BiLSTM-Attention-情感评分
标题
BiLSTM-Attention-情感评分-实战应用
文章目录
-
- 标题
- 前言
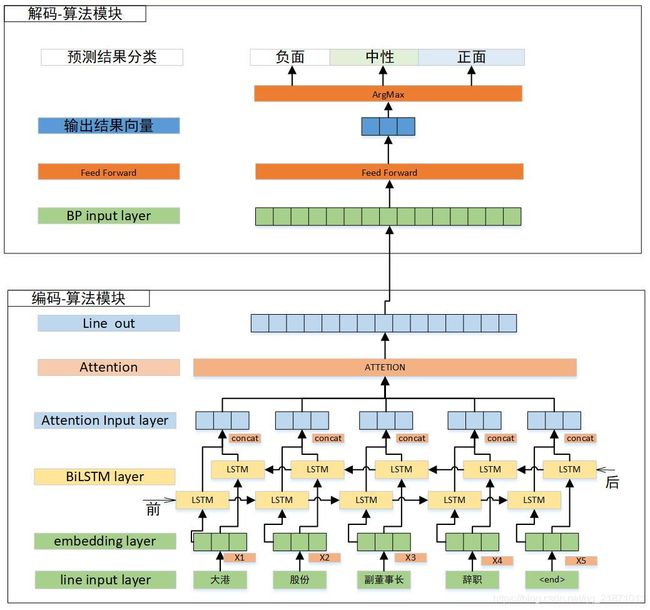
- 一、算法模型图
- 二、附件介绍
- 三、 词向量
-
- 1.说明
- 2.训练方法
- 四、样本数据预处理
- 五、训练、保存训练模型
-
- readtxt2.py 文本工具类
- bpattention.py 训练代码
- 训练结果
- 预测数据情况
- 六、实战运用
-
- BaseRgerBean.java 基础类
- NumberUtil.java 工具类
- Word2VecUtil.java 词向量初始化
- 识别
- 结语
前言
情感分析旨在自动识别和提取文本中的倾向、立场、评价、观点等主观信息。它包含各式各样的任务,比如句子级情感分类、评价对象级情感分类、观点抽取、情绪分类等。这次实战运用主要是针对互联网上新闻数据,目前互联网上关于BiLSTM-Attention运用到文本情感评分的代码很多,理论多于实战。本文将从词向量、样本数据预处理、训练、保存训练结果、运用训练结果等方面介绍。
一、算法模型图
二、附件介绍
资源地址: 链接:https://pan.baidu.com/s/1J5h3fehNIxoxiAISbjmCOw 提取码:5jbj
资源
| 名字 | 说明 |
| java | 词向量训练代码、实战运用模型 |
| python | 训练模型代码 |
| 训练模型 | 已经训练好的模型 |
| Word2vec | 已经训练好的词向量 |
软硬件
| 软件 | 版本 |
| jdk | Jdk1.8 |
| python | 3.4.3 |
| tensorflow | 1.15.0 |
| Java idea - eclipse | launcher |
| Python idea - IntelliJ IDEA Community Edition | 14.1.4 |
三、 词向量
1.说明
本模型使用的是Word2vec,它是一群用来产生词向量的相关模型。这些模型为双层的神经网络,用来训练以重新建构语言学之词文本。
网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
详细介绍略(自己上网翻)。
2.训练方法
com.jt.dctsaple.word2vec.nlp.vec.Learn 详细训练代码,需要的直接看代码,github有大量的源码,大家可以根据自己的需要去寻找。
如果适配特定领域数据,需要寻找该领域的样本,训练该领域词向量。
如果文本分类对数字比较敏感,建议分词时特殊处理。
四、样本数据预处理
样本数据分成三份80%训练、10%测试、10%预测。

目标分类
| 分类 | 分类标记 |
| 负面 | -1 |
| 中性 | 0 |
| 正面 | 1 |
本文的样本对数据中的数字、电话号码做了单独处理,所以大家可以根据自己的需要去做处理,别忘了词向量。
五、训练、保存训练模型
readtxt2.py 文本工具类
import numpy as np
import tensorflow as tf
def _read_word2vec(filepath):
f = open(filepath, encoding='gbk', errors='ignore') # 返回一个文件对象
line = f.readline() # 调用文件的 readline()方法
print(line)
i = 0
words_list = []
words_list_index = []
word_vectors = []
# for j in range(200):
# print(j)
while line:
# print(i, ':', len(line)), # 后面跟 ',' 将忽略换行符
# print(line, end = '') # 在 Python 3中使用
line = f.readline()
line = line.strip('\n')
lines = line.split("\t")
if i >= 1 and lines.__len__() == 202:
# print(lines[0])
v = np.zeros((200))
for j in range(200):
v[j] = float(lines[j+1])
words_list.append(lines[0])
words_list_index.append(i-1)
word_vectors.append(v)
else:
print(line)
i += 1
f.close()
words_list_map = dict(zip(words_list,words_list_index))
return words_list, np.array(word_vectors), words_list_map
def _read_train_data(filepath):
ft = open(filepath, encoding='gbk', errors='ignore') # 返回一个文件对象
# line = f.readline() # 调用文件的 readline()方法
targets = []
words = []
# j = 0
for line in ft.readlines():
line = line.strip('\n')
lines = line.split("" )
v = []
if lines.__len__() != 2:
print(line)
else:
if lines[0] == '1':
targets.append([0, 0, 1])
elif lines[0] == '0':
targets.append([0, 1, 0])
else:
targets.append([1, 0, 0])
ws = lines[1].split("\t")
for i in range(ws.__len__()):
v.append(ws[i])
words.append(v)
# j = j + 1
# if j > 100:
# break
ft.close()
return targets, words
def _find_index_word(word, max_lengh, words_list):
_index = np.zeros((max_lengh), dtype=np.int32)
num = len(word)
