sklearn SVM的应用-山鸢花分类python代码
'''
导入sklearn自带数据集:山鸢鸟数据集
数据集包括 150 条鸢尾花的四个特征 (萼片长/宽和花瓣长/宽) 和三个类别。
是从 csv 文件读取的,本工程从 Sklearn 里面的 datasets 模块中引入,代码如下:
'''
from sklearn.datasets import load_iris
iris = load_iris()
import numpy as np
import matplotlib.pyplot as plt
'''
导入需要的包机器学习中
from sklearn.cross_validation import train_test_split出错
解决方法:
from sklearn.model_selection import train_test_split
原因:
cross_validation 里面的函数都放在 model_selection 里面了
'''
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
#x = iris.data[:,] #取所有特征列;特征值矩阵;
x = iris.data[:, 2:4] #取特征的后两个;如需要画图,用这一行;
y = iris.target[:] #标签列
#print(x)
#print(y)
'''
划分测试集及训练集
test_size:float or int, default=None
测试集的大小,如果是小数的话,值在(0,1)之间,表示测试集所占有的比例;
如果是整数,表示的是测试集的具体样本数;
如果train_size也是None的话,会有一个默认值0.25
shuffle:布尔值,可选(默认值=True)默认洗牌;
'''
train_x, test_x, train_y, test_y = train_test_split(x, y, test_size=0.2, random_state=20)
'''
模型训练及预测:
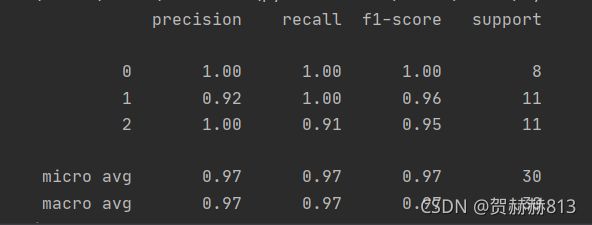
其中列表左边的一列为分类的标签名,右边support列为每个标签的出现次数.
avg / total行为各列的均值(support列为总和).
precision recall f1-score三列分别为各个类别的精确度/召回率及值
计算方法:https://blog.csdn.net/akadiao/article/details/78788864
F1值是精确度和召回率的调和平均值:
2F1=1P+1R
F1=2P×RP+R
精确度和召回率都高时,F1值也会高. F1值在1时达到最佳值(完美的精确度和召回率),最差为0.在二元分类中, F1值是测试准确度的量度。
'''
'''
创建SVC模型(支持向量机)
sklearn.svm.SVC中kernel参数说明:
https://blog.csdn.net/qq_37007384/article/details/88418256
'''
clf = SVC(kernel='linear', C=0.2)#线性核,惩罚参数
clf.fit(train_x, train_y)
linearVector = clf.support_vectors_
pred_y = clf.predict(test_x)
print(classification_report(test_y, pred_y))
'''
绘制分类结果的图像:目前只能拿两个特征做分类,只用了两个特征只能画二维图像;
'''
steplength = 0.02 # 将训练出的模型用于高密度的预测,形成一条边界,就是二分类的边界线;边界的宽度;可以理解为最小误差;栅格的大小
x_min, x_max = x[:, 0].min() - 0.1, x[:, 0].max() + 0.1#x的范围:特征1的范围:4.2-8.0;
y_min, y_max = x[:, 1].min() - 0.1, x[:, 1].max() + 0.1#y的范围:特征2的范围:1.5-4.5
xmesh = np.arange(x_min, x_max, steplength)
ymesh = np.arange(y_min, y_max, steplength)
xx, yy = np.meshgrid(xmesh, ymesh)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
#这里预测出来的Z是行向量,也需要重整理成矩阵形式
# Put the result into a color plot
Z = Z.reshape(xx.shape)
f1 = plt.figure()
plt.title('Linear Kernel boundary output')
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
# Plot also the training points
plt.scatter(x[y == 0, 0], x[y == 0, 1], marker='v', color='k', s=100, label='bad')
plt.scatter(x[y == 1, 0], x[y == 1, 1], marker='o', color='g', s=100, label='good')
plt.scatter(linearVector[:, 0], linearVector[:, 1], marker='.', color='r')
plt.show()