写在前面
此系列是本人一个字一个字码出来的,包括示例和实验截图。由于系统内核的复杂性,故可能有错误或者不全面的地方,如有错误,欢迎批评指正,本教程将会长期更新。 如有好的建议,欢迎反馈。码字不易,如果本篇文章有帮助你的,如有闲钱,可以打赏支持我的创作。如想转载,请把我的转载信息附在文章后面,并声明我的个人信息和本人博客地址即可,但必须事先通知我。
你如果是从中间插过来看的,请仔细阅读 羽夏看Win系统内核——简述 ,方便学习本教程。
看此教程之前,问几个问题,基础知识储备好了吗?保护模式篇学会了吗?练习做完了吗?没有的话就不要继续了。
华丽的分割线
简述
初入64位的内核世界,64位的汇编肯定是基础。在64位的Win操作系统,调用约定并不是原来的多种多样,而是只有一种调用约定FastCall。并且在64位下,操作系统以及应用程序十分注重对齐(地址数值可以被16整除)和栈帧这个事情,并且SEH的实现也不再基于堆栈,这一切将在本篇我会详细介绍。
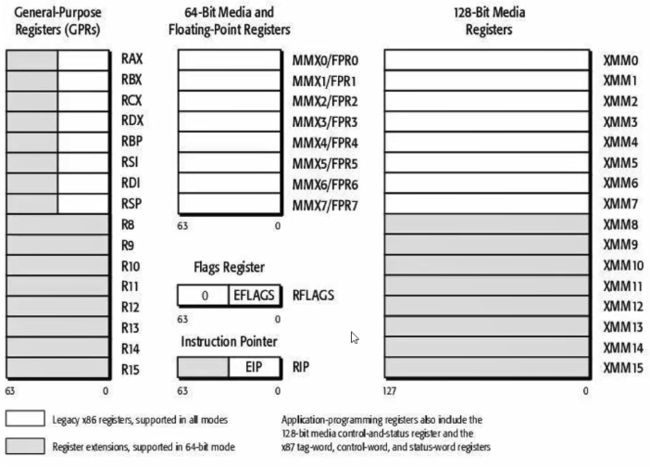
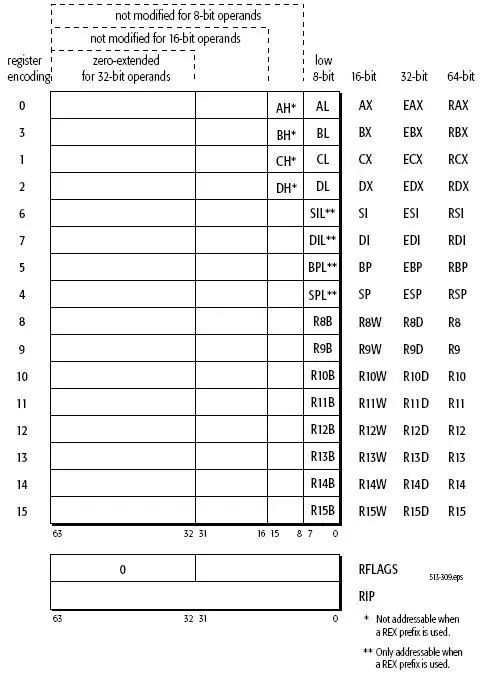
本部分讨论的x64是AMD64与Intel64的合称,是指与现有x86兼容的64位CPU。在64位系统中,内存地址为64位。64位环境下寄存器有比较大的变化,如下图所示:
在介绍本节东西之前,我们先学习在64位下的仅有FastCall调用约定,实行外平栈:
| 参数 | 类型 | 浮点类型 |
|---|---|---|
| 第1个参数 | RCX | XMM0 |
| 第2个参数 | RDX | XMMI |
| 第3个参数 | R8 | XMM2 |
| 第4个参数 | R9 | XMM3 |
了解这些东西之后,我们接下来对64位的汇编进行铺垫。
汇编铺垫
当我们初步踏入64位汇编的世界时,我们先看看我们入门 羽夏看C语言 系列教程的时候会提供一个最简单的示例来从汇编角度来看C/C++,现在我们重新用64位来看看它们现在的样子,如下是示例代码:
#include
using namespace std;
int main()
{
int a = 1;
cout << a << endl;
return 0;
}
它的反汇编如下所示:
#include
using namespace std;
int main()
{
00007FF628591860 push rbp
00007FF628591862 push rdi
00007FF628591863 sub rsp,108h
00007FF62859186A lea rbp,[rsp+20h]
int a = 1;
00007FF62859186F mov dword ptr [a],1
cout << a << endl;
00007FF628591876 mov edx,dword ptr [a]
00007FF628591879 mov rcx,qword ptr [__imp_std::cout (07FF6285A0170h)]
00007FF628591880 call qword ptr [__imp_std::basic_ostream >::operator<< (07FF6285A0158h)]
00007FF628591886 lea rdx,[std::endl > (07FF628591037h)]
00007FF62859188D mov rcx,rax
00007FF628591890 call qword ptr [__imp_std::basic_ostream >::operator<< (07FF6285A0150h)]
return 0;
00007FF628591896 xor eax,eax
}
00007FF628591898 lea rsp,[rbp+0E8h]
00007FF62859189F pop rdi
00007FF6285918A0 pop rbp
00007FF6285918A1 ret
可以看出,汇编似乎没有太大的变化,依旧采用rbp寻址,但是这个寻址看起来比较奇怪,下面我来逐步介绍这些奇怪之处。
lea rbp,[rsp+20h]这句汇编代码看起来比较奇怪,其实这里是预留给参数传递的空间,正好是4个参数的空间,在参数不多于4个的时候会采用,一共32个字节。稍后我们会对此进行展开。