if max_lengh < len(word):
num = max_lengh
for i in range(num):
try:
_index[i] = words_list.index(word[i])
except ValueError:
_index[i] = 0
return _index
def _train_data_index(words, max_lengh, words_list):
data_len = len(words)
datax = np.zeros([data_len, max_lengh], dtype=np.int32)
for i in range(data_len):
datax[i] = _find_index_word(words[i], max_lengh, words_list)
return datax
def _train_uniondata_index(words, max_lengh, words_list):
data_len = len(words)
datax = np.zeros([data_len, max_lengh], dtype=np.int32)
for i in range(data_len):
print("_train_uniondata_index %d" % i)
datax[i] = _find_unionindex_word(words[i],max_lengh,words_list)
return datax
def _find_unionindex_word(word, max_lengh, words_list):
_index = np.zeros(max_lengh, dtype=np.int32)
for i in range(max_lengh):
if i < len(word):
try:
_index[i] = int(words_list.get(word[i], 1))
except ValueError:
_index[i] = 1
else:
_index[i] = 1
return _index
if __name__ == "__main__":
words_list, word_vectors,words_list_map = _read_word2vec("../gbn-word2vector.txt")
print(words_list_map.get("'",0))
print(word_vectors.shape)
init = tf.constant_initializer(word_vectors)
print(type(init))
targets, words = _read_train_data("data/padata-1.txt")
datax = _train_uniondata_index(words,64,words_list_map)
for i in range(np.array(words).shape[0]):
ta = targets[i]
print(targets[i])
if ta[1] == 1:
da = datax[i]
line = "int[] input "+str(i) +" = {"
for j in range(88):
if j > 0:
line = line + ","
line = line + str(da[j])
line = line + "};"
print(line)
print(targets[i])
bpattention.py 训练代码
__author__ = 'zxhjiutian'
# -*-coding:utf-8 -*-
import tensorflow as tf
import readtxt2 as read
import datetime
import numpy as np
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
class Config(object):
# 目标分类数目
numClasses = 3
# 拼接长度
# 最大句长
maxSeqLength = 64
# 词向量长度
numDimensions = 200
# 最大简称句长
KEEP_PROB = 0.1 # dropout率
HIDDEN_SIZE = 64 # lstm隐层单元个数
NUM_LAYERS = 1 # lstm层数
VOCAB_SIZE = 10000 # 词表大小
LEARNING_RATE = 0.002 # 学习率
TRAIN_BATCH_SIZE = 64 # 训练batch大小
grad_clip = 4.0 #gradient clipping threshold
# 测试阶段,batch设置为1
EVAL_BATCH_SIZE = 1
EVAL_NUM_STEP = 1
attention_size = 64 # the size of attention layer
class PbAttention(object):
def __init__(self, config, is_training, word_vectors):
self.config = config
self.batch_size = tf.placeholder(tf.int32, name='batch_size')
# 目标分类
self.input_class = tf.placeholder(tf.int32, [None, self.config.numClasses], name="input_class")
# 命中文本
self.input_line = tf.placeholder(tf.int32, [None, self.config.maxSeqLength], name="input_line")
self.is_training = is_training
self.global_step = tf.Variable(0, trainable=False, name='global_step')
self.sequence_lengths = tf.placeholder(tf.int32, shape=[None], name="sequence_lengths")
# [词表大小, 词的向量表示]
self.embedding = tf.get_variable("embedding", shape=[len(word_vectors), 200], initializer=tf.constant_initializer(word_vectors))
