烧脑干货|OceanBase创始人阳振坤:如何劈开关系数据库的枷锁?
以下内容是根据阳振坤在是在友盟+举办的2019UBDC全域大数据峰会上的演讲,在不改变原义的基础上整理编辑:
如今,数据库其实距离大家并不遥远,每个人都在用,无论是坐地铁、坐飞机、坐高铁,还是吃饭、刷手机,这后面其实都有数据库的存在,但真正做它、理解它的人却很少。
![]()

(图为:OceanBase创始人 阳振坤)
今天,我将围绕以下三点内容,帮助大家“劈开关系数据库的枷锁”,真正了解什么是数据库:
1、数据库的背景
2、OceanBase的突破
3、TPC-C benchmark
现在几乎所有的企业都要用到数据库,主要就是在做两件事:
第一个是做交易。大家去买东西,去做任何事情,后面都有一套交易系统、业务系统在支撑。事实上,数据库是一个很正常的矛盾体,它最有价值的东西就是它的事务,最困难的也是它的事务。原子性、一致性、隔离性或持久性,这些内容我已经说了快10年了,但是最难做的事也是这些。因为它难做,所以数据库从诞生到发展到今天一直是集中式的,说直白了本质上就是单机,一台机器来做。

第二个是做商业智能分析。举个例子,公司都有业务系统、销售系统,做销售的都知道,团队与公司都想对比了解今年跟去年的情况,这个月对比上个月又是怎样的,以及华东跟华南现在的状况是怎么样的,大家都需要看这些报表数据。只有了解了这些结果,才能决定下个季度的策略。数据库这么多年来一直就在干这件事。
数据库的挑战
商业数据库曾经做的很好,但互联网出现后,整个数据库的访问量增长了几百倍、几千倍,数据量也随之大涨。因为数据库是集中式的,本质上是单机系统,存也存不下,处理也处理不了,所以进入互联网时代之后,数据库一直面临着严峻的考验。
但是另一方面,业务还得继续发展,于是大家开始想办法,分析做不了那就做一个叫作“数据仓库”的东西。在数据库跟数据仓库之间还得加上一个桥梁,因为原来都是在一个数据库里面,现在变成了两个系统,就需要把数据抽取、转换,然后再加载到数据仓库。
事实上,数据仓库的诞生也带来了很多其他的问题。
比如分库分表,数据没有一致性了,系统整个伸缩也面临很大的挑战。“伸”还比较简单,我可以把一个库变成四个库、八个库,但是如果你想把四个库变成两个库、一个库,操作起来就非常困难了。
此外,数据仓库还带来了数据冗余。因为数据仓库是特定面向主题,具有方向性的,而关系数据库从来没有说面向一个主题建一个关系数据库,因为它就只有一个。数据仓库还有一个问题是它做不了实时的更新,如果它能做实时更新,就变成了交易处理的数据库了,所以这方面也会带来很大的挑战。
为什么关系数据库一定要做成集中式的?
第一个问题是在所谓的事务上,因为事务要做成原子的。下面简单说一下数据库里面的事务。

