Python-20分钟入门torch
目录
回归问题
数据生成(包含数据集划分)
梯度下降
步骤一:计算损失
步骤二:计算梯度
步骤三:更新参数
步骤四:重复上述步骤(针对不同情况的每个epoch的参数更新量N/一次训练传入的数据集大小)
线性回归的Numpy实现(手动计算梯度+手动更新参数+手动定义损失函数)
PyTorch
Tensor(张量)
数据载入、设备和CUDA
创建参数
Autograd(自动计算梯度包)
动态计算图
Optimizer(自动更新参数)
损失(自动调用损失函数)
模型定义(init定义操作+foward计算输出)
嵌套模型
序贯模型
单步训练函数(fullbatch)
Dataset(元组列表:特征,标签;方便进行数据划分dataloader-minibatch;在CPU上的处理)
DataLoader(训练集/验证集数据切片-minibatch;元组:特征,标签)
验证(设定验证模式;不需要计算梯度)
完整的代码实现
转载
本文翻译自towardsdatascience上非常火爆的PyTorch介绍
https://towardsdatascience.com/understanding-pytorch-with-an-example-a-step-by-step-tutorial-81fc5f8c4e8etowardsdatascience.com
作者同时也正在出书
Deep Learning with PyTorch Step-by-Step: A Beginner’s Guideleanpub.com
希望能帮助到有需要的人。
本篇文章主要涉及以下方面内容:
- 一个简单的回归问题
- 梯度下降
- 线性回归的Numpy实现
- PyTorch
- Autograd
- Dynamic Computation Graph 动态计算图
- Optimizer 优化器
- Loss 损失
- Model 模型
- Dataset 数据集
- DataLoader 数据加载器
- Evaluation 评估
回归问题
考虑一个只有一个特征 x 的回归问题

数据生成(包含数据集划分)
假设模型参数的真实值为 a=1,b=2 ,噪声为高斯白噪声,生成 100个样本数据
np.random.seed(42)
x = np.random.rand(100,1)
y = 1 + 2*x + .1*np.random.rand(100,1)将数据集分为训练集和验证集,将次序打乱并将前 80 个样本用于训练
# 打乱次序
idx = np.arange(100)
np.random.shuffle(idx)
# 前80个样本用于训练
train_idx = idx[:80]
val_idx = idx[80:]
# 创建训练集和验证集
x_train, y_train = x[train_idx], y[train_idx]
x_val, y_val = x[val_idx], y[val_idx]接下来我们来看看如果利用梯度下降法来学习模型参数。
梯度下降
步骤一:计算损失
需要注意:如果我们将所有( N个)训练数据都用于计算损失,则是批(batch)梯度下降;如果只用一个点来计算损失,则是随机梯度下降(SGD);如果数据点介于 1 到N 则是最小(mini-batch)梯度下降。
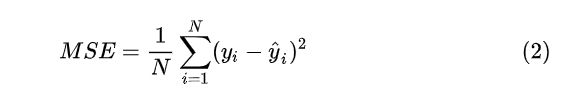
带入模型后

步骤二:计算梯度
一个梯度就是关于一个参数的偏导数,因为我们这里有两个参数 a和 b,因此需要计算两个偏导数。这里需要利用到链式法则
- 其中x_i和y_i就是真实的x_train和y_train值
- x_hat和y_ha就是模型计算预测的值

步骤三:更新参数
我们利用梯度来更新参数,由于我们要最小化损失,所以参数的更新方向需要往负梯度方向进行。

其中 n 为学习率。
步骤四:重复上述步骤(针对不同情况的每个epoch的参数更新量N/一次训练传入的数据集大小)
采用更新后的参数并回到步骤一重复以上过程。
- 一个epoch完成指的是所有样本点都已经被用来计算损失了。比如批梯度下降,一次参数的更新就是一个epoch;
- 对于随机梯度下降,一个epoch对应 N次参数更新;
- 而最小批梯度下降,一个epoch对应 N/n 次更新。
线性回归的Numpy实现(手动计算梯度+手动更新参数+手动定义损失函数)
首先随机初始化参数 a,b
np.random.seed(42)
a = np.random.randn(1)
b = np.random.randn(1)设置学习率和epoch数目
lr = 1e-1
n_epochs = 1000 # 全部数据需要用来训练几次在每个epoch中执行
for epoch in range(n_epochs):
# 计算模型的预测
yhat = a + b * x_train
# 计算模型的预测误差
error = (y_train - yhat)
# 计算损失(MSE),对应公式(3)
loss = (error ** 2).mean()
# 计算梯度,对应公式(4)
a_grad = -2 * error.mean()
b_grad = -2 * (x_train * error).mean()
# 更新模型参数,对应公式(5)
a = a - lr * a_grad
b = b - lr * b_grad我们也可以调用 Scikit-Learn 的线性回归来拟合模型然后比较我们梯度下降得到的参数和 Scikit-Learn 得到的是否一致
- 将真实值x_i和y_i传入即可
- 也就是传入x_train, y_train
from sklearn.linear_model import LinearRegression
linr = LinearRegression()
linr.fit(x_train, y_train)
print(a, b)
print(linr.intercept_, linr.coef_[0])是时候进入PyTorch了!
