python机器学习基础05——sklearn之逻辑回归+分类评价指标
文章目录
- 逻辑回归
-
- 逻辑回归的损失函数
- 逻辑回归API
- 分类模型的评价指标
-
- 混淆矩阵
-
- 准确率
- 召回率(较多被使用)
- 精确率
- f1-score:精确率和召回率的调和平均数
- AUC
逻辑回归
逻辑回归是经典的分类模型,使用的是sigmod函数

- 函数解释:
- Sigmoid函数是一个S型的函数,当自变量z趋近正无穷时,因变量g(z)趋近于1,而当z趋近负无穷时,g(z)趋近于0,它能够将任何实数(非0和1的标签数据)映射到(0,1)区间,使其可用于将任意值函数转换为更适合二分类的函数。 因为这个性质,Sigmoid函数也被当作是归一化的一种方法,与我们之前学过的MinMaxSclaer同理,是属于数据预处理中的“缩放”功能,可以将数据压缩到[0,1]之内。区别在于,MinMaxScaler归一化之后,是可以取到0和1的(最大值归一化后就是1,最小值归一化后就是0),但Sigmoid函数只是无限趋近于0和1。
逻辑回归的损失函数
- 在逻辑回归分类的时候,不管原始样本中的类别使用怎样的值或者文字表示,逻辑回归统一将其视为0类别和1类别。
- 因为逻辑回归也采用了寻找特征和目标之间的某种关系,则每个特征也是有权重的就是w,那么也会存在真实值和预测值之间的误差(损失函数),那么逻辑回归的损失函数和线性回归的损失函数是否一样呢?
- 由于逻辑回归是用于分类的,因此该损失函数和线性回归的损失函数是不一样的!逻辑回归采用的损失函数是:对数似然损失函数:
- 注意:没有求解参数需求的模型是没有损失函数的,比如KNN,决策树。
- 损失函数被写作如下:
- 为什么使用-log函数为损失函数,损失函数的本质就是,如果我们预测对了,则没有损失,反之则损失需要变的很大,而-log函数在【0,1】之间正好符合这一点(-log可以放大损失),
我们可以画图尝试,在结果为1是,被分到1的损失越小,远离1的损失越大,log在0,1取值正好满足- -log(h)表示分类到正例1的损失
- -log(1-h)表示分类到反例0的损失
- 为什么使用-log函数为损失函数,损失函数的本质就是,如果我们预测对了,则没有损失,反之则损失需要变的很大,而-log函数在【0,1】之间正好符合这一点(-log可以放大损失),

综合后的损失函数为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0VsCe32o-1645016453497)(F:/ZNV/%E7%AC%94%E8%AE%B0%E5%9B%BE%E7%89%87/python/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/image-20220215211138887.png)]](http://img.e-com-net.com/image/info8/764568da6ae24ef4a269832806d90b30.jpg)
这里逻辑回归中优化损失的方法有两个:梯度下降和正则化
梯度下降
- 梯度下降原理介绍:
- 假设现在有一个带两个特征并且没有截距的逻辑回归y(x1,x2),两个特征所对应的参数分别为[1,2]。我们的损失函数 J(1,2)在以1,2和J为坐标轴的三维立体坐标系上的图像。现在,我们寻求的是损失函数的最小值,也就是最低点。
正则化
- 注意:
- 由于我们追求损失函数的最小值,让模型在训练集上表现最优,可能会引发另一个问题:如果模型在训练集上表示优秀,却在测试集上表现糟糕,模型就会过拟合。所以我们还是需要使用控制过拟合的技术来帮助我们调整模型,对逻辑回归中过拟合的控制,通过正则化来实现。
- 正则化是用来防止模型过拟合的过程,常用的有L1正则化和L2正则化两种选项,分别通过在损失函数后加上参数向量的L1范式和L2范式的倍数来实现。这个增加的范式,被称为“正则项”,也被称为"惩罚项"。

-
其中J()是我们之前提过的损失函数,C是用来控制正则化程度的超参数,n是方程中特征的总数,也是方程中参数的总数,j代表每个参数(w系数)。在这里,j要大于等于1,是因为我们的参数向量中,第一个参数是0,是我们的截距它通常是不参与正则化的。
-
总结:
- 我们知道损失函数的损失值越小(在训练集中预测值和真实值越接近)则逻辑回归模型就越有可能发生过拟合(模型只在训练集中表现的好,在测试集表现的不好)的现象。通过正则化的L1和L2范式可以加入惩罚项C来矫正模型的拟合度。因为C越小则损失函数会越大表示正则化的效力越强,参数会被逐渐压缩的越来越小。
- 注意:L1正则化会将参数w压缩为0,L2正则化只会让参数尽量小,不会取到0。原因解释会涉及到坐标下降法和求导相关,故作不解释,只需要记住结论即可!