self.rnn(self.is_training)
tensor_info_x = tf.saved_model.utils.build_tensor_info(self.input_line)
tensor_info_y = tf.saved_model.utils.build_tensor_info(self.y_pred_cls)
self.tensor_info_x = tensor_info_x
self.tensor_info_y = tensor_info_y
logdir = "tensorboard/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") + "/"
self.logdir = logdir
merged = tf.summary.merge_all()
self.merged = merged
def rnn(self, is_training):
# Define Basic RNN Cell
def basic_rnn_cell(rnn_size):
# return tf.contrib.rnn.GRUCell(rnn_size)
return tf.contrib.rnn.LSTMCell(rnn_size, state_is_tuple=True)
# Define Forward RNN Cell
with tf.name_scope('fw_rnn'):
fw_rnn_cell = tf.contrib.rnn.MultiRNNCell([basic_rnn_cell(self.config.HIDDEN_SIZE) for _ in range(self.config.NUM_LAYERS)])
if is_training:
fw_rnn_cell = tf.contrib.rnn.DropoutWrapper(fw_rnn_cell, output_keep_prob=self.config.KEEP_PROB)
# Define Backward RNN Cell
with tf.name_scope('bw_rnn'):
bw_rnn_cell = tf.contrib.rnn.MultiRNNCell([basic_rnn_cell(self.config.HIDDEN_SIZE) for _ in range(self.config.NUM_LAYERS)])
if is_training:
bw_rnn_cell = tf.contrib.rnn.DropoutWrapper(bw_rnn_cell, output_keep_prob=self.config.KEEP_PROB)
# Embedding layer
with tf.name_scope('embedding_line'):
input_line_vec = tf.nn.embedding_lookup(self.embedding, self.input_line)
tf.summary.histogram("input_line_vec", input_line_vec)
with tf.name_scope('bi_rnn'):
rnn_output, _ = tf.nn.bidirectional_dynamic_rnn(fw_rnn_cell, bw_rnn_cell, inputs=input_line_vec,
sequence_length=self.sequence_lengths, dtype=tf.float32)
tf.summary.histogram("rnn_output", rnn_output)
if isinstance(rnn_output, tuple):
rnn_output = tf.concat(rnn_output, 2)
# Attention Layer
with tf.name_scope('attention'):
input_shape = rnn_output.shape # (batch_size, sequence_length, hidden_size)
sequence_size = input_shape[1].value # the length of sequences processed in the RNN layer
hidden_size = input_shape[2].value # hidden size of the RNN layer
attention_w = tf.Variable(tf.truncated_normal([hidden_size, self.config.attention_size], stddev=0.1),
name='attention_w')
attention_b = tf.Variable(tf.constant(0.1, shape=[self.config.attention_size]), name='attention_b')
attention_u = tf.Variable(tf.truncated_normal([self.config.attention_size], stddev=0.1), name='attention_u')
# tf.summary.distribution("attention_w", attention_w)
z_list = []
for t in range(sequence_size):
u_t = tf.tanh(tf.matmul(rnn_output[:, t, :], attention_w) + tf.reshape(attention_b, [1, -1]))
z_t = tf.matmul(u_t, tf.reshape(attention_u, [-1, 1]))
z_list.append(z_t)
# Transform to batch_size * sequence_size hideen
attention_z = tf.concat(z_list, axis=1)
self.alpha = tf.nn.softmax(attention_z)
attention_output = tf.reduce_sum(rnn_output * tf.reshape(self.alpha, [-1, sequence_size, 1]), 1)