还有一个比较奇怪的点,如下所示:
00007FF628591863 sub rsp,108h
00007FF62859186A lea rbp,[rsp+20h]
……
00007FF628591898 lea rsp,[rbp+0E8h]
看到在恢复堆栈的时候这两个数值不太一样了吗?这就是中间调用一些函数进行内平栈的结果,我们函数就写一个return 0;看看它的反汇编结果:
int main()
{
00007FF704AB1830 push rbp
00007FF704AB1832 push rdi
00007FF704AB1833 sub rsp,0C8h
00007FF704AB183A mov rbp,rsp
return 0;
00007FF704AB183D xor eax,eax
}
00007FF704AB183F lea rsp,[rbp+0C8h]
00007FF704AB1846 pop rdi
00007FF704AB1847 pop rbp
00007FF704AB1848 ret
这时候提升的堆栈和恢复的堆栈就是一模一样了。
下面我们继续来详细介绍有关参数调用的细节,当我们传参不多于4个的时候,它是怎样传参的,如下是测试代码:
#include
using namespace std;
int add(int a, int b, int c, int d)
{
return a + b + c + d;
}
int main()
{
int a = 3, b = 4, c = 5, d = 6;
int e = add(a, b, c, d);
return 0;
}
先看add函数的反汇编:
int add(int a, int b, int c, int d)
{
00007FF633681830 mov dword ptr [rsp+20h],r9d
00007FF633681835 mov dword ptr [rsp+18h],r8d
00007FF63368183A mov dword ptr [rsp+10h],edx
00007FF63368183E mov dword ptr [rsp+8],ecx
00007FF633681842 push rbp
00007FF633681843 push rdi
00007FF633681844 sub rsp,0C8h
00007FF63368184B mov rbp,rsp
return a + b + c + d;
00007FF63368184E mov eax,dword ptr [b]
00007FF633681854 mov ecx,dword ptr [a]
00007FF63368185A add ecx,eax
00007FF63368185C mov eax,ecx
00007FF63368185E add eax,dword ptr [c]
00007FF633681864 add eax,dword ptr [d]
}
00007FF63368186A lea rsp,[rbp+0C8h]
00007FF633681871 pop rdi
00007FF633681872 pop rbp
00007FF633681873 ret
对于开头的汇编代码,可能有点难理解:
mov dword ptr [rsp+20h],r9d
mov dword ptr [rsp+18h],r8d
mov dword ptr [rsp+10h],edx
mov dword ptr [rsp+8],ecx
如上参数就是存储在所谓的预留空间,示意图如下:
这预留的栈空间是在主函数内完成的,这个暂且先不关注。后面的代码紧接着是经典的rbp寻址,但是眼尖的同志可能会发现,后面的运算都是用32位寄存器,没有用64位的。
这里我啰嗦一下,64位寄存器是对32位的扩展,但是有些汇编指令32位有但是64位没有的,我们接下来探究这个事情。
对32位寄存器的写操作,包括运算结果,对相应的64位寄存器的高32位清0。这个是64位不同于32位的操作,我们用一个动图来展示一下该效果:
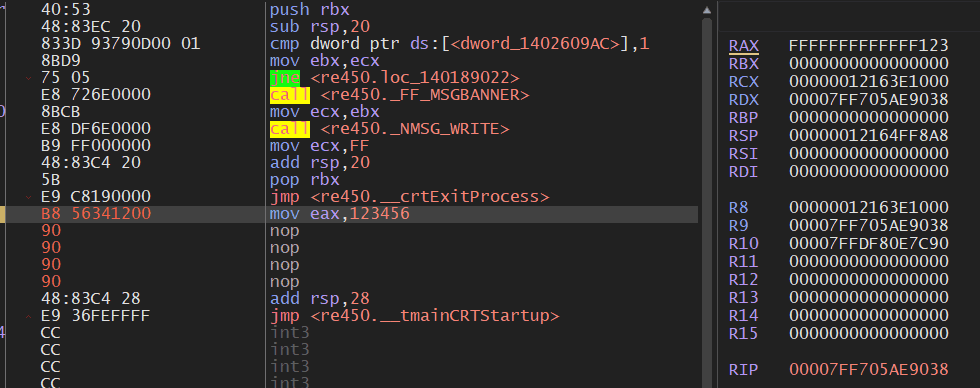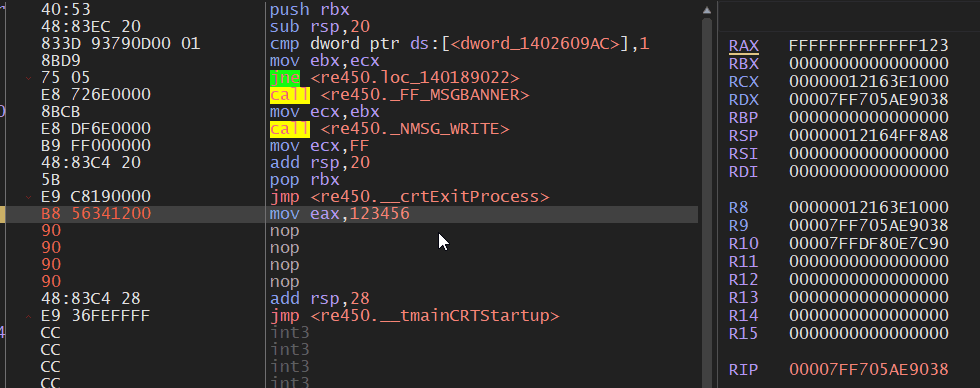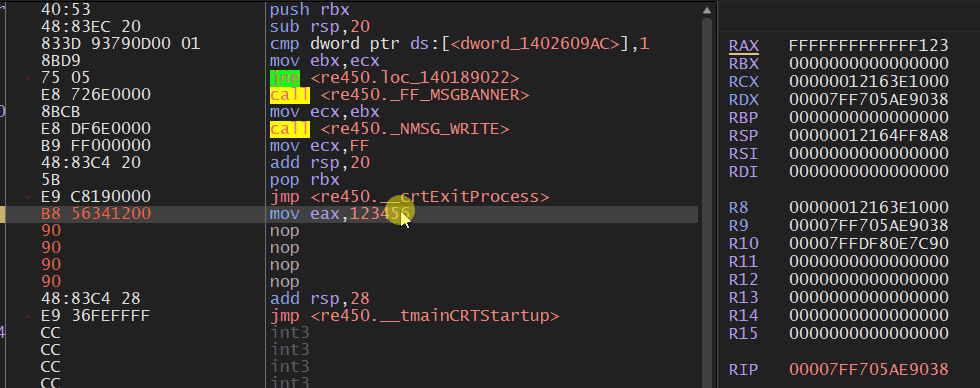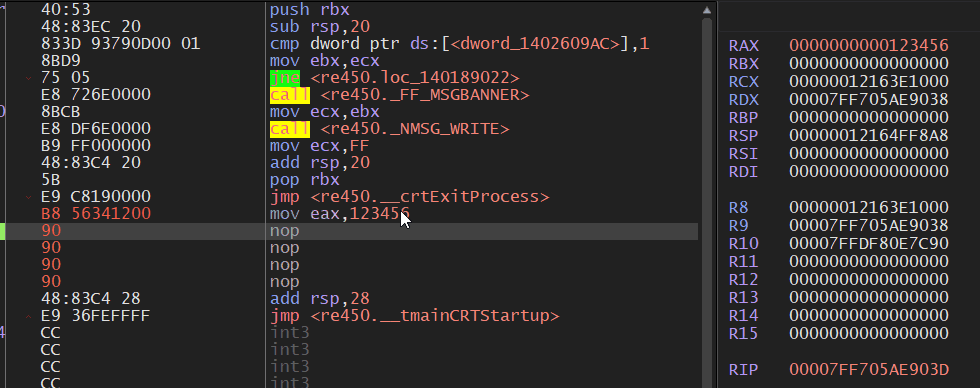
