Apollo 7.0障碍物感知模型原型,SMOKE 单目3D目标检测,代码开源。
作者:黎国溥 CSDN博客专家,华为云-云享专家
首发:公众号【3D视觉开发者社区】
前言
SMOKE是一个one-stage的单目视觉障碍物检测模型,它认为2D检测对于单目3D检测任务来说是冗余的,且会引入噪声影响3D检测性能,所以直接用关键点预测和3D框回归的方式。
最近发布的百度Apollo 7.0中,摄像头障碍物感知也是基于这个模型改进的;它能实现实时推理,代码开源,值得学习一下。

论文名称:SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation
论文地址:https://arxiv.org/pdf/2002.10111.pdf
开源地址:https://github.com/lzccccc/SMOKE
环境搭建:https://guo-pu.blog.csdn.net/article/details/122243245
SMOKE模型的3D目标检测和俯视图效果如图1.1所示。

图1.1 SMOKE模型效果
一、论文动机
1.1 对于已有的两阶段单目3D目标检测框架:
a、基于2D目标检测网络生成目标的2D候选区域;
b、针对获取到的目标的“2D patch特征” 预测目标位姿;
1.2 SMOKE
a、论文认为其中的2D检测对于单目3D检测任务来说是冗余的,且会引入噪声影响3D检测性能。
b、若已知相机内参和目标的3D属性,反过来是可以推测出目标的2D检测框的;(即:基于3D box在图像平面上的投影点求取满足条件的最小外接矩形。)
本论文抛弃了2D候选区域生成这一步,提出了基于关键点预测的一阶段单目3D检测框架SMOKE(Single-Stage Monocular 3D Object Detection via Keypoint Estimation),直接预测目标的3D属性信息。
二、单目3D目标检测
针对单张RGB图像,宽度 W、高度 H、通道数 3;
给出其中每个目标的类别标签 C、3D边界框 B;其中B 可以用7个参数表示(h、w、l、x、y、z、θ),如图2.1 所示。需要加水相机的内参矩阵已知。
- (h、w、l) 表示目标的高度、宽度和长度;
- (x、y、z) 表示目标中心点在相机坐标系下的坐标;
- θ 表示目标的航向角。

