1. 背景
OnZoom是Zoom新产品,是基于Zoom Meeting的一个独一无二的在线活动平台和市场。作为Zoom统一通信平台的延伸,OnZoom是一个综合性解决方案,为付费的Zoom用户提供创建、主持和盈利的活动,如健身课、音乐会、站立表演或即兴表演,以及Zoom会议平台上的音乐课程。
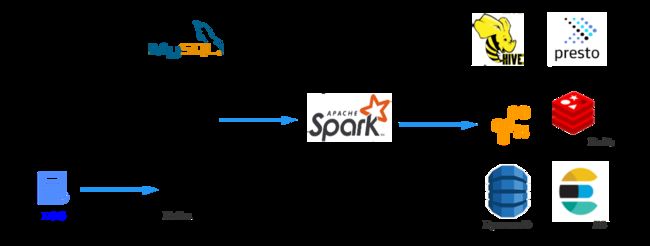
在OnZoom data platform中,source数据主要分为MySQL DB数据和Log数据。 其中Kafka数据通过Spark Streaming job实时消费,MySQL数据通过Spark Batch job定时同步, 将source数据Sink到AWS S3。之后定时调度Spark Batch Job进行数仓开发。最终按照实际业务需求或使用场景将数据Sink到合适的存储。
初版架构问题
- MySQL通过sql方式获取数据并同步到S3是离线处理,并且某些场景下(比如物理删除)只能每次全量同步
- Spark Streaming job sink到S3需要处理小文件问题
- 默认S3存储方式不支持CDC(Change Data Capture),所以只支持离线数仓
- 因为安全要求,有时需求删除或更新某个客户数据时,只能全量(或指定分区)计算并overwrite。性能较差
2. 架构优化升级
基于以上问题,我们在进行大量技术调研选型及POC之后,我们主要做了如下2部分大的架构优化升级。
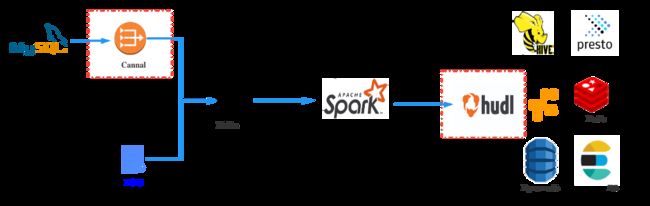
2.1 Canal
MySQL Binlog即二进制日志,它记录了MySQL所有表结构和表数据变更。
Cannal基于MySQL Binlog日志解析,提供增量数据订阅和消费,将数据Sink到Kafka实现CDC。
后续使用Spark Streaming job实时消费Binlog就能解决上述问题1的时效性以及物理删除等问题。
2.2 Apache Hudi
我们需要有一种能够兼容S3存储之后,既支持大量数据的批处理又支持增加数据的流处理的数据湖解决方案。最终我们选择Hudi作为我们数据湖架构方案,主要原因如下:
- Hudi通过维护索引支持高效的记录级别的增删改
- Hudi维护了一条包含在不同的即时时间(instant time)对数据集做的所有instant操作的timeline,可以获取给定时间内的CDC数据(增量查询)。也提供了基于最新文件的Raw Parquet 读优化查询。从而实现流批一体架构而不是典型的Lambda架构。
- Hudi智能自动管理文件大小,而不用用户干预就能解决小文件问题
- 支持S3存储,支持Spark、Hive、Presto查询引擎,入门成本较低只需引入对应Hudi package
3. Hudi 实践经验分享
Hudi upsert 时默认PAYLOAD_CLASS_OPT_KEY为OverwriteWithLatestAvroPayload,该方式upsert时会将所有字段都更新为当前传入的DataFrame。但很多场景下可能只想更新其中某几个字段,其他字段跟已有数据保持一致,此时需要将PAYLOAD_CLASS_OPT_KEY传为OverwriteNonDefaultsWithLatestAvroPayload,将不需要更新的字段设为null。但该upsert方式也有一定限制,比如不能将某个值更新为null。
我们现在有实时同步数据,离线rerun数据的场景,但当前使用的是Hudi 0.7.0版本,该版本还不支持多个job并发写Hudi表。临时方案是每次需要rerun数据的时候暂停实时任务,因为0.8.0版本已经支持并发写,后续考虑升级。
一开始我们任务变更Hudi表数据时每次都默认同步hive元数据。但对于实时任务每次连接Hive Metastore更新元数据很浪费资源,因为大部分操作只涉及到数据变更而不涉及表结构或者分区变动。所以我们后来将实时任务关闭同步hive元数据,在需要更新元数据时另外再执行hudi-hive-sync-bundle-*.jar来同步。