-
L1和L2范式的区别
- 在L1正则化在逐渐加强的过程中,携带信息量小的、对模型贡献不大的特征的参数w,会比携带大量信息的、对模型有巨大贡献的特征的参数更快地变成0,所以L1正则化本质是一个特征选择的过程。L1正则化越强,参数向量中就越多的参数为0,选出来的特征就越少,以此来防止过拟合。因此,如果特征量很大,数据维度很高,我们会倾向于使用L1正则化。
- L2正则化在加强的过程中,会尽量让每个特征对模型都有一些小的贡献,但携带信息少,对模型贡献不大的特征的参数w会非常接近于0。通常来说,如果我们的主要目的只是为了防止过拟合,选择L2正则化就足够了。但是如果选择L2正则化后还是过拟合,模型在未知数据集上的效果表现很差,就可以考虑L1正则化。
逻辑回归API
- from sklearn.linear_model import LogisticRegression
- 超参数介绍:
- penalty:
- 可以输入l1或者l2来指定使用哪一种正则化方式。不填写默认"l2"。 注意,若选择"l1"正则化,参数solver仅能够使用求解方式”liblinear"和"saga“,若使用“l2”正则 化,参数solver中所有的求解方式都可以使用。
- C:
- 惩罚项。必须是一个大于0的浮点数,不填写默认1.0,即默认正则项与损失函数的比值是1:1。C越小,损失函数会越大,模型对损失函数的惩罚越重,正则化的效力越强,参数会逐渐被压缩得越来越小。
- max_iter:
- 梯度下降中能走的最大步数,默认值为100.步数的不同取值可以帮助我们获取不同的损失函数的损失值。目前没有好的办法可以计算出最优的max_iter的值,一般是通过绘制学习曲线对其进行取值。
- solver:
- 我们之前提到的梯度下降法,只是求解逻辑回归参数的一种方法。sklearn为我们提供了多种选择,让我们可以使用不同的求解器来计算逻辑回归。求解器的选择,由参数"solver"控制,共有五种选择。
- liblinear:是二分类专用(梯度下降),也是现在的默认求解器。
- lbfgs,newton-cg,sag,saga:是多分类专用,几乎不用。

- 我们之前提到的梯度下降法,只是求解逻辑回归参数的一种方法。sklearn为我们提供了多种选择,让我们可以使用不同的求解器来计算逻辑回归。求解器的选择,由参数"solver"控制,共有五种选择。
- multi_class:
- 输入"ovr", “multinomial”, “auto"来告知模型,我们要处理的分类问题的类型。默认是"ovr”。
- ‘ovr’:表示分类问题是二分类,或让模型使用"一对多"的形式来处理多分类问题。
- ‘multinomial’:表示处理多分类问题,这种输入在参数solver是’liblinear’时不可用。
- “auto”:表示会根据数据的分类情况和其他参数来确定模型要处理的分类问题的类型。比如说,如果数据是二分 类,或者solver的取值为"liblinear",“auto"会默认选择"ovr”。反之,则会选择"multinomial"。
- 输入"ovr", “multinomial”, “auto"来告知模型,我们要处理的分类问题的类型。默认是"ovr”。
- class_weight:
- 表示样本不平衡处理的参数。样本不平衡指的是在一组数据中,某一类标签天生占有很大的比例,或误分类的代价很高,即我们想要捕捉出某种特定的分类的时候的状况。什么情况下误分类的代价很高?