tf.summary.histogram("alpha", self.alpha)
tf.summary.histogram("attention_output", attention_output)
# attention_output shape: (batch_size, hidden_size)
# Add dropout
with tf.name_scope('dropout'):
# attention_output shape: (batch_size, hidden_size)
self.final_output = tf.nn.dropout(attention_output, rate=self.config.KEEP_PROB)
tf.summary.histogram("final_output", self.final_output)
# Fully connected layer
with tf.name_scope('output'):
fc_w = tf.Variable(tf.truncated_normal([hidden_size, self.config.numClasses], stddev=0.1), name='fc_w')
fc_b = tf.Variable(tf.zeros([self.config.numClasses]), name='fc_b')
# 目标向量
self.logits = tf.matmul(self.final_output, fc_w) + fc_b
self.y_pred_cls = tf.argmax(self.logits, 1, name='predictions')
tf.summary.histogram("fc_w", fc_w)
tf.summary.histogram("fc_b", fc_b)
tf.summary.histogram("logits", self.logits)
tf.summary.histogram("y_pred_cls", self.y_pred_cls)
# Calculate cross-entropy loss
with tf.name_scope('loss'):
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=self.input_class)
self.loss = tf.reduce_mean(cross_entropy)
tf.summary.scalar("loss", self.loss)
# Create optimizer
with tf.name_scope('optimization'):
optimizer = tf.train.AdamOptimizer(self.config.LEARNING_RATE)
gradients, variables = zip(*optimizer.compute_gradients(self.loss))
gradients, _ = tf.clip_by_global_norm(gradients, self.config.grad_clip)
self.optim = optimizer.apply_gradients(zip(gradients, variables), global_step=self.global_step)
# Calculate accuracy
with tf.name_scope('accuracy'):
correct_pred = tf.equal(self.y_pred_cls, tf.argmax(self.input_class, 1))
self.acc = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
tf.summary.scalar("accuracy", self.acc)
def get_sequence_length(x_batch):
"""
Args:
x_batch:a batch of input_data
Returns:
sequence_lenghts: a list of acutal length of every senuence_data in input_data
"""
sequence_lengths=[]
for x in x_batch:
actual_length = np.sum(np.sign(x))
sequence_lengths.append(actual_length)
return sequence_lengths
def run_epoch(session, model, data, target, eval_data, eval_target):
writer = tf.summary.FileWriter(model.logdir, session.graph)
saver = tf.train.Saver()
# state = session.run(model.initial_state) # vlstm单元初始状态
batch_size = 128
# 训练一个epoch。
steps = 5000
dataset_size = len(target)
dataset_size = (dataset_size // batch_size) * batch_size
eval_dataset_size = len(eval_target)
eval_dataset_size = (eval_dataset_size // batch_size) * batch_size
for step in range(steps):
# 每次选取batch_size个样本训练
start = (step * batch_size) % dataset_size
end = min(start + batch_size, dataset_size)
x_batch = data[start:end]
sequence_lengths = get_sequence_length(x_batch)
_batch_size1 = end - start + 1
optimizer, summary, accuracy = session.run([model.optim, model.merged, model.acc],
{model.input_line: x_batch, model.input_class: target[start:end],