图2.1 描述3D目标检测框
三、SMOKE 整体框架
输入图像经过DLA-34 Backbone进行特征提取;网络主要包含两个分支:关键点预测分支和3D边界框回归分支,DLA框架结构如图3.1 所示。
SMOKE网络采用关键点预测分支来定位前景目标,关键点分支输出的分辨率为 ( H 4 , W 4 , C ) \left( \frac{H}{4}, \frac{W}{4},C\right) (4H,4W,C),表示数据集中前景目标的类别个数。3D边界框回归分支输出的分辨率为 ( H 4 , W 4 , 8 ) \left( \frac{H}{4}, \frac{W}{4},8\right) (4H,4W,8),表示描述3D边界框的参数有8个。
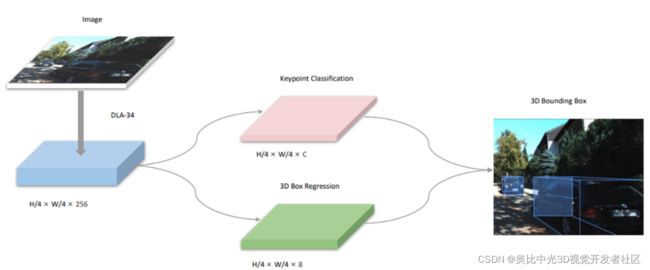
图3.1 SMOKE框架结构
四、SMOKE的Backbone(主干网络)
主干网络采用带有DCN(Deformable Convolution Network)以及使用GN(GroupNorm)标准化的DLA-34神经网络提取特征,网络输出分辨率为输入分辨率的四分之一。
4.1 DLA
DLA-34是DLA结构中的其中一种,先介绍一下DLA(Deep Layer Aggregation),CVPR 2018的一篇论文,它是一种网络特征融合方法。
DLA框架结构如图4.1所示。通过了迭代深度聚合和分层深度聚合,最后为了降低计算量简化了模型。目的是更好地融合空间特征和语义信息,即融合浅层的底层信息和深层的语义信息。
论文地址:https://arxiv.org/pdf/1707.06484.pdf
开源代码:https://github.com/ucbdrive/dla
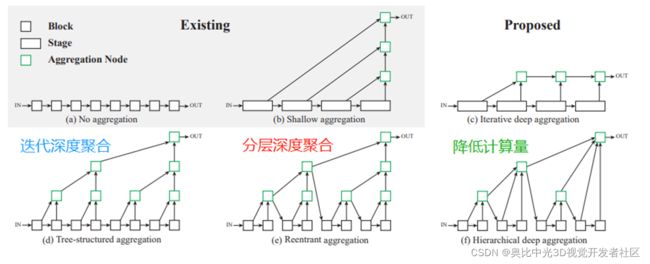
图4.1 DLA框架结构
DLA-34
论文中采用DLA-34作为主干网络进行特征提取,以便对不同层之间的特征进行聚合。
网络中主要做了两点改动如下:
1、将所有的分层聚合连接替换为可变形卷积;
2、将所有的BN层用GN(GroupNorm)替换,因为GN对batch size大小不敏感,且对训练噪声更鲁棒,作者在实验部分也对这一点进行了验证。
4.2 可变形卷积(改进点1)
Deformable Convolutional ,可变形卷积( ICCV 2017)
论文地址:https://arxiv.org/pdf/1703.06211.pdf
开源地址:https://github.com/msracver/Deformable-ConvNets
如图4.2所示,可变形卷积指卷积核在每一个元素上额外增加了一个参数方向参数,这样卷积核就能在训练过程中扩展到很大的范围。
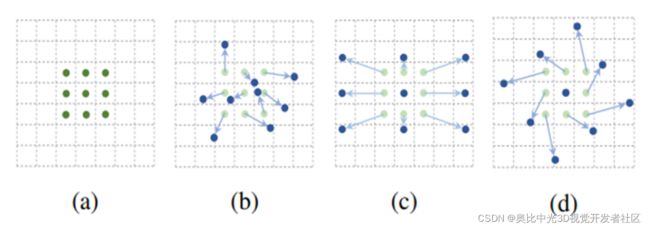
图4.2 描述传统卷积和可变形卷积
(a)是传统的标准卷积核,尺寸为3x3(图中绿色的点);
(b)可变形卷积,通过在图(a)的基础上给每个卷积核的参数添加一个方向向量(图b中的浅绿色箭头),使的卷积核可以变为任意形状;
(c)和(d)是可变形卷积的特殊形式。
传统的卷积核通常是固定尺寸、固定大小的(例如3x3,5x5),它对于未知的变化适应性差,泛化能力不强。
例如:同一CNN层的激活单元的感受野尺寸都相同,但是不同的位置可能对应有不同尺度的物体,这些层需要能够自动调整尺度或者感受野的方法。

图4.3 传统卷积和可变形卷积
可变形卷积的卷积核可以根据实际情况调整本身的形状,更好的提取输入的特征。
即:卷积核的形状是可变的,也就是感受野可以变化,但注意感受野的元素是“不变”的。
4.3 Group Normbalization(改进点2)
组归一化(Group Normbalization,GN)是一种新的深度学习归一化方式,它解决了BN式归一化对batch size依赖的影响,对训练噪声更鲁棒。
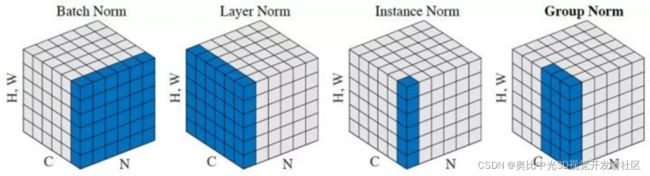
图4.4 几种归一化方式的对比
•BatchNorm:batch方向做归一化,算NHW的均值
•LayerNorm:channel方向做归一化,算CHW的均值
•InstanceNorm:一个channel内做归一化,算H*W的均值
•GroupNorm:将channel方向分group,然后每个group内做归一化,算(C/G)HW均值
五、SMOKE的 3D检测网络
此部分主要包括关键点检测、3D边界框回归分支。
5.1 关键点检测
在关键点分支中,图像中的每一个目标用一个关键点进行表示。 这里的关键点被定义为目标3D框的中心点在图像平面上的投影点,而不是目标的2D框中心点。
如图5.1所示,红色点是目标的2D框中心点,橙色点是3D框的中心点在图像平面上的投影点。