由于32位指令编码比对应的64位指令编码指令要短,为了优化就会使用较短的32位指令编码。比如xor rax,rax这条指令,它的硬编码为48 33 C0,而xor eax,eax可以实现相同的功能,它的硬编码为33 C0,那么编译器会优先使用xor eax,eax。
有些32位的汇编指令对应64位是没有的,比如push,在64位是没有的:
内存优先使用相对偏移寻址,直接寻址指令较少。这个我们来看一个例子,如下图所示:
![]()
可以看到硬编码的结果了吗?接的内容是0,但是指的是下一行地址,和32位下的jmp的硬编码方式是一样的。但是如果间接寻址的范围无法表示了,就写死地址,类似下面的结果:
![]()
当然,我们可以将间接寻址的改为直接寻址的,如下图所示:
![]()
这里再扩展比较有意思的nop指令,如下图所示,需要硬编码进行输入:
![]()
有关64位的汇编就介绍这么多,我们会过来再看看add函数的传参情况。后面都是我们学过32位的ebp寻址都能看懂的代码了,接下来看主函数的反汇编:
int main()
{
00007FF6336817A0 push rbp
00007FF6336817A2 push rdi
00007FF6336817A3 sub rsp,188h
00007FF6336817AA lea rbp,[rsp+20h]
int a = 3, b = 4, c = 5, d = 6;
00007FF6336817AF mov dword ptr [rbp+4],3
00007FF6336817B6 mov dword ptr [rbp+24h],4
00007FF6336817BD mov dword ptr [rbp+44h],5
00007FF6336817C4 mov dword ptr [rbp+64h],6
int e = add(a, b, c, d);
00007FF6336817CB mov r9d,dword ptr [rbp+64h]
00007FF6336817CF mov r8d,dword ptr [rbp+44h]
00007FF6336817D3 mov edx,dword ptr [rbp+24h]
00007FF6336817D6 mov ecx,dword ptr [rbp+4]
00007FF6336817D9 call 00007FF6336813C5
00007FF6336817DE mov dword ptr [rbp+0000000000000084h],eax
return 0;
00007FF6336817E4 xor eax,eax
}
00007FF6336817E6 lea rsp,[rbp+0000000000000168h]
00007FF6336817ED pop rdi
00007FF6336817EE pop rbp
00007FF6336817EF ret
开头我讲了,后面又来了奇怪的局部变量分配和初始化:
mov dword ptr [rbp+4],3
mov dword ptr [rbp+24h],4
mov dword ptr [rbp+44h],5
mov dword ptr [rbp+64h],6
可以看到,每个局部变量之间差了0x20个字节,也就是32个字节,这是为什么呢?目前暂时搞不清楚为什么,可能有对齐的意味在这里。
下面我们来看看IDA是如何分析这部分代码的:
; int __fastcall main()
main proc near
a= dword ptr -16Ch
b= dword ptr -14Ch
c= dword ptr -12Ch
d= dword ptr -10Ch
push rbp
push rdi
sub rsp, 188h
lea rbp, [rsp+20h]
mov [rbp+170h+a], 3
mov [rbp+170h+b], 4
mov [rbp+170h+c], 5
mov [rbp+170h+d], 6
mov r9d, [rbp+170h+d] ; d
mov r8d, [rbp+170h+c] ; c
mov edx, [rbp+170h+b] ; b
mov ecx, [rbp+170h+a] ; a
call j_?add@@YAHHHHH@Z ; add(int,int,int,int)
