【踩雷血泪总结】torchvision加载EMNIST数据集方法 完美解决缺少train.pt和Dataset not found问题
全网独家,含泪总结
emnist是mnist的扩展数据集,里面除了对手写数字mnist进行了新增外,还多了letters手写字母集,Digits集等,每个集都有自己的训练图,训练标签,测试图,测试标签4文件
写深度学习作业,用torchvision的datasets.EMNIST函数加载这个数据集,出现了识别不到的情况,网上没有完整的方法,自己琢磨两天,终于在底层代码找到了原因和解决办法
首先解决大多数人遇到的第一个问题:
一:从各路下载的EMNIST数据集只有emnist-×××-×××-images-idx××-ubyte ,没有training.pt和test.pt文件
从官网下的数据集肯定是最全的,但就算翻嫱下的也慢的一批,并且可能下了一半就报错,很多人用的是别人在百度云提供的转存,但只有idx-ubyte四人组,没有processed文件夹和文件夹内的两个 .pt文件,巧了,torchvision.datasets.EMNIST()这个函数第一个参数就是要检查.pt文件的位置,没有就开门红√
解决:github上一个老哥提供了EMNIST全系列的.pt文件,需要哪个下哪个github链接

例如我就用emnist的letters系列,把解压出的processed放到EMNIST文件夹下,同目录下还有raw,存放的是之前下的四个ubyte文件。看下图,数据集加载函数的第一个参数是EMNIST所在的文件夹,这里我的是mnist_data,不用包括到EMNIST


二、紧接着第二步,让函数读到你下载的emnist数据集
直接运行你会发现根本识别不出,download=False会直接提示
Dataset not found. You can use download=True to download it(这一句报错看了两天,再看到真的条件反射头大)
网上有人说改download=True 一步到胃,我也不知道你是怎么到位的,改完直接开始从官网下了,然后就是无止境的下一半崩溃,崩溃再下,本质你还是没找到它想要的文件
它想要的到底是什么?要ubyte给了,要training.pt test.pt也给了,还是欲求不满,继续压榨无辜网民?
我们直接定位到site-package里的torchvision库,打开这个万恶的底层文件,进去就直奔EMNIST部分。
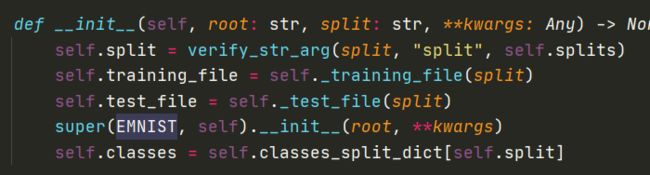
几番阅读,终于注意到上图这部分中,第三行的training_file和第四行的test_file规定了如何识别所需的.pt文件,我们点进第三行:

好家伙,在这等着我呢,原来,它所要看到的不仅仅是你有training.pt文件,而且要把文件名改成training_letters.pt,这个letters指的是系列,是参数split,也是要填进torchvision.datasets.EMNIST()的第二个参数。
解决:我们拐回到processed文件夹,进行修改:
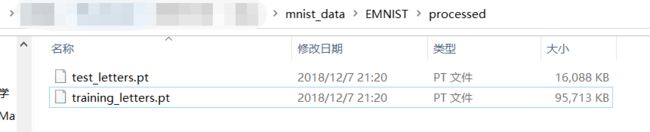
运行,不报错不重下,大功告成。