- 例如,我们现在要对潜在犯罪者和普通人进行分类,如果没有能够识别出潜在犯罪者,那么这些人就可能去危害社会,造成犯罪,识别失败的代价会非常高,但如果,我们将普通人错误地识别成了潜在犯罪者,代价却相对较小。所以我们宁愿将普通人分类为潜在犯罪者后再人工甄别,但是却不愿将潜在犯罪者 分类为普通人,有种"宁愿错杀不能放过"的感觉。
- 再比如说,在银行要判断“一个新客户是否会违约”,通常不违约的人vs违约的人会是99:1的比例,真正违约的人其实是非常少的。这种分类状况下,即便模型什么也不做,全把所有人都当成不会违约的人,正确率也能有99%, 这使得模型评估指标变得毫无意义,根本无法达到我们的“要识别出会违约的人”的建模目的。
- None:
- 因此我们要使用参数class_weight对样本标签进行一定的均衡,给少量的标签更多的权重,让模型更偏向少数类, 向捕获少数类的方向建模。该参数默认None,此模式表示自动给与数据集中的所有标签相同的权重,即自动1: 1。
- balanced:
- 当误分类的代价很高的时候,我们使用”balanced“模式,可以解决样本不均衡问题。
- 表示样本不平衡处理的参数。样本不平衡指的是在一组数据中,某一类标签天生占有很大的比例,或误分类的代价很高,即我们想要捕捉出某种特定的分类的时候的状况。什么情况下误分类的代价很高?
- penalty:
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
import sklearn.datasets as dt
from sklearn.model_selection import train_test_split
feature = dt.load_breast_cancer()['data']
target = dt.load_breast_cancer()['target']
x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2021)
knn = KNeighborsClassifier().fit(x_train,y_train)
print('knn:',knn.score(x_test,y_test))
gs = GaussianNB().fit(x_train,y_train)
print('gs:',gs.score(x_test,y_test))
l = LogisticRegression().fit(x_train,y_train)
print('l:',l.score(x_test,y_test))
# 结果:
knn: 0.9035087719298246
gs: 0.9385964912280702
l: 0.9210526315789473
l = LogisticRegression(penalty='l1',solver='liblinear',max_iter=500).fit(x_train,y_train)
print('l:',l.score(x_test,y_test)) # l: 0.9298245614035088
分类模型的评价指标
相关知识点:https://blog.csdn.net/xiaoyoupei/article/details/121547135
- 准确率
- 精准率
- 召回率
- f1-Score
- auc曲线
混淆矩阵
-
概念:在分类任务下,预测结果(Predict Condition)和真实结果(True Condition)之间存在的四种不同的组合。适用于二分类和多分类
-
例子:设计一个二分类的场景,将图片分类为猫或者狗。则:
-
真正例(TP):本来是猫结果预测值为猫的比例(预测为正例是真的)
-
伪正例(FP):本来不是猫结果预测值为猫的比例(预测为正例是假的)
-
伪反例(FN):本来是猫结果预测值为不是猫的比例(预测为反例是假的)
-
真反例(TN):本来不是猫结果预测值为不是猫的比例(预测为反例是真的)
-
真正例率TPR = TP / (TP + FN)
- 预测为正例且实际为正例的样本占所有训练集中为正例样本的比例。
- 将正例预测对的占正样本的比例(预测对的比例),这个比例越大越好
-
伪反例率FPR = FP / (FP + TN)
- 预测为正例但实际为负例的样本占训练集中所有负例样本的比例
- 将负例预测错的占负样本的比例(预测错的比例),这个比例越小越好
准确率
- Accuracy = (TP+TN)/(TP+FN+FP+TN)
- 解释:(预测正确)/(预测对的和不对的所有结果),简而言之就是预测正确的比例。
- 准确率=所有预测正确的结果除以所有结果
- 比如一个模型要识别 5 张图片,最后 识别正确 4 张图片,错了 1 张,那么准确率就是 4/5=80%
- 模型.score()方法返回的就是模型的准确率
- 解释:(预测正确)/(预测对的和不对的所有结果),简而言之就是预测正确的比例。
召回率(较多被使用)
-
