构建企业级推荐系统(08):矩阵分解推荐算法(万文建藏)
作者:刘强
简介:《构建企业级推荐系统》作者,公众号「数据与智能」主理人,9年推荐系统实战经验,持续输出推荐系统、大数据、机器学习、AI等硬核技术文章
《构建企业级推荐系统》新书已出版,强烈建议收藏加关注,文章免费看!
创作不易,点赞 关注 支持一下吧✌
《构建企业级推荐系统》往期文章回顾
第一篇:推荐系统介绍
第二篇:推荐系统产品概述
第三篇:推荐算法团队介绍
第四篇:推荐算法概述
第五篇:从零开始入门推荐算法工程师
第六篇:基于内容的推荐算法
第七篇:协同过滤推荐算法
持续更新中......
目录
一、矩阵分解算法的核心思想
二、矩阵分解算法的算法原理
三、矩阵分解算法的求解方法
3.1 利用SGD来求解矩阵分解
3.2 利用ALS来求解矩阵分解
(1) 可以并行化处理
(2) 对于隐式特征问题比较合适
四、矩阵分解推荐算法的拓展与优化
4.1 整合偏差(bias)项
4.3 整合时间因素
4.4 整合用户对评分的置信
4.5 隐式反馈
4.6 整合用户和标的物metadata信息
五、近实时矩阵分解算法
5.1 算法原理
5.2 工程实现
步骤1:获取种子视频集
步骤2:获取候选推荐视频集
步骤3:获取特征向量
步骤4:预测评分偏好
步骤5:候选集排序
六、矩阵分解算法的应用场景
6.1 应用于完全个性化推荐场景(完全个性化推荐范式)
6.2 应用于标的物关联的物场景(标的物关联标的物范式)
6.3 用于用户及标的物聚类
6.4 应用于群组个性化场景(群组个性化推荐范式)
七、矩阵分解算法的优缺点
7.1 优点
(1) 不依赖用户和标的物的其他信息,只需要用户行为就可以为用户做推荐
(2) 推荐精准度不错
(3) 可以为用户推荐惊喜的标的物
(4) 易于并行化处理
7.2 缺点
(1) 存在冷启动问题
(2) 可解释性不强
总结
参考文献
作者在《协同过滤推荐算法》这篇文章中介绍了user-based和item-based协同过滤算法,这类协同过滤算法是基于邻域的算法(也称为基于内存的协同过滤算法),该算法不需要模型训练,基于非常朴素的思想就可以为用户生成推荐结果。还有一类基于隐因子(模型)的协同过滤算法也非常重要,这类算法中最重要的代表就是本节我们要讲的矩阵分解算法。矩阵分解算法是2006年Netflix推荐大赛获奖的核心算法,在整个推荐系统发展史上具有举足轻重的地位,对促进推荐系统的大规模发展及工业应用功不可没。
本篇文章我们会详细介绍矩阵分解算法的方方面面。我们会从矩阵分解算法的核心思想、矩阵分解算法的算法原理、矩阵分解算法的求解方法、矩阵分解算法的拓展与优化、近实时矩阵分解算法、矩阵分解算法的应用场景、矩阵分解算法的优缺点等7个方面来讲解矩阵分解算法。希望通过本文的学习,读者可以很好地了解矩阵分解的算法原理与工程实现,并且具备自己动手实践矩阵分解算法的能力,可以尝试将矩阵分解算法应用到自己的推荐业务中。
一、矩阵分解算法的核心思想
我们在《协同过滤推荐算法》这篇文章中讲过,用户操作行为可以转化为如下的用户行为矩阵。其中
![]()
是用户i对标的物j的评分,如果是隐式反馈,值为0或者1(隐式反馈可以通过一定的策略转化为得分,具体参考《协同过滤推荐算法》这篇文章介绍),本文我们主要用显示反馈(用户的真实评分)来讲解矩阵分解算法,对于隐式反馈,我们将在第四节5中专门讲解和说明。

图1:用户对标的物的操作行为矩阵
矩阵分解算法是将用户评分矩阵
![]()
分解为两个矩阵
![]()
、
![]()
的乘积。
![]()
其中,
![]()
代表的用户特征矩阵,
![]()
代表标的物特征矩阵。
某个用户对某个标的物的评分,就可以采用矩阵
![]()
对应的行(该用户的特征向量)与矩阵
![]()
对应的列(该标的物的特征向量)的乘积。有了用户对标的物的评分就很容易为用户做推荐了。具体,可以采用如下方式为用户做推荐:
首先可以将用户特征向量
![]()
乘以标的物特征矩阵
![]()
,最终得到用户对每个标的物的评分
![]()
。

图2:为用户计算所有标的物评分
得到用户对标的物的评分
![]()
后,从该评分中过滤掉用户已经操作过的标的物,针对剩下的标的物得分做降序排列取topN推荐给用户。
矩阵分解算法的核心思想是将用户行为矩阵分解为两个低秩矩阵的乘积,通过分解,我们分别将用户和标的物嵌入到了同一个k维的向量空间(k一般很小,几十到上百),用户向量和标的物向量的内积代表了用户对标的物的偏好度。所以,矩阵分解算法本质上也是一种嵌入方法。
上面提到的k维向量空间的每一个维度是隐因子(latent factor),之所以叫隐因子,是因为每个维度不具备与现实场景对应的具体的可解释的含义,所以矩阵分解算法也是一类隐因子算法。这k个维度代表的是某种行为特性,但是这个行为特性又是无法用具体的特征解释的,从这点也可以看出,矩阵分解算法的可解释性不强,我们比较难以解释矩阵分解算法为什么这么推荐。