mov [rbp+84h], eax
xor eax, eax
lea rsp, [rbp+168h]
pop rdi
pop rbp
retn
main endp
我们继续介绍FastCall调用约定:push和pop指令仅用来保存非易变寄存器,其他栈指针操作显式写寄存器rsp。实现进入call之前rsp满足0×10字节对齐。
通常不使用rbp寻址栈内存,所以rsp在函数帧中尽量保持稳定,一次性分配局部变量和参数空间但是。在咱的实例中,用到了rbp寻址,但在使用过程中rsp保持比较稳定的状态。
上面的介绍仅仅是冰山一角,让你对64位的汇编指令和调用约定有一个整体的认识,具体细节请自行探索。
SEH
概述
之前我们在32位介绍SEH的时候,它是用栈实现的,但是如果黑客利用构造特殊的代码对栈进行攻击导致代码劫持,这是十分不安全的。所以,在64位下,SEH不使用栈来实现。对于64位来说,函数有没有异常处理程序的执行效率是一样的,因为它并没有类似32位挂SEH的操作。我们通过代码示例看一下:
#include
using namespace std;
int filter()
{
return 1;
}
int main()
{
__try
{
cout << "try1" << endl;
__try
{
cout << "try2" << endl;
__try
{
cout << "try3" << endl;
}
__finally
{
cout << "finally" << endl;
}
}
__except (filter())
{
cout << "except filter" << endl;
}
}
__except (1)
{
cout << "except 1" << endl;
}
return 0;
}
它的反汇编如下:
int main()
{
00007FF72C6222C0 push rbp
00007FF72C6222C2 push rdi
00007FF72C6222C3 sub rsp,0E8h
00007FF72C6222CA lea rbp,[rsp+20h]
__try
{
cout << "try1" << endl;
00007FF72C6222CF lea rdx,[string "try1" (07FF72C62AC24h)]
00007FF72C6222D6 mov rcx,qword ptr [__imp_std::cout (07FF72C631198h)]
00007FF72C6222DD call std::operator<< > (07FF72C62108Ch)
00007FF72C6222E2 lea rdx,[std::endl > (07FF72C62103Ch)]
00007FF72C6222E9 mov rcx,rax
00007FF72C6222EC call qword ptr [__imp_std::basic_ostream >::operator<< (07FF72C6311B0h)]
00007FF72C6222F2 nop
__try
{
cout << "try2" << endl;
00007FF72C6222F3 lea rdx,[string "try2" (07FF72C62AC2Ch)]
00007FF72C6222FA mov rcx,qword ptr [__imp_std::cout (07FF72C631198h)]
00007FF72C622301 call std::operator<< > (07FF72C62108Ch)
00007FF72C622306 lea rdx,[std::endl > (07FF72C62103Ch)]
00007FF72C62230D mov rcx,rax
00007FF72C622310 call qword ptr [__imp_std::basic_ostream >::operator<< (07FF72C6311B0h)]
00007FF72C622316 nop
__try
{
cout << "try3" << endl;
00007FF72C622317 lea rdx,[string "try3" (07FF72C62AC34h)]
00007FF72C62231E mov rcx,qword ptr [__imp_std::cout (07FF72C631198h)]
