Python - 高级动态编程语言 - 入门基础知识(上)
Python 概述
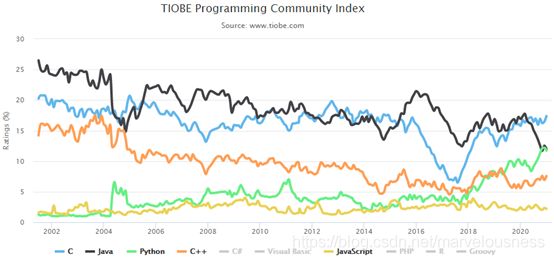
2021年1月的TIOBE指数
January Headline: Python is TIOBE’s Programming Language of 2020!
Python has won the TIOBE programming language of the year award! This is for the fourth time in the history, which is a record! The title is awarded to the programming language that has gained most popularity in one year. Python made a positive jump of 2.01% in 2020. Programming language C++ is a very close runner up with an increase of 1.99%. Other winners are C (+1.66%), Groovy (+1.23%) and R (+1.10%).
It has been stated before: Python is popping up everywhere. It started as a competitor of Perl to write scripts for system administrators a long time ago. Nowadays it is the favorite language in fields such as data science and machine learning, but it is also used for web development and back-end programming and growing into the mobile application domain and even in (larger) embedded systems. The main reasons for this massive adoption are the ease of learning the language and its high productivity. These two qualities are key in a world that is craving for more developers in all kinds of fields. Python already tested the second position some months ago and it will for sure swap places with Java permanently soon. Will Python also beat C? Well, C has still one trump card to play: its performance, and this will remain the case for some time to come. So I guess it will certainly take some years for Python to become the new number 1 in the TIOBE index.
上文摘自 TIOBE在2021年1月发布的文章,文章开篇就介绍了Python赢得了年度TIOBE编程语言奖!是历史上第四次创下纪录!标题被授予在一年中最受欢迎的编程语言。Python在2020年实现了2.01%的正增长。
通过下图的增长趋势图,不难看出,Python 逐年增长,并有望与 Java 交换位置。
Python 起源
Python,由荷兰人吉多·范罗苏姆(Guido van Rossum)于1989年圣诞节期间发明。第一个公开发行版发行于1991年。
1982年,Guido从阿姆斯特丹大学(University of Amsterdam)获得了数学和计算机硕士学位。然而,尽管他算得上是一位数学家,但他更加享受计算机带来的乐趣。用他的话说,尽管拥有数学和计算机双料资质,他总趋向于做计算机相关的工作,并热衷于做任何和编程相关的活儿。在那个时候,他接触并使用过诸如Pascal、C、 Fortran等语言。这些语言的基本设计原则是让机器能更快运行。
在80年代,个人电脑的配置较之如今是极低的,比如早期的Macintosh,只有8MHz的CPU主频和128KB的RAM,一个大的数组就能占满内存。所有的编译器的核心是做优化,以便让程序能够运行。为了增进效率,语言也迫使程序员像计算机一样思考,以便能写出更符合机器口味的程序。而正是因为这一点,让Guido感到苦恼。他认为这样编写程序实在是太过于耗费时间,于是他想到了shell。Bourne Shell作为UNIX系统的解释器(interpreter)已经长期存在。UNIX的管理员们常常用shell去写一些简单的脚本,以进行一些系统维护的工作,比如定期备份、文件系统管理等等。shell可以像胶水一样,将UNIX下的许多功能连接在一起。许多C语言下上百行的程序,在shell下只用几行就可以完成。然而,shell的本质是调用命令,它并不是一个真正的语言,shell不能全面的调动计算机的功能。
于是,Guido开始思考,是否能设计一款语言,使它同时具备C与shell的优点,既能够全面调用计算机的功能接口,又可以轻松编写程序。
后来他进入到荷兰的CWI(Centrum Wiskunde & Informatica, 数学和计算机研究所)工作,并参加了ABC语言的开发。ABC语言以教学为目的。与当时的大部分语言不同,ABC语言的目标是“让用户感觉更好”。ABC语言希望让语言变得 容易阅读,容易使用,容易记忆,容易学习,并以此来激发人们学习编程的兴趣。比如下面是这一段ABC程序的源码:
HOW TO RETURN words document:
PUT {} IN collection
FOR line IN document:
FOR word IN split line:
IF word NOT.IN collection:
INSERT word IN collection
RETURN collection
HOW TO用于定义一个函数。一个Python程序员应该很容易理解这段程序。ABC语言使用冒号和缩进来表示程序块(C语言使用成对的大括号来表示程序块)。行尾没有分号。FOR和IF结构中也没有括号。如果将HOW TO改为def,将PUT行改为collection = [],将INSERT行改为collection.append(word),这就几乎是一个标准的Python函数。上面的函数读起来就像一段自然的文字。
尽管已经具备了良好的可读性和易用性,ABC语言最终没有流行起来。在当时,ABC语言编译器需要比较高配置的电脑才能运行。而这些电脑的使用者通常精通计算机,他们更多考虑程序的效率,而非它的学习难度。除了硬件上的困难外,ABC语言的设计也存在一些致命的问题:可拓展性差,不能直接IO,过度革新与传播困难,导致它不为大多数程序员所接受(因为语法上的过度革新,加大了程序员的学习难度)与传播。
除去这些缺点,我们不难看出,ABC就Guido心中所期望的语言的雏形。
1989年圣诞节期间,在阿姆斯特丹,Guido为了打发圣诞节的无趣,决心开发一个新的脚本解释程序,作为ABC 语言的一种继承。而为其命名为Python,是取自他挚爱的一部电视剧Monty Python’s Flying Circus 。
