Python笔记
pyqt5中使用GraphicsView显示图片
def show_selected_image(self, image):
height = image.shape[0]
width = image.shape[1]
ratio = float(height / width)
new_height = 300
new_width = int(300 / ratio)
img = cv2.resize(image, (new_width, new_height))
frame = QImage(img, new_width, new_height, QImage.Format_RGB888)
pix = QPixmap.fromImage(frame)
self.item = QGraphicsPixmapItem(pix)
self.scene = QGraphicsScene() # 创建场景
self.scene.addItem(self.item)
self.graphicsView.setScene(self.scene)
Python 图片转数组,二进制互转操作
https://www.jb51.net/article/207138.htm
import matplotlib.pyplot as plt
import cv2
from PIL import Image
from io import BytesIO
import numpy as np
# 图片转numpy数组
img_path = "images/1.jpg"
img_data = cv2.imread(img_path)
#numpy数组转图片
img_data = np.linspace(0,255,100*100*3).reshape(100,100,-1).astype(np.uint8)
cv2.imwrite("img.jpg",img_data) # 在当前目录下会生成一张img.jpg的图片
# 以 二进制方式 进行图片读取
with open("img.jpg","rb") as f:
img_bin = f.read() # 内容读取
# 将 图片的二进制内容 转成 真实图片
with open("img.jpg","wb") as f:
f.write(img_bin) # img_bin里面保存着 以二进制方式读取的图片内容,当前目录会生成一张img.jpg的图片
"""
以上两种方式"合作"也可以实现,但是中间会有对外存的读写
一般这些到磁盘的IO操作还是很耗时间的
所以在内存直接处理会较好
"""
#将数组转成 图片的二进制数据
img_data = np.linspace(0,255,100*100*3).reshape(100,100,-1).astype(np.uint8)
ret,buf = cv2.imencode(".jpg",img_data)
img_bin = Image.fromarray(np.uint8(buf)).tobytes()
#将图片二进制数据 转为数组
img_data = plt.imread(BytesIO(img_bin),"jpg")
print(type(img_data))
print(img_data.shape)
"""
out:
(100, 100, 3)
"""
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import rcParams
matplotlib.use('pgf')
pgf_config={
"font.family":"serief",
"font.size":20,
"pgf.rcfonts":False,
"text.usetex":True,
"pgf.preamble":'\n'.join([
r"\usepackage{unicode-math}",
r"\setmainfont{times new roman}",
r"\usepackage{xeCJK}",
r"\xeCJKsetup{CJKmath=true}",
r"\setCJKmainfont{SimSun}",
]),
}
rcParams.update(pgf_config)
2,梯度下降法求极值
求下列函数的极小值
f ( x ) = x 4 − 3 ∗ x 3 + 2 ⇒ f ′ ( x ) = 4 x 3 − 9 x 2 f(x) = x^4 - 3 * x^3 + 2 \; \Rightarrow \; f'(x) = 4x^3 - 9x^2 f(x)=x4−3∗x3+2⇒f′(x)=4x3−9x2
#From calculation, it is expected that the local minimum occurs at x=9/4
cur_x = 6 # The algorithm starts at x=6
gamma = 0.01 # step size multiplier
precision = 0.00001
previous_step_size = cur_x
def df(x):
return 4 * x**3 - 9 * x**2
while previous_step_size > precision:
prev_x = cur_x
cur_x += -gamma * df(prev_x)
previous_step_size = abs(cur_x - prev_x)
print("The local minimum occurs at %f" % cur_x)