model.sequence_lengths: sequence_lengths,
model.batch_size: _batch_size1
})
if step % 10 == 0:
# summary = session.run(model.merged, {model.sequence_lengths: sequence_lengths,
# model.input_line: x_batch,
# model.input_class: target[start:end],
# model.batch_size: batch_size})
writer.add_summary(summary, step)
# print(step, optimizer)
if step % 20 == 0:
# accuracy = session.run(model.acc, {model.sequence_lengths: sequence_lengths,
# model.input_line: x_batch,
# model.input_class: target[start:end],
# model.batch_size: batch_size})
print("step: %d accuracy: %g time: %s" % (step, accuracy, datetime.datetime.now().strftime("%Y%m%d-%H%M%S")))
# Save the network every 10,000 training iterations
# if step % 5000 == 0 and step != 0:
if step % 100 == 0 and step != 0:
eval_step = step // 100
eval_start = (eval_step * 1000) % eval_dataset_size
eval_end = min(eval_start + 1000, eval_dataset_size)
eval_batch = eval_data[eval_start:eval_end]
eval_batch_class = eval_target[eval_start:eval_end]
eval_sequence_lengths = get_sequence_length(eval_batch)
_batch_size = eval_end - eval_start + 1
optimizer, summary, accuracy = session.run([model.optim, model.merged, model.acc],
{model.input_line: eval_batch,
model.input_class: eval_batch_class,
model.sequence_lengths: eval_sequence_lengths,
model.batch_size: _batch_size
})
print("eval step: %d accuracy: %g time: %s" % (step, accuracy, datetime.datetime.now().strftime("%Y%m%d-%H%M%S")))
if accuracy > 0.92 and step > 1000:
break
# save_path = saver.save(session, "model/"+str(step)+"/pretrained_lstm.ckpt", global_step=step)
# print("saved to %s" % save_path)
save_path = saver.save(session, "model/pretrained_lstm.ckpt", global_step=step)
print("saved to %s" % save_path)
writer.close()
def main():
g_2 = tf.Graph()
with g_2.as_default():
# word2vec 文件中
words_list, word_vectors, words_list_map = read._read_word2vec("../data/gbn-word2vector.txt")
print("----------------------------------bg-1------------------------------")
# print(words_list.__le__())
# print(len(word_vectors))
#print(len(words_list_map))
targets, words= read._read_train_data("data/padata-1.txt")
print("----------------------------------bg-2------------------------------")
config = Config()
datax = read._train_uniondata_index(words, config.maxSeqLength, words_list_map)
print("----------------------------------bg-------------------------------")
eval_targets, eval_words = read._read_train_data("data/padatapre-1.txt")
eval_datax = read._train_uniondata_index(eval_words, config.maxSeqLength, words_list_map)
print("----------------------------------bg-veal-------------------------------")
initializer = tf.random_uniform_initializer(-0.05, 0.05)
with tf.variable_scope("language_model", reuse=None, initializer=initializer):
train_model = PbAttention(config, True, word_vectors)
with tf.Session(graph=g_2) as session:
tf.global_variables_initializer().run()
for i in range(1):
print("In iteration: %d" % (i + 1))
run_epoch(session, train_model, datax, targets, eval_datax, eval_targets)
train_model.is_training = False
prediction_signature = tf.saved_model.signature_def_utils.build_signature_def(
inputs={'input-x': train_model.tensor_info_x},
outputs={'out-y':train_model.tensor_info_y})
legacy_init_op = tf.group(tf.tables_initializer(), name='legacy_init_op')
# 保存训练模型 java 要调用
builder = tf.saved_model.builder.SavedModelBuilder("model/pb/"
+ datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
builder.add_meta_graph_and_variables(
session, [tf.saved_model.tag_constants.SERVING],
signature_def_map={
'predict_data': prediction_signature},
legacy_init_op=legacy_init_op)
builder.save(False)
graph_def = g_2.as_graph_def()
if __name__ == "__main__":
print(1)
main()
训练结果
tensorboard --host=127.0.0.1 --logdir= tensorboard 查看训练参数
地址:http://127.0.0.1:6006/
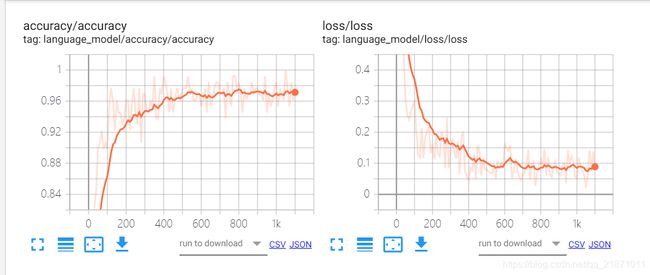
准确率和损失函数
预测数据情况
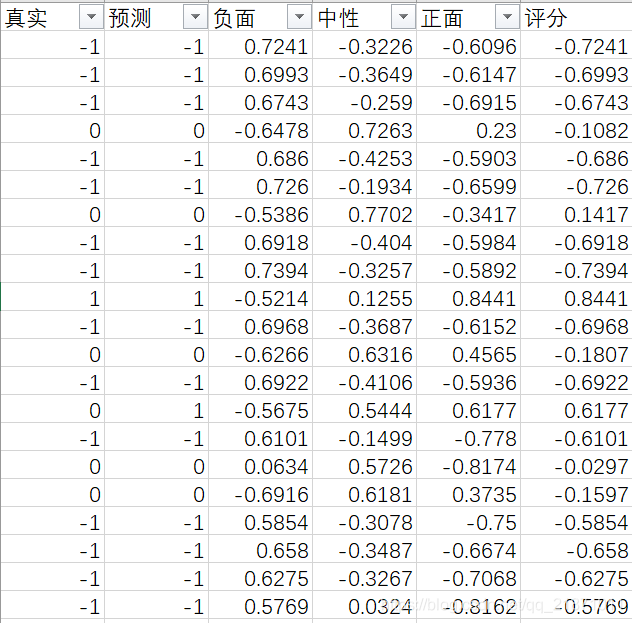
部分预测数据
六、实战运用
BaseRgerBean.java 基础类
package com.jt.dctsaple.tf;
import java.text.NumberFormat;
import org.tensorflow.Graph;
import org.tensorflow.SavedModelBundle;
import org.tensorflow.Session;
/**
* 识别风险命中是否准确
* @author zxh
* @date 2020年8月3日 上午11:01:41
*/
public abstract class BaseRgerBean {
NumberFormat nf = NumberFormat.getNumberInstance();
protected SavedModelBundle smb= null;
protected Graph graph = null;
protected Session session = null;
/**
*
* @param modelPath 模型位置
*/
public BaseRgerBean(String modelPath){
smb= SavedModelBundle.load(
modelPath,"serve");
graph = smb.graph();
session = smb.session();
nf.setMaximumFractionDigits(4);
}
/**
* 预测
* @param line 命中句子
* @param maxLeangh 句长限制
* @time 2020-08-3
* @return
*/
public abstract Object[] predictions(String line,int maxlength);
/**
*
* @param words
* @param maxlength
* @return
*/
public abstract Object[] predictions(String[] words,int maxlength);
/**
* 余玄
* @param a
* @param b
* @return
*/
public double cose(float[] a,float[] b){
float fm = 0;
for (int i = 0; i < b.length; i++) {
fm += a[i]*b[i];
}
float atw = 0;
for (int i = 0; i < a.length; i++) {
atw += a[i]*a[i];
}
float btw = 0;
for (int i = 0; i < b.length; i++) {
btw += b[i]*b[i];
}
return Double.valueOf(nf.format(fm/Math.sqrt(atw*btw)));
}
}
NumberUtil.java 工具类
package com.jt.dctsaple.tf;
import java.math.BigInteger;
import java.util.Arrays;
import org.apache.commons.lang.StringUtils;
/**
* 数值提取
* @author zxh
* @date 2020年7月27日 下午2:18:32
*/
public class NumberUtil {
private NumberUtil(){}
/**
* 提取数值
* @param word
* @return Object[] [doube,单位]
*/
public static Object[] getNumBerString(String word){
if(StringUtils.isBlank(word)){
return null;
}
String numstr = "";
String dwstr = "";
char[] ws = word.toCharArray();
if(word.startsWith("."))