矩阵分解的目的是通过机器学习的手段将用户行为矩阵中缺失的数据(用户没有评分的元素)填补完整,最终达到可以为用户做推荐的目标。
讲完了矩阵分解算法的核心思路,那么我们怎么利用机器学习算法来对矩阵进行分解呢?这就是下节要讲的主要内容。
二、矩阵分解算法的算法原理
前面只是很形式化地描述了矩阵分解算法的核心思想,本节我们来详细讲解怎么将矩阵分解问题转化为一个机器学习问题,从而方便我们训练机器学习模型、求解该模型,具备最终为用户做推荐的能力。
假设所有用户有评分的
![]()
对(
![]()
代表用户,
![]()
代表标的物)组成的集合为A,
![]()
,通过矩阵分解将用户
![]()
和标的物
![]()
嵌入k维隐式特征空间的向量分别为:
![]()
![]()
那么用户
![]()
对标的物
![]()
的预测评分为
![]()
,真实值与预测值之间的误差为
![]()
。如果预测得越准,那么
![]()
越小,针对所有用户评分过的
![]()
对,如果我们可以保证这些误差之和尽量小,那么有理由认为我们的预测是精准的。
有了上面的分析,我们就可以将矩阵分解转化为一个机器学习问题。具体地说,我们可以将矩阵分解转化为如下等价的求最小值的最优化问题。
![]()
公式1:矩阵分解等价的最优化问题
其中
![]()
是超参数,可以通过交叉验证等方式来确定,
![]()
是正则项,避免模型过拟合。通过求解该最优化问题,我们就可以获得用户和标的物的特征嵌入(用户的特征嵌入
![]()
,就是上一节中用户特征矩阵
![]()
的行向量,同理,标的物的特征嵌入
![]()
就是标的物特征矩阵
![]()
的列向量),有了特征嵌入,就可以为用户做个性化推荐了。
那么剩下的问题是怎么求解上述最优化问题了,这是下节主要讲解的内容。
三、矩阵分解算法的求解方法
对于上一节讲到的最优化问题,在工程上一般有两种求解方法,SGD(Stochastic Gradient Descent)和ALS(Alternating Least Squares)。下面我们分别讲解这两种方法的实现原理。
3.1 利用SGD来求解矩阵分解
假设用户
![]()
对标的物
![]()
的评分为
![]()
,
![]()
嵌入k维隐因子空间的向量分别为
![]()
,我们定义真实评分和预测评分的误差为
![]()
,公式如下:
![]()
我们可将公式1写为如下函数
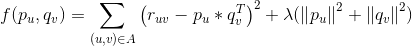
![]()
对
![]()
求偏导数,具体计算如下:
![]()
![]()
有了偏导数,我们沿着导数(梯度)相反的方向更新
![]()
,最终我们可以采用如下公式来更新
![]()
。
![]()
![]()
上式中
![]()
为步长超参数,也称为学习率(导数前面的系数2可以吸收到参数
![]()
中),取大于零的较小值。
![]()
先可以随机取值,通过上述公式不断更新
![]()
,直到收敛到最小值(一般是局部最小值),最终求得所有的
![]()
。
SGD方法一般可以快速收敛,但是对于海量数据的情况,单机无法承载这么大的数据量,所以在单机上是无法或者在较短的时间内无法完成上述迭代计算的,这时我们可以采用下面的ALS方法来求解,该方法可以非常容易做分布式拓展。
3.2 利用ALS来求解矩阵分解
ALS方法是一个高效的求解矩阵分解的算法,目前Spark Mllib中的协同过滤算法就是基于ALS求解的矩阵分解算法,它可以很好地拓展到分布式计算场景,轻松应对大规模训练数据的情况(参考文献6中有ALS分布式实现的详细说明)。下面对ALS算法原理及特点做一个简单介绍。
ALS算法的原理基本就是名字表达的意思,通过交替优化求得极值。一般过程是先固定
![]()
,那么公式1就变成了一个关于
![]()
的二次函数,可以作为最小二乘问题来解决,求出最优的
![]()
后,固定
![]()
,再解关于
![]()
的最小二乘问题,交替进行直到收敛。对工程实现有兴趣的读者可以参考Spark ALS算法的源码。相比SGD算法,ALS算法有如下两个优势。
(1) 可以并行化处理
从上面
![]()
、
![]()
的更新公式中可以看到,当固定
![]()
后,迭代更新
![]()
时每个
![]()
只依赖自己,不依赖于其他的标的物的特征向量,所以可以将不同的
![]()
的更新放到不同的服务器上执行。同理,当
![]()
固定后,迭代更新
![]()
时每个
![]()
只依赖自己,不依赖于其他用户的特征向量,一样可以将不同用户的更新公式放到不同的服务器上执行。Spark的ALS算法就是采用这样的方式做到并行化的。
(2) 对于隐式特征问题比较合适
用户真正的评分是很稀少的,所以利用隐式行为是更好的选择(其实也是不得已的选择)。当利用了隐式行为,那么用户行为矩阵就不会那么稀疏了,即有非常多的
![]()
