一文读懂机器学习
本文转载自公众号 sigua心底的小声音 ,数学系的一线小研发,更新数据结构和算法 | 深度学习 | 职场等技术原创文章。本公众号有 Google TensorFlow程序员,苹果 (Apple) 公司程序员,微软程序员,一站到底选手,科技公司CTO,省状元都在关注,欢迎大家关注。
本文约6000字,建议阅读10+分钟
本文以图文的形式对模型算法中的集成学习,以及对集中学习在深度学习中的应用进行了详细解读。
目录
- 机器学习概览
- learning from data
- 什么是机器学习
- 机器学习类型
- Supervised learning 监督学习
- Unsupervised learning 无监督学习
- Reinforcement learning 强化学习
- 机器学习的过程
- 如何衡量一个模型的好坏
- Overfitting
- Training, Testing, and Validation Sets
- The Confusion Matrix
- Accuracy Metrics
- 基础的数据分析
- 过拟合overfittting和欠拟合underfitting
- bias and variance
机器学习概览
- learning from data
在深入探讨该主题之前,让我们退后一步,思考一下真正的学习是什么。我们需要为机器考虑的关键概念是learning from data。人类和其他动物可以通过学习经验来调整我们的 行为。learning赋予我们生活的灵活性,我们可以调整适应新的情况,并学习新的技巧。人类学习的重要部分是remembering, adapting, and generalising:认识到上一次我们处于这种情况下(看到了此数据),我们尝试了一些特定的动作(给出了此输出)并且奏效了(正确),因此我们将再次尝试,如果无法奏效,我们将尝试其他操作。概括地说,最后一句话是关于识别不同情况之间的相似性,以便将在一个地方应用的东西可以在另一个地方使用。这就是learning有用的原因,我们可以在很多不同的地方使用我们的知识。
- 什么是机器学习
于是,机器学习就是要使计算机修改或调整动作,让这些动作变得更加准确,它的准确性是由所选动作与正确动作的相似程度来衡量。
本质是让计算机learning from data。
正式定义:
Machine Learning is about building systems that can learn from data. Learning means getting better at some task, given some performance measure.
机器学习类型
我们将learning宽松地定义为通过在某项任务上的练习变得更好。这就引出了两个重要的问题:计算机如何知道是否在变好,如何知道如何改进?这些问题有几种不同的可能答案,它们会产生不同类型的机器学习。现在,我们将考虑机器是否在学习: 我们可以告诉算法问题的正确答案(带标签),以便下次可以正确解决;我们希望只需要告诉它一些正确的答案,然后它就可以“解决”如何为其他问题获得正确的答案;或者,我们可以告诉它答案是否正确,而不是如何找到正确的答案,因此它必须搜索正确的答案;我们根据答案的正确性给答案打分(概率),而不仅仅是“正确或错误”的答案;最后,我们可能没有正确的答案,我们只希望算法查找具有共同点的输入。
这些不同的答案为我们将要讨论的不同算法提供了分类。
- Supervised learning 监督学习
监督学习提供了具有正确答案(targets/标签)的示例训练集,并且基于该训练集,算法可以概括为正确响应所有可能的输入,这也称为learning from exemplars。

一些典型的监督学习算法有:
- k近邻
- 线性回归
- 逻辑回归
- SVM
- 决策树和随机森林
- 神经网络
- Unsupervised learning 无监督学习
无监督学习未提供正确的响应,而是算法尝试识别输入之间的相似性,以便将具有共同点的输入归类在一起。用于无监督学习的统计方法称为密度估计(density estimation)。

一些重要的非监督学习方法:
- 聚类
- 可视化和降维
- 关联性规则
- Reinforcement learning 强化学习
强化学习这是在监督学习和无监督学习之间的某个地方。当答案错误时,系统会告知该算法,但不会告诉你如何更正该算法。它必须探索并尝试各种可能性,直到找到正确的答案。强化学习有时被称为与批评者一起学习,因为该监视器可以对答案进行评分,但不能提出改进建议。