1991年,第一个Python编译器诞生,它是用C语言实现的,并能够调用C库(.so文件)。从一出生,Python已经具有了:类(class),函数(function),异常处理(exception),列表(list)和字典(dictionary)在内的核心数据类型,以及模块(module)为基础的拓展系统。
Guido为防止重蹈ABC的覆辙,着重注意Python的可扩展性,并且也沿用了C中的大部分语法习惯,而这,使Python得到Guido同事的欢迎。他们迅速的反馈使用意见,并参与到Python的改进。
九十年代初,个人计算机开始进入普通家庭。Intel发布了486处理器,windows发布window 3.0开始的一系列视窗系统,计算机的性能大大提高。由于计算机性能的提高,软件的世界也开始随之改变。硬件足以满足许多个人电脑的需要。硬件厂商甚至渴望高需求软件的出现,以带动硬件的更新换代。C++和Java相继流行。C++和Java提供了面向对象的编程范式,以及丰富的对象库。在牺牲了一定的性能的代价下,C++和Java大大提高了程序的产量。语言的易用性被提到一个新的高度。
我们还记得,ABC失败的一个重要原因是硬件的性能限制。从这方面说,Python诞生在一个幸运的时间。Python要比ABC幸运许多。
另一个悄然发生的改变是Internet。九十年代还是个人电脑的时代,windows和Intel挟PC以令天下,盛极一时。尽管Internet为主体的信息革命尚未到来,但许多程序员以及资深计算机用户已经在频繁使用Internet进行交流 (包括email和newsgroup)。Internet让信息交流成本大大下降。一种新的软件开发模式开始流行:开源 (open source)。程序员利用业余时间进行软件开发,并开放源代码。1991年,Linus在comp.os.minix新闻组上发布了Linux内核源代码,吸引大批hacker的加入。Linux和GNU相互合作,最终构成了一个充满活力的开源平台。
由于Internet随个人电脑的普及而为人们所广知,许多程序员以及资深计算机用户频繁使用Internet进行交流,这使得Python没有了硬件上的束缚与传播上的困难,再加上Python易于使用的特点,使Python得到了一定程度上的传播。
硬件性能不是瓶颈,Python又容易使用,所以许多人开始转向Python。Guido维护了一个mail list,与Python用户通过邮件进行交流。因为Python用户来自许多领域,有不同的背景,对Python也有不同的需求。Python相当的开放,又容易拓展,所以当用户不满足于现有功能,很容易对Python进行拓展或改造。随后,这些用户将改动发给Guido,并由Guido决定是否将新的特征加入到Python或者标准库中。这就使得不同领域的优点集中于Python。
后来的Python2.0,从mail list的开发方式,转为完全开源的开发方式, python的数据库的扩展速度与传播速度也由此更进一步。
到今天,Python的框架已经确立。Python语言以对象为核心组织代码(Everything is object),支持多种编程范式(multi-paradigm),采用动态类型(dynamic typing),自动进行内存回收(garbage collection)。Python支持解释运行(interpret),并能调用C库进行拓展。Python有强大的标准库 (battery included)。由于标准库的体系已经稳定,所以Python的生态系统开始拓展到第三方包。
Python已经进入到3.x的时代。由于Python 3.0向后不兼容,所以从2.x到3.x的过渡并不容易。另一方面,Python的性能依然值得改进,Python的运算性能低于C++和Java。Python依然是一个在发展中的语言。
Python 设计定位
Python的设计哲学是“优雅”、“明确”、“简单”。
因此,Perl语言中“总是有多种方法来做同一件事”的理念在Python开发者中通常是难以忍受的。Python开发者的哲学是[“用一种方法,最好是只有一种方法来做一件事”]。在设计Python语言时,如果面临多种选择,Python开发者一般会拒绝花俏的语法,而选择明确的没有或者很少有歧义的语法。由于这种设计观念的差异,Python源代码通常被认为比Perl具备更好的可读性,并且能够支撑大规模的软件开发。这些准则被称为Python格言。在Python解释器内运行 import this 可以获得完整的列表。
Python开发人员尽量避开不成熟或者不重要的优化。一些针对非重要部位的加快运行速度的补丁通常不会被合并到Python内。所以很多人认为Python很慢。不过,根据二八定律,大多数程序对速度要求不高。在某些对运行速度要求很高的情况,Python设计师倾向于使用JIT技术,或者用使用C/C++语言改写这部分程序。可用的JIT技术是PyPy。
Python是完全面向对象的语言。函数、模块、数字、字符串都是对象。并且完全支持继承、重载、派生、多继承,有益于增强源代码的复用性。
Python支持重载运算符和动态类型。相对于LISP语言(LISP,List Processing的缩写)这种传统的函数式编程语言,Python对函数式设计只提供了有限的支持。有两个标准库(functools, itertools)提供了Haskell和Standard ML中久经考验的函数式程序设计工具。
虽然Python可能被粗略地分类为“脚本语言”(script language),但实际上一些大规模软件开发计划例如Zope、Mnet及BitTorrent,Google也广泛地使用它。Python的支持者较喜欢称它为一种高级动态编程语言,原因是“脚本语言”泛指仅作简单程序设计任务的语言,如ShellsSript、VBScript等只能处理简单任务的编程语言,并不能与Python相提并论。
Python本身被设计为可扩充的。并非所有的特性和功能都集成到语言核心。Python提供了丰富的API和工具,以便程序员能够轻松地使用C、C++ 来编写扩充模块。Python编译器本身也可以被集成到其它需要脚本语言的程序内。因此,很多人还把Python作为一种“胶水语言”(glue language)使用。使用Python将其他语言编写的程序进行集成和封装
在Google内部的很多项目,例如Google Engine使用C++编写性能要求极高的部分,然后用Python或Java/Go调用相应的模块。
《Python技术手册》的作者马特利(Martelli Alex)说:“这很难讲,不过,2004 年,Python 已在Google 内部使用,Google 召募许多 Python 高手,但在这之前就已决定使用Python,他们的目的是 Python where we can, C++ where we must,在操控硬件的场合使用 C++,在快速开发时候使用 Python。”
Python 之禅
Python解释器内运行 import this 可以得到由蒂姆·彼得斯写的 Python格言,原文如下:
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
优美比丑陋好
Explicit is better than implicit.
清晰比晦涩好
Simple is better than complex.
简单比复杂好
Complex is better than complicated.
复杂比错综复杂好
Flat is better than nested.
扁平比嵌套好
Sparse is better than dense.
稀疏比密集好
Readability counts.
可读性很重要
Special cases aren't special enough to break the rules.
特殊情况也不应该违反这些规则
Although practicality beats purity.
