【源码学习-spark2.1.1和yarn2.11】SparkOnYarn部署流程(一)从sparksubmit提交到yarn启动进程ApplicationMaster
001-源码spark-2.1.1版
- SparkOnYarn部署流程-SparkSubmit
源码三步
1.整体框架
2.框架组件、通信
3.任务的划分、调度、执行
这里基于spark-2.1.1版本的源码,官网现在是spark-3.0.0和spark-2.1.1的源码还是有很多区别的。
官网下载:https://www.apache.org/dyn/closer.lua/spark/spark-2.1.1/spark-2.1.1.tgz
SparkOnYarn部署流程-SparkSubmit
bin/spark-submit \
-class org.apache.spark.examaple.SparkPi \
-master yarn \
-deploymode client \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
执行该命令源码底层:
1.0
spark submit操作是脚本文件,后面跟参数,最终会形成java命令执行,所有的环境,参数配置好了,最后会走java类文件。
2.0
最终会走到SparkSubmit.scala
当执行java SparkSubmit -xxx -xxxx -xxx的时候,会启动一个进行,JVM - Process,进程的名字就叫SparkSubmit(在Linux中执行jps会又该名称的进程,前面会有进行id号),即JVM - Process(SparkSubmit);
SparkSubmit.scala源码文件66行伴生对象SparkSubmit,通过静态的方式访问方法,
object SparkSubmit {
3.0 启动进程
启动一个进程之后,去找main方法(源码中的main方法,就是SparkSubmit.scala这个类里的main方法,不是我们自己写的代码中的main方法),即JVM - Process(SparkSubmit) - main;
在SparkSubmit.scala源码文件118行有个main方法(上面所说的就是这里),
def main(args: Array[String]): Unit = {
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
// scalastyle:off println
printStream.println(appArgs)
// scalastyle:on println
}
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
4.0
通过SparkShell进入spark环境,会出现一个spark的logo,java SparkSubmit进程启动,接下来调用的肯定是main方法。
在SparkSubmit.scala源码文件99行有个printVersionAndExit()方法,是用来打印在命令行启动spark环境开头的logo的,以及版本,类型信息等。
private[spark] def printVersionAndExit(): Unit = {
printStream.println("""Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version %s
/_/
""".format(SPARK_VERSION))
printStream.println("Using Scala %s, %s, %s".format(
Properties.versionString, Properties.javaVmName, Properties.javaVersion))
printStream.println("Branch %s".format(SPARK_BRANCH))
printStream.println("Compiled by user %s on %s".format(SPARK_BUILD_USER, SPARK_BUILD_DATE))
printStream.println("Revision %s".format(SPARK_REVISION))
printStream.println("Url %s".format(SPARK_REPO_URL))
printStream.println("Type --help for more information.")
exitFn(0)
}
// scalastyle:on println
5.0 封装参数
在main方法里,通过new SparkSubmitArguments(args)封装参数,此处的args参数来自于main方法的参数args,main方法的参数args来自于spark submit后面提交的参数。
5.1
那SparkSubmitArguments方法封装了什么?crtl+鼠标左键 进入SparkSubmitArguments.scala方法,SparkSubmitArgurments类体内的方法、构造器都会执行。
SparkSubmitArguments.scala源码文件41行到79行为参数变量:
/**
* Parses and encapsulates arguments from the spark-submit script.
* The env argument is used for testing.