机器学习的过程
- 数据收集和准备: 通常很难收集,要么是因为它需要进行很多测量,要确保它是干净的;它没有重大错误,缺少数据等,需要考虑数据量。机器学习算法需求大量的数据,最好没有太多的噪音,但是增加了数据集的大小增加了计算成本,并且用足够的数据达到了最佳效果而没有过多的计算开销通常是不可能的。
- 特征选择: 这个始终需要事先了解问题和数据;算法根据给定的数据集,选择合适的算法。
- 参数和模型选择:对于许多算法,有一些参数可以必须手动设置,或者需要进行实验才能确定适当的值。
- 训练给定数据集,算法和参数: 训练应该简单地使用计算资源以建立数据模型以进行预测新数据的输出。
- 评估: 在部署系统之前,需要对其进行测试和评估以确保其性能, 对未经训练的数据的准确性计算。
如何衡量一个模型的好坏
learning的目的是更好地预测输出。知道算法成功学习的唯一真实方法是将预测与已知的目标标签进行比较,这是针对监督学习进行训练的方式。这表明你可以做的一件事就是仅查看算法对训练集train set造成的错误error。但是,我们希望算法能推广到训练集中没有看到的数据,并且显然我们无法使用训练集对其进行测试(因为数据已经被看见过了)。因此,我们还需要一些不同的数据(一个测试集test set)来对其进行测试。我们通过输入测试集(input, target) 对到训练好的网络中,并将预测的输出与目标进行比较,不做权重或其他参数修改:我们使用它们来确定算法的性能怎么样。这样做唯一的问题是它减少了我们可用于训练的数据量,但这是我们必须忍受的。
- Overfitting
但实际情况要比上面的描述要复杂,我们可能还想要了解算法在学习过程中的一般性: 我们需要确保进行足够的训练以使算法有很好的一般性。实际上,过度训练的危险与训练不足中的危险一样大。在大多数机器学习算法中,可变性的数量是巨大的-对于神经网络,权重很多,并且每个权重都可以变化。因此我们需要小心:如果训练时间太长,那么我们将过度拟合数据,这意味着我们已经学习了数据中的噪声和不准确性。因此,我们学习的模型太复杂了,无法推广。

在学习过程中有两个不同的点。在图的左侧,曲线很好地拟合了数据的总体趋势(已将其推广到基本的通用函数),但是训练误差不会接近于零。但是右图,随着网络的不断学习,最终将产生一个更复杂的模型,该模型具有较低的训练误差(接近于零),这意味着它已经记住了训练示例,包括其中的任何噪声成分,因此已经过拟合训练数据。
验证集的出现
我们想在算法过拟合之前停止学习过程,这意味着我们需要知道它在每个时间步上的推广程度。我们不能为此使用训练数据,因为它是用来训练参数的,我们不会检测到过度拟合;我们也不能使用测试数据,它是用来看模型性能的,我们将其保存为最终测试。因此,我们需要用于此目的的第三组数据,称为验证集validation set,因为到目前为止我们正在使用它来验证学习,这被称为统计中的交叉验证cross-validation。这是模型选择model selection的一部分:为模型选择正确的参数,以便尽可能地泛化。
- Training, Testing, and Validation Sets
不同数据集的作用
现在,我们需要三组数据:
- 训练集train set: 用于实际训练算法的训练集,把它拿来做函数拟合,使得模型好一点。
- 验证集validation: 用于跟踪算法学习情况, 观察函数好不好调整(改模型的时候依赖它),每次训练完后把模型拿到它的上面去测试一下看看模型好不好,用于没见过的数据,防止模型过拟合,虽然没有训练模型,但是改模型是依据模型的,对于模型来说,validation实际上是见过的,测试真正的效果应该给模型从来没有见过的数据。
- 测试集test set: 当我们的模型都能忍受两个值的时候就定了,最后一步就是拿test来模型上作用看最终的看好坏(用过一次就不用第二次)。如果test数据上了效果还是不好,就要重新选择这三个数据了,因为test数据集已经被见过了。
数据集划分
每种算法都需要一些合理量的数据去学习(精确度有所不同,但是算法看到的数据越多,看到每种可能输入类型的示例的可能性就越大,尽管更多的数据也会增加计算时间)。
平衡的分配
一般来说,数据划分比例取决于你,如果有大量数据,通常执行2:1:1,否则进行3:1:1。拆分方式也很重要。如果你选择前几个作为训练集,接下来选择测试集,依此类推,那么结果将是非常糟糕的,因为训练没有看到所有的类别。这可以通过以下方法解决:首先对数据进行随机重新排序,或者将每个数据点随机分配给一组数据,如下图。