return null;
for (int i = 0; i < ws.length; i++) {
if((ws[i] >= '0' && ws[i] <= '9') || ws[i] == '.'){
numstr += ws[i];
}else{
if(i == 0){
return null;
}
dwstr += ws[i];
}
}
if(StringUtils.isBlank(dwstr)){
return new Object[]{Math.round(Double.valueOf(numstr))};
}else{
return new Object[]{Math.round(Double.valueOf(numstr)),dwstr};
}
}
public static String[] getVec(String v,int length){
String[] vec = new String[length];
BigInteger targetSignature = new BigInteger( v + "");
String vec2 = targetSignature.toString(2);
char[] cs = vec2.toCharArray();
int j = cs.length - 1;
for (int i = length - 1; i >= 0; i--) {
if(j>=0){
vec[i] = cs[j]+"";
}else{
vec[i] = "0";
}
j--;
}
return vec;
}
}
Word2VecUtil.java 词向量初始化
package com.jt.dctsaple.tf;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.commons.io.FileUtils;
import org.apdplat.word.WordSegmenter;
import org.apdplat.word.segmentation.SegmentationAlgorithm;
import org.apdplat.word.segmentation.Word;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Word2VecUtil {
public static String dicfile = "library/gbn-word2vector.txt";
private static final Logger log = LoggerFactory.getLogger(Word2VecUtil.class);
static Map<String,Integer> wordIndex = new HashMap<>();
private Word2VecUtil(){
}
public static void init(){
List<String> list;
try {
list = FileUtils.readLines(new File(dicfile), "GBK");
for (int i = 2; i < list.size(); i++) {
String[] indexs = list.get(i).split("\t");
if(indexs.length > 200){
wordIndex.put(indexs[0], i-2);
}
}
} catch (IOException e) {
log.error("加载词向量出现问题 path={} ", dicfile);
}
}
/**
* 查找词向量索引
* @param words 分词
* @param maxlength 最大长度
* @return
*/
public static int[] getWordIndex(String[] words,int maxlength){
int[] indexs = new int[maxlength];
for (int i = 0; i < indexs.length; i++) {
indexs[i] = 0;
}
int j = 0;
for (int i = 0; i < words.length && i<maxlength; i++) {
String word = words[i];
if(wordIndex.containsKey(word)){
indexs[j] = wordIndex.get(word);
}else{
indexs[j] = 1;
}
j ++;
}
return indexs;
}
/**
* NLP 分词
* @param line
* @return
*/
public static String[] nlpSplitWord(String line){
List<String> splitwords = new ArrayList<>();
List<Word> words = WordSegmenter.segWithStopWords(line, SegmentationAlgorithm.MaxNgramScore);
for (Word word : words) {
Object[] ws = NumberUtil.getNumBerString(word.getText());
if(ws == null){
splitwords.add(word.getText());
}else{
if(ws.length == 2){
Long vlimit = Long.valueOf(ws[0]+"");
if(vlimit < 10001){
}else if(vlimit > 10000000000L){
splitwords.add("SJHM");
}else{
splitwords.add("10000");
}
String daw = ws[1]+"";
splitwords.add(daw);
}
if(ws.length == 1){