以银行转帐为例,A给B转100块钱,假如图中的这个球就是100块钱,用户是看不到中间过程的,只能看得到一个原子的结果。这100块钱如果在A这边看到没转,那B肯定没收到。如果A这边转了,B一定是收到了,中间没有延时,不能说等一会B才能收到。所以,当两个账户如果在一台机器上的时候,人们有一些比较成熟的办法,但是当他们在两台机器上的时候这件事情就会变得非常困难,因此数据库大师想了一个办法,将它变成了两个阶段:
第一个阶段,通知A这台机器,说你检查一下A这个账户有没有钱,他是不是至少有100块钱,他的账户是不是正常的。同时通知B那台机器也检查那个账户是否正常,正常就把这两个账户都锁住,锁住的时间也许很短,就零点几毫秒,不让别人来读,也不让别人来写,如果都正常就走到第二步。但是如果其中一个有问题,账就转不了。走到第二步之后,当A扣了100块钱,B多了100块钱时,这个锁就会被打开,这样外面就能看到了。
在这过程中出现的最大的问题是,比如A这个节点突然异常了,那B那100块钱加不加,加的话,如果A这台机器的硬盘真的坏掉了,换了一台机器,那台机器是不知道有这100块钱转账的,系统的账就不平了。如果不加,万一A这台机器是假死的,过一会儿又回来了,然后A这边把100块钱扣除了,但是B这边又没有加上。这也是导致分布式数据库这么多年没有应用于交易处理的原因。
第二个原因是分布式系统有一个可用率,当你把100台机器放在一起的时候,这100台机器的可用率会发生指数变化,就是100次方,所以整个系统随着机器的增加,可用率会指数级下降。
对于蚂蚁金服来说,我们在做数据库的时候,天时、地利、人和都赶上了。
天时是需求的增加,互联网的数据量、访问量增加了这么多,原来的集中式肯定抗不住。同时,最关键的是地利,阿里巴巴说商业成就了技术,技术成就了商业,当时我们内部就有成千上万的数据库。还有一个因素就是我们的分布式背景,单机不行,集中做不了了,那只能做分布式,正好我们的一些同事当时拥有分布式的背景,所以说几个机会我们全部都赶上了。
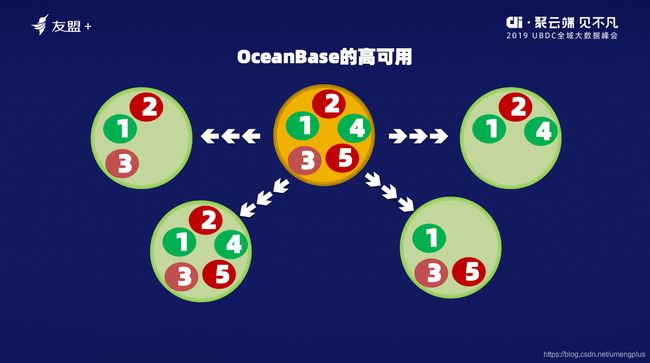
数据库一般是有主库和备库的,如果主库出了问题把备库顶上就行了,但是特别遗憾的是,在数据库的交易处理场景里做不到备库跟主库一致。现实中,每秒种可能要处理几千、几万笔事务,在这个过程中,你需要将主库同步到备库,但备库一旦有抖动或者网络出现问题,主库就有大批事务要积压,资源就全耗尽,这时主库就无法工作了,同时意味着业务就断了,这比数据丢失更可怕。
对此,我们做的就是引入了一个投票机制。一个备库不行,就引入两个备库。两个备库都同步时,不要求它们都同时收到,但只要有一个收到就行,相当于说有一个落地,这样任何一台机器出问题,剩下的两台机器中至少有一台有数据,所以它就能很快自动恢复。
事实上,这种两台机器同时坏的概率极低,但如果有人为因素的时候,它的概率就不是自然概率了,如果人为关了一台机器,自然还会再坏一台机器,所以我们在做特别重要的业务时,用的不是三台,而是五台机器,一个主库用四个备库来写日志,这样不需要每个都写成功,只要超过半数的写成功就能够解决问题了。
OceanBase是从2010年开始做的,目前应用最多的是蚂蚁金服,也就是支付宝,绝大部分数据库现在都在OceanBase上。还有一个就是网商银行,网商银行成立的那天起,它所有的数据库用的都是OceanBase。
TPC Benchmark
刺激数据库发展的一个很大原因,是自动提款机出来之后,大家发现数据库变得很重要了,它需要做在线交易处理,那时候厂商都想把数据库卖给客户,都说自己的性能好,但是没有一个统一的东西。
直到1984年Jim Gray(后来的图灵奖的获得者)提出了一个模型,这个模型后来成为了我们做交易处理跑分的基础,今天跑分的东西都还是基于他这个模型在做,但随着时代、技术、软件、硬件还有业务的发展,这个技术一直在持续发展完善。
当初他提出这个模型的时候,很多人以为说现在有标准了,大家的benchmark终于可以统一了,其实不是,用当时的话说水变得更浑了,因为有的厂商偷工减料改模型,把这个模型改的适合自己,跑出更高的分。几年后,Omri Serlin,他是一个工业分析师,说服了八家公司,成立了TPC组织,这个组织其实就在做两个事情:
第一立法,把Jim Gray的模型变成一个可以执行的标准;
第二执法,不是单纯跑一个结果,要审核全部过程,以免有人做偷工减料的事情,不仅要审核结果,还要审核过程。