*/
private[deploy] class SparkSubmitArguments(args: Seq[String], env: Map[String, String] = sys.env)
extends SparkSubmitArgumentsParser {
var master: String = null
var deployMode: String = null
var executorMemory: String = null
var executorCores: String = null
var totalExecutorCores: String = null
var propertiesFile: String = null
var driverMemory: String = null
var driverExtraClassPath: String = null
var driverExtraLibraryPath: String = null
var driverExtraJavaOptions: String = null
var queue: String = null
var numExecutors: String = null
var files: String = null
var archives: String = null
var mainClass: String = null
var primaryResource: String = null
var name: String = null
var childArgs: ArrayBuffer[String] = new ArrayBuffer[String]()
var jars: String = null
var packages: String = null
var repositories: String = null
var ivyRepoPath: String = null
var packagesExclusions: String = null
var verbose: Boolean = false
var isPython: Boolean = false
var pyFiles: String = null
var isR: Boolean = false
var action: SparkSubmitAction = null
val sparkProperties: HashMap[String, String] = new HashMap[String, String]()
var proxyUser: String = null
var principal: String = null
var keytab: String = null
// Standalone cluster mode only
var supervise: Boolean = false
var driverCores: String = null
var submissionToKill: String = null
var submissionToRequestStatusFor: String = null
var useRest: Boolean = true // used internally
5.2
通过parse(args.asJava)将scala转换为java往下传递
SparkSubmitArguments.scala源码文件96行到102行:
// Set parameters from command line arguments
try {
parse(args.asJava)
} catch {
case e: IllegalArgumentException =>
SparkSubmit.printErrorAndExit(e.getMessage())
}
5.2.1
ctrl+鼠标左键 进入SparkSubmitOptionParser.java文件
5.3
在SparkSubmitArguments.scala源码文件326行有个handle方法,在做模式匹配,进行处理参数,解析参数。
此处的case参数,可crtl+鼠标左键 匹配到SparkSubmitOptionParser.java源码文件的39行到77行。
6.0
在SparkSubmit.scala源码文件120到124行,是否打印详细信息,不是很重要
7.0
在SparkSubmit.scala源码文件125到129行是模式匹配(scala中模式匹配比较多),匹配不同的操作环境SUBMIT、KILL、REQUEST_STATUS,
然后对action进行ctrl+鼠标左键 进入SparkSubmitArguments.scala源码文件68行,默认为null,但是一定有地方对它进行赋值,否则无法匹配SUBMIT、KILL、REQUEST_STATUS(这里SparkSubmit.scala源码文件125行的action在SparkSubmit.scala源码文件119行的val appArgs = new SparkSubmitArguments(args)已经赋值)
7.1
在SparkSubmitArguments.scala源码文件中进行搜索action,找到227行:
// Action should be SUBMIT unless otherwise specified
action = Option(action).getOrElse(SUBMIT)
142行的loadEnvironmentArguments()方法,就是对action进行赋值的。
刚才action是默认值null,因此现在给action赋值为SUBMIT。
8.0 提交
那么此时,SparkSubmit.scala源码文件中125行的action值为SUBMIT,然后模式匹配走126行,执行submit(appArgs)方法,调用159行的submit(args: SparkSubmitArguments)方法,
在submit方法中有一个prepareSubmitEnvironment(args)方法,准备提交环境,
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)
它的返回值是个元组,不是单个变量xxx,也就是个模式匹配,可以直接使用对应的返回值了,不用xxx._1,xxx._2等的去操作了。
接下来在162行声明了一个方法doRunMain(),声明的方法,不去调用不会执行,暂时不用看,哪里调用了,再返回来看。
走到SparkSubmit.scala源码文件196行,判断是否独立的standalone的集群:
// In standalone cluster mode, there are two submission gateways:
// (1) The traditional RPC gateway using o.a.s.deploy.Client as a wrapper
// (2) The new REST-based gateway introduced in Spark 1.3
// The latter is the default behavior as of Spark 1.3, but Spark submit will fail over
// to use the legacy gateway if the master endpoint turns out to be not a REST server.
if (args.isStandaloneCluster && args.useRest) {
try {
// scalastyle:off println