但现实往往并不那么完美
Errors should never pass silently.
异常不应该被静默处理
Unless explicitly silenced.
除非你希望如此
In the face of ambiguity, refuse the temptation to guess.
遇到模棱两可的地方,不要胡乱猜测
There should be one-- and preferably only one --obvious way to do it.
肯定有一种通常也是唯一一种最佳的解决方案
Although that way may not be obvious at first unless you're Dutch.
虽然这种方案并不是显而易见的,因为你不是那个荷兰人
[这里指的是Python之父Guido]
Now is better than never.
现在开始做比不做好
Although never is often better than *right* now.
不做比盲目去做好[极限编程中的YAGNI原则]
If the implementation is hard to explain, it's a bad idea.
如果一个实现方案难于理解,它就不是一个好的方案
If the implementation is easy to explain, it may be a good idea.
如果一个实现方案易于理解,它很有可能是一个好的方案
Namespaces are one honking great idea -- let's do more of those!
命名空间非常有用,我们应当多加利用
Python 特点
- 易学习:
Python有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单。
- 易阅读:
Python代码定义的更清晰。
- 易维护:
Python的成功在于它的源代码是开源的,非常容易维护。
- 丰富的社区支持:
Python的最大的优势之一是拥有丰富的库,跨平台的,在UNIX,Windows和Mac兼容很好。
- 可互式:
支持交互式编程,即可以从终端输入执行代码并获得结果,方便测试和调试代码片断。
- 可移植:
基于其开放源代码的特性,Python已经被移植(也就是使其工作)到许多平台。
- 可扩展:
如果你需要一段运行很快的关键代码,或者是想要编写一些不愿开放的算法,你可以使用C或C++完成那部分程序,然后从你的Python程序中调用。
- 可嵌入:
可以将Python嵌入到C/C++程序,让你的程序的用户获得"脚本化"的能力。
Python 不足之处
由于Python 是一种解释型语言,编写的代码就是执行码,这既是它的优点也是它的缺点。
Ø 慢
在 Python 程序执行的时候,由 Python 解释器一边读取源代码,一边执行,效率较低。
在开发高性能程序的时候基本上不会考虑 Python。但是在普通的不追求极致效率的应用级别的程序时,Python 慢的缺点体现得并不明显,而 Python 简单,高效得开发能力优势明显,所以大量使用。
Ø 无法加密
Python 程序发布的过程就是将源代码发布的过程,代码无法实现保密的效果,但也正是因为这样的特点决定了 Python 从语言层面上就是天然开源的,这也是 Python 社区快速发展的原因之一。
Python 应用广泛
Ø 网站开发: Django, Pyramid, Bottle, Tornado, Flask, web2py
Ø GUI开发: tkInter, PyGObject, PyQt, PySide, Kivy, wxPython
Ø 科学和数值运算: SciPy, Pandas, IPython
Ø 软件开发: Buildbot, Trac, Roundup
Ø 系统管理: Ansible, Salt, OpenStack
Python 开发环境搭建
Python下载和安装
官方下载地址:https://www.python.org/downloads/,可以在此链接中下载所有可用的 Python 发行版本以及对应版本的使用手册。安装好之后,将安装目录及其下的 script 目录配置到 PATH 中,使得 python 能在命令行中被使用:
Python 环境检测
通过 python -V 指令能查看到当前 python 的版本说明当前开发环境可用,或者通过命令行直接输入 python 能进入到 python 交互式界面则说明环境安装成功,例如:

Python 基础知识
Python 交互式编程
不需要创建脚本文件,是通过 Python 解释器的交互模式进来编写代码。例如通过命令行输入 python 指令进入到python 交互式界面后,python 会逐一执行输入的python代码,例如输入 print(“Hello World!”),回车后立即执行该行代码,如下图所示:

Python 脚本式编程
就跟C/Java等编程语言一样,需要编写源程序,不同的是,不需要将其编译成目标程序再执行,而是通过python解释器对源程序进行解释并执行,直到执行完毕。
Hello World
新建一个 Hello.py 文件,以 .py 为后缀的文件,一般被称之为为 Python 源程序或者脚本文件,在该文件中编写一行代码如下所示:
print("****Hello World****!")
解释并执行
在编写好脚本文件后,然后就可以通过 python Hello.py 命令调用 Python 解释器来解释并执行该脚本文件。
当然,如果在在Linux平台上,是可以直接使用 Python 命令的。因为在目前的绝大多数Linux发行版中,基本上都内置了 Python解释器,如下所示:
[root@centos ~]# python Hello.py
Hello World!
除此之外,我们还可以通过在脚本的第一行指明 python 解释器的具体位置来执行脚本,如下所示:
#!/bin/python
print(**"****Hello World****!"**)
在编写好脚本文件后,然后通过 chmod 命令将该文件的权限设置为可执行,然后就可以在当前目录使用 ./ Hello.py 来执行该脚本,如下所示:
[root@centos ~]# ./Hello.py
Hello World!
无论脚本中是否指定了解析器的具体位置,都可以通过 python Hello.py 命令调用解释器来解释并执行该脚本,这也是推荐的做法。
Python2.x 和 Python3.x 之间的差异
Python 的 3.0 版本,常被称为 Python 3000,或简称 Py3k。相对于 Python 的早期版本,这是一个较大的升级。
为了不带入过多的累赘,Python 3.0 在设计的时候没有考虑向下相容。为了照顾现有程式,Python 2.6 作为一个过渡版本,基本使用了 Python 2.x 的语法和库,同时考虑了向 Python 3.0 的迁移,允许使用部分 Python 3.0 的语法与函数。
大多数第三方库都正在努力地和Python 3.x 相容。即使无法立即使用 Python 3.0,也建议编写相容 Python 3.0 版本的程式,然后使用 Python 2.6 或者Python 2.7 来执行。
Python 3.0 的变化主要在以下九个方面(包括但不限于):
print 函数
在 2.x 中,使用 print 函数允许不带小括号,如下所示:
\>>> print "hello"
hello
在 3.x 中,使用 print 函数必须带小括号,如下所示:
\>>> print "hello"
File "" , line 1
print "hello"
^
SyntaxError: Missing parentheses in call to 'print'. Did you mean print("hello")?