pandas#创建无数据Dataframe
import pandas as pd
cc=pd.DataFrame(columns=['x','y','z'])
cc
安装本地python库文件
-
tar.gz格式的文件
解压文件,在文件目录打开终端,执行
python setup.py install -
whl格式文件
达到文件目录,执行
pip install a.whl
pip更新软件包
直接运行-cmd 控制台操作
查看包 pip list
安装a.whl包 pip install a.whl
升级包 pip install --upgrade a.whl
卸载包 pip uninstall a.whl
查看待更新包 pip list --outdate
升级pip自己 pip install --upgrade pip
升级python库:
pip install --upgrade matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
升级某个版本的包
pip install SomePackage # latest version
pip install SomePackage==1.0.4 # specific version
Python 里面直接运行,更新多个包
import pip
from subprocess import call
for dist in pip.get_installed_distributions():
call("pip install --upgrade " + dist.project_name, shell=True)
表示解包
[*range(10)]
将多个数据写入sheet
import pandas as pd
df1 = pd.DataFrame({'a':[3,1],'b':[4,3]})
df2 = df1.copy()
with pd.ExcelWriter(r'C:\Users\mengx\Desktop\output.xlsx') as writer:
str1 = ['a','b','c','d','e','f','g','h','i',\
'j','k','l','m','n','o','p','q']
for i in str1:
name = str(i)
df1.to_excel(writer, sheet_name= name)
writer.save()
writer.close()
#拆分报表
import pandas as pd
df=pd.read_excel(r'C:\Users\zen\Desktop\数据.xlsx')
df
for x,y in df.loc[(df.数量>3),:].groupby('月份',sort=0):
h=x[0]+x[1]
pd.DataFrame(y.values,columns=df.columns).to_excel(r'C:\Users\zen\Desktop\拆\/'+h+'.xlsx',index=False)
| 月份 | 数量 | |
|---|---|---|
| 0 | 五月 | 7 |
| 1 | 六月 | 8 |
#总表拆分多个工作簿
import pandas as pd
df=pd.read_excel(r'C:\Users\zen\Desktop\数据.xlsx',header=[0,1])
df
for x,y in df.groupby(['月份'],sort=0):
with pd.ExcelWriter(r'C:\Users\zen\Desktop\拆\数据.xlsx',mode='a',engine='openpyxl') as writer:
pd.DataFrame(y.values,columns=df.columns).to_excel(writer,sheet_name='h')
| Unnamed: 0_level_0 | 总 | ||
|---|---|---|---|
| 类 | 月份 | 数量 | |
| 0 | a | 一月 | 3 |
| 1 | b | 二月 | 4 |
| 2 | c | 三月 | 5 |
| 3 | d | 四月 | 6 |
| 4 | b | 五月 | 7 |
#拆分多个工作簿,变成单个表格
import pandas as pd
df=pd.read_excel(r'C:\Users\zen\Desktop\拆\数据.xlsx',sheet_name=None)
df
for key in df:
df[key].to_excel(r'C:\Users\zen\Desktop\拆\/'+key+'.xlsx',index=False)
{'b': 类 月份 数量
0 a 一月 3
1 b 二月 4
2 c 三月 5
3 d 四月 6
4 b 五月 7,
'b二月': 类 月份 数量
0 b 二月 4,
'c三月': 类 月份 数量
0 c 三月 5,
'd四月': 类 月份 数量
0 d 四月 6,
'b五月': 类 月份 数量
0 b 五月 7}
#多个表格写到一个表格多个工作簿
import pandas as pd
import glob as glob
ce=glob.glob(r'C:\Users\zen\Desktop\拆\*.xlsx')
ce
import os
for i in ce:
df=pd.read_excel(i)