printStream.println("Running Spark using the REST application submission protocol.")
// scalastyle:on println
doRunMain()
} catch {
// Fail over to use the legacy submission gateway
case e: SubmitRestConnectionException =>
printWarning(s"Master endpoint ${args.master} was not a REST server. " +
"Falling back to legacy submission gateway instead.")
args.useRest = false
submit(args)
}
// In all other modes, just run the main class as prepared
} else {
doRunMain()
}
因为我们提交的client方式,所以不是standalone模式,然后走else的doRunMain()方法,就是调用刚才说的162行(可以看到无论是if还是else都会调用doRunMain()方法)。
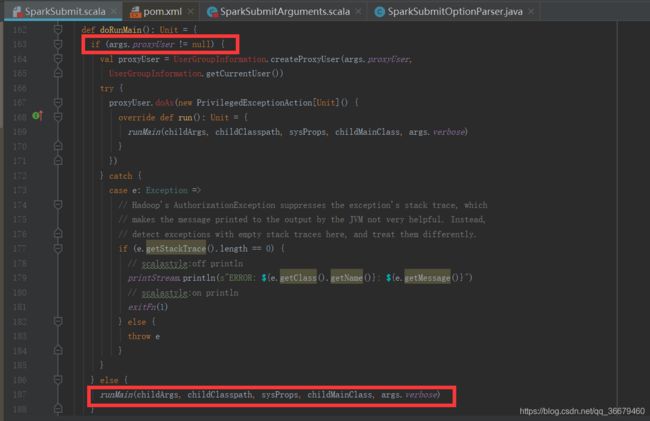
调用doRunMain(),首先判断args.proxyuser代理用户(服务器用户)是否为空,这里没有提交过一定为空,然后走else的runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)。(这里无论if还是else都会走runMain,这四个参数是刚才准备环境的返回值)
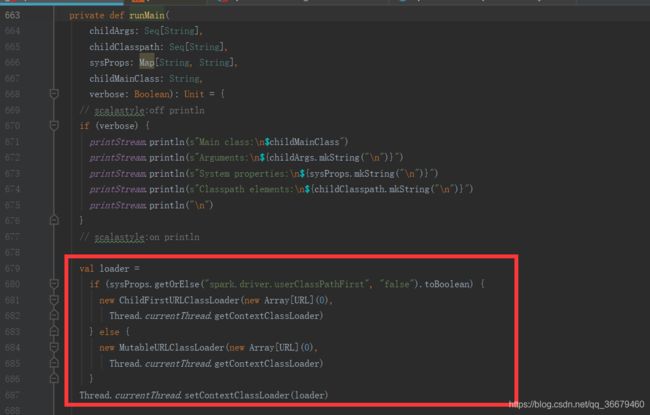
runMain方法是采用当前线程的类加载器,
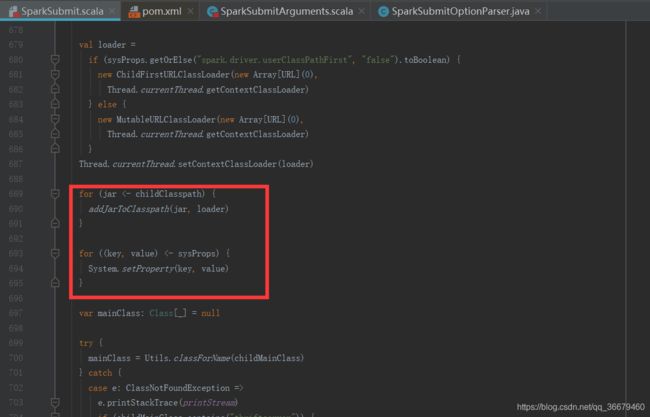
从类加载读取jar,设定参数。
接下来比较重要的是,反射加载类,700行的mainClass = Utils.classForName(childMainClass),ctrl+鼠标左键classForName进入Utils.scala类,
8.1
在Utils.scala源码文件229行,反射加载类
// scalastyle:off classforname
/** Preferred alternative to Class.forName(className) */
def classForName(className: String): Class[_] = {
Class.forName(className, true, getContextOrSparkClassLoader)
// scalastyle:on classforname
}
8.2 查找main方法
在SparkSubmit.scala源码文件727行,看看mainClass类信息里面有没有main方法,
val mainMethod = mainClass.getMethod("main", new Array[String](0).getClass)
if (!Modifier.isStatic(mainMethod.getModifiers)) {
throw new IllegalStateException("The main method in the given main class must be static")
}
第二步判断是不是静态方法,不是静态方法就报错,那么传的必须是静态方法,而且是数组Array[String]。
8.3 调用mian方法
在SparkSubmit.scala源码文件743行:
mainMethod.invoke(null, childArgs.toArray)
8.4
虽然知道要调用main方法,但不知道是哪个类的main方法,要知道mainClass = Utils.classForName(childMainClass)中的childMainClass是从哪里来的,可以追溯到准备环境prepareSubmitEnvironment(args)的四个返回值中的一个,
走到225行prepareSubmitEnvironment(args: SparkSubmitArguments)方法,最后一行654行是它的返回值。
在575行cluster模式
childMainClass = "org.apache.spark.deploy.yarn.Client"
在490行client模式
childMainClass = args.mainClass
这里的args.mainClass即spark submit传进的参数–class org.apache.spark.examaple.SparkPi
工作中,肯定是要走yarn集群的,client是我们平常自己操作用的。
如果走yarn会启动一个进程吗?不会的,因为只有执行java SparkSubmit --xxx这样的才会启动进程。现在是反射调用方法,普通调用;只是没法直接调用,用到了反射。在sparksubmit进程中,生成一个yarn集群的client对象
9.0
通过org.apache.spark.deploy.yarn.Client找到该源码文件中的main方法(ctrl+shift+alt+n进行搜索,如果没有该类,需要在pom.xml文件下添加:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_2.11</artifactId>
<version>2.1.1</version>
</dependency>
这里2.1.1版本和2.3.3版本差别还是很大的,在2.3.3就没有main方法了。
),然后就从spark submit过渡到了Client。
在Client.scala源文件1211行main方法中:
val args = new ClientArguments(argStrings)
new ClientArguments(argStrings)也是用来封装参数用的,ctrl+鼠标左键ClientArguments进入ClientArguments.scala源码文件23行,后面也有一些配置参数(如–class、–jar等)。
然后在Client.scala源文件1226行,创建对象,运行客户端:
new Client(args, sparkConf).run()
ctrl+鼠标左键Client走68行到Client构造方法处传参:
def this(clientArgs: ClientArguments, spConf: SparkConf) =
this(clientArgs, SparkHadoopUtil.get.newConfiguration(spConf), spConf)
最终调59行主构造方法:
private[spark] class Client(
val args: ClientArguments,
val hadoopConf: Configuration,
val sparkConf: SparkConf)
extends Logging {
接着会从Client类里面代码开始依次往下执行的,
走到71行,创建yarn客户端,
private val yarnClient = YarnClient.createYarnClient
ctrl+鼠标左键createYarnClient进入YarnClient.java源文件54行,构建一个yarn客户端的实现:
/**
* Create a new instance of YarnClient.