00007FF72C622325 call std::operator<< > (07FF72C62108Ch)
00007FF72C62232A lea rdx,[std::endl > (07FF72C62103Ch)]
00007FF72C622331 mov rcx,rax
00007FF72C622334 call qword ptr [__imp_std::basic_ostream >::operator<< (07FF72C6311B0h)]
00007FF72C62233A nop
}
__finally
{
cout << "finally" << endl;
00007FF72C62233B lea rdx,[string "finally" (07FF72C62AC40h)]
00007FF72C622342 mov rcx,qword ptr [__imp_std::cout (07FF72C631198h)]
00007FF72C622349 call std::operator<< > (07FF72C62108Ch)
00007FF72C62234E lea rdx,[std::endl > (07FF72C62103Ch)]
00007FF72C622355 mov rcx,rax
00007FF72C622358 call qword ptr [__imp_std::basic_ostream >::operator<< (07FF72C6311B0h)]
}
}
00007FF72C62235E jmp main+0C4h (07FF72C622384h)
__except (filter())
{
cout << "except filter" << endl;
00007FF72C622360 lea rdx,[string "except filter" (07FF72C62AC50h)]
00007FF72C622367 mov rcx,qword ptr [__imp_std::cout (07FF72C631198h)]
00007FF72C62236E call std::operator<< > (07FF72C62108Ch)
00007FF72C622373 lea rdx,[std::endl > (07FF72C62103Ch)]
00007FF72C62237A mov rcx,rax
00007FF72C62237D call qword ptr [__imp_std::basic_ostream >::operator<< (07FF72C6311B0h)]
00007FF72C622383 nop
}
}
00007FF72C622384 jmp $LN8+24h (07FF72C6223AAh)
__except (1)
{
cout << "except 1" << endl;
00007FF72C622386 lea rdx,[string "except 1" (07FF72C62AC60h)]
00007FF72C62238D mov rcx,qword ptr [__imp_std::cout (07FF72C631198h)]
00007FF72C622394 call std::operator<< > (07FF72C62108Ch)
00007FF72C622399 lea rdx,[std::endl > (07FF72C62103Ch)]
00007FF72C6223A0 mov rcx,rax
00007FF72C6223A3 call qword ptr [__imp_std::basic_ostream >::operator<< (07FF72C6311B0h)]
00007FF72C6223A9 nop
}
return 0;
00007FF72C6223AA xor eax,eax
}
00007FF72C6223AC lea rsp,[rbp+0C8h]
00007FF72C6223B3 pop rdi
00007FF72C6223B4 pop rbp
00007FF72C6223B5 ret
可以看出生成的代码和我们认为的普通代码没什么两样,每一个对应的异常处理程序前都会用jmp跳过,感觉十分奇怪。那么64位是如何实现异常的SEH处理的呢?
