问题
JuiceFS 是一个基于对象存储的分布式文件系统,在之前跟对象存储比较的文章中已经介绍了 JuiceFS 能够保证数据的强一致性和极高的读写性能,因此完全可以用来替代 HDFS。但是数据平台整体迁移通常是一个费时费力的大工程,需要做到迁移超大规模数据的同时尽量不影响上层业务。下面将会介绍如何通过 JuiceFS 的迁移工具来实现平滑迁移 HDFS 中的海量数据到 JuiceFS。
平滑迁移方案
数据平台除了我们在 HDFS 上实际看到的文件以外,其实还有一些同样重要的信息,也就是所谓的「元数据」,这些元数据存储在类似 Hive Metastore 这样的系统里。因此当我们谈论数据迁移时不能把这两种数据拆分开来,必须同时考虑,迁移完数据以后需要同时更新 Hive 表或者分区的位置(LOCATION)信息,如果任何一种数据出了问题都会对业务方造成影响。
为了保证数据和元数据的一致性,通常的做法是在迁移完数据以后同步更新元数据中的位置信息,但当数据规模比较大,并且业务又可能更新数据时,很难保证数据拷贝和更新位置信息是个原子操作,迁移过程中可能导致数据丢失,影响整体迁移的可靠性。甚至需要以暂停业务为代价来实现,或者在业务中采用双写等机制来实现在线迁移,侵入业务逻辑,费时费力。
如果能够在迁移过程中为数据访问提供统一的路径来屏蔽实际的数据位置,实现元数据和真实数据位置的解耦,将会大大降低整体迁移的风险。文件系统的符号链接就可以达到这个效果,JuiceFS 也支持符号链接,并且支持跨文件系统的符号链接,借助它可以为多个文件系统提供统一的访问入口,形成统一命名空间。
符号链接是操作系统中广泛应用的概念,你可以通过符号链接实现在一个目录树中管理分散在各个地方的数据。对应的,我们也可以通过 JuiceFS 的符号链接特性实现在一个文件系统中管理多个存储系统。其实符号链接这个功能早在 2013 年 Hadoop 社区就已经想要在 HDFS 上实现(HADOOP-10019),但遗憾的是目前为止还没完整支持。借助符号链接即可在 JuiceFS 上管理包括但不限于 HDFS、对象存储在内的各种存储系统,表面上看起来访问的是 JuiceFS,但实际访问的是底层真实的存储。
同时,JuiceFS 的原子重命名(rename)操作也能在数据迁移过程中发挥关键作用。JuiceFS 通过符号链接来跳转回原始数据,但当数据完全拷贝过来以后需要覆盖这个符号链接,这个时候原子重命名就能保证数据的安全性和可靠性,避免出现数据丢失和损坏。
此外,JuiceFS 还可以通过配置文件和特殊的标志文件来动态感知到迁移过程,并在新增和删除文件时进行额外的检查,确保新创建的文件也会出现在迁移后的目录中,并且确保要删除的文件也能从新系统中删掉。对于更复杂的重命名操作,也有类似的机制来保证正确性。
有了刚才介绍的 JuiceFS 的这些特性,就可以实现在数据迁移时分别迁移数据和元数据,同时整个迁移过程对于业务是完全透明的。下面讲解具体的迁移操作步骤。
操作步骤
步骤一:将 JuiceFS 作为 HDFS 的访问入口
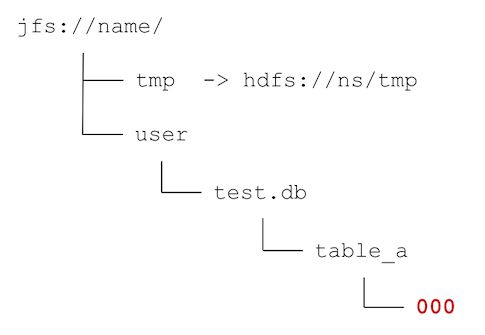
在 JuiceFS 上给 HDFS 的所有第一级目录(或文件)创建对应的符号链接(假定不会再在 HDFS 根目录创建内容),之后通过 jfs://name/ 就能完整访问 HDFS 里面的内容,两者是完全等价的。如下图所示。

步骤二:使用 JuiceFS 来访问 HDFS 中的数据
这一步有两种实现方法。第一种是修改 Hive Metastore 中表或者分区的 LOCATION 为对应的 JuiceFS 路径,例如之前是 hdfs://ns/user/test.db/table_a,新路径则为 jfs://name/user/test.db/table_a。第二种方法是将 fs.hdfs.impl 修改为 com.juicefs.MigratingFileSystem,这样可以维持 LOCATION 不变。
这两种方法的目的都是为了将所有访问 HDFS 的入口改成访问 JuiceFS,因为步骤一已经创建了指向 HDFS 的符号链接,所以不会影响现有业务访问 HDFS。
步骤三:迁移目录结构
从这一步开始我们会正式进行迁移工作,不过先不着急把数据拷贝过来,我们需要先把目录结构从 HDFS 中映射过来。你可以选择你想要迁移的表或目录,然后通过 JuiceFS 提供的工具快速将 HDFS 上的目录结构迁移到 JuiceFS 上。以迁移 hdfs://ns/user/test.db/table_a 为例,这个目录中的所有子目录将会逐级在 JuiceFS 中创建。因为这一步仅涉及元数据操作,没有数据拷贝,因此可以以极快的速度将历史数据的目录结构从 HDFS 迁移到 JuiceFS 上。同时需要注意的是,所有文件仍然通过符号链接的方式指向 HDFS 中的路径。如下图所示,红色部分即表示在 JuiceFS 上新创建的目录。

同样的,完成这一步以后不会影响现有业务访问 HDFS,但是新写入的数据将会直接存储到 JuiceFS 中。
步骤四:迁移数据
这一步将会真正开始拷贝数据,通过 JuiceFS 的迁移工具并发地将上一步遗留的指向 HDFS 中普通文件的符号链接替换为真实的数据。最终迁移目录中将不再会有符号链接,也就表示这个目录已经迁移完成。如下图所示,红色部分已经从符号链接变成了普通文件。
反向迁移
在数据迁移过程中也可以通过反向迁移随时回滚,来撤销迁移操作。如果已经修改了元数据中的位置信息,JuiceFS 迁移工具能确保反向迁移时恢复回原来的状态。如果已经有新增的数据写入到 JuiceFS 中,也能把这些新增数据拷贝回原始的存储系统。
总结
通过前面的操作步骤介绍,可以看到整个迁移过程完全不会影响现有业务继续访问 HDFS,从开始到结束对于业务来说都是无感知的。JuiceFS 提供了完善的工具来简化迁移流程,详细的操作指南请参考 JuiceFS 官方文档。
本篇文章以将 HDFS 迁移到 JuiceFS 为例说明了 JuiceFS 的符号链接特性,其实你完全可以发挥脑洞,把 JuiceFS 的符号链接应用在更多更广的场景,例如在不同 HDFS 集群之间进行数据迁移、跨云跨区的数据迁移等。正是因为有了强大的符号链接特性,通过 JuiceFS 来提供统一的数据访问层和视图,才使得很多时候无法平滑操作的事情成为了可能。
推荐阅读:知乎 x JuiceFS:利用 JuiceFS 给 Flink 容器启动加速
如有帮助的话欢迎关注我们项目 Juicedata/JuiceFS 哟! (0ᴗ0✿)