Unicode
在2.x 版本中,其脚本文件的默认编码是 ASCII 格式,在没有修改编码格式时无法正确打印汉字,所以在读取中文时会报错,如下所示:
[root@centos ~]# python Hello.py
File "Hello.py", line 1
SyntaxError: Non-ASCII character '\xe4' in file Hello.py on line 1, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
针对该问题,我们需要在脚本文件开头声明其文件编码即可,也就是只要在文件开头加入 # -*- coding: UTF-8 -*- 或者 # coding=utf-8 。如下所示:
# coding=utf-8
print("您好!")
在3.x 中,其脚本文件的默认编码是 UTF-8 格式。所以可以正常解析中文,无需指定 UTF-8 编码。
除法运算
Python 中的除法有两个运算符, / 和 // 。我们以 10 ÷ 3 为例子来对比两个版本的运算结果,如下所示:
在 Python 2.7.5 中:
\>>> 10/3
3
\>>> 10//3
3
在 Python 3.8.7 中:
\>>> 10/3
3.3333333333333335
\>>> 10//3
3
不难看出,在 3.x 中, // 的作用就跟 C 语言或者 Java 语言中一样,直接舍掉小数位进行单纯的整型运算,而 / 的作用则会保留小数位。
异常
在 3.x 中,捕获异常的语法由 except exc, var 改为 except exc as var。我们以除以零为例子来对比两个版本的运算结果,如下所示:
在 Python 2.7.5 中:
try:
print(10 / 0)
except ZeroDivisionError, e:
print("除以零出错:" + e.__doc__)
在 Python 3.8.7 中:
try:
print(10 / 0)
except ZeroDivisionError as e:
print("除以零出错:" + e.__doc__)
xrange
在 2.x 中用于创建迭代对象的 xrange() 函数在 3.x 中被 range() 函数代替,使用对比入下所示:
在 Python 2.7.5 中:
for x in xrange(3):
print(x)
在 Python 3.8.7 中:
for x in range(3):
print(x)
八进制字面量表示
我们以十进制的 32 为例子来对比两个不同版本的八进制字面量表示形式,如下所示:
在 Python 2.7.5 中:
\>>> 040
32
在 Python 3.8.7 中:
\>>> 0o40
32
在 3.x 版本中需要将数字0和字母 o 作为前缀来表示这个字面量为八进制,这种格式在十六进制也是如此,十六进制需要将数字0和字母 x作为前缀来表示字面量。
不等运算符
在 2.x 中,不等于有两种写法 != 和 <> ,而在 3.x 中废弃了 <> 写法。
在 Python 2.7.5 中:
\>>> 2 != 3
True
\>>> 2 <> 3
True
在 Python 3.8.7 中:
\>>> 2 != 3
True
\>>> 2 <> 3
File "" , line 1
2 <> 3
^
SyntaxError: invalid syntax
废弃了repr表达式
在2.x 中反引号 相当于3.x 的repr函数的作用,在3.x 中去掉了这种写法,只允许使用repr函数。对比示例如下:
在 Python 2.7.5 中:
\>>> repr({"name":"timor", "age":3})
"{'age': 3, 'name': 'timor'}"
\>>> `{"name":"timor", "age":3}`
"{'age': 3, 'name': 'timor'}"
在 Python 3.8.7 中:
\>>> repr({"name":"timor", "age":3})
"{'name': 'timor', 'age': 3}"
\>>> `{"name":"timor", "age":3}`
File "" , line 1
`{"name":"timor", "age":3}`
^
SyntaxError: invalid syntax
数据类型
3.x 废弃了long类型
在3.x废弃了long类型,只保留一种整型——int,对比示例如下:
在 Python 2.7.5 中:
\>>> type(9999999999999999999)
<type 'long'>
在 Python 3.8.7 中:
\>>> type(9999999999999999999)
<class 'int'>
3.x 新增 bytes 类型
在3.x中,新增了bytes类型,对应于2.X版本的八位串,对比示例如下:
在 Python 2.7.5 中:
\>>> type(b'hello')
<type 'str'>
在 Python 3.8.7 中:
\>>> type(b'hello')
<class 'bytes'>
3.x 修改了字典的迭代器
在3.x 中,字典的 keys、items 和 values 方法的返回迭代器,都取缔了 2.x 中字典的iterkeys、iteritems 和 itervalues 方法。对比示例如下:
在 Python 2.7.5 中:
d = {"name": "timor", "age": 3}
for x in d.iterkeys():
print(x)
for x in d.itervalues():
print(x)
for x in d.iteritems():
print(x)
在 Python 3.8.7 中:
d = {"name": "timor", "age": 3}
for x in d.keys():
print(x)
for x in d.values():
print(x)
for x in d.items():
print(x)
编程规范
Python 代码行
-
通常一行就是一条语句,不需要分号。
-
如果将多行写在同一行,则需要通过分号断句,放置歧义。
-
Python 中并非使用大括号作为作用域的标识,而是采用制表符来标识作用范围的。
Python 注释
Python使用 # 作为单行注释的符号,也常用作脚本的特性声明,比如声明当前文档的编码,或者声明当前文档解释器的完整路径等。
Python 标识符
在 Python 中,所有的标识符可以包括英文,数字和下划线,但不能以数字开头。并且区分大小写。另外,Python 中的下划线具有特殊含义,在使用的时候需要注意以下几点:
-
使用单下划线开头的标识符代表不能访问的成员,类似 Java 中的 private
-
使用双下划线开头和结尾代表特殊成员专用的标识符,例如 init() 代表类的构造函数
Python 保留字
保留字不能用作常数或变数,或任何其他标识符名称,可以通过 Python 的文档中找到所有的所有的关键字的列表,如下所示:
| - | - | - | - | - |
|---|---|---|---|---|