在数据不均衡的场景下,我们应该考虑的评估指标应该是精确率和召回率。
-
Recal = TP/(TP+FN)
精确率
- Precision = TP/(TP+FP)
f1-score:精确率和召回率的调和平均数
- 有时候我们需要综合精确率和召回率的指标,则需要使用f1-score
- 一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
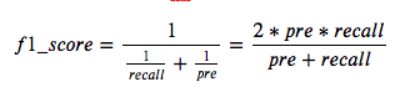 - 反应了模型的稳健性
- 反应了模型的稳健性 - 它是精确率和召回率的调和平均数
- 是一个综合的评判标准
from sklearn.linear_model import LogisticRegression
import sklearn.datasets as dt
from sklearn.model_selection import train_test_split
from sklearn.metrics import recall_score #召回率
from sklearn.metrics import accuracy_score #精确率
from sklearn.metrics import f1_score
feature = dt.load_breast_cancer()['data']
target = dt.load_breast_cancer()['target']
x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2021)
l = LogisticRegression().fit(x_train,y_train)
print('准确率:',l.score(x_test,y_test))
print('召回率:',recall_score(y_test,l.predict(x_test)))
print('精确率:',accuracy_score(y_test,l.predict(x_test)))
print('f1-score:',f1_score(y_test,l.predict(x_test)))
# 结果:
准确率: 0.9210526315789473
召回率: 0.9722222222222222
精确率: 0.9210526315789473
f1-score: 0.9395973154362416
AUC
-
AUC是一个模型评价指标,只能用于二分类模型的评价。该评价指标通常应用的比较多!
- 应用的比较多是原因是因为很多的机器学习的分类模型计算结果都是概率的形式(比如逻辑回归),那么对于概率而言,我们就需要去设定一个阈值来判定分类,那么这个阈值的设定就会对我们的正确率和准确率造成一定成都的影响。
- 逻辑回归的默认阈值为0.5
- 应用的比较多是原因是因为很多的机器学习的分类模型计算结果都是概率的形式(比如逻辑回归),那么对于概率而言,我们就需要去设定一个阈值来判定分类,那么这个阈值的设定就会对我们的正确率和准确率造成一定成都的影响。
-
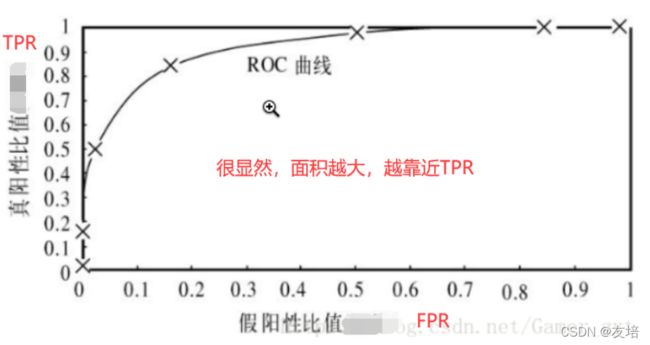
AUC(Area under Curve),表面上意思是曲线下边的面积,这么这条曲线是什么?
-
ROC曲线(receiver operating characteristic curve,接收者操作特征曲线)
-
真正例率TPR = TP / (TP + FN)
- 预测为正例且实际为正例的样本占所有训练集中为正例样本的比例。 - 将正例预测对的占正样本的比例(预测对的比例),这个比例越大越好 -
伪反例率FPR = FP / (FP + TN)
- 预测为正例但实际为负例的样本占训练集中所有负例样本的比例 - 将负例预测错的占负样本的比例(预测错的比例),这个比例越小越好
-
-
-
在理想情况下,最佳的分类器应该尽可能地处于左上角,这就意味着分类器在伪反例率(预测错的概率)很低的同时获得了很高的真正例率(预测对的概率)。也就是说ROC曲线围起来的面积越大越好,因为ROC曲线面积越大,则曲线上面的面积越小,则分类器越能停留在ROC曲线的左上角。
- AUC的的取值是固定在0-1之间。AUC的值越大越好。
-
AUC的API
- from sklearn.metrics import roc_auc_score
- y_pre = predict_proba(x_test)返回预测的概率
- auc=roc_auc_score(y_test,y_pre[:,1])
from sklearn.metrics import roc_auc_score
l = LogisticRegression().fit(x_train,y_train)
#y_score是模型将测试样本集分到正例类别的概率
y_score = l.predict_proba(x_test)[:,1]
roc_auc_score(y_test,y_score) # 0.9847883597883598