对是非空的,计算量会更大,这时采用ALS算法是更合适的,因为固定
![]()
或者
![]()
,让整个计算问题更加简单,容易求目标函数的极值。读者可以阅读参考文献5,进一步了解隐式反馈利用ALS算法实现的原因及细节(Spark MLlib中的ALS算法即是参考该论文来实现的)。
四、矩阵分解推荐算法的拓展与优化
前面几节对矩阵分解的原理及求解方法进行了介绍,我们知道矩阵分解算法是一个非常容易理解并易于分布式实现的算法。不光如此,矩阵分解算法的框架还是一个非常容易拓展的框架,可以整合非常多的其他信息及特性到该框架之下,从而丰富模型的表达空间,提升预测的准确度。本节我们就来总结和梳理一下矩阵分解算法可以进行哪些拓展与优化。
4.1 整合偏差(bias)项
在第二节,用户u对标的物v的评分采用公式
![]()
来预测,但是不同的人对标的物的评价可能是不一样的,有的人倾向于给更高的评分,而有的人倾向于给更低的评分。对于同一个标的物,也会受到外界其他信息的干扰,影响人们对它的评价(比如视频,可能由于主演的热点事件导致该视频突然变火),这两种情况是由于用户和标的物引起的偏差。我们可以在这里引入Bias项,将评分表中观察到的值分解为4个部分:全局均值(global average),标的物偏差(item bias),用户偏差(user bias)和用户标的物交叉项(user-item interaction)。这时,我们可以用如下公式来预测用户u对标的物v的评分:
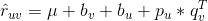
其中
![]()
是全局均值,
![]()
是标的物偏差,
![]()
是用户偏差,
![]()
是用户与标的物交叉项。那么最终的优化问题就转化为:
![]()
该优化问题同样可以采用SGD或者ALS算法来优化,该方法在开放数据集及工业实践上都被验证比不整合Bias的方法有更好的预测效果(见参考文献8)。
由于用户一般只对很少的标的物评分,导致评分过少,可能无法给该用户做出较好的推荐,这时可以通过引入更多的信息来缓解评分过少的问题。具体来说,我们可以整合用户隐式反馈(收藏、点赞、分享等)和用户人口统计学信息(年龄、性别、地域、收入等)到矩阵分解模型中。
对于隐式反馈信息,我们用
![]()
来表示用户有过隐式反馈的标的物集合。
![]()
,
![]()
是用户对标的物v的隐式反馈的嵌入特征向量(这里为了简单起见,我们不区分用户的各种隐式反馈,只要用户做了一次隐式反馈,认为有隐式反馈,即是采用布尔代数的方式来处理隐式反馈)。那么对用户所有的隐式反馈
![]()
,累计的特征贡献为
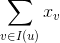
我们可以对上式进行如下的归一化处理
![]()
对于用户人口统计学信息,假设
![]()
是用户的所有人口统计学属性构成的集合,
![]()
,
![]()
是属性
![]()
在嵌入特征向量空间的表示。那么用户u所有的人口统计学信息可以综合表示为
![]()
最终整合了用户隐式反馈和人口统计学信息后(包括偏差项)的用户预测公式可以表示为:
![]()
同样地,我们可以写出最终的优化目标函数。由于公式太长,这里不写出来了。该模型也可以用SGD和ALS算法来求解。
4.3 整合时间因素
到目前为止,我们的模型都是静态的。实际上,用户的偏好、用户对标的物的评分趋势、以及标的物的受欢迎程度都是随着时间变化的(读者可以阅读参考文献11,对怎么在协同过滤中整合时间因素有更深入的了解)。
拿电影来说,用户可能原来喜欢爱情类的电影,后面可能会转而喜欢科幻喜剧类电影,所以我们用包含时间的
![]()
来表示用户的偏好特性向量。用户开始对某个视频偏向于打高分,经过一段时间后,用户看的电影多了起来,用户的审美越来越挑剔,所以一般不会再对一个电影打很高的分数了,除非他觉得真的特别好,因此,我们可以用包含时间的
![]()
来表示用户的偏差随着时间而变化。对于标的物偏差也一样,一个电影可能开始不是很火,但是如果它的主演后面演了一部非常火的电影,也会将将原来的电影热度带到一个新的高度。比如,最近比较火的李现演的《亲爱的,热爱的》,导致李现人气高涨,他原来演的《南方有乔木》的百度搜索指数在《亲爱的,热爱的》播出期间高涨(见下面图3)。因此,我们可以用包含时间的
![]()
来表示标的物偏差随着时间的变化而变化的趋势。标的物本身的特征
![]()
,我们可以认为是稳定的,它代表的是标的物本身的固有属性或者品质,所以不会随着时间而变化。
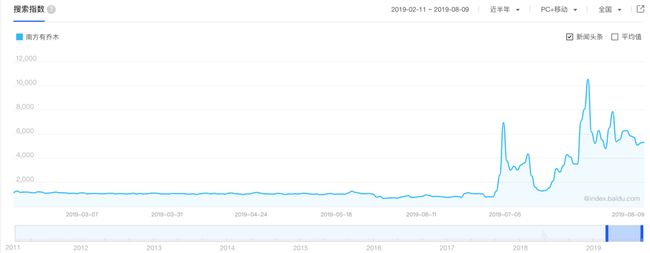
图3:《南方有乔木》在《亲爱的,热爱的》播出期间(2019.07.09播出)百度搜索指数高涨
基于上面的分析,我们最终的预测用户评分的公式整合时间因素后可以表达为
![]()
整合时间因素的模型效果是非常好的,具体可以阅读参考文献8进一步了解。