| False | await | else | import | pass |
| None | break | except | in | raise |
| True | class | finally | is | return |
| and | continue | for | lambda | try |
| as | def | from | nonlocal | while |
| assert | del | global | not | with |
| async | elif | if | or | yield |
当然,不同的版本中,保留字不一定仅限于上表所示的保留字,具体的,可以通过导入关键字的模块来进行查看,如下所示:
\>>> from keyword import kwlist
\>>> print(kwlist)
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
\>>> len(kwlist)
35
Python 变量和常量
Python 没有声明引用的关键字,直接写标识符就是在声明一个引用变量,并且声明的引用变量没有类型的区别。也就是说同一个引用变量可以先后指向不同类型的数据。在需要的时候,可以使用 type 函数来获取引用变量的类型,如下所示:
x = 100
print(type(x))
x = 0o40
print(type(x))
x = 0x20
print(type(x))
x = 3.14
print(type(x))
x = 'A'
print(type(x))
x = "Hello"
print(type(x))
其输出结果如下所示:
<class 'int'>
<class 'int'>
<class 'int'>
<class 'float'>
<class 'str'>
<class 'str'>
在 Python 中约定,如果引用标识符采用全大写的书写形式就被称之为常量。需要注意的是,其本质依然是变量,python 解释器允许它的值被重新赋予。
运算符与表达式
算术运算符
| - | - |
|---|---|
| + | 求和 |
| - | 求差 |
| * | 求积 |
| / | 求商 |
| // | 整除(向下取整) |
| % | 取模 |
| ** | 乘方 |
示例:
\>>> a = 3; b = 2
\>>> a+b
5
\>>> a-b
1
\>>> a*b
6
\>>> a/b
1.5
\>>> a//b
1
\>>> a%b
1
\>>> a**b
9
关系运算符
| - | - |
|---|---|
| == | 等于 |
| != | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 不小于 |
| <= | 不大于 |
示例:
\>>> a = 3; b = 2
\>>> a==b
False
\>>> a!=b
True
\>>> a>b
True
\>>> a>> a>=b
True
\>>> a<=b
False
赋值运算符
| - | - |
|---|---|
| += | 求和赋值 |
| -= | 求差赋值 |
| *= | 求积赋值 |
| /= | 求商赋值 |
| //= | 整除赋值(向下取整) |
| %= | 取模赋值 |
| **= | 乘方赋值 |
示例:
\>>> a = 7; b = 2
\>>> a+=b; a,b
(9, 2)
\>>> a-=b; a,b
(7, 2)
\>>> a*=b; a,b
(14, 2)
\>>> a/=b; a,b
(7.0, 2)
\>>> a//=b; a,b
(3.0, 2)
\>>> a**=b; a,b
(9.0, 2)
\>>> a%=b; a,b
(1.0, 2)
位运算符
| - | - |
|---|---|
| & | 与 |
| | | 或 |
| ^ | 异或 |
| ~ | 取反 |
| << | 左移 |
| >> | 右移 |
示例:
\>>> 1&0
0
\>>> 1&1
1
\>>> 1|1
1
\>>> 1|0
1
\>>> 1^1
0
\>>> 1^0
1
\>>> 0^0
0
\>>> ~1
-2
\>>> ~0
-1
\>>> 4 << 1
8
\>>> 4 >> 1
2
Tips: 左右移运算符通常在做除 2及其倍数或 乘 2及其倍数的运算的的时候非常高效。
逻辑运算符
| - | - |
|---|---|
| and | 与 |
| or | 或 |
| not | 非 |
逻辑表达式的结果会使用标准真值程序来进行辨识,官方描述是:
If x is false or omitted, this returns False; otherwise it returns True
所以,针对数字来讲,非零即真,对其他引用类型来讲,非空即真
示例:
\>>> bool(1 and True)
True
\>>> bool(0 and True)
False
\>>> bool(0.0 and True)
False
\>>> bool(0.1 and True)
True
\>>> bool("" and True)
False
\>>> bool("Fasle" and True)
True
\>>> bool({} and True)
False
\>>> bool({"name": "timor"} and True)
True
\>>> bool([] and True)
False
\>>> bool([1] and True)
True
成员运算符
| - | - |
|---|---|
| in | 判断成员是否存在 |
| not in | 判断成员是否不存在 |
示例:
\>>> 1 in [1,3,5]
True
\>>> 2 in [1,3,5]
False
\>>> 3 not in [1,3,5]
False
\>>> "name" in {"name":"timor"}
True
\>>> "age" in {"name":"timor"}
False
\>>> "name" not in {"name":"timor"}
False
身份运算符
| - | - |
|---|---|
| is | 比较两个对象的存储单元(内存地址)是否是同一个 |
| is not | 比较两个对象的存储单元(内存地址)是否不是同一个 |
示例:
\>>> a=3; b=2
\>>> a is b
False
\>>> a is not b
True
\>>> id(a) == id(b)
False
\>>> id(a) != id(b)
True
\>>> a=2; b=2
\>>> a is b
True
\>>> a is not b
False
\>>> id(a) == id(b)
True
\>>> id(a) != id(b)
False
程序控制结构
为了保持程序结构的完整性,无论是分支结构还是循环结构,或者是类,函数,如果结构中没有任何语句,需要使用 pass 表示当前结构属于空结构。
分支结构
if True:
pass
if True:
print("It is true!")
else:
print("It is false!")