为了方便介绍,我们把编译后的程序放到IDA里面,将会得到如下结果:
; int __fastcall main()
main proc near ; CODE XREF: j_main↑j
; DATA XREF: .pdata:000000014001F89C↓o
; __unwind { // j___C_specific_handler_0
push rbp
push rdi
sub rsp, 0E8h
lea rbp, [rsp+20h]
lea rdx, _Val ; "try1"
mov rcx, cs:__imp_?cout@std@@3V?$basic_ostream@DU?$char_traits@D@std@@@1@A ; _Ostr
call j_??$?6U?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@PEBD@Z ; std::operator<<>(std::ostream &,char const *)
lea rdx, j_??$endl@DU?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@@Z ; std::endl>(std::ostream &)
mov rcx, rax
call cs:__imp_??6?$basic_ostream@DU?$char_traits@D@std@@@std@@QEAAAEAV01@P6AAEAV01@AEAV01@@Z@Z ; std::ostream::operator<<(std::ostream & (*)(std::ostream &))
nop
lea rdx, aTry2 ; "try2"
mov rcx, cs:__imp_?cout@std@@3V?$basic_ostream@DU?$char_traits@D@std@@@1@A ; _Ostr
call j_??$?6U?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@PEBD@Z ; std::operator<<>(std::ostream &,char const *)
lea rdx, j_??$endl@DU?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@@Z ; std::endl>(std::ostream &)
mov rcx, rax
call cs:__imp_??6?$basic_ostream@DU?$char_traits@D@std@@@std@@QEAAAEAV01@P6AAEAV01@AEAV01@@Z@Z ; std::ostream::operator<<(std::ostream & (*)(std::ostream &))
nop
lea rdx, aTry3 ; "try3"
mov rcx, cs:__imp_?cout@std@@3V?$basic_ostream@DU?$char_traits@D@std@@@1@A ; _Ostr
call j_??$?6U?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@PEBD@Z ; std::operator<<>(std::ostream &,char const *)
lea rdx, j_??$endl@DU?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@@Z ; std::endl>(std::ostream &)
mov rcx, rax
call cs:__imp_??6?$basic_ostream@DU?$char_traits@D@std@@@std@@QEAAAEAV01@P6AAEAV01@AEAV01@@Z@Z ; std::ostream::operator<<(std::ostream & (*)(std::ostream &))
nop
$LN18:
lea rdx, aFinally ; "finally"
mov rcx, cs:__imp_?cout@std@@3V?$basic_ostream@DU?$char_traits@D@std@@@1@A ; _Ostr
call j_??$?6U?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@PEBD@Z ; std::operator<<>(std::ostream &,char const *)
lea rdx, j_??$endl@DU?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@@Z ; std::endl>(std::ostream &)
mov rcx, rax
call cs:__imp_??6?$basic_ostream@DU?$char_traits@D@std@@@std@@QEAAAEAV01@P6AAEAV01@AEAV01@@Z@Z ; std::ostream::operator<<(std::ostream & (*)(std::ostream &))
jmp short loc_140012384
; ---------------------------------------------------------------------------
$LN12:
lea rdx, aExceptFilter ; "except filter"
mov rcx, cs:__imp_?cout@std@@3V?$basic_ostream@DU?$char_traits@D@std@@@1@A ; _Ostr
call j_??$?6U?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@PEBD@Z ; std::operator<<>(std::ostream &,char const *)