4.4 整合用户对评分的置信
一般来说,用户对不同标的物的评分不是完全一样可信的,可能会受到外界其他因素的影响,比如某个视频播出后,主播发生了热点事件,肯定会影响用户对该视频的评价,节假日,特殊事件也会影响用户的评价。对于隐式反馈,一般我们用0和1来表示用户是否喜欢该标的物,多少有点绝对,更好的方式是引入一个喜欢的概率/置信度,用户对该标的物操作次数越多、时间越长、付出越大,相应的置信度也越大。因此,我们可以在用户对标的物的评分中增加一个置信度的因子
![]()
,那么最终的优化公式就变为:

4.5 隐式反馈
参考文献5中有对隐式反馈矩阵分解算法的详细介绍,这里对一些核心点做讲解,让读者对隐式反馈有一个比较明确的认知。
用二元变量
![]()
表示用户u对标的物的偏好,
![]()
=1表示用户u对标的物v有兴趣,
![]()
=0表示对标的物v无兴趣。
![]()
是用户u对标的物的隐式反馈,如观看视频的时长,点击次数等等。
![]()
与
![]()
的关系见下面公式。
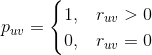
![]()
越大,有理由认为用户对标的物兴趣的置信度越高,比如一个文章读者看了好几篇,肯定比看一遍更能反映出读者对这篇文章的喜爱。具体可以用下面的公式来衡量用户u对标的物v的置信度
![]()
。
![]()
上式中
![]()
代表用户u对标的物v的偏好置信度,
![]()
是一个超参数,论文中作者建议取
![]()
,效果比较好。
基于隐式反馈,求解矩阵分解可以采用如下的公式,
![]()
即是置信度,
![]()
定义如上面的公式。
![]()
上述隐式反馈算法逻辑将用户的操作
![]()
分解为置信度
![]()
和偏好
![]()
能够更好地反映隐式行为的特征,并且从实践上可以大幅提升预测的准确度。同时,通过该分解,利用代数上的一些技巧及该模型的巧妙设计,该算法的时间复杂度与用户操作行为总次数线性相关,不依赖于用户数和标的物数,因此非常容易并行化(读者可以参考文献5了解更多技术实现细节)。
隐式反馈也有一些缺点,不像明确的用户评分,无法很好地表达负向反馈,用户购买一个物品可能是作为礼物送给别人的,他自己可能不喜欢这个物品,用户观看了某个视频,有可能是产品进入视频详情页时是自动起播的,这些行为是包含很多噪音的。
4.6 整合用户和标的物metadata信息
参考文献9给出了一类整合用户和标的物metadata信息的矩阵分解算法,该算法可以很好地处理用户和标的物冷启动问题,在同等条件下会比单独的内容推荐或者矩阵分解算法效果要更好,该算法在全球时尚搜索引擎Lyst真实推荐场景下得到验证。我们在下面简单介绍一下该算法的思路。
![]()
表示所有用户的集合,
![]()
表示所有标的物的集合。
![]()
表示用户特征集合(年龄、性别、收入等),
![]()
表示标的物特征集合(产地、价格等)。
![]()
、
![]()
分别表示用户对标的物的正负反馈集合。
![]()
是用户u的特征表示(每个用户用一系列特征来表示)。同理,
![]()
表示标的物i的特征集合。
对于每个特征
![]()
,我们用
![]()
和
![]()
分别表示用户和标的物嵌入到d维的特征空间的特征向量。
![]()
和
![]()
分别表示用户和标的物的bias项。
那么用户u的隐因子表示,可以用该用户的所有特征的嵌入表示之和,具体来说,可以表示为:
![]()
同理,标的物i的隐因子也可以用该标的物所有特征的嵌入向量的和来表示,具体如下:
![]()
我们分别用

,
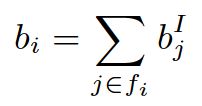
表示用户u和标的物i的bias向量表示。那么,用户u对标的物i的预测评分可以用如下公式表示
![]()
其中,
![]()
可以采用如下的函数形式,
![]()
有了上面这些基础介绍,最终可以用如下的似然函数来定义问题的目标函数,通过最大化似然函数,求得
![]()
、
![]()
、
![]()
、
![]()
这些嵌入的特征向量。
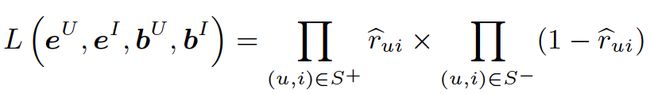
上面利用特征的嵌入向量之和来表示用户或者标的物向量,这就很好地将metadata信息整合到了用户和标的物向量中了,再利用用户向量
![]()
和标的物向量
![]()
的内积加上bias项,通过一个logistic函数来获得用户u对标的物i的偏好概率/得分,从这里的介绍可以看到,该模型很好地将矩阵分解和metadata信息整合到了一个框架之下。感兴趣的读者可以详细阅读原文,对该方法做进一步了解(该文章给出了具体的代码实现,是一个非常好的学习资源,代码见https://github.com/lyst/lightfm)。
五、近实时矩阵分解算法
