背景
一直对语音合成系统比较感兴趣,总想能给自己合成一点内容,比如说合成小说,把我下载的电子书播报给我听等等。
语音合成系统
其实就是一个基于语音合成的工具,但是这个东西由于很多厂家都提供了API的形式,因此开发难度大大降低,只需要调用几个API即可实现属于自己的语音合成工具;麻雀虽小,五脏俱全。往大了说,这就是一个小型的语音合成系统。
准备工作
首先我们电脑上需要安装
- Anaconda
- Python 3.7
- visual studio code
步骤
这里我们选用讯飞开放平台的WebAPI接口。
首先我们到控制台创建一个应用

创建好了之后,点击该应用进入,有该应用的详细栏目。
点击左侧的语音合成,再到下一级在线语音合成(流式版)
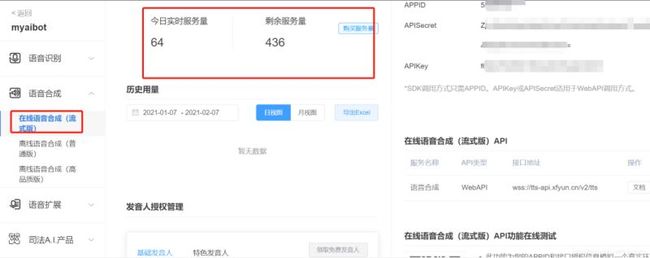
在右上侧,我们需要拿到3个东西:
- APPID
- APISecret
- APIKey
代码实现
好了接下来进行代码实现了,首先安装我们需要的两个库。
pip install websocket-client pip install playsound
接下来我们定义一个类play,包含4个函数
class play: def __init__(self): #初始化函数 def play_sound(self):#播放音频函数 def select_vcn(self,*arg):#选择下拉框设置发音人 def xfyun_tts(self):#进行语音合成
在这里,大家需要填上刚才从讯飞开放平台控制台获取到的appid、appkey以及appsecret
def __init__(self):
self.APP_ID = 'xxx' #请填上自己的appid
self.API_KEY = 'xxx' #请填上自己的appkey
self.SECRET_KEY = 'xxx' #请填上自己的appsecret
self.root=tk.Tk() #初始化窗口
self.root.title("语音合成系统") #窗口名称
self.root.geometry("600x550") #设置窗口大小
self.root.resizable(0,0)
#self.root.resizable(width=True,height=True)#设置窗口是否可变,宽不可变,高可变,默认为True
self.lb=tk.Label(self.root,text='请选择语音发音人')#标签
self.tt=tk.Text(self.root,width=77,height=30) #多行文本框
self.cb=ttk.Combobox(self.root, width=12) #下拉列表框
#设置下拉列表框的内容
self.cb['values']=("甜美女声-小燕","亲切男声-许久","知性女声-小萍", "可爱童声-许小宝","亲切女声-小婧")
self.cb.current(0) #将当前选择状态置为0,也就是第一项
self.cb.bind("<>", self.select_vcn)
self.tk_tts_file=tk.Label(self.root,text='生成文件名')
self.b1=tk.Button(self.root, text='进行语音合成', width=10,height=1,command=self.xfyun_tts) #按钮
self.tk_play=tk.Button(self.root, text='播放', width=10,height=1,command=self.play_sound) #按钮
#各个组件的位置
self.tk_tts_file.place(x=30,y=500)
self.b1.place(x=300,y=500)
self.tk_play.place(x=400,y=500)
self.lb.place(x=30,y=30)
self.cb.place(x=154,y=30)
self.tt.place(x=30,y=60)
self.root.mainloop()
当选择了下拉列表,设置对应的发音人
def select_vcn(self,*arg):
if self.cb.get()=='甜美女声-小燕':
self.vcn="xiaoyan"
elif self.cb.get()=='亲切男声-许久':
self.vcn="aisjiuxu"
elif self.cb.get()=='知性女声-小萍':
self.vcn="aisxping"
elif self.cb.get()=='可爱童声-许小宝':
self.vcn="aisbabyxu"
elif self.cb.get()=='亲切女声-小婧':
self.vcn="aisjinger"
print(self.vcn)
接下来我们来魔改讯飞自带的Python demo为从而更加方便的来使用
# -*- coding:utf-8 -*-
#
# author: iflytek
#
# 本demo测试时运行的环境为:Windows + Python3.7
# 本demo测试成功运行时所安装的第三方库及其版本如下:
# cffi==1.12.3
# gevent==1.4.0
# greenlet==0.4.15
# pycparser==2.19
# six==1.12.0
# websocket==0.2.1
# websocket-client==0.56.0
# 合成小语种需要传输小语种文本、使用小语种发音人vcn、tte=unicode以及修改文本编码方式
# 错误码链接:https://www.xfyun.cn/document/error-code (code返回错误码时必看)
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
import websocket
import datetime
import hashlib
import base64
import hmac
import json
from urllib.parse import urlencode
import time
import ssl
from wsgiref.handlers import format_date_time
from datetime import datetime
from time import mktime
import _thread as thread
import os
import wave
STATUS_FIRST_FRAME = 0 # 第一帧的标识
STATUS_CONTINUE_FRAME = 1 # 中间帧标识
STATUS_LAST_FRAME = 2 # 最后一帧的标识
PCM_PATH = "./demo.pcm"
class Ws_Param(object):