lea rdx, j_??$endl@DU?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@@Z ; std::endl>(std::ostream &)
mov rcx, rax
call cs:__imp_??6?$basic_ostream@DU?$char_traits@D@std@@@std@@QEAAAEAV01@P6AAEAV01@AEAV01@@Z@Z ; std::ostream::operator<<(std::ostream & (*)(std::ostream &))
nop
loc_140012384: ; CODE XREF: main+9E↑j
jmp short loc_1400123AA
; ---------------------------------------------------------------------------
$LN8:
lea rdx, aExcept1 ; "except 1"
mov rcx, cs:__imp_?cout@std@@3V?$basic_ostream@DU?$char_traits@D@std@@@1@A ; _Ostr
call j_??$?6U?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@PEBD@Z ; std::operator<<>(std::ostream &,char const *)
lea rdx, j_??$endl@DU?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@@Z ; std::endl>(std::ostream &)
mov rcx, rax
call cs:__imp_??6?$basic_ostream@DU?$char_traits@D@std@@@std@@QEAAAEAV01@P6AAEAV01@AEAV01@@Z@Z ; std::ostream::operator<<(std::ostream & (*)(std::ostream &))
nop
loc_1400123AA: ; CODE XREF: main:loc_140012384↑j
xor eax, eax
lea rsp, [rbp+0C8h]
pop rdi
pop rbp
retn
; } // starts at 1400122C0
main endp
有关SEH异常处理的信息放在了PE结构的Exception目录,如果对该方面一点不清楚的同志请学习 羽夏笔记——PE结构(不包含.Net) ,否则下面的介绍可能对你来说意义不太大。
RUNTIME_FUNCTION
在64位下,每一个非叶函数(叶函数就是既不调用函数,又没有修改栈指针,也没有使用SEH的函数)都有一个结构体来描述该函数的SEH处理信息,那就是RUNTIME_FUNCTION,它的结构如下:
typedef struct _RUNTIME_FUNCTION {
ULONG BeginAddress;
ULONG EndAddress;
ULONG UnwindData;
} RUNTIME_FUNCTION, *PRUNTIME_FUNCTION;
第一个成员标志着开始RVA,第二个成员标志的是结束RVA。我们来看看main函数的RUNTIME_FUNCTION:
RUNTIME_FUNCTION
IDA帮我们给识别好了,我们来看看它的硬编码:
C0 22 01 00 B6 23 01 00 00 C6 01 00
为了配合讲解,我们把主函数的开始地址和结束地址看一下:
.text:00000001400122C0 ; int __fastcall main()
.text:00000001400122C0 main proc near ; CODE XREF: j_main↑j
.text:00000001400122C0 ; DATA XREF: .pdata:000000014001F89C↓o
.text:00000001400122C0 ; __unwind { // j___C_specific_handler_0
……
.text:00000001400123B5 main endp
.text:00000001400123B5
.text:00000001400123B5 ; ---------------------------------------------------------------------------
.text:00000001400123B6 byte_1400123B6 db 3Dh dup(0CCh) ; DATA XREF: .pdata:000000014001F89C↓o
也就是说,第一个成员的值就是0x122C0,正好是我们程序的偏移(镜像加载的地址为0x140000000),第二个成员的值是0x123B6也就是结束的位置偏移。
还有一个成员我们并没有介绍,那就是UnwindData,它其实是一个结构体,装着异常发生时栈的回滚信息,如下所示:
typedef struct _UNWIND_INFO {
UCHAR Version : 3;
UCHAR Flags : 5;
UCHAR SizeOfProlog;
UCHAR CountOfCodes;
UCHAR FrameRegister : 4;
UCHAR FrameOffset : 4;
UNWIND_CODE UnwindCode[1];
//
// The unwind codes are followed by an optional DWORD aligned field that
// contains the exception handler address or a function table entry if
// chained unwind information is specified. If an exception handler address
// is specified, then it is followed by the language specified exception
// handler data.