前面三节对矩阵分解的算法原理、求解方法、拓展进行了详细介绍。前面介绍的方法基本上是适合做批处理的,通过离线训练模型,再为用户推荐。批处理比较适合对时效性要求不太高、消费标的物需要时间比较长的产品,比如电商推荐、长视频推荐等。而有些产品,比如今日头条、快手、网易云音乐,这类产品的标的物要么用户消费时间短要么单位时间内会产生大量标的物,用户很短的时间就听完了一首歌,每天有大量用户上传短时视频到快手平台。针对这类产品,用离线模型不能很好的捕获用户的实时兴趣变化,另外,因为有很多新标的物加入进来,批处理也无法及时将新标的物整合到推荐中,解决这两个问题的方法之一是做近实时的矩阵分解,这样可以实时反映用户兴趣变化及更快地整合新标的物进推荐系统。
那么可以做到对矩阵分解进行实时化改造吗?答案是肯定的,业内有很多这方面的研究成果及工业实践应用,有兴趣的读者可以详细阅读参考文献1、2、14、15、16、17,这6篇文章有对近实时矩阵分解算法的介绍及工程实践经验的案例分享。在本节我们讲解一种实时矩阵分解的技术方案,该方案是腾讯在2016年发的一篇文章上提供的(见参考文献1),并且在腾讯视频上进行了实际检验,效果相当不错,该算法的实现方案简单易懂,非常值得借鉴。下面我们从算法原理和工程实现两个维度来详细讲解该算法的细节。
5.1 算法原理
该实时矩阵分解算法也是采用第四节1中整合偏差项来预测用户u对标的物v的评分,具体预测公式如下:
其中
![]()
是全局均值,
![]()
是标的物偏差,
![]()
是用户偏差,
![]()
是用户标的物交叉项。那么最终的优化问题就转化为:
![]()
我们定义
![]()
基于上面的最优化问题,我们可以得到如下的SGD迭代更新公式:
![]()
![]()
![]()
![]()
该论文采用跟第四节5中隐式反馈中一样的思路,用
![]()
表示用户u对标的物v的偏好置信度,
![]()
的计算公式如下,其中a、b是超参数,
![]()
、
![]()
分别是用户播放视频v的播放时长及视频v总时长。
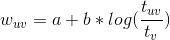
该论文中也尝试过采用
![]()
这类线性公式,但是经过线上验证,上述对数函数的公式效果更好。
作者公司也是做视频的,作者曾经用公式
![]()
来计算视频的得分,其中ratio就是视频播放时长与视频总时长的比例,等价于上面的
![]()
,log是对数函数,上式中乘以10是为了将视频评分统一到0到10之间,并且当ratio=0时,
![]()
=0,当ratio=1时,
![]()
=10。这个公式跟腾讯论文中的公式本质上是一致的。
采用对数函数是有一定的经济学道理在里面的,因为
![]()
是自变量x的递减函数,即导数(斜率)是单调递减函数,当自变量x越大时,函数值增长越慢,因此基于该公式的数学解释可以说明对数函数是满足经济学上的“边际效应递减”这一原则的。针对视频来说,意思就是你在看前面十分钟代表的兴趣程度是大于在最后看十分钟的,这就像你在很饿的时候,吃前面一个馒头的满足感是远大于吃了4个馒头之后再吃一个馒头的满足感的。
用户u对视频v的偏好
![]()
为二元变量,
![]()
=1表示用户喜欢视频v(用户播放、收藏、评论等隐式行为),
![]()
=0表示不喜欢(视频曝光给用户而用户未产生行为或者视频根本没有曝光给用户),具体公式如下:

在近实时训练矩阵分解模型时,只有当
![]()
=1的(隐式)用户行为才更新模型,
![]()
=0时直接将该行为丢弃,而更新时,学习率跟置信度成正比,用户越喜欢该视频,该用户行为对训练模型的影响越大,具体采用如下公式来定义学习率,它是
![]()
的线性函数。
![]()
具体的实时训练采用SGD算法,算法逻辑如下:
算法1:利用SGD实时训练矩阵分解算法
Input:用户操作行为,(用户id,视频id,具体隐式操作行为)三元组
(1) 计算
![]()
,
![]()
(2) if
![]()
=1 then
(3) if u is new, then
(4) Initialize
![]()
(5) end
(6) if v is new, then
(7) Initialize
![]()
(8) end
(9) Compute
![]()
by
![]()
(10) Compute
![]()
by
![]()
(11)
![]()
(12)
![]()
(13)
![]()
(14)
![]()
(15) end
5.2 工程实现
上面讲完了实时训练矩阵分解算法的原理,下面我们来讲讲怎么为用户做推荐,以及在工程上怎么实现实时为用户做推荐。
首先,我们简单描述一下怎么为用户进行推荐。具体为用户生成推荐的流程如下图,一共包含5个步骤。下面分别对每个步骤的作用加以说明。
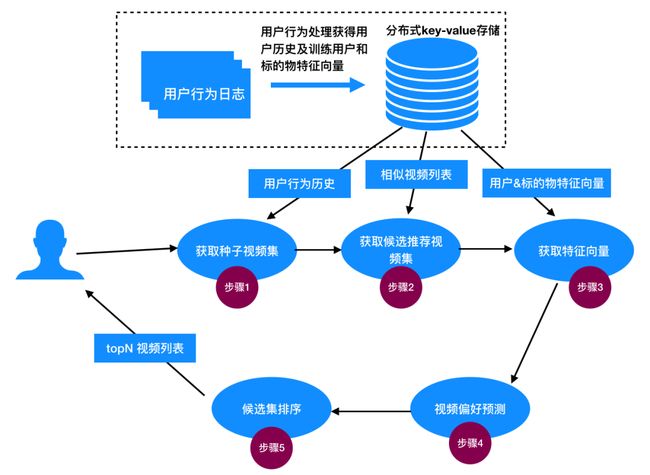
图4:为用户实时生成推荐的流程
步骤1:获取种子视频集