与 Java 中的 if 结构不一样的是,Python的if结构能为引用变量赋值,类似 Java 中的三元运算符,例如:
a = 3.14 if 100 > 100 else 2.68
循环结构
Python 支持 break 和 continue 关键对循环进行控制,其作用和 Java 中是一样的。
while 循环
x = 100
while x > 0:
print(x)
x -= 1
for 循环
for 循环被用来遍历任何序列结构,比如字符串,列表,元组等。如下所示:
tuples = ("timor", 1, 3.14)
for i in tuples:
print(i)
tuples = ["timor", 1, 3.14]
for i in tuples:
print(i)
通过 range(start, stop, step) 函数能按照 step为步长生成 [start, stop) 区间的序列,可用于在 for 循环中循环特定次数。如下所示:
for i in range(1, 30, 4):
print(i)
内置对象
| - | - |
|---|---|
| package | 用于获取当前模块的包名 |
| doc | 用于获取引用对象的文档描述 |
| name | 用于唯一标识导入系统中的模块。 |
内置函数
数学相关
| 函数名 | 函数说明 | 使用示例 |
|---|---|---|
| abs | 返回绝对值 | abs(-2) |
| divmod | 取两个(非复数)数作为参数, 当使用整数除法时,返回商和模的元组 | divmod(10, 3) |
| max | 返回指定元素的最大值 | max(2,3,4) |
| min | 返回指定元素的最小值 | min(2,3,4) |
| pow | 返回参数的乘方结果 | pow(2,3) |
| round | 四舍五入 | round(2.675) |
| sum | 求和 | sum([2,3,4]) |
类型相关
| 函数名 | 函数说明 | 使用示例 |
|---|---|---|
| ord | 返回表示Unicode字符码对应的整型数值 | ord(‘a’) |
| chr | 返回表示整型数值对应的Unicode字符码 | chr(97) |
| str | 返回字符串的表现形式 | str(1) |
| int | 返回十进制表示形式的整型 | int(“2”) |
| oct | 返回八进制表示形式的整型 | oct(32) |
| hex | 返回十六进制表示形式的整型 | hex(12) |
| float | 将参数转换为 float 类型 | float(2) |
| bin | 将整数转换为前缀为“0b”的二进制字符串。 | bin(10) |
| bool | 将参数转换为 bool 值,True 和 False 中的一个 | bool(10) |
| bytes | 将参数转换为 bytes 类型 | bytes(20) |
| list | 创建一个列表类型的对象 | list() |
| tuple | 创建一个元组类型的对象 | tuple() |
| dict | 创建一个字典类型的对象 | dict({}) |
| set | 创建一个集合类型的对象 | set() |
常用函数
| 函数名 | 函数说明 | 使用示例 |
|---|---|---|
| 打印输出 | print(“Hello”) | |
| input | 接收来自控制台输入的数据 | input() |
| type | 返回引用变量的类型 | type(2) |
| len | 返回容器中的元素总数 | len(“ok”) |
| range | 生成指定范围内的序列 | range(2,20,1) |
| enumerate | 返回序列的枚举对象,包含其元素和索引 | enumerate([33 , 99]) |
| sorted | 将序列进行排序 | sorted([2,3,4]) |
| reversed | 将序列进行反转 | reversed([2,3,4]) |
| zip | 生成一个迭代器,从每个iterable聚合元素 | zip([2,3], [5,6]) |
| all | 如果序列中所有的元素都为真则返回真 | all([0, 1]) |
| any | 如果序列中存在任意元素为真则返回真 | any([0, 1]) |
其他函数
| 函数名 | 函数说明 | 使用示例 |
|---|---|---|
| exit | 退出程序 | exit() |
| quit | 退出 | quit() |
| isinstance | 判断对象是否是某个类的实例 | isinstance(1, float) |
| issubclass | 判断字类是否是某个类的子类 | issubclass(C, A) |
| open | 打开一个文件 | open(“/a.txt”) |
| id | 返回对象的“标识”。 在 CPython 中指的是内存中对象的地址。 | id(1) |
| repr | 返回包含对象的可打印表示形式的字符串 | repr({“name”: “提莫”}) |
| ascii | 返回一个对象的可以打印的表现形式的字符串, 非 ASCII 字符串将采用\x, \u 或 \U 来转义 | ascii({“name”: “提莫”}) |
| eval | 对Python表达式进行分析和计算 | eval(“3+1”) |
| callable | 判断对象是否是可以被调用的 | callable(int) |
| delattr | 删除对象的属性,该属性是在构造器中被声明 | delattr(c, “gender”) |
| getattr | 获取对象的属性的值 | getattr(c, “name”) |
| hasattr | 判断对象的属性是否存在 | hasattr(c, “name”) |
| dir | 不带参数,返回当前本地作用域中的名称列表。 | dir() |
| help | 查看指定对象的文档介绍 | help() |
Python 数据结构
鸭子类型
一种编程风格,它不看对象的类型来确定它是否有正确的接口;相反,方法或属性被简单地调用或使用(“如果它看起来像鸭子,嘎嘎叫起来像鸭子,它一定是鸭子”),通过强调接口而不是特定的类型,设计良好的代码通过允许多态性替代。
数字类型
Python支持三种不同的数字类型:int(有符号整型)、float(浮点型)、complex(复数)。
Python 支持复数,复数由实数部分和虚数部分构成,可以用 a + bj,或者 complex(a,b)来表示,复数的实部 a 和虚部 b 都是浮点型。
\>>>
\>>> # 正整数
\>>> print (149600000000)
149600000000
\>>> # 负整数
\>>> print (-149600000000)
-149600000000
\>>> # 十六进制
\>>> print (0x22D4DAD800)
149600000000
\>>> # 浮点数
\>>> print (3.141592653589793)
3.141592653589793
\>>> # 复数
\>>> print (-1j)
-1j
字符串类型
Python 可以使用单引号( ’ )、双引号( " )、三引号( ‘’’ 或 “”" ) 来表示字符串,引号的开始与结束必须是相同类型的。
成对的三引号中所表示的字符串可以由多行组成,将会忽略换行和转义符号,一般称之为文本块。例如:
\>>>
\>>> print ("Hello World!")
Hello World!
\>>> print ('你好 世界!')
你好 世界!
\>>> print ('''
Python
Hello Python String Block!
''')
<html>
<head>
<title>Python</title>
</head>
<body>
<h1>Hello Python String Block! </h1>
</body>
</html>
文档字符串
作为类、函数或模块之内的第一个表达式出现的字符串字面值。它在代码执行时会被忽略,但会被解释器识别并放入所在类、函数或模块的 doc 属性中。由于它可用于代码内省,因此是对象存放文档的规范位置。例如:
\>>> def fun ():
"我是函数的文档字符串"
pass
\>>> print (fun.__doc__)
我是函数的文档字符串
原始字符串
在成对的单引号或者双引号表示的字符串中,\n,\t 等都被转义为了特殊符号,如果不需要转义,在字符串的第一个引号前加上字母“r”或“R”,就构成了原始字符串,它的所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。例如:
\>>>
\>>> print ('a\tb')
a b
\>>> print (r'a\tb')
a\tb
字符串格式化
Python 字符串支持使用 % 来是格式化字符串,如下所示:
\>>> "My name is %s." % "Timor"
'My name is Timor.'
