机器学习 (四) 贝叶斯分类器原理及实战系统
前言
前面介绍的k-近邻分类器有其自身优点也有不足,今天我们介绍下从另一个角度进行分类的算法,它是基于概率论为基础的分类,接触的机器学习算法多了之后也会体会到机器学习是集数学、概率论、统计学、数据挖掘、数据结构与算法等于一身的综合学科,重在根据理论基础来设计不同的算法解决现实生活中的问题,本人在实现每个算法之前会把相关概念也介绍一下,有助于大家理解后面的实现过程,也作为自己的一个随笔。
人物
贝叶斯是一个英国数学家( Thomas Bayes 1702-1761 ) ,生于伦敦,距今有300多年历史,三代人周期可见时间还不太长,假设如果你能时间穿越到300年前你是否能发明概率统计学呢?贝叶斯发明的缘由是为了证明上帝的存在,它发明了概率统计学原理,由此可见他可能是基于逻辑推理悖论来死磕结果才发明了概率论,假设根据已有经验和生活谁又会去思考上帝为什么存在呢?
概率基础
我们先来看一下概率基础知识,以及条件概率的理解,在概率表示方法中,有一种叫做维恩图表示法,如下图:
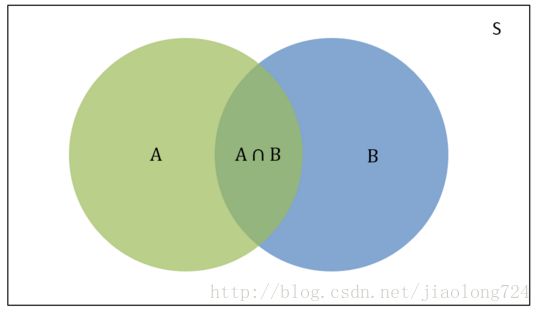
在上图中:
S:S是样本空间,是所有可能事件的总和。
P(A):是样本空间S中A事件发生的概率,维恩图中绿色的部分。
P(B):是样本空间S中B事件发生的概率,维恩图中蓝色的部分。
P(A∩B):是样本空间S中A事件和B事件同时发生的概率,也就是A和B相交的区域。
P(A|B):是条件概率,是B事件已经发生时A事件发生的概率。
对于条件概率,还有一种更清晰的表示方式叫概率树。下面的概率树表示了条件概率P(A|B)。与维恩图中的P(A∩B)相比,可以发现两者明显的区别。P(A∩B)是事件A和事件B同时发现的情况,因此是两者相交区域的概率。而事件概率P(A|B)是事件B发生时事件A发生的概率。这里有一个先决条件就是P(B)要首先发生。
另一种表示方法叫做数概率,如下:
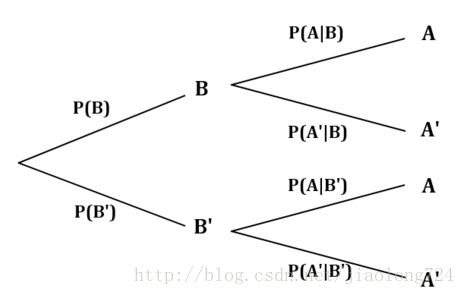
因为条件概率P(A|B)是在事件B已经发生的情况下,事件A发生的概率,因此P(A|B)可以表示为事件A与B的交集与事件B的比率。

原理
让我们结合一个垃圾文档的分类实例来理解贝叶斯概率分类器是如何工作的,思路是计算给定样本属于各个分类的概率,概率大即样本所属的分类,在求解这一过程中利用到了贝叶斯定理,贝叶斯公式如下:
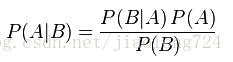
该公式的含义是在事件B发生的时候事件A发生的概率,在这里事件B即某个样本(向量w表示),A是该样本所属的分类(Ci表示),我们的目的是求样本所属某个分类的概率,我们只要逐一把公式右边的概率求出来即可知道结果,该公式变形为下面形式:
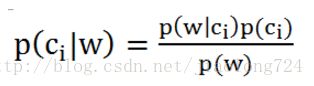
在这里i只有两类 垃圾和非垃圾,i取值为0或1,假设当i=1时
p(c1)表示该文档属于垃圾分类的概率,p(w)表示该待测文档为w向量的概率,根据已经样本可以求出来,p(w|c1)表示分类位垃圾文档时样本为向量w的概率,这里我们要清楚w是由很多单词组成的,这些单词可以表示为w0、w1、w2、w3………………等,到这里就涉及到了“朴素”一词的含义,朴素代表各个事件之间相互独立、互不影响,相当于做成一件事情需要n个小事件一起来完成,根据概率知识独立小事件概率相乘等于一件事件发生的概率,因此 p(w|ci) = p(w0|ci) * p(w1|ci) * p(w2|ci) * …. * p(wn|ci) ,我们的公式就可以继续往下面求解了。
在理解原理的时候要理解几个概率的含义,如文档类别概率即该类别文档数占总类文档数百分比,其次是某个单词占该分类的百分比。
涉及概念
- 样本空间:样本空间即随机事件E的所有基本结果组成的集合为E的样本空间。样本空间的元素称为样本点或基本事件。
- 贝叶斯准则:又叫做贝叶斯定理、贝叶斯规则都是一回事,它是描述两个事件的关系,比如A发生时B也发生的概率和B发生时A也发生的概率是不一样的,贝叶斯准则描述的就是这两种之间的关系问题,然它只是统计学模型中一个方法。
- 先验概率:在贝叶斯公式中右边的P(A)、P(B)都表示先验概率,即主观已知的概率。
- 后验概率:P(A|B)或P(B|A )叫后验概率,即我们要求的值,公式右边另一个比值叫调节因子。