*/
@Public
public static YarnClient createYarnClient() {
YarnClient client = new YarnClientImpl();
return client;
}
ctrl+鼠标左键YarnClientImpl进入YarnClientImpl.java源文件86行,上面有属性rmClient(ResourceManagerClient)和rmAddress(ResouceManager服务端):
@Private
@Unstable
public class YarnClientImpl extends YarnClient {
private static final Log LOG = LogFactory.getLog(YarnClientImpl.class);
protected ApplicationClientProtocol rmClient;
protected InetSocketAddress rmAddress;
protected long statePollIntervalMillis;
private static final String ROOT = "root";
public YarnClientImpl() {
super(YarnClientImpl.class.getName());
}
回到Client.scala源文件,继续往下执行,都是在构建属性,对象等。
10.0
对于Client.scala源文件1226行,创建对象,运行客户端:
new Client(args, sparkConf).run()
ctrl+鼠标左键run走到1166行run()方法处,往下执行:
this.appId = submitApplication()
submitApplication()会返回一个appId,全局唯一性id,webUI通过该id进行关联。
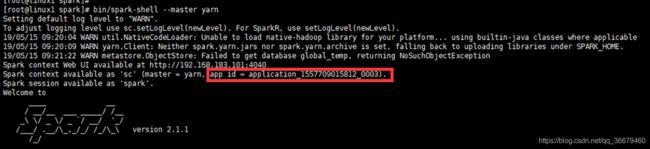
ctrl+鼠标左键submitApplication走到145行submitApplication()方法,中有个比较特殊的类launcherBackend,在148行有个后台连接launcherBackend.connect(),后面有yarnClient的初始化和启动(用来启动和服务器的连接),yarn的Client来创建应用,得到一个响应,取出唯一性id,以后用该id做关联。
/**
* Submit an application running our ApplicationMaster to the ResourceManager.
*
* The stable Yarn API provides a convenience method (YarnClient#createApplication) for
* creating applications and setting up the application submission context. This was not
* available in the alpha API.
*/
def submitApplication(): ApplicationId = {
var appId: ApplicationId = null
try {
launcherBackend.connect()
// Setup the credentials before doing anything else,
// so we have don't have issues at any point.
setupCredentials()
yarnClient.init(yarnConf)
yarnClient.start()
logInfo("Requesting a new application from cluster with %d NodeManagers"
.format(yarnClient.getYarnClusterMetrics.getNumNodeManagers))
// Get a new application from our RM
val newApp = yarnClient.createApplication()
val newAppResponse = newApp.getNewApplicationResponse()
appId = newAppResponse.getApplicationId()
reportLauncherState(SparkAppHandle.State.SUBMITTED)
launcherBackend.setAppId(appId.toString)
new CallerContext("CLIENT", Option(appId.toString)).setCurrentContext()
// Verify whether the cluster has enough resources for our AM
verifyClusterResources(newAppResponse)
// Set up the appropriate contexts to launch our AM
val containerContext = createContainerLaunchContext(newAppResponse)
val appContext = createApplicationSubmissionContext(newApp, containerContext)
// Finally, submit and monitor the application
logInfo(s"Submitting application $appId to ResourceManager")
yarnClient.submitApplication(appContext)
appId
} catch {
case e: Throwable =>
if (appId != null) {
cleanupStagingDir(appId)
}
throw e
}
}
最后yarn的Client向yarn提交应用yarnClient.submitApplication(appContext),也就是向ResourceManager提交(其实这里提交的是command指令,操作等,不是应用),其中参数appContext来自于(newApp, containerContext),容器containerContext来自于createContainerLaunchContext(newAppResponse)。
crtl+鼠标左键createContainerLaunchContext走到870行,方法中有很多关于JVM参数的配置,命令行参数等,这里是封装指令command
通过984行到989行判断是集群模式,还是客户端来进行赋值,
command=bin/java org.apache.spark.deploy.yarn.ApplicationMaster (cluster)
command=bin/java org.apache.spark.deploy.yarn.ExecutorLauncher (client)
当指令被提交后,ResourceManager会通知NodeManager启动一个ApplicationMaster进程(这里使用java命令了,所以是进程),但是通过SparkShell下jps没有该名称的进程,只有ExecutorLauncher的进程,所以SparkShell默认启动是的client模式,并且没有办法在SparkShell中启动cluster模式。