\>>> "My name is %s, I`m %d years old." % ("Timor", 12)
'My name is Timor, I`m 12 years old.'
Python 字符串格式化符号列表:
| 符号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %F 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
在格式化小数的时候,如果需要保留小数位数,可以按照如下方式来使用,如下所示:
"PI is %.3f" % 3.1415926
在格式化字符串的时候,如果需要保留 %,可以使用两个 %%,如下所示:
"32 %% 3 = %d" % 2
字符串的函数 format 也可以用于格式化字符串。该语法在大多数情况下与 % 格式化类似,只是增加了 {} 和 : 来取代 % 。 例如,, ‘%03.2f’ 可以被改写为 ‘{:03.2f}’ 。
>>> '{0}, {1}, {2}'.format('a', 'b', 'c')
'a, b, c'
>>> '{}, {}, {}'.format('a', 'b', 'c') # 3.1+ only
'a, b, c'
>>> '{2}, {1}, {0}'.format('a', 'b', 'c')
'c, b, a'
>>> '{2}, {1}, {0}'.format(*'abc')
'c, b, a'
>>> '{0}{1}{0}'.format('abra', 'cad')
'abracadabra'
按名称访问参数:
>>> 'a is: {a}, b is: {b}'.format(a='37', b='-115')
'a is: 37, b is: -115'
>>> coord = {'latitude': '37.24N', 'longitude': '-115.81W'}
>>> 'Coordinates: {latitude}, {longitude}'.format(**coord)
'Coordinates: 37.24N, -115.81W'
使用逗号作为千位分隔符:
>>> '{:,}'.format(1234567890)
'1,234,567,890'
表示为百分数:
>>> 'Correct answers: {:.2%}'.format(19/22)
'Correct answers: 86.36%'
字符串常用操作
切片
Python的字符串可以通过类似数组下标的方式取得对应位置的字符,如下所示:
"hello"[1]
通过下标取值有两种取值顺序:
l 从左到右索引默认0开始的,最大范围是字符串长度少1
l 从右到左索引默认-1开始的,最大范围是字符串开头
在Python中处理列表的部分元素,称之为切片。可以使用 [头下标:尾下标] 这种格式来截取相应的字符串。其中下标是从 0 开始算起,可以是正数或负数,下标可以为空表示取到头或尾。对应结果如下所示:
x = "Hello"
x[1:3] => el
x[-4:-2] => el
x[-2:-4] =>
-------------------
x[:3] => Hel
x[:-2] => Hel
-------------------
x[1:] => ello
x[-4:] => ello
-------------------
x => Hello
x[:] => Hello
Python 字符串截取可以接收第三个参数,参数是一个正整数,作用是表示截取的步长,例如:
运算
加号(+)是字符串连接运算符,星号(*)是重复操作。示例如下
\>>> "ab" + "cd"
'abcd'
\>>> "ab" * 2
'abab'
in 和 not in 判断是否包含,示例如下:
\>>> "a" in "abcd"
True
\>>> "e" in "abcd"
False
列表类型
声明
vs = ["timor", '男', 20, 42.6]
print("vs`length is %d." % vs.__len__())
遍历
for v in vs:
print(v)
# 通过 enumerate 获取元素及其下标
for (i, v) in enumerate(vs):
print("i = %d, v = %s" % (i, v))
增加
vs.append(30)
print(vs)
vs.insert(1, "insert to 1")
print(vs)
vs.extend([55, 66])
print(vs)
# 列表连接
vs += [77, 88]
print(vs)
# 列表重复
vs *= 2
print(vs)
修改
vs[1] = "update by 1"
print(vs)
取值
print(vs[1])
删除
# 删除指定的元素,当找不到的时候会出现异常
vs.remove(3333333)
print(vs)
# 删除列表最后一个
p = vs.pop()
print(p)
print(vs)
其他操作
# 统计某个元素在列表中出现的次数
c = vs.count(66)
print(c)
# 从列表中查找到某个值的第一个匹配的索引位置
c = vs.index(66)
print(c)
# 反转列表
vs.reverse()
print(vs)
# 列表排序,默认升序,如果需要降序,可以升序后反转为降序。
vs = [43, 6, 10, 3, 20]
# 升序
vs.sort()
print(vs)
vs = [43, 6, 10, 3, 20]
# 降序
vs.sort(reverse=True)
print(vs)
元组类型
Python的元组与列表类似,不同之处在于元组的元素不能修改。
声明
vs = ("timor", '男', 20, 42.6)
print("vs`length is %d." % vs.__len__())
print("vs`length is %d." % len(vs))
遍历
for v in vs:
print(v)
# 通过 enumerate 获取元素及其下标
for (i, v) in enumerate(vs):
print("i = %d, v = %s" % (i, v))
增加
元组的元素不可修改,可以通过连接和重复的方式来改变元组
# 元组连接
vs += (77, 88)
print(vs)
# 元组重复
vs *= 2
print(vs)
修改
元组的元素不可修改的
取值
print(vs[1])
删除
元组的元素不可删除的
字典类型
字典是另一种可变容器模型,且可存储任意类型对象。字典的每个键值对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 。字典的键不可重复,且无序,字典的结构和 JSON 对象的结构一样。
声明
vs = {"name": "timor", "gender": '男', "age": 20, "weight": 42.6}
print("vs`length is %d." % vs.__len__())
print("vs`length is %d." % len(vs))
遍历
for v in vs:
print(v)
# 通过 enumerate 获取元素及其下标
for (i, v) in enumerate(vs):
print("i = %s, v = %s" % (i, v))
# 通过 values 函数遍历元素的值
for v in vs.values():
print("value = %s" % v)
# 通过 keys 函数遍历元素的键
for k in vs.keys():
print("key = %s, value = %s" % (k, str(vs[k])))
# 通过 items 函数遍历元素, 每个元素都是一个元组
for kv in vs.items():
print("key = %s, value = %s" % (kv[0], kv[1]))
增加
vs["address"] = "武汉"
print(vs)