- 词向量:一般是一个01或布尔类型的值得集合,表示一个单词在文档或者邮件中是否存在。
- 词集模型(set-of-words model):我们将每个词出现与否作为一个特征,如当词向量表示0或1存不存在时,这种方式叫词集模型,寓意只是词的集合不包括重复词。
- 词袋模型(bag-of-words model):当词向量中类型为整型,表示某个单词出现的次数时,这种方式取名叫词袋模型,寓意词的全量包括重复出现的。
代码
下面让我们看一个贝叶斯分类文档的完整实例代码,代码如下:
def loadDataSet():
'''
获取文档集合列表,也可以是邮件列表
:return:文档集合列表
'''
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
# 已经分类的标签
classVec = [0,1,0,1,0,1] # 1 代表侮辱性文字 0 代表正常言论
return postingList,classVec
def createVocabList(dataSet):
'''
创建词汇表
:param dataSet:文档集合列表
:return: 词汇表
'''
# 创建空集
vocabSet = set([])
# 遍历文档集合
for document in dataSet:
# 将每个文档单词去重,取每个文档的并集
vocabSet = vocabSet | set(document)
# 返回词汇表
return list(vocabSet)
def setOfWords2Vec(vocabList,inputSet):
'''
将待测文档转为词向量
:param vocabList: 词汇表
:param inputSet: 单一文档
:return:文档词向量
'''
# 创建一个长度等于词汇表,值都为0的向量
returnVec = [0]*len(vocabList)
# 循环待测文档中每个单词
for word in inputSet:
# 如果单词在词汇表中
if word in vocabList:
# 把对应单词的位置标记为1 表示存在 词集模型
returnVec[vocabList.index(word)] = 1
else:print "the word:%s is not in my Vocabulary!" % word
# 返回词向量
return returnVec
def trainNB0(trainMatrix, trainCategory):
'''
:param trainMatrix:训练数据
:param trainCategory: 已经分类类别标签
:return:
'''
# 参与训练总文档的数目
numTrainDocs = len(trainMatrix)
# 词向量的长度(单词个数最大值)
numWords = len(trainMatrix[0])
# 侮辱性文档个数占总文档个数的概率(比值)
pAbusive = sum(trainCategory)/float(numTrainDocs)
# 初始化每个单词所占百分比
p0Num = np.zeros(numWords);p1Num = np.zeros(numWords)
p0Denom = 0.0 ; p1Denom = 0.0
# 对于每个文档
for i in range(numTrainDocs):
# 垃圾文档
if trainCategory[i] == 1:
# 计算该分类下每个单词个数
p1Num += trainMatrix[i]
# 该分类下单词出现总个数
p1Denom += sum(trainMatrix[i])
# 非垃圾文档
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
# 计算每个元素出现的概率
p1Vect = p1Num/p1Denom # change to log()
p0Vect = p0Num/p0Denom # change to log()
return p0Vect,p1Vect,pAbusive
