机器学习Sklearn实战——KNN算法
scikit-learn
- Simple and efficient tools for predictive data analysis
- Accessible to everybody, and reusable in various contexts
- Built on NumPy, SciPy, and matplotlib
- Open source, commercially usable - BSD license
KNN算法入门
- k近邻算法:nearest neighbors classification
- k定义多少个邻居
- 物以类聚,人以群分
- 教会计算机根据邻居分类,邻居:距离比较近
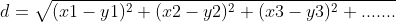
- 距离越小,越近,d<10规定邻居
- 计算——>数学公式——>计算结构
- 计算获取邻居(5个邻居)——>统计,类别(富有,贫穷),富有4个,贫穷1个
- 4>1 富有>贫穷
- 结论:判断出来,我也是富有,概率,概率低
- 人分类时,有可能出现错误
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
movie = pd.read_excel("/Users/zhucan/Desktop/movies.xlsx",sheet_name = 1)
data = movie.iloc[:,1:3]
target = movie['分类情况']
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(data,target)
X_test = pd.DataFrame({"武打镜头":[100,67,1],"接吻镜头":[3,2,10]})
print(knn.predict(X_test))['动作片' '动作片' '爱情片']KNN鸢尾花分类
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
iris = datasets.load_iris()
x = iris["data"]
y = iris["target"]
index = np.arange(150)
np.random.shuffle(index)
x_train,x_test = x[index[:100]],x[index[100:]]
y_train,y_test = y[index[:100]],y[index[100:]]
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train,y_train)
y_=knn.predict(x_test)
print(y_)
print("--------------------")
print(y_test)[1 1 0 1 2 1 1 0 0 0 2 0 0 1 1 2 1 2 0 1 0 0 2 0 1 2 0 2 0 0 0 0 1 2 1 1 1
0 0 0 0 1 2 2 2 1 1 2 1 1]
--------------------
[1 1 0 1 2 1 1 0 0 0 2 0 0 1 1 2 1 2 0 1 0 0 2 0 1 2 0 2 0 0 0 0 1 2 1 1 1
0 0 0 0 1 1 2 2 1 1 2 1 1]KNN算法调参数
print(knn.score(x_test,y_test))0.96proba_ = knn.predict_proba(x_test)
print(proba_)
print(proba_.argmax(axis=1))
print(y_)[[0. 1. 0. ]
[1. 0. 0. ]
[0. 0. 1. ]
[1. 0. 0. ]
[0. 1. 0. ]
[0. 1. 0. ]
[0. 0. 1. ]
[0. 1. 0. ]
[1. 0. 0. ]
[0. 0. 1. ]
[0. 0.2 0.8]
[1. 0. 0. ]
[0. 1. 0. ]
[0. 1. 0. ]
[1. 0. 0. ]
[0. 0. 1. ]
[0. 0. 1. ]
[0. 0. 1. ]
[1. 0. 0. ]
[1. 0. 0. ]
[0. 1. 0. ]
[1. 0. 0. ]
[0. 0. 1. ]
[0. 0. 1. ]
[1. 0. 0. ]
[0. 0.2 0.8]
[0. 1. 0. ]
[0. 0.2 0.8]
[1. 0. 0. ]
[1. 0. 0. ]
[0. 1. 0. ]
[1. 0. 0. ]
[0. 0. 1. ]
[0. 1. 0. ]
[0. 1. 0. ]
[0. 0. 1. ]
[1. 0. 0. ]
[0. 0. 1. ]
[0. 0. 1. ]
[1. 0. 0. ]
[0. 0. 1. ]
[1. 0. 0. ]
[1. 0. 0. ]
[1. 0. 0. ]
[0. 0. 1. ]
[0. 1. 0. ]
[1. 0. 0. ]
[0. 1. 0. ]
[0. 1. 0. ]
[0. 0. 1. ]]
[1 0 2 0 1 1 2 1 0 2 2 0 1 1 0 2 2 2 0 0 1 0 2 2 0 2 1 2 0 0 1 0 2 1 1 2 0
2 2 0 2 0 0 0 2 1 0 1 1 2]
[1 0 2 0 1 1 2 1 0 2 2 0 1 1 0 2 2 2 0 0 1 0 2 2 0 2 1 2 0 0 1 0 2 1 1 2 0
2 2 0 2 0 0 0 2 1 0 1 1 2]knn = KNeighborsClassifier(n_neighbors=5,weights="uniform"/"distance",p=1/2)
p=1曼哈顿距离
p=2欧氏距离
n_neighbors最好不要超过样本数量开平方
KNN手写数字识别
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
digit = cv2.imread("./data/0/0_101.bmp")
digit = cv2.cvtColor(digit,code=cv2.COLOR_BGR2GRAY)
X=[]
for i in range(10):
for j in range(1,501):
digit = cv2.imread("./data/%d/%d_%d.bmp"%(i,i,j))
X.append(digit[:,:,0])
#数据X和目标值y是一一对应
X = np.asarray(X)
y = [i for i in range(10)]*500
y.sort()
index = np.random.randint(0,5000,size=1)[0]
digit = X[index]
print(y[index])
plt.imshow(digit,cmap=plt.cm.gray)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2)
X_train = X_train.reshape(4000,-1)
knn = KNeighborsClassifier(n_neighbors=63)
knn.fit(X_train,y_train)
X_test = X_test.reshape(1000,-1)
y_ = knn.predict(X_test)
knn.score(X_test,y_test)
二值化操作
for i in range(5000):
for y in range(28):
for x in range(28):
if X[i][y,x] < 200:
X[i][y,x] = 0
else:
X[i][y, x] = 0
train_test_split(X,y,test_size=0.2,random_state=100)