# 把参数字典的键/值对更新当前字典中
vs.update({"position": "软件开发工程师", "name": "Mary"})
print(vs)
修改
vs["name"] = "jack"
取值
print(vs["name"])
print(vs.get("name"))
删除
# 根据键删除
p = vs.pop("position")
print(p)
print(vs)
# 删除最后一个
p = vs.popitem()
print(p)
print(vs)
# 清空整个字典
vs.clear()
print(vs)
集合类型
set对象是不同的对象的集合,无序且不可重复。常见的用途包括成员测试、从序列中删除重复项以及计算数学运算,如交集、并集、差分和对称差分。
声明
vs = {"timor", '男', 20, 42.6}
print("vs`length is %d." % vs.__len__())
print("vs`length is %d." % len(vs))
遍历
for v in vs:
print(v)
# 通过 enumerate 获取元素及其下标
for (i, v) in enumerate(vs):
print("i = %s, v = %s" % (i, v))
增加
vs.add(3.14)
vs.add(3.14)
print(vs)
vs.update({33, 44})
print(vs)
修改和取值
set 不支持通过下标修改值,也不支持通过下标取值
删除
vs.discard(33)
print(vs)
vs.remove(44)
print(vs)
p = vs.pop()
print(p)
print(vs)
vs.clear()
print(vs)
序列解包
字符串,列表,元组,字典和集合都能至少通过如下两种方式进行(解包)遍历:
for v in vs:
print(v)
for (i, v) in enumerate(vs):
print("i = %d, v = %s" % (i, v))
实例
实例:身份验证
提示用户输入用户名和密码,仅当用户名为 root,密码为 root时显示登录成功,否则提示重新输入。
# --coding:utf-8--
# 实例:身份验证
username = input("请输入账号:")
while username != "root":
username = input("无效账号,请重新输入账号:")
password = input("请输入密码:")
while password != "root":
password = input("账号和密码不匹配,请重新输入密码:")
print("账号%s成功登录" % username)
实例:温度转换
摄氏温标:单位是°C
以1标准大气压下,水作为测温物质,定熔点为0 度,沸点为 100度,将温度进行等分刻画。
华氏温标:单位是°F
以1标准大气压下,水银作为测温物质,定熔点为 32度,沸点为212度,将温度进行等分刻画。
根据华氏和摄氏的定义,有如下转换公式:
C = (F - 32) ÷ 1.8
F = C × 1.8 + 32
脚本程序示例:
# coding=utf-8
# 华氏温度转换公式
f = input("请输入华氏度:")
f = float(f)
c = (f - 32) / 1.8
print(f, "°F = ", c, "°C")
# 摄氏温度转换公式
c = input("请输入摄氏度:")
c = float(c)
f = c * 1.8 + 32
print(c, "°C = ", f, "°F")
实例:计算器
通过控制台输入两个数和操作符后,计算并输出结果,执行过程如下所示:
python Calculator.py
请输入第一个整数:4
请输入第二个整数:a
输入无效,请重新输入第二个整数:6
请输入操作符(+, -, *, /, //):plus
输入无效,请重新请输入操作符(+, -, *, /, //):+
4 + 6 = 10
脚本程序示例:
# --coding:utf-8--
# 实例:计算器
a = input("请输入第一个整数:")
while not isinstance(a, int):
try:
a = int(a)
except ValueError as e:
a = input("输入无效,请重新输入第一个整数:")
b = input("请输入第二个整数:")
while not isinstance(b, int):
try:
b = int(b)
except ValueError as e:
b = input("输入无效,请重新输入第二个整数:")
c = input("请输入操作符(+, -, *, /, //):")
while c not in ['+', '-', '*', '/', '//']:
c = input("输入无效,请重新请输入操作符(+, -, *, /, //):")
if '+' == c:
d = a + b
elif '-' == c:
d = a - b
elif '*' == c:
d = a * b
elif '/' == c:
d = a / b
else:
d = a // b
print("%d %s %d = %d" % (a, c, b, d))
实例:名片输出
通过控制台输入姓名、电话和地址后,打印约十秒的文本进度条,最后格式化输出输入的信息,执行过程如下所示:
python Card.py
请输入您的姓名:奇妙的代码
请输入您的手机号:182****9070
请输入您的地址:湖北武汉
名片生成中............
〓〓〓〓〓〓〓〓〓〓〓
姓名: 奇妙的代码
电话: 182****9070
地址: 湖北武汉
〓〓〓〓〓〓〓〓〓〓〓
脚本程序示例:
# --coding:utf-8--
import time
name = input("请输入您的姓名:")
phone = input("请输入您的手机号:")
address = input("请输入您的地址:")
print("\n名片生成中..", end="")
for x in range(0, 10):
print(".", end="",flush=True)
time.sleep(1)
print("""
〓〓〓〓〓〓〓〓〓〓〓
姓名: %s
电话: %s
地址: %s
〓〓〓〓〓〓〓〓〓〓〓
""" % (name, phone, address))
实例:石头剪刀布
通过控制台输入 r, s, p 分别代表石头剪刀布。然后电脑(NPC)会随机出石头剪刀布,通过逻辑比较之后,输出玩家(Player)是否胜出。过程如下所示:
python Rock-Paper-Scissors.py
请输入(r:石头,s:剪刀,p:布)p
布(player) VS 石头(npc)
您胜了
脚本程序示例如下:
# --coding:utf-8--
# 实例:石头剪刀布
import random
KEYS = ['r', 's', 'p']
ROLES = ['石头', '剪刀', '布']
MAX = len(ROLES) - 1
player = input("请输入(r:石头,s:剪刀,p:布)")
while player not in KEYS:
player = input("输入错误,请输入(r:石头,s:剪刀,p:布)")
iPlayer = KEYS.index(player)
player = ROLES[iPlayer]
iNpc = random.randint(0, 2)
npc = ROLES[iNpc]
print("%s(player) VS %s(npc)" % (player, npc))
if iNpc == iPlayer:
print("平局")
elif min(iPlayer, iNpc) == 0 and max(iPlayer, iNpc) == MAX:
print("您%s了" % ("胜" if iPlayer > iNpc else "败"))
elif iPlayer < iNpc:
# 默认情况下,下标越小,就越大
print("您胜了")
else:
print("您败了")