with pd.ExcelWriter(r'C:\Users\zen\Desktop\数据.xlsx',mode='a',engine='openpyxl') as writer:
df.to_excel(writer,sheet_name=os.path.basename(i).split('.')[0],index=False)
['C:\\Users\\zen\\Desktop\\拆\\b.xlsx',
'C:\\Users\\zen\\Desktop\\拆\\b二月.xlsx',
'C:\\Users\\zen\\Desktop\\拆\\b五月.xlsx',
'C:\\Users\\zen\\Desktop\\拆\\c三月.xlsx',
'C:\\Users\\zen\\Desktop\\拆\\d四月.xlsx']
import pandas as pd
from openpyxl import load_workbook
from openpyxl.utils.dataframe import dataframe_to_rows
df=pd.read_excel(r'C:\Users\zen\Desktop\数据.xlsx')
df
| 月份 | 数量 | |
|---|---|---|
| 0 | 五月 | 7 |
| 1 | 六月 | 8 |
import pandas as pd
from openpyxl import load_workbook
from openpyxl.utils.dataframe import dataframe_to_rows
df=pd.read_excel(r'C:\Users\zen\Desktop\数据.xlsx')
df
| 月份 | 数量 | |
|---|---|---|
| 0 | 五月 | 7 |
| 1 | 六月 | 8 |
#多个工作表写入相同名字表格
for x,y in df.loc[(df.数量>3),:].groupby('月份',sort=0):
wbook = load_workbook(r'C:\Users\zen\Desktop\测\/'+x+'.xlsx')
ws1=wbook.active
for each in dataframe_to_rows(pd.DataFrame(y.values), index=False, header=False):
ws1.append(each)
wbook.save(r'C:\Users\zen\Desktop\测\/'+x+'.xlsx')
import pandas as pd
df=pd.read_excel(r'C:\Users\zen\Desktop\数据.xlsx')
df
| 数 | 量 | |
|---|---|---|
| 0 | 0 | 2 |
| 1 | 0 | 3 |
| 2 | 1 | 4 |
| 3 | 0 | 5 |
from openpyxl import load_workbook
from openpyxl.utils.dataframe import dataframe_to_rows
wbook = load_workbook(r'C:\Users\zen\Desktop\数据.xlsx')
ws2=wbook['b月']
i = 4 #行号
r=4
for line in df.values:
for col in range(0, len(line)):
ws2.cell(row=i, column=col+4).value = line[col - 1] #col+数字代表第几列 ,数字与r一样
i += 1
r += 1#间隔
wbook.save(r'C:\Users\zen\Desktop\数据.xlsx')
鸢尾花数据集相关性分析
from sklearn.datasets import load_iris
df=load_iris()
import pandas as pd
result=pd.concat([pd.DataFrame(df['data']),pd.DataFrame(df.target)],axis=1)
# result.columns=df['feature_names']
result.describe()
import seaborn as sns
sns.pairplot(result,kind='reg')
Dataframe插入列
import pandas as pd
df1 = pd.DataFrame([['Snow','M',22],['Tyrion','M',32],['Sansa','F',18],['Arya','F',14]], columns=['name','gender','age'])
print("----------在最后新增一列---------------")
print("-------案例1----------")
在数据框最后加上score一列,元素值分别为:80,98,67,90
df1[‘score’]=[80,98,67,90] # 增加列的元素个数要跟原数据列的个数一样
print(df1)
print("-------案例2----------")
print("---------在指定位置新增列:用insert()--------")
在gender后面加一列城市
在具体某个位置插入一列可以用insert的方法
语法格式:列表.insert(index, obj)
index —>对象 obj 需要插入的索引位置。
obj —> 要插入列表中的对象(列名)
col_name=df1.columns.tolist() # 将数据框的列名全部提取出来存放在列表里