//
// union {
// struct {
// ULONG ExceptionHandler;
// ULONG ExceptionData[];
// };
//
// RUNTIME_FUNCTION FunctionEntry;
// };
//
} UNWIND_INFO, *PUNWIND_INFO;
UNWIND_INFO
该结构前两个成员是个位域,占用一个UCHAR大小。第一个成员是版本号,目前都是1,第二个成员是比较重要的成员,它标志了它的类型,我们来看看:
#define UNW_FLAG_NHANDLER 0x0
#define UNW_FLAG_EHANDLER 0x1
#define UNW_FLAG_UHANDLER 0x2
#define UNW_FLAG_CHAININFO 0x4
可以看到有四种类型,下面我们来看看它们的含义。
UNW_FLAG_NHANDLER
表示既没有EXCEPT_FILTER也没有EXCEPT_HANDLER,这个是最简单的类型,它的示意图如下:

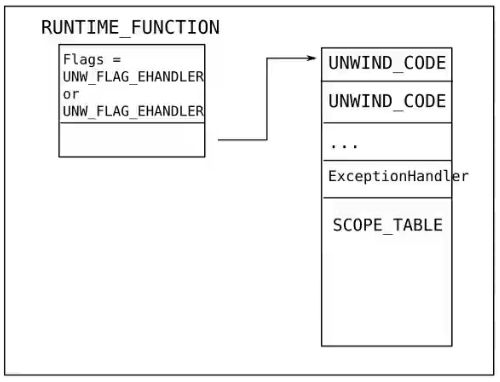
UNW_FLAG_EHANDLER
表示该函数有EXCEPT_FILTER和EXCEPT_HANDLER,示意图如下:
UNW_FLAG_UHANDLER
表示该函数有FINALLY_HANDLER,它的结构如下:
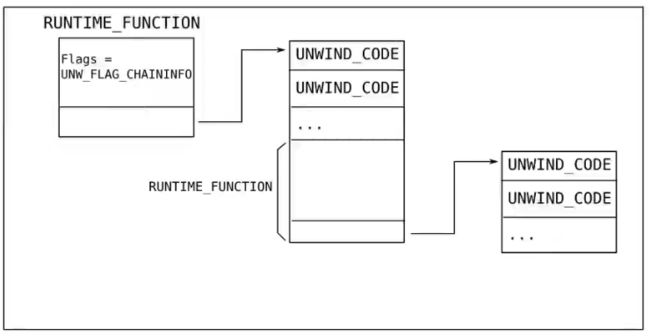
UNW_FLAG_CHAININFO
表示该函数有多个UNWIND_INFO并串接在一起。
SizeOfProlog
表示该函数的Prolog指令的大小,单位是字节。
CountOfCodes
表示当前UNWIND_INFO包含多少个UNWIND_CODE结构。
FrameRegister
如果函数建立了栈帧,它表示栈帧的索引,否则为0.
FrameOffset
表示FrameRegister距离函数最初栈顶(刚进入函数,还没有执行任何指令时的栈顶)的偏移,单位为字节。
UnwindCode
是一个UNWIND_CODE类型的不定长数组,元素数量由CountOfCodes决定。
这里在说明几点:如果Flags设置了UNW_FLAG_EHANDLER或UNW_FLAG_UHANDLER,那么在最后一个UNWIND_CODE之后存放着ExceptionHandler,它相当于 x86的EXCEPTION_REGISTRATION::handle以及ExceptionData它相当于x86的EXCEPTION_REGISTRATION::scopetable。UnwindCode数组详细记录了函数修改栈、保存非易失性寄存器的指令。
UNWIND_CODE
下面我们来看看UNWIND_CODE结构体:
typedef enum _UNWIND_OP_CODES {
UWOP_PUSH_NONVOL = 0,
UWOP_ALLOC_LARGE, // 1
UWOP_ALLOC_SMALL, // 2
UWOP_SET_FPREG, // 3
UWOP_SAVE_NONVOL, // 4
UWOP_SAVE_NONVOL_FAR, // 5
UWOP_SPARE_CODE1, // 6
UWOP_SPARE_CODE2, // 7
UWOP_SAVE_XMM128, // 8
UWOP_SAVE_XMM128_FAR, // 9
UWOP_PUSH_MACHFRAME // 10
} UNWIND_OP_CODES, *PUNWIND_OP_CODES;
typedef union _UNWIND_CODE {
struct {
UCHAR CodeOffset;
UCHAR UnwindOp : 4;
UCHAR OpInfo : 4;
};
USHORT FrameOffset;
} UNWIND_CODE, *PUNWIND_CODE;
由于我们这里是知识铺垫,具体细节就不去追究了,感兴趣的可以自行探索。
下一篇
x64 番外篇——保护模式相关