Long vlimit = Long.valueOf(ws[0]+"");
if(vlimit < 10001){
splitwords.add(vlimit+"");
}else if( vlimit > 10000000000L){
splitwords.add("SJHM");
}else{
splitwords.add("10000");
}
}
}
}
String[] rtwords = new String[splitwords.size()];
for (int i = 0; i < rtwords.length; i++) {
rtwords[i] = splitwords.get(i);
}
return rtwords;
}
}
识别
package com.jt.dctsaple.tf;
import java.text.DecimalFormat;
import java.util.Arrays;
import java.util.List;
import org.tensorflow.Tensor;
/**
* 情感分析模型
* @author zxh
*
*/
public class GbAnasysBean extends BaseRgerBean{
DecimalFormat df = new DecimalFormat("#0.0000");
public GbAnasysBean(String modelPath) {
super(modelPath);
}
@Override
public Object[] predictions(String line, int maxlength) {
String[] words = Word2VecUtil.nlpSplitWord(line);
return predictions(words, maxlength);
}
@Override
public Object[] predictions(String[] words, int maxlength) {
int[] indexs = Word2VecUtil.getWordIndex(words, maxlength);
int[][] _inputs = new int[1][maxlength];
_inputs[0] = indexs;
Tensor<?> inputs = Tensor.create(_inputs);
Tensor<?> batch_size = Tensor.create(1);
Tensor<?> sequence_lengths = Tensor.create(new int[]{maxlength});
List<Tensor<?>> result = session.runner()
.feed("language_model/input_line", inputs) //输入文本
.feed("language_model/batch_size", batch_size) //批量
.feed("language_model/sequence_lengths", sequence_lengths) //长度
.fetch("language_model/output/add") //输出向量
.fetch("language_model/output/predictions").run(); //输出最大值索引
Tensor<Float> vs = result.get(0).expect(Float.class);
long[] sss = vs.shape();
int nlabels = (int) sss[1];
float[][] ks = vs.copyTo(new float[1][nlabels]);
Tensor<Long> _vs = result.get(1).expect(Long.class);
long[] s = _vs.copyTo(new long[1]);
float[] v = ks[0];
float[] y_1 = {(float) 1.0,(float) 0.0,(float) 0.0};
float[] y0 = {(float) 0.0,(float) 1.0,(float) 0.0};
float[] y1 = {(float) 0.0,(float) 0.0,(float) 1.0};
// 1=[1,0] 0=[0,1]
int cs = -1;
if(s[0] == 0){
cs = -1;
}
if(s[0] == 1){
cs = 0;
}
if(s[0] == 2){
cs = 1;
}
double dis_1 = cose(v , y_1);
double dis0 = cose(v , y0);
double dis1 = cose(v , y1);
double score = 0;
if(cs == -1){
score = dis_1 * -1;
}else
if(cs == 1){
score = dis1 ;
}else{
score = Double.valueOf(nf.format(dis_1 * dis0 * dis1));
}
return new Object[]{cs,dis_1,dis0,dis1,score};
}
public static void main(String[] args) {
Word2VecUtil.dicfile = "..\\..\\..\\gbn-word2vector.txt";
Word2VecUtil.init();
GbAnasysBean bg = new GbAnasysBean("...\\model\\pb\\20200828-174724");
Object[] objs = bg.predictions("字节跳动确认:TikTok首席执行官凯文·梅耶尔辞任 Vanessa担任临时负责人", 64);
System.out.println(Arrays.toString(objs));
}
}
结语
谨以此文作为技术交流,有错误之处请不吝赐教。