PyTorch
首先我们要熟悉一些基础的概念,比如说
Tensor(张量)
张量其实就是任意维度的矩阵,比如标量就是零维张量,向量就是一维张量,矩阵就是二维张量。
数据载入、设备和CUDA
我们可以直接将numpy中的array转化为张量,并定义为是GPU中的张量,还是CPU中的张量(这里的设备指的是CPU或GPU)
import torch
import torch.optim as optim
import torch.nn as nn
from torchviz import make_dot
# 如果有GPU则用GPU,没有则用CPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 将Numpy的array转化为tensor并指定设备
x_train_tensor = torch.from_numpy(x_train).float().to(device)
y_train_tensor = torch.from_numpy(y_train).float().to(device)
# 观察它们类别的不同
print(type(x_train), type(x_train_tensor), x_train_tensor.type())可以看到第一个的类别是numpy.ndarray,第二个的类别是torch.Tensor。
同样也可以将张量转化为Numpy中的array,使用指令x_train_tensor.numpy()即可,需要注意的是如果是GPU中的张量需要先(用"cpu()")转为CPU型张量再进一步转化。
创建参数
了解张量后我们需要将需要学习的参数创建成张量的形式,并声明是否需要计算梯度,同时也可以声明设备。
# 随机初始化参数,并声明需要计算梯度:REQUIRES_GRAD = TRUE,tensor的位置。
torch.manual_seed(42)
a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
print(a, b)Autograd(自动计算梯度包)
Autograd 是 PyTorch 的自动微分包,可以帮我们自动计算出所有梯度。
- 使用 bachward() 指令告诉PyTorch计算梯度,由于我们计算梯度都是从损失函数计算的,因此我们需要在对应的变量调用backward()指令,比如:loss.backward()
- 通过张量的 grad 属性可以知道梯度的具体数值。
- 由于梯度的计算是累积的,每次更新完参数后我们需要将梯度清零:zero_()
- 由于 PyTorch默认 使用的是动态图,如果要对梯度进行常规 Python 操作,需要使用:torch.no_grad()
lr = 1e-1
n_epochs = 1000
torch.manual_seed(42)
a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
for epoch in range(n_epochs):
yhat = a + b * x_train_tensor
error = y_train_tensor - yhat
loss = (error ** 2).mean()
# 不需要再手动计算梯度了
# a_grad = -2 * error.mean()
# b_grad = -2 * (x_tensor * error).mean()
# 直接在loss后调用计算梯度指令
loss.backward()
# 计算出来的梯度
print(a.grad)
print(b.grad)
# 参数的更新
# 需要声明不需要涉及动态图的运算
with torch.no_grad():
a -= lr * a.grad
b -= lr * b.grad
# 将梯度清空
a.grad.zero_()
b.grad.zero_()
print(a, b)动态计算图
PyTorchViz 工具包的 make_dot(variable) 方法能够让我们看到相应变量的计算图。
torch.manual_seed(42)
a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
yhat = a + b * x_train_tensor
error = y_train_tensor - yhat
loss = (error ** 2).mean()如果我们调用 make_dot(yhat),可以看到

其中
- 蓝色方框表示的是我们需要计算梯度的那些参数
- 灰色方框表示的是 Python 涉及梯度计算的操作
- 绿色方框表示的和灰色方框一样,并声明了梯度计算的起点(backward()作用的对象)
- 由于我们不对 x 计算梯度,因此并没有和 x对应的框。no gradients, no graph.
