其对应的parameter设置为unused parameter。backward时除了模型正常的反向传播计算各个参数的梯度外,还通过hook函数得到当前参数的梯度,根据预先设定的index顺序将其添加进对应的bucket中,等待所有bucket的ready状态后触发gpu之间的reduce通信。下面2图分别为执行的伪代码和示意图:

3.2 sample code
根据一个toy example的sample code来解释如何在一般情况下应用DistributedDataParallel构建多节点多gpu上的分布式模型。在每个gpu上开启一个进程,负责当前gpu上的数据前向传播和反向传播。所有进程组成当前的进程组,DistributedDataParallel API自动获取当前进程组,并在进程组之间通过reduce_mean方法来完成各gpu上的梯度通信,将梯度均值分发给各个模型进行更新。
import os
from datetime import datetime
import argparse
import torch.multiprocessing as mp
import torchvision
import torchvision.transforms as transforms
import torch
import torch.nn as nn
import torch.distributed as dist
def train(gpu, args):
# 当前gpu上的进程在总进程组中的rank
rank = args.nr * args.gpus + gpu
# 通过pytorch的dist模块将当前进程加入进程组
dist.init_process_group(
backend='nccl',
init_method='env://',
world_size=args.world_size,
rank=rank
)
# 模型、损失函数和优化器等定义与普通模型相同
model = SomeModel()
# 如果模型中有原始的batchnorm,要记得通过下面一句将当前模型的所有普通batchnorm改成可在多gpu同步的syncbatchnorm,否则每个gpu单独使用当前的子batch计算的mean和variance训练,可能导致效果不好甚至不收敛。Syncbatchnorm也是在当前的进程组里找到其他的gpu进程,然后将各gpu的mean和variance做一个reduce_mean再分发。
# model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
torch.cuda.set_device(gpu)
model.cuda(gpu)
batch_size = 100
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
# Wrap the model
model = nn.parallel.DistributedDataParallel(model,
device_ids=[gpu])
# Data loading code
train_dataset = torchvision.datasets.MNIST(
root='./data',
train=True,
transform=transforms.ToTensor(),
download=True
)
# 使用DistributedSampler来进行数据集的采样,指定总gpu数量=节点数*每节点gpu数,当前gpu的rank,train_loader可以根据总子batch数和当前batch的index,为当前gpu产生对应的子batch
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
num_replicas=args.world_size,
rank=rank
)
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
# 这个batch_size是指单个gpu上的子batch_size,一次iteration的实际batch=batch_size * args.gpus * args.nodes
batch_size=batch_size,
# 这里的shuffle必须设置为False
shuffle=False,
num_workers=0,
pin_memory=True,
# 传入指定的sampler划分训练集
sampler=train_sampler)
start = datetime.now()
total_step = len(train_loader)
for epoch in range(args.epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
labels = labels.cuda(non_blocking=True)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0 and gpu == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(
epoch + 1,
args.epochs,
i + 1,
total_step,
loss.item())
)
if gpu == 0:
print("Training complete in: " + str(datetime.now() - start))
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--nodes', default=1,
type=int, metavar='N')
parser.add_argument('-g', '--gpus', default=1, type=int,
help='number of gpus per node')
parser.add_argument('-nr', '--nr', default=0, type=int,
help='ranking within the nodes')
parser.add_argument('--epochs', default=2, type=int,
metavar='N',
help='number of total epochs to run')
args = parser.parse_args()
# 每个gpu上开一个进程,总进程数=节点数*每节点gpu数
args.world_size = args.gpus * args.nodes
# 多个节点之间的相互通信,指定一个监听的主节点
os.environ['MASTER_ADDR'] = '10.57.23.164'
os.environ['MASTER_PORT'] = '8888'
# 通过multiprocessing模块开启多进程,train为各个进程上分配的执行函数,其被调用时,传入的参数是(index,args),其中index为当前进程在总进程组中的rank
mp.spawn(train, nprocs=args.gpus, args=(args,))
if __name__ == '__main__':
main()
不妨设总共用4个节点,每个节点有8个gpu,首先在主节点(即ip为10.57.23.164的节点)上执行:
python src/mnist-distributed.py -n 4 -g 8 -nr 0
然后在其余三个节点执行:
python src/mnist-distributed.py -n 4 -g 8 -nr 1
python src/mnist-distributed.py -n 4 -g 8 -nr 2
python src/mnist-distributed.py -n 4 -g 8 -nr 3
四、总结
相比于DataParallel,DistributedDataParallel是进一步的数据并行分布式训练,加速效果十分明显。通过构建多进程,避免了单进程多线程由于GIL对python解释器和相应资源的依赖;各gpu上单独计算每个子batch的前向传播和反向传播,gpu之间通信仅涉及到每个gpu上计算得到的梯度求reduce_mean,且通过设计策略充分利用了通信带宽。支持多节点多gpu的硬件架构,还可以结合apex扩展为混合精度训练,速度提升效果更佳。后面准备再写一篇关于混合精度训练相关的流水账。草草记录,如有不妥请指正。