# 初始化
def __init__(self):
pass
def set_tts_params(self, text, vcn):
if text != "":
self.Text = text
if vcn != "":
self.vcn = vcn
# 业务参数(business),更多个性化参数可在官网查看
self.BusinessArgs = {"bgs":1,"aue": "raw", "auf": "audio/L16;rate=16000", "vcn": self.vcn, "tte": "utf8"}
#使用小语种须使用以下方式,此处的unicode指的是 utf16小端的编码方式,即"UTF-16LE"”
#self.Data = {"status": 2, "text": str(base64.b64encode(self.Text.encode('utf-16')), "UTF8")}
self.Data = {"status": 2, "text": str(base64.b64encode(self.Text.encode('utf-8')), "UTF8")}
def set_params(self, appid, apiSecret, apiKey):
if appid != "":
self.APPID = appid
# 公共参数(common)
self.CommonArgs = {"app_id": self.APPID}
if apiKey != "":
self.APIKey = apiKey
if apiSecret != "":
self.APISecret = apiSecret
# 生成url
def create_url(self):
url = 'wss://tts-api.xfyun.cn/v2/tts'
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + "ws-api.xfyun.cn" + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + "/v2/tts " + "HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (
self.APIKey, "hmac-sha256", "host date request-line", signature_sha)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": "ws-api.xfyun.cn"
}
url = url + '?' + urlencode(v)
return url
def on_message(ws, message):
try:
#print(message)
try:
message =json.loads(message)
except Exception as e:
print("111",e)
code = message["code"]
sid = message["sid"]
audio = message["data"]["audio"]
audio = base64.b64decode(audio)
status = message["data"]["status"]
print(code, sid, status)
if status == 2:
print("ws is closed")
ws.close()
if code != 0:
errMsg = message["message"]
print("sid:%s call error:%s code is:%s" % (sid, errMsg, code))
else:
with open(PCM_PATH, 'ab') as f:
f.write(audio)
except Exception as e:
print("receive msg,but parse exception:", e)
# 收到websocket错误的处理
def on_error(ws, error):
print("### error:", error)
# 收到websocket关闭的处理
def on_close(ws):
print("### closed ###")
# 收到websocket连接建立的处理
def on_open(ws):
def run(*args):
d = {"common": wsParam.CommonArgs,
"business": wsParam.BusinessArgs,
"data": wsParam.Data,
}
d = json.dumps(d)
print("------>开始发送文本数据")
ws.send(d)
if os.path.exists(PCM_PATH):
os.remove(PCM_PATH)
thread.start_new_thread(run, ())
def text2pcm(appid, apiSecret, apiKey, text, vcn, fname):
wsParam.set_params(appid, apiSecret, apiKey)
wsParam.set_tts_params(text, vcn)
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
ws.on_open = on_open
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
pcm2wav(PCM_PATH, fname)
def pcm2wav(fname, dstname):
with open(fname, 'rb') as pcmfile:
pcmdata = pcmfile.read()
print(len(pcmdata))
with wave.open(dstname, "wb") as wavfile:
wavfile.setparams((1, 2, 16000, 0, 'NONE', 'NONE'))
wavfile.writeframes(pcmdata)
wsParam = Ws_Param()
最终一个语音合成系统就这样实现了。
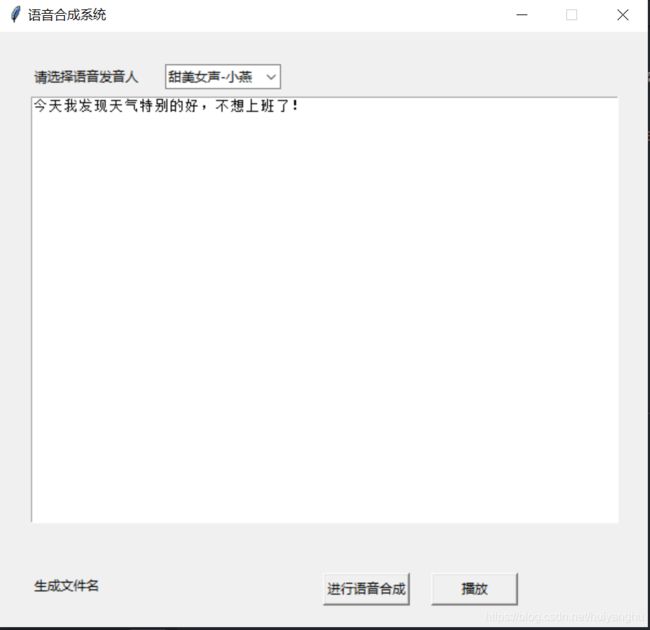
当前,各种云计算、云服务迅速发展,各大公司提供了丰富的资源,大大降低了人工智能开发的门槛,不需要懂语音合成的原理,竟然可以快速开发出一个语音合成工具出来!
到此这篇关于基于Python编写一个语音合成系统的文章就介绍到这了,更多相关Python语音合成内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!