动态图的一个优点是我们可以根据自己的需求设计梯度的计算方向,比如
yhat = a + b * x_train_tensor
error = y_train_tensor - yhat
loss = (error ** 2).mean()
# 有两个分叉
if loss > 0:
yhat2 = b * x_train_tensor
error2 = y_train_tensor - yhat2
loss += error2.mean()对应的计算图为

Optimizer(自动更新参数)
现在你能够利用 PyTorch 自动计算出来梯度并手动更新参数了,但是如果有一堆的参数,我们可以利用 PyTorch 的优化器,比如 SGD 或者 Adam,来更加高效地更新参数。
- 定义随机梯度下降优化器用来优化参数
- 使用 step() 更新参数
- 不需要逐个清零梯度,只需要调用优化器的 zero_grad()
torch.manual_seed(42)
a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
print(a, b)
lr = 1e-1
n_epochs = 1000
# 定义随机梯度下降优化器用来优化参数
optimizer = optim.SGD([a, b], lr=lr)
for epoch in range(n_epochs):
yhat = a + b * x_train_tensor
error = y_train_tensor - yhat
loss = (error ** 2).mean()
loss.backward()
# 不需要再手动更新了
# with torch.no_grad():
# a -= lr * a.grad
# b -= lr * b.grad
optimizer.step()
# 不需要再清零梯度
# a.grad.zero_()
# b.grad.zero_()
optimizer.zero_grad()
print(a, b)损失(自动调用损失函数)
PyTorch覆盖了大部分我们可能用到的损失函数,对于回归问题我们采用的是MSE,定义了损失函数我们就没必要自己计算损失了。
- 直接调用torch自带的MSE损失函数
torch.manual_seed(42)
a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
print(a, b)
lr = 1e-1
n_epochs = 1000
# 定义MSE损失函数
loss_fn = nn.MSELoss(reduction='mean')
optimizer = optim.SGD([a, b], lr=lr)
for epoch in range(n_epochs):
yhat = a + b * x_train_tensor
# 不需要自己计算损失了
# error = y_tensor - yhat
# loss = (error ** 2).mean()
loss = loss_fn(y_train_tensor, yhat)
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(a, b)接下来我们再看看如何利用模型进行预测。
模型定义(init定义操作+foward计算输出)
在 PyTorch 中模型用 python 中的类(class)表示
最基本的方法是
- __init__(self):它定义了模型的组成部分,在回归例子里是两个参数a,b
- 在模型里需要将参数包装为 nn.Parameter
- forward(self, x): 它根据输入x 计算输出
class ManualLinearRegression(nn.Module):
def __init__(self):
super().__init__()
# 在模型里我们将参数包装为 nn.Parameter
self.a = nn.Parameter(torch.randn(1, requires_grad=True, dtype=torch.float))
self.b = nn.Parameter(torch.randn(1, requires_grad=True, dtype=torch.float))
def forward(self, x):
# 计算预测
return self.a + self.b * x注意:我们需要将模型和数据放在同一设备中(GPU或CPU)。
torch.manual_seed(42)
# 创建模型并指定设备
model = ManualLinearRegression().to(device)
# 使用 state_dict 看参数
print(model.state_dict())
lr = 1e-1
n_epochs = 1000
loss_fn = nn.MSELoss(reduction='mean')
optimizer = optim.SGD(model.parameters(), lr=lr)
for epoch in range(n_epochs):