种子是用户最近偏好(有过隐式反馈的)的视频,或者用户历史上有偏好的视频,分别代表了用户的短期和长期兴趣,这些行为直接从用户的隐式反馈行为中获取,只要前端对用户的操作埋点,通过实时日志收集就可以获取。
步骤2:获取候选推荐视频集
一般来说,全量视频是非常巨大的,实时为用户推荐不可能对全部视频分别计算用户对每个视频的偏好预测,因此会选择一个较小的子集作为候选集(这即是召回的过程),我们需要确保该子集很大概率上是用户可能喜欢的,我们先计算出用户对该子集中每个视频的偏好评分,最终将预测评分最高的topN推荐给用户。
该论文通过选取步骤1中种子集的视频的相似视频作为候选集,因为种子视频是用户喜欢的,它的相似视频用户喜欢的概率也相对较大,所以这种方式的召回是有理论依据的。视频相似度会在后面介绍。
步骤3:获取特征向量
从分布式存储中获取用户和候选集视频的特征向量,该向量会用于计算用户对候选集中视频的偏好。特征向量的计算会在后面介绍。
步骤4:预测评分偏好
有了步骤3中的用户和视频特征向量,就可以用公式
来计算该用户对每个候选集中视频的偏好度。
步骤5:候选集排序
步骤4计算出了用户对候选集中每个视频的偏好度,那么按照偏好度降序排列,就可以将topN的视频推荐给用户了。
当用户在前端进行隐式反馈操作时,用户的行为通过实时日志流到实时推荐系统,该系统根据上面5个步骤为每个用户生成推荐结果,用户最近及历史行为、视频相似度、用户特征向量、视频特征向量都存储在高效的分布式存储中(如Redis、HBase、CouchBase等分布式NoSQL),这5个步骤都是非常简单的计算,因此可以在几十毫秒之内为用户生成个性化推荐。最终的推荐结果可以插入(更新)到分布式存储引擎中,当用户在前端请求推荐结果时,推荐web服务器从分布式存储引擎中将该用户的推荐结果取出,并组装成合适的数据格式,返回到前端展示给用户。
用户最近及历史行为、视频相似度、用户特征向量、视频特征向量这些数据是通过另外一个后台实时程序来计算及训练的,跟推荐过程解耦,互不影响。在腾讯的文章中,是利用Storm来实现的,除了用Storm外,用Spark Streaming或者Flink等流式计算引擎都是可以的,只是具体的实现细节不一样。为了不拘泥于一种计算平台,下面结合个人的经验及理解,来讲解怎么生成这些在推荐过程中依赖的数据。这里我们抽象出实现的一般逻辑,具体生成数据的流程见下图,通过4个算子来完成数据生成过程,下面我们分别对这4个算子的功能加以说明。
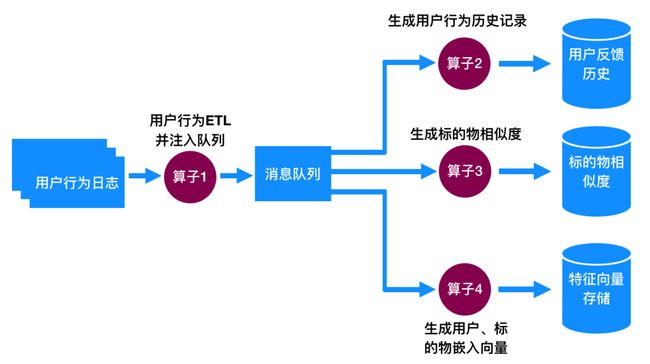
图5:计算个性化推荐依赖的用户播放历史、视频相似度、用户&视频特征向量
算子1:提取用户隐式反馈行为
基于用户在前端对视频的隐式反馈,通过收集用户行为日志,做ETL,将(用户id,视频id,隐式操作,操作时间) 四元组插入消息队列(如kafka),供后面的算子使用。
算子2:生成用户反馈历史并存于分布式key-value存储中
基于消息队列中的用户行为四元组,将用户隐式反馈行为存于分布式存储中。注意,这里可以保留用户最近的操作行为及过去的操作行为,并且也可以给不同时间点的行为不同的权重,以体现用户的兴趣是随着时间衰减的。
算子3:计算视频之间的相似度
这里先说一下计算两个视频相似度的计算公式,腾讯这篇文章是通过如下3类因子的融合来计算两个视频最终的相似性的:
(1) 基于视频特征向量的相似性:
![]()
(2) 基于视频类型的相似性,其中type(i)是视频i的标签类型(如搞笑、时政等)

如果两个视频类型一样,类型相似性为1,否则为0。
(3) 时间衰减因子
![]()
,其中
![]()
是sim(i,j)最近一次更新时间与当前时间之差,
![]()
是控制衰减速率的超参数。
有了上面3类因子,通过如下融合公式来最终得到i和j的相似度,具体如下:
![]()
有了上面计算两个视频相似度的公式,当新事件发生时(即有新用户行为产生),基于该事件中的视频 i,在分布式存储中根据上面的公式结合用户行为历史更新该视频与其他视频构成的视频对的相似度(i:
算子4:生成用户和视频的特性向量
这一步是整个算法的核心,这一步利用算法1中的实时更新逻辑来训练用户和视频的特性向量。具体训练过程是,当用户新的用户行为从管道中流过来时,从分布式存储中将该用户和对应的视频的特征向量取出来,采用算法1中的公式更新特征向量,更新完成后再插入分布式存储中。如果该用户是新用户或者操作的视频是新入库的视频,那么就可以随机初始化用户或视频特征向量,并插入分布式存储中,待后续该用户或者包含该视频新的操作流进来时继续更新。
通过上面的介绍,我们大致知道怎么利用流式计算引擎来做实时的矩阵分解并给用户做个性化推荐了。到此,矩阵分解的离线及实时算法实现方案都讲完了,下面我们来梳理一下矩阵分解算法可行的应用场景。
六、矩阵分解算法的应用场景
前面几节对矩阵分解的算法原理、工程实践及拓展做了详细介绍,我们知道了矩阵分解算法的特性,那么矩阵分解算法可以用于哪些应用场景呢?在本节我们会详细介绍可行的几类应用场景。