Hudi增量查询语义是返回给定时间内所有的变更数据,所以会在timeline在里查找历史所有commits文件。但历史commits文件会根据retainCommits参数被清理,所以如果给定时间跨度较大时可能会获取不到完整的变更数据。如果只关心数据的最终状态,可以根据_hoodie_commit_time来过滤获取增量数据。
Hudi默认spark分区并行度withParallelism为1500,需要根据实际的输入数据大小调整合适的shuffle并行度。(对应参数为 hoodie.[insert|upsert|bulkinsert].shuffle.parallelism)
Hudi基于parquet列式存储,支持向后兼容的schema evolution,但只支持新的DataFrame增加字段的schema变更,预计在在 0.10 版本实现 full schema evolution。如果有删除或重命名字段的需求,只能overwrite。另外增加字段也可能导致hive sync metadata失败,需要先在hive执行drop table。
Hudi Insert 对 recordKey 相同的数据,根据不同的参数有不同的处理情况,决定性的参数包括以下三个:
hoodie.combine.before.insert
hoodie.parquet.small.file.limit
hoodie.merge.allow.duplicate.on.inserts
其中:hoodie.combine.before.insert 决定是否对同一批次的数据按 recordKey 进行合并,默认为 false;hoodie.parquet.small.file.limit 和hoodie.merge.allow.duplicate.on.inserts 控制小文件合并阈值和如何进行小文件合并。如果 hoodie.parquet.small.file.limit > 0 并且 hoodie.merge.allow.duplicate.on.inserts 为 false,那么在小文件合并的时候,会对相同 recordKey 的数据进行合并。此时有概率发生去重的情况 (如果相同 recordKey 的数据写入同一文件中);如果 hoodie.parquet.small.file.limit > 0 并且 hoodie.merge.allow.duplicate.on.inserts 为 true,那么在小文件合并的时候,不会处理相同 recordKey 的数据
4. 总结
我司基于Hudi实现流批一体数据湖架构上线生产环境已有半年多时间,在引入Hudi之后我们在以下各个方面都带来了一定收益:
- 成本: 引入Hudi数据湖方案之后,实现了S3数据增量查询和增量更新删除,之前更新删除方案只能全表overwrite。Hudi实现智能小文件合并,之前需要单独任务去处理。在数据处理和存储方面都节约了相应成本,预估节省1/4费用。
- 时效性: 所有ODS表已从T+1改造为Near Real Time。后续会建设更多实时表。
- 效率: 在插入及更新数据时,默认情况下,Hudi使用Bloom Index,该索引更适合单调递增record key,相比于原始Spark Join,其速度最高可提高10倍。查询数据时,借助Hudi提供的Clustering(将文件按照某些列进行聚簇,以重新布局,达到优化查询性能的效果),Compaction(将基础文件和增量日志文件进行合并,生成新版本列存文件)等服务,可将查询性能提升50%+。
以上就是OnZoom基于Apache Hudi的一体架构实践 的详细内容,更多关于OnZoom基于Apache Hudi架构的资料请关注脚本之家其它相关文章!