图5.1 关键点检测
设关键点坐标为 ( x c , y c ) \left( x_{c} ,y_{c}\right) (xc,yc),则其与目标在相机坐标系下的位置 (x,y,z) 之间的关系表示如下:
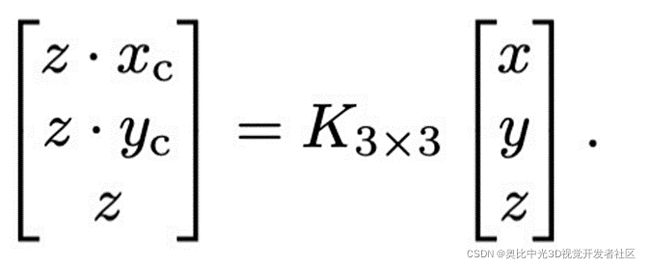
这是个经典的3D世界到相机平面投影的公式,K是相机内参;
如果对单目相机模型不理解的,这里参考高翔大佬的《视觉SLAM十四讲》进行补充说明一下。假设在世界坐标系中看到点P,通过小孔成像模型,投影到相机坐标系中形成点p’ ;通过相似三角形定理推出: z f = X X ’ 和 z f = Y Y ’ \frac{z}{f}=\frac{X}{X^{’}}和 \frac{z}{f}=\frac{Y}{Y^{’}} fz=X’X和fz=Y’Y,整理后得到如下图的形式。

如下图所示,相机坐标 ( X ′ , Y ′ ) (X^{'},Y^{'} ) (X′,Y′)转换到像素坐标 ( u , v ) (u,v) (u,v) ;其过程包括比例变化和平移。

5.2 3D边界框回归分支
3D框回归用于预测与构建3D边界框相关的信息,该信息可以表示为一个8元组:
τ = ( λ z , λ x c , λ y c , λ h , λ w , λ l , s i n α , c o s α ) T \tau=\left( \lambda_{z} ,\lambda_{x_{c}} ,\lambda_{y_{c}} ,\lambda_{h} ,\lambda_{w} ,\lambda_{l},sin\alpha,cos\alpha\right)^{T} τ=(λz,λxc,λyc,λh,λw,λl,sinα,cosα)T
参数含义如下:
λ z \lambda_{z} λz 表示目标的深度偏移量;
λ x c \lambda_{x_{c}} λxc 表示特征图的关键点坐标x方向的偏移量;
λ y c \lambda_{y_{c}} λyc表示特征图的关键点坐标y方向的偏移量;
λ h , λ w , λ l \lambda_{h} ,\lambda_{w} ,\lambda_{l} λh,λw,λl, 表示目标体积值得残差;
s i n α , c o s α sin\alpha,cos\alpha sinα,cosα 表示目标旋转角得向量化表示。
由于网络中进行了特征图下采样,下采样后的特征图上的关键点坐标基于预定义的关键点坐标执行离散化下采样得到,但是这样计算出来的关键点坐标会存在误差,因此论文中设置了两个预测量 λ x c 和 λ y c \lambda_{x_{c}} 和 \lambda_{y_{c}} λxc和λyc 。
构建3D边界框的流程如下:
(1)设关键点坐标为 ( x c , y c ) \left( x_{c} ,y_{c}\right) (xc,yc) ,则其与目标在相机坐标系下的位置 (x,y,z) 之间的关系表示如下边公式:
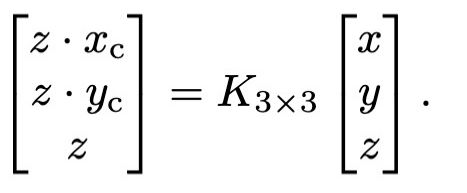 (2)对于目标的深度z,可以通过预先计算好的尺度因子和平移因子计算如下:
(2)对于目标的深度z,可以通过预先计算好的尺度因子和平移因子计算如下:
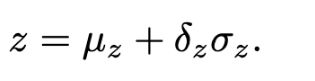
(3)当目标深度z 计算得到后,目标在相机坐标系下的位置也可以通过其在图像上的投影坐标变换得到:

(4)计算目标体积,首先对整个数据集计算各个类别目标的平均体积,然后基于前面提到的网络预测的体积残差计算目标的真实体积如下:

其中在计算目标的深度z时,预先计算好的尺度因子和平移因子,参考源码:

六、损失函数
关键点分类损失函数
由于论文是基于关键点的,因此其关键点分类loss借鉴了CornerNet与CenterNet中的带惩罚因子的focal loss,引入了高斯核对关键点真值附近的点也分配了监督信号进行约束。
在输出的热图(heatmap)上以逐点方式使用惩罚减少焦点损失,设 ( S i , j ) (S_{i},j) (Si,j) 是热图位置 ( i , j ) (i,j) (i,j) 的预测分数, ( y i , j ) (y_{i},j) (yi,j)是高斯核分配的每个点的真实值,定义如下:
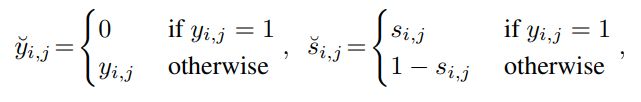
这里只考虑单个对象类,关键点分类的损失函数公式如下:

其中a,b是可调的参数,N是每张图的关键点数量,(1- y ˇ i , j {\check y_{i,j}} yˇi,j )是对真值点周围的区域的点的惩罚。
3D边界框回归损失函数
借鉴了“Disentangling Monocular 3D Object Detection”中所提出的解耦训练的方式。回归的对象是3D边界框的( λ z \lambda_{z} λz , λ x c \lambda_{x_{c}} λxc , λ y c \lambda_{y_{c}} λyc , λ h \lambda_{h} λh , λ w \lambda_{w} λw , λ l \lambda_{l} λl, s i n α sin\alpha sinα, c o s α cos\alpha cosα)八个参数;回归的损失函数使用L1 Loss,3D边界框回归损失定义为:

其中; B ∧ B \wedge B∧ 系数是预测值,B是真实值, λ N \frac{\lambda}{N} Nλ系数是用作调节回归损失和关键点分类损失的占比的。
总体的损失函数
总的损失函数是分类和回归两个损失函数相加,公式定义如下:
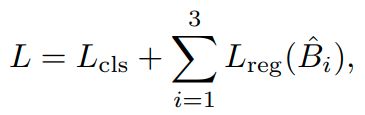
七、训练细节
细节1、滤除3D中心点投影位于图像平面以外的目标
进行关键点分类时,预测的是3D中心点在图像平面上的投影点,因此在进行训练时,论文滤除掉了那些3D中心点投影位于图像平面以外的目标。
细节2、数据增强
采用了随机水平翻转、缩放和平移操作,由于缩放和平移操作会引起目标3D属性的改变,因此数据增强仅仅用于关键点分类阶段。
细节3、限制关键点个数
在测试阶段,为了减小误检的影响,针对每幅图像,论文仅选取得分在前100个的关键点,并且基于0.25的预测得分进行过滤。
八、实验结果
8.1、3D目标检测、鸟瞰图、2D目标检测
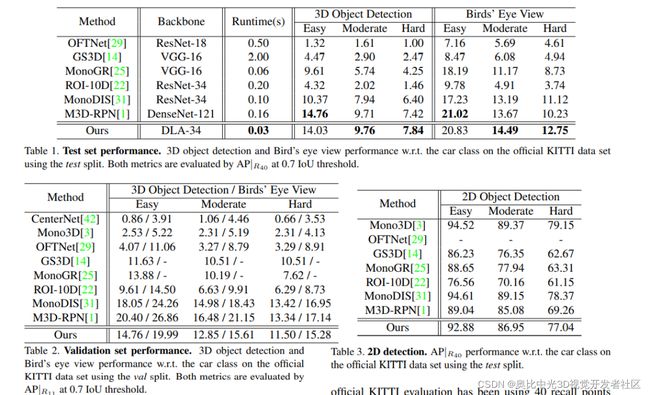
表1:测试集上评估汽车类的3D物体检测和鸟瞰性能,其中AP|R40以0.7IoU阈值。
表2:验证集上评估汽车类的3D 物体检测和鸟瞰性能,其中AP|R40以0.7IoU阈值。
表3:2D车辆检测结果,论文基于预测的3D信息恢复出来的2D检测框也同样表现出了比较好的性能。
8.2、消融实验
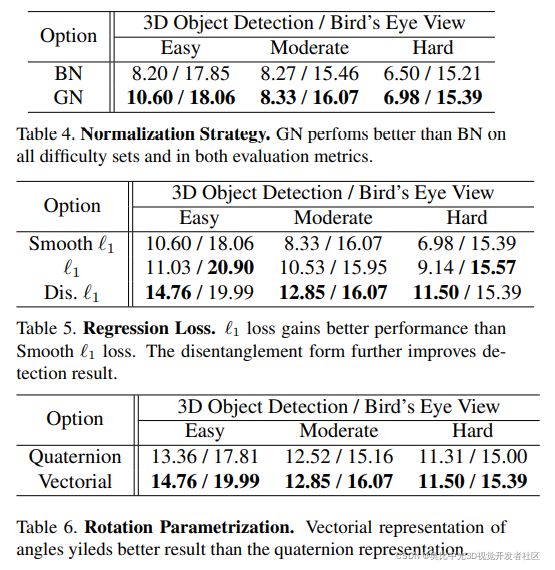
Table4,Table5和Table6则分别通过一系列的消融实验,验证了论文中所做的一些改进的性能提升:
- 使用GN相比于使用BN的效果提升。
- 使用解耦方式训练loss的性能提升。
- 采用向量表示旋转角相比于四元数的性能提升。
8.3、模型效果

9、SMOKE在百度Apollo7.0中应用
百度在Apollo7.0中也基于SMOKE框架开发出了一个新的基于视觉的障碍物检测模型,其针对SMOKE做了一些改进,并在waymo数据集上进行了训练和测试。改进点:
- 使用常规卷积替换可变性卷积,从而能转换为onnx或libtorch,便于模型部署;
- 增加了一个用于预测2D边界框中心点与3D边界框中心点投影之间的偏移量的head,然后将该偏移量与2D边界框中心点相加来替换原有的3D边界框中心点投影预测,以应对部分截断障碍物的3D中心点投影出现在图像以外区域,以至于被过滤掉的问题;
- 原有的SMOKE框架没有预测2D边界框,Apollo在部署的时候仍然加入了2D边界框的预测。通过预测2D边框的中心点、宽度和高度,计算出障碍物的2D边框。
改进后的模型,在waymo验证集上的测试结果如下表所示:
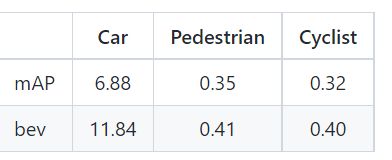
效果:

版权声明:本文为奥比中光3D视觉开发者社区特约作者授权原创发布,未经授权不得转载,本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。点击加入3D视觉开发者社区,和开发者们一起讨论分享吧~
或可微信关注官方公众号 3D视觉开发者社区 ,获取更多干货知识哦。