# 将模型设置为训练模式!
model.train()
# 不需要人工进行预测
# yhat = a + b * x_tensor
yhat = model(x_train_tensor)
loss = loss_fn(y_train_tensor, yhat)
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(model.state_dict())注意:上面的 model.train() 并不是用来训练模型的,它只是将模型设置为训练模式。因为有的模型在训练和评价阶段采用的机制不一样,比如训练过程有 Dropout 操作。
嵌套模型
上面的模型中我们自己定义了两个参数作为线性回归的参数,我们也可以使用 PyTorch 的 Linear 模型作为我们模型的属性。在 __init__ 方法中我们需要增加一个属性来表示线性模型
class LayerLinearRegression(nn.Module):
def __init__(self):
super().__init__()
# 创建一个单入单出的线性层
self.linear = nn.Linear(1, 1)
def forward(self, x):
# 计算输出时只需要调用这一层,不需要用forward
return self.linear(x)序贯模型
对于一些深度模型,一层的输出作为下一层的输入,我们可以采用序贯 Sequential 模型,比如线性模型可以看作只有一个模型组成的序贯模型
model = nn.Sequential(nn.Linear(1, 1)).to(device)单步训练函数(fullbatch)
目前为止我们定义了优化器、损失函数和模型。可以将它们整合成一个函数进行一步训练。
- 一个函数 make_train_step 的输入是优化器、损失函数和模型,输出是另一个函数 train_step
- 函数 train_step 用于单步训练:输入是数据样本,输出是损失。
def make_train_step(model, loss_fn, optimizer):
# 定义单步训练函数
def train_step(x, y):
# 将模型设置为训练模式
model.train()
# 进行预测
yhat = model(x)
# 计算损失
loss = loss_fn(y, yhat)
# 计算梯度
loss.backward()
# 更新参数并清零梯度
optimizer.step()
optimizer.zero_grad()
# 返回损失
return loss.item()
# 返回单步训练函数
return train_step
# 根据模型、损失函数和优化器创建单步训练函数
train_step = make_train_step(model, loss_fn, optimizer)
losses = []
# For each epoch...
for epoch in range(n_epochs):
# 单步训练并返回损失
loss = train_step(x_train_tensor, y_train_tensor)
losses.append(loss)
# 检验模型参数
print(model.state_dict())到目前为止我们使用的数据是从 Numpy 的数组转化过来的张量,其实在 PyTorch 中我们可以使用 Dataset 这个类。
Dataset(元组列表:特征,标签;方便进行数据划分dataloader-minibatch;在CPU上的处理)
可以将其视为一种 Python 元组列表,每个元组对应一个点(特征,标签)。最基本的方法是
__init__(self): 它包含构建元组列表所需的任何参数-它可能是将被加载和处理的CSV文件的名称;它可能是两个张量,一个用于特征,另一个用于标签;或其他任何东西,取决于待解决的任务。__get_item__(self, index):它允许数据集索引__len__(self):返回数据集的大小
from torch.utils.data import Dataset, TensorDataset
class CustomDataset(Dataset):
def __init__(self, x_tensor, y_tensor):
self.x = x_tensor
self.y = y_tensor
def __getitem__(self, index):
return (self.x[index], self.y[index])
def __len__(self):
return len(self.x)
# 这里的张量是在CPU中的,不占用GPU
x_train_tensor = torch.from_numpy(x_train).float()
y_train_tensor = torch.from_numpy(y_train).float()
train_data = CustomDataset(x_train_tensor, y_train_tensor)
print(train_data[0])
# 如果数据集里只是一些张量可以直接使用自带的TensorDataset类
train_data = TensorDataset(x_train_tensor, y_train_tensor)
print(train_data[0])使用 Dataset 的好处在于它可以使用 数据加载器 DataLoader,从而对数据进行划分训练。
DataLoader(训练集/验证集数据切片-minibatch;元组:特征,标签)
目前为止我们单步训练使用的是全部数据,即批梯度下降。当数据样本很多时通常采用小批次梯度下降,也就是单步训练只采用部分数据。使用 DataLoader 能够帮我们对数据进行切片!