print(col_name)
col_name.insert(2,‘city’) # 在列索引为2的位置插入一列,列名为:city,刚插入时不会有值,整列都是NaN
df1=df1.reindex(columns=col_name) # DataFrame.reindex() 对原行/列索引重新构建索引值
df1[‘city’]=[‘北京’,‘山西’,‘湖北’,‘澳门’] # 给city列赋值
print(df1)
print("----------新增行---------------")
重要!!先创建一个DataFrame,用来增加进数据框的最后一行
new=pd.DataFrame({'name':'lisa',
'gender':'F',
'city':'北京',
'age':19,
'score':100},
index=[1]) # 自定义索引为:1 ,这里也可以不设置index
print(new)
print("-------在原数据框df1最后一行新增一行,用append方法------------")
df1=df1.append(new,ignore_index=True) # ignore_index=True,表示不按原来的索引,从0开始自动递增
print(df1)
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import rcParams
matplotlib.use('pgf')
pgf_config={
"font.family":"serief",
"font.size":20,
"pgf.rcfonts":False,
"text.usetex":True,
"pgf.preamble":'\n'.join([
r"\usepackage{unicode-math}",
r"\setmainfont{times new roman}",
r"\usepackage{xeCJK}",
r"\xeCJKsetup{CJKmath=true}",
r"\setCJKmainfont{SimSun}",
]),
}
rcParams.update(pgf_config)
设置tick文字旋转
plt.xticks(rotation= )旋转 Xticks 标签文本fig.autofmt_xdate(rotation= )旋转 Xticks 标签文本ax.set_xticklabels(xlabels, rotation= )旋转 Xticks 标签文本plt.setp(ax.get_xticklabels(), rotation=)旋转 Xticks 标签文本ax.tick_params(axis='x', labelrotation= )旋转 Xticks 标签文本- 旋转
xticklabels对齐
matplotlib图例位置
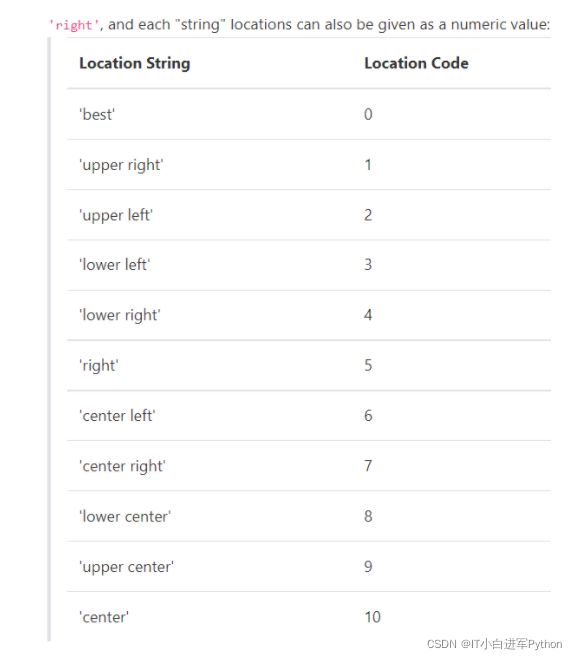
设置图例位置在外面
plt.legend(loc=2, bbox_to_anchor=(1.05,0.7),borderaxespad = 0.)
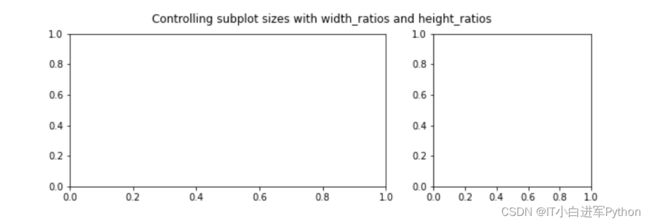
matplotlib不等宽子图
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(10,3))
fig.suptitle("Controlling subplot sizes with width_ratios and height_ratios")
gs = plt.GridSpec(1, 2, width_ratios=[2, 1])
ax1 = fig.add_subplot(gs[0])
ax2 = fig.add_subplot(gs[1])
为图添加text,相对位置
为每张图添加分类的分数
ax.text(0.95,0.06,('%2f'% score).lstrip('0')
,size=15
,bbox=dict(boxstyle='round',alpha=0.8,facecolor='white')
,transform=ax.transAxes,horizontalalignment='right')
转存中…(img-XQ9BzDbK-1648021926388)]
设置图例位置在外面
plt.legend(loc=2, bbox_to_anchor=(1.05,0.7),borderaxespad = 0.)
matplotlib不等宽子图
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(10,3))
fig.suptitle("Controlling subplot sizes with width_ratios and height_ratios")
gs = plt.GridSpec(1, 2, width_ratios=[2, 1])
ax1 = fig.add_subplot(gs[0])
ax2 = fig.add_subplot(gs[1])
为图添加text,相对位置
为每张图添加分类的分数
ax.text(0.95,0.06,('%2f'% score).lstrip('0')
,size=15
,bbox=dict(boxstyle='round',alpha=0.8,facecolor='white')
,transform=ax.transAxes,horizontalalignment='right')