6.1 应用于完全个性化推荐场景(完全个性化推荐范式)
完全个性化推荐是为每个用户生成不一样的推荐结果,我们通常指的推荐一般是指完全个性化推荐,上面第一、第二节介绍的为每个用户生成推荐即是完全个性化推荐。下图就是电视猫首页的兴趣推荐,为每个用户推荐感兴趣的长视频,是完全个性化的,其中也采用了矩阵分解算法。
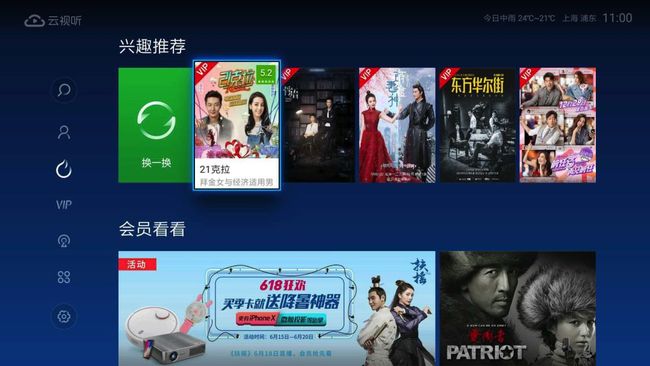
图6:电视猫首页兴趣推荐:完全个性化推荐,每个用户推荐不一样的视频集
6.2 应用于标的物关联的物场景(标的物关联标的物范式)
标的物关联标的物推荐就是为每个标的物关联一组相似/相关的标的物作为推荐。前面我们没有直接讲到怎么做标的物关联推荐。但是,如果我们得到了每个标的物的特征向量(通过矩阵分解,获得的标的物嵌入k维特征空间的向量),那么我们可以通过向量的cosine余弦相似度来获得与某个标的物最相似的K个标的物作为关联推荐结果。有了标的物特征向量后具体怎么工程实现,计算topK相似度,读者可以参考《协同过滤推荐算法》第三节1中计算topK相似度的方法来实现,原理是完全一样的,这里不再赘述。
下图是电视猫视频的相似推荐,它就是一种关联推荐,关联推荐大量用于电商、视频、新闻等产品中。
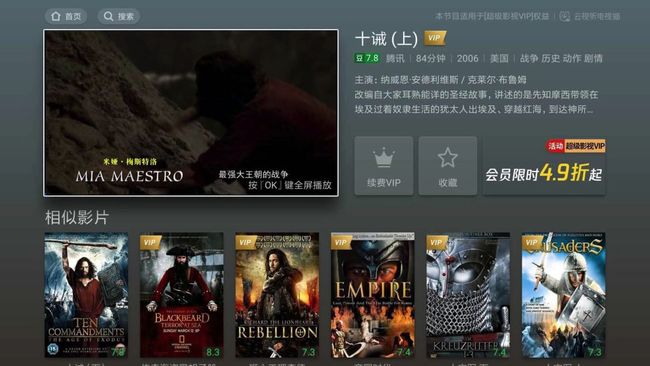
图7:电视猫详情页相似影片:视频关联视频的推荐,可以基于标的物特征向量来计算关联推荐
6.3 用于用户及标的物聚类
通过矩阵分解我们获得了用户及标的物的k维特征向量,有了特征向量,我们就可以对用户和标的物聚类了。
对用户聚类后,我们可以将同一类的其他用户操作过的标的物推荐给该用户,这也是一种可行的推荐策略。
对标的物聚类后,我们可以将同一类的标的物作为该标的物的关联推荐。另外,聚类好的标的物可以作为专题/专辑等供编辑、运营人员用于营销推广。
6.4 应用于群组个性化场景(群组个性化推荐范式)
在3中我们讲了用户聚类,当用户聚类后,我们可以对同一类用户提供相同的推荐服务,这时就是群组个性化推荐。群组个性化推荐相当于将有相同兴趣偏好的个体组成一个等价类,统一为他们提供推荐,它是介于完全个性化推荐(每个人推荐的都不一样)和完全非个性化推荐(所有人推荐的都一样)之间的一类推荐形态。
我们对电视猫的站点树内容做的个性化重排序就是采用的基于矩阵分解获取用户特征向量再对用户聚类的技术。首先对用户聚类,同一类的用户通过特征向量平均获得该类的中心特征向量,该中心特征向量代表了该群组的特征,我们再用该向量跟标的物特征向量求cosine余弦,最终获得该中心向量跟所有标的物特征向量的相似度。在站点树重排中,对站点树的所有节目,可以获得中心向量与站点树节目特征向量的相似度,按照该相似度降序排列就获得了该群组的重排序结果。下图就是电视猫电视剧频道“战争风云”站点树重排序的产品形态(每个用户看到的战争风云总节目量是一样的,只是排序不一样,会按照自己的兴趣(其实是自己所在群组的平均兴趣)将喜欢的排在前面)。

图8:电视猫站点树个性化排序:基于群组个性化为用户做推荐
除了上面的应用场景外,由矩阵分解获得的用户和标的物特征向量,可以作为其他模型(如深度学习模型)的特征输入,进一步训练更复杂的模型。
七、矩阵分解算法的优缺点
通过前面的介绍,我们知道矩阵分解算法原理相对简单,也易于分布式实现,并且可以用于很多真实业务场景和产品形态,那么在本节我们来总结一下矩阵分解算法的优缺点,方便大家在实际应用矩阵分解算法时更好地理解和运用。
7.1 优点
矩阵分解算法作为一类特殊的协同过滤算法,具备协同过滤算法的所有优点,具体表现在:
(1) 不依赖用户和标的物的其他信息,只需要用户行为就可以为用户做推荐
矩阵分解算法也是一类协同过滤算法,它只需要用户行为就可以为用户生成推荐结果,而不需要用户或者标的物的其他信息,而这类其他信息往往是半结构化或者非结构化的信息,不易处理,有时也较难获得。
矩阵分解是领域无关的一类算法,因此,该优点可以让矩阵分解算法基本可以应用于所有推荐场景中,这也是矩阵分解算法在工业界大受欢迎的重要原因。
(2) 推荐精准度不错
矩阵分解算法是Netflix推荐大赛中获奖算法中非常重要的一类算法,准确度是得到业界一致认可和验证的,我们公司推荐业务中也大量利用矩阵分解算法,效果也是非常不错的。
(3) 可以为用户推荐惊喜的标的物
协同过滤算法利用群体的智慧来为用户推荐,具备为用户推荐差异化、有惊喜度的标的物的能力,矩阵分解算法作为协同过滤算法中一类基于隐因子的算法,当然也具备这个优点,甚至比user-based和item-based协同过滤算法有更好的效果。
(4) 易于并行化处理
通过第三节ALS求解我们可以知道矩阵分解是非常容易并行化的,Spark MLlib中就是采用ALS算法分布式进行矩阵分解的。
7.2 缺点