缺乏训练数据
如果你确实缺乏训练数据,那么如果你有单独的验证集,可能会担心算法将无法得到充分训练;那么就可以执行leave-some-out, multi-fold cross-validation。这个想法如下图所示。数据集被随机分为K个子集,一个子集用作验证集,而算法对其他所有数据进行训练。然后遗漏另一个子集,并在该子集上训练一个新模型,并对所有不同的子集重复相同的过程。最后,测试并使用产生最小验证误差的模型。由于我们不得不训练K个不同的模型,而不仅仅是一个模型,因此我们权衡了数据的运行时间。在最极端的情况下,存在留一法交叉验证,该算法仅对一项数据进行验证,并对其余所有数据进行训练。
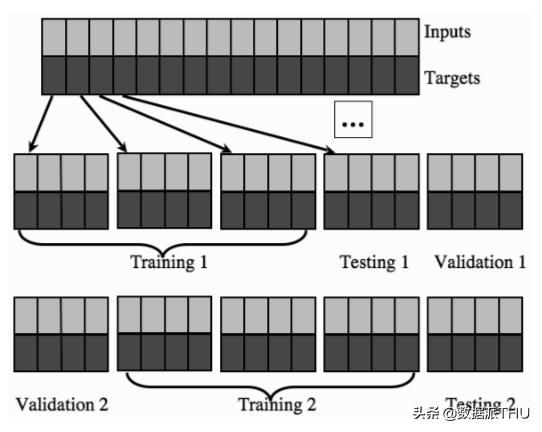
- The Confusion Matrix
无论我们使用多少数据来测试训练过的算法,我们仍然需要确定结果是否良好。我们将在这里介绍一种适用于分类问题的方法,称为混淆矩阵。
混淆矩阵:制作一个包含水平和垂直方向上所有可能类别的方矩阵,并沿着表格顶部列出这些类别作为预测输出,然后在左侧向下列出目标类别。
因此,例如矩阵(i,j)的元素告诉我们输入的数据中,本来是i类的,结果算法判别它呈j类的数据有多少个。算法判断对的数据是对角线上的任何内容。假设我们有三个类:C1,C2和C3。现在,我们计算次数,当类别是C1时候,算法判别它是C1的次数,判别它是C2的次数,等等。直到填写完表格:

该表告诉我们,对于这三个类,大多数示例已正确分类,但是C3类的两个示例被错误分类为C1,依此类推。对于类少的时候,这是查看输出的好方法。如果只需要一个数字,则可以将对角线上的元素之和除以矩阵中所有元素的总和,这就是所谓的准确性accuracy,我们将看到它并不是评估机器学习算法结果的唯一方法。
- Accuracy Metrics
我们不仅可以测量准确性,还可以做更多分析结果的工作。如果考虑这些类的可能输出,则可以将它们安排在这样的简单图表中,ture positive是真实情况,predicted condition 是预测情况,condition positive是真实情况是真的,condition negative是真实情况是假的,predicted condition positive是预测情况是真的,predicted condition negative是预测情况是假的。
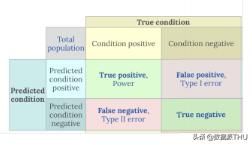
就像混淆矩阵一样,此图表的对角线上的输入是正确的(预测情况和真实情况一致),而副对角线上的输入则是错误的(预测情况和真实情况不一致)。
于是准确性定义:

准确性的问题在于,它无法告诉我们结果的所有信息,因为它将四个数字变成一个。有一些互补的测量值可以帮助我们解释分类器的性能,即 sensitivity 和 specificity 以及 precision 和 recall。接下来显示它们的定义,然后进行一些解释。

- sensitivity(也称为true positive rate)是正确的阳性样本与分类为阳性的样本之比。
- specificity 是正确的阴性样本与分类为阴性的样本之比。
- precision 是正确的阳性样本与实际阳性样本数量的比率,预测正确的值中,真正预测正确的是对少,准确率是多少。
- recall 是分类为阳性的阳性样本中正确阳性的样本数量的比率,这与sensitivity相同。所有正的值中,实际找到它多少个。
如果再次查看该图表,你会发现 sensitivity 和 specificity 的分母是各列的和,而 precision 和 recall 的分母是第一列和第一行的和,因此错过了一些在否定示例中的信息。
总之,这些任何一个都提供了更多的信息,而不仅仅是准确性。如果你考虑 precision 和 recall,你会发现它们在某种程度上是负相关的,因为如果 false positive 的数量增加,那么 false negative 的数量通常会减少,反之亦然。可以将它们组合在一起以给出一个单独的度量标准,即F1度量标准:

以及就false positive的数量而言
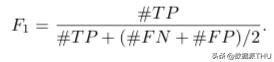
基础的数据分析
如果数据是数字类型,可以提前做一个数据分析,以下几个量是比较常见的:
- 中位数: 数据从小到大排列,最中间的数字就是中位数。
- 众数: 数据中出现次数最多的数字。
- 百分位数: 如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。
- 标准差,方差: 衡量数据的分布均衡不均衡。
- 数据的标准化normalization: 以前的数据差距大,通过标准化,将它们的差距缩小,这样使得程序更好的计算,数据集和测试集都要标准化。
- 异常值outline: 异常值的定义方法有很多,一种方法是比25%的1.5倍还小或75%的1.5倍(大太多了)还大,就是异常值。
- 过拟合overfittting和欠拟合underfitting
过拟合overfittting: 训练数据上效果非常好,没见过的数据就不行 。
欠拟合underfitting: 训练数据上的效果都不怎么行。
过拟合发生在相对于训练数据的量和噪声,模型过于复杂的情况。可能的解决办法有:
- 简化模型,可以通过选择一个参数更少的模型(比如线性模型,而不是高阶多项式模型),减少训练数据的 属性数或限制模型。
- 收集更多的训练数据(然而获取额外的训练数据并不是那么轻易和廉价的)。
- 减小训练数据的噪声(错误测量引入的教噪声,比如修改数据错误,去除异常值)。
- 限定一个模型让它更简单,正则化。
欠拟合发生在你的模型过于简单的时候,可能解决的办法有:
- 选择一个更复杂的模型,带有更多的参数。
- 用更好的特征训练学习算法(特征工程)。
- 减小对模型的限制(比如减小正则化超参数)。
机器学习重点解决的事情如何克服overfitting和underfitting。在统计学中,underfitting和overfittting是bias and variance。
- bias and variance
bias: 随着模型复杂度的上升,错误有一些变化。模型不够完整,没有把相关的特性挖掘出来。这种情况叫bias。
variance: 对训练数据太过敏感,数据稍微一变就会产生错误。

上图的意思:
- 随着模型的复杂度越来越高,overfitting的情况会越来越多(variance),underffting的情况越来越小。
- 期望达到对于现有的数据比较好,对于预期的数据也比较好。
参考资料
- Hands on TensorFlow
- 统计学习方法
- Machine learning: an algorithmic perspective
- Learning from data
编辑:王菁
校对:林亦霖
—完—