我们这次做的TPC-C的Benchmark其实是一个在线交易处理的Benchmark,它的基本单位是仓库,一个仓库有10个销售点,每个销售点有3000个顾客,模拟的是某个顾客到他对应的销售点去买东西。买什么呢?买商品,平均10件,最少5件,最多15件。每一件商品可能本地还不一定有,有一定的概率是异地,1%,所以平均每一次的购买,就是一个订单里面大概有10%出现异地仓库的概率,如果你在分布式系统下它就变成分布式事务。
在这个系统里,无法堆砌机器就能跑出来好成绩,因为你必须要先过数据库事务的测试,在多机下也就是分布式事务。
还有就是订单支付,订单创建是45%,也就是每100笔事务里有45笔是订单创建,还有43笔是订单支付,这个支付大概有15%的概率是异地,还有3种事务是订单的查询、订单的配送和库存的查询。
整体上来看,这其中超过百分之十的事务是分布式事务,你要解决不了分布式事务,根本就过不了这个测试所要求规定的功能,那性能就更谈不上了。而且它还有一些限制,每个仓库你只能有12.86个tpmC,最终你按照这样的5种事务的混合比例跑,每分钟你跑出来的交易订单创建的个数就叫tpmC。
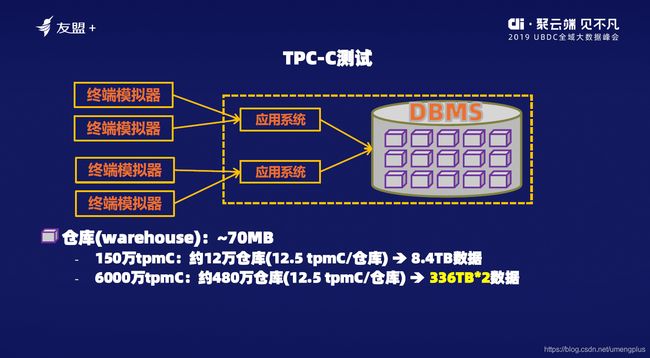
以上是它的整个模型,一个人跑到他对应的销售点,用一个销售终端买东西,就是这么简单。
假设你的性能是150万tpmC,那就是每一分钟的订单创建有150万,实际上做的时候大概有300多万,订单创建只占45%,不到一半。大概对应下来的数据量要8个多TB的数据,我们做6000万tpmC,要多少个仓库呢?大约480万个仓库。这些仓库上的数据还要乘以2,因为我们没有用共享存储,用普通的PC服务器,而且是虚拟机,机器故障数据是可能丢的,要保证持久性,所以我们的数据成了2分,日志成了3分。

还有一些限制,第一要审核,从过程到结果,都要审核。第二要求系统提供60天的压测存储空间,压测一天数据会增长,相当于提供60倍的增长的空间。
另外,要想测试跑分,要先测功能。这里面所谓的事物的原子性、一致性、隔离性、持久性是前提,还有其它的好多要求,这只是其中比较重要的一块。然后要测性能,要跑8个小时,性能测试至少跑2个小时,要求性能波动不能超过2%。
这个结果出来之后,就处在了所谓的60天公示期,任何人都可以提出问题,提出质疑,如果有人提出来,我们都要回答他。60天过了之后,结果成为了active,意味着用户能以披露书上的价格买到整套系统,这个价格包括软件、硬件以及3年的服务。再往后,如果用户无法再以这个价格购买到整套系统,比如硬件不再生产了,这个记录就变成了历史记录(history)。

我们可以比较一下最近的3个榜首,最早是在2010年8月份,IBM用了3台Power780做出来的,这也是整个TPC-C结果里第一次过1000万tpmC。
IBM位置没有坐多久,4个月不到的时间,Oracle又做出了更高的结果,还是集中式的,用了27台计算工作站和97台存储,每一台存储里都有一台X86服务器,用这个做到了3000多万。
大家会问我们为什么今天有底气做呢?因为我们是分布式。

这是我们一些简单的数据,一共用了210台数据库,其实真正用做数据处理的是204台,最早是201台,后来不到原来第一名的2倍,加了3台。还有3台做管理的。另外还有3台做系统监控。我们是真的按照生产系统来部署的。
我们用虚拟机,虚拟机所在的物理机不管是内存还是CPU都超过50%,如果用物理机性能起码还能提升50%。
今天我们具备了交易处理能力,作为一个分布式数据库,具备商业智能处理分析能力只是时间问题。因为数据库最难过的坎是交易处理,你做不了交易处理,系统就没有数据,只能像数据仓库那样去做数据分析。如果你有交易处理能力,并且是分布式系统,那就意味着你既能够做交易处理,还能够同时做分析处理。
期待展望
传统数据库发展了这么多年,一直是一个集中式的枷锁,限制约束就摆在那儿。我们做的时候,听到了很多质疑的声音,说这个是曾经被判了死刑的东西。我们虽然有这么多用户,但大家说你还是不能证明你自己,现在我们通过了这个测试,不止是性能,更关键是整个测试证明我们具备了做交易数据库的处理能力。
接下来我们要做的事情,就是一方面把我们的功能补全,另一方面把交易处理+商业智能分析功能发展起来,让我们的用户能够更好地用这个系统。