# 上面的代码存在两个问题
# 一是p(wn|ci)只要有一个为0那么累乘结果将为0,因为某个文档必将有不存在的元素,0必然会出现,所以,我们在初始化该值时p1Num p0Num初始化为1
# 二是p(wn|ci)可能是很小的值,导致累乘时超出浮点数的下限,产生下溢,解决该问题我们采用取对数,转为累加来解决
# 其实这两种问题在其它算法中也可能出现,需要灵活应对
def trainForceNB0(trainMatrix, trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
# 初始化概率
p0Num = np.ones(numWords);p1Num = np.ones(numWords)
p0Denom = 2.0 ; p1Denom = 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
# 向量相加
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
# 取对数的结构
p1Vect = np.log(p1Num/p1Denom) # change to log()
p0Vect = np.log(p0Num/p0Denom) # change to log()
return p0Vect,p1Vect,pAbusive
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
p1 = sum(vec2Classify * p1Vec) + np.log(pClass1)
p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
def testingNB():
'''
朴素贝叶斯分类函数
:return:
'''
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat = []
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList,postinDoc))
p0V,p1V,pAb = trainNB0(np.array(trainMat),np.array(listClasses))
testEntry = ['love','my','dalmation']
thisDoc = np.array(setOfWords2Vec(myVocabList,testEntry))
print testEntry,'classified as :',classifyNB(thisDoc,p0V,p1V,pAb)
代价解析与说明,函数trainForceNB0()方法是加强之后的方法主要解决了被除数可能0以及多个数累成值太小造成出现异常,给了默认值以及取对数进行解决。另外代码中并没有对p(w)求值因为只是比较结果,这一个值求不求出来都无所谓,只是从贝叶斯公式看是有这个值的;除此之外还有一处向量相乘运算,这个是ndarray具有的性质,两个一样大小的向量可以对相应位置的元素相乘,意思是向量的分量相乘,之所以这么用本人觉得矩阵或向量方便运算。
题外思考
计算机思维重要性
雅虎 或者很多银行业务很难发展起来,根本原因是他们没有一个计算机思维或者是大数据思维,面对的客户是全国或者是全世界,而不仅仅是周围地区的一些人,思维不同实际行动起来,定制的实现方案就会受思维的局限不能发展起来,在现代社会我们要以大数据、以结果为终的目前去做事去行动,过程不再显得那么重要,人工智能发展以后任何行业只要存储了非常大的资料库,利用这些知识来处理问题将是很简单的事情,比人们用大脑去记忆不知要好上多少倍,学会计算机维斯站在更高的维护去处理事情,不要局限于当前。
参考文章:
https://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html
https://www.baidu.com/link?url=6aWHK-
kdQZbHYxEvoj76JJhMG4bLP53fIi5o9pfAWL7uopHCjKVRHRhWZJCQ_oC-p7MUiB7HylpPhBN9VisADq&wd=&eqid=e595bacf0001fc35000000035a57ed7f
https://baike.baidu.com/item/%E8%B4%9D%E5%8F%B6%E6%96%AF%E5%88%86%E7%B1%BB%E5%99%A8/1739590?fr=aladdin
http://blog.csdn.net/li8zi8fa/article/details/76176597