上面讲了这么多矩阵分解算法的优点,除了这些优点外,矩阵分解在下面这两点上是有缺陷的,需要采用其他的方式来弥补或者避免。
(1) 存在冷启动问题
当某个用户的用户行为很少时,我们基本无法利用矩阵分解获得该用户比较精确的特征向量表示,因此无法为该用户生成推荐结果。这时可以借助内容推荐算法来为该用户生成推荐。
对于新入库的标的物也一样,可以采用人工编排的方式将标的物做适当的曝光获得更多用户对标的物的操作行为,从而方便算法将该标的物推荐出去。
参考文献9中提供了一种解决矩阵分解冷启动问题的有效算法lightFM,通过将metadata信息整合到矩阵分解中,可以有效解决冷启动问题,对于操作行为不多的用户以及新上线不久还未收集到更多用户行为的标的物都有比较好的推荐效果。该论文的lightFM算法在github上有相应的python代码实现(参见https://github.com/lyst/lightfm),可以作为很好的学习材料。
(2) 可解释性不强
矩阵分解算法通过矩阵分解获得用户和标的物的(嵌入)特征表示,这些特征是隐式的,无法用现实中的显示特征进行解释,因此利用矩阵分解算法做出的推荐,我们无法对推荐结果进行解释,只能通过离线或者在线评估来评价算法的效果。不像user-based和item-based协同过滤算法基于非常朴素的”物以类聚、人以群分“的思想,可以非常容易做解释。但也不是绝对的,其中参考文献5中的实现方法就提供了一个为矩阵分解做推荐解释的非常有建设性的思路。
总结
本文对矩阵分解算法原理、工程实践、应用场景、优缺点等进行了比较全面的总结。矩阵分解算法是真正意义上的基于模型的协同过滤算法。通过将用户和标的物嵌入到低维隐式特征空间,获得用户和标的物的特征向量表示,再通过向量的内积来量化用户对标的物的兴趣偏好,思路非常简单、清晰,也易于工程实现,效果也相当不错,所以在工业界有非常广泛的应用。矩阵分解算法算是开启了嵌入类方法的先河,后面非常有名的Word2Vec也是嵌入方法的代表,深度学习兴起后,各类嵌入方法在大量的业务场景中得到了大规模的应用。
参考文献
-
Real-time Video Recommendation Exploration
-
Real-Time Top-N Recommendation in Social Streams
-
Online-updating regularized kernel matrix factorization models for large-scale recommender systems
-
Factorization Meets the Item Embedding- Regularizing Matrix Factorization with Item Co-occurrence
-
Collaborative Filtering for Implicit Feedback Datasets
-
Large-Scale Parallel Collaborative Filtering for the Netflix Prize
-
Content-boosted Matrix Factorization Techniques for Recommender Systems
-
Matrix Factorization Techniques for Recommender Systems
-
Metadata Embeddings for User and Item Cold-start Recommendations
-
Neural Word Embedding as Implicit Matrix Factorization
-
Collaborative Filtering with Temporal Dynamics
-
Factorization Meets the Neighborhood: A Multifaceted Collaborative Filtering Model
-
Scalable Collaborative Filtering with Jointly Derived Neighborhood Interpolation Weights
-
Online collaborative flitering
-
Online-updating regularized kernel matrix factorization models for large-scale recommender systems
-
Fast incremental matrix factorization for recommendation with positive-only feedback
-
Online personalized recommendation based on streaming implicit user feedbac
关注「数据与智能」,支持强哥,优质好文持续更新中……✍