- 函数的输入为:训练数据集dataset、批次数量batch_size、是否打乱次序
from torch.utils.data import DataLoader
# 函数的输入为:训练数据集、批次数量、是否打乱次序
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)- 如果想要得到一个批次的数据可以使用 next(iter(train_loader)),它会返回两个张量,一个是特征、一个是标签。
- 多了一个for循环来循环for x_batch, y_batch in train_loader: #注意将x_batch, y_batch也放到设备中
使用 DataLoader 后我们的代码变为
losses = []
train_step = make_train_step(model, loss_fn, optimizer)
for epoch in range(n_epochs):
for x_batch, y_batch in train_loader:
# 由于数据是存在CPU的,因此我们需要将训练数据送到模型所在位置
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
loss = train_step(x_batch, y_batch)
losses.append(loss)
print(model.state_dict())注意:使用 DataLoader 后有两点不同的地方,
- 一是多了个内部循环每次使用一个批次数据进行训练,
- 二是每次仅将一个批次的数据送入设备(降低GPU的内存占用且进一步可以使用多卡训练)。
同理我们需要对验证数据建立一个 DataLoader
from torch.utils.data.dataset import random_split
x_tensor = torch.from_numpy(x).float()
y_tensor = torch.from_numpy(y).float()
dataset = TensorDataset(x_tensor, y_tensor)
# 数据集划分
train_dataset, val_dataset = random_split(dataset, [80, 20])
train_loader = DataLoader(dataset=train_dataset, batch_size=16)
val_loader = DataLoader(dataset=val_dataset, batch_size=20)验证(设定验证模式;不需要计算梯度)
接下来我们来看看验证部分,有两点需要注意的:
- 验证时不涉及梯度的计算
- 需要将模型设置为验证模式
losses = []
val_losses = []
train_step = make_train_step(model, loss_fn, optimizer)
for epoch in range(n_epochs):
for x_batch, y_batch in train_loader:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
loss = train_step(x_batch, y_batch)
losses.append(loss)
with torch.no_grad():
for x_val, y_val in val_loader:
x_val = x_val.to(device)
y_val = y_val.to(device)
# 验证模式
model.eval()
yhat = model(x_val)
val_loss = loss_fn(y_val, yhat)
val_losses.append(val_loss.item())
print(model.state_dict())完整的代码实现
import numpy as np
import torch
import torch.optim as optim
import torch.nn as nn
from torchviz import make_dot
from torch.utils.data import Dataset, TensorDataset, DataLoader
from torch.utils.data.dataset import random_split
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 数据的生成
np.random.seed(42)
x = np.random.rand(100, 1)
true_a, true_b = 1, 2
y = true_a + true_b*x + 0.1*np.random.randn(100, 1)
# 将Numpy数据转为张量
x_tensor = torch.from_numpy(x).float()
y_tensor = torch.from_numpy(y).float()
# 自定义Dataset
class CustomDataset(Dataset):
def __init__(self, x_tensor, y_tensor):
self.x = x_tensor
self.y = y_tensor
def __getitem__(self, index):
return (self.x[index], self.y[index])
def __len__(self):
return len(self.x)
# 创建 Dataset
dataset = TensorDataset(x_tensor, y_tensor) # dataset = CustomDataset(x_tensor, y_tensor)
# 划分训练数据和测试数据8:2
train_dataset, val_dataset = random_split(dataset, [80, 20])
# 创建数据加载器
train_loader = DataLoader(dataset=train_dataset, batch_size=16)
val_loader = DataLoader(dataset=val_dataset, batch_size=20)
# 定义模型
class ManualLinearRegression(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
# 定义单步训练函数
def make_train_step(model, loss_fn, optimizer):
def train_step(x, y):
model.train() #训练模式
yhat = model(x) #计算输出
loss = loss_fn(y, yhat) #计算损失
loss.backward() #计算梯度
optimizer.step() #更新参数
optimizer.zero_grad() #清零梯度
return loss.item()
return train_step
# Estimate a and b
torch.manual_seed(42)
# 模型、损失函数、优化器
model = ManualLinearRegression().to(device) # model = nn.Sequential(nn.Linear(1, 1)).to(device)
loss_fn = nn.MSELoss(reduction='mean')
optimizer = optim.SGD(model.parameters(), lr=1e-1)
# 创建单步训练函数
train_step = make_train_step(model, loss_fn, optimizer)
n_epochs = 100
training_losses = []
validation_losses = []
print(model.state_dict())
for epoch in range(n_epochs):
batch_losses = []
for x_batch, y_batch in train_loader:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
loss = train_step(x_batch, y_batch)
batch_losses.append(loss)
training_loss = np.mean(batch_losses)
training_losses.append(training_loss)
with torch.no_grad():
val_losses = []
for x_val, y_val in val_loader:
x_val = x_val.to(device)
y_val = y_val.to(device)
model.eval()
yhat = model(x_val)
val_loss = loss_fn(y_val, yhat).item()
val_losses.append(val_loss)
validation_loss = np.mean(val_losses)
validation_losses.append(validation_loss)
print(f"[{epoch+1}] Training loss: {training_loss:.3f}\t Validation loss: {validation_loss:.3f}")
print(model.state_dict())Python数据处理入门教程!
开源项目地址:https://github.com/datawhalechina/powerful-numpy