深度学习经典网络实现与分析 —— VGGNet
代码地址
https://github.com/xmy0916/DLNetwork
简介
参考:https://blog.csdn.net/weixin_42546496/article/details/87915453
VGGNet论文给出了一个非常振奋人心的结论:卷积神经网络的深度增加和小卷积核的使用对网络的最终分类识别效果有很大的作用。
VGGNet由牛津大学的视觉几何组(Visual Geometry Group)和 Google DeepMind公司的研究员一起研发的的深度卷积神经网络,在 ILSVRC 2014 上取得了第二名的成绩,将 Top-5错误率降到7.3%。目前使用比较多的网络结构主要有ResNet(152-1000层),GooleNet(22层),VGGNet(19层),大多数模型都是基于这几个模型上改进,采用新的优化算法,多模型融合等。到目前为止,VGG Net 依然经常被用来提取图像特征。
重点
- 使用更多小size的卷积核。
- 使用简单网络训练好的参数初始化复杂网络。
- 采用了Multi-Scale的方法来训练和预测。
更多小size的卷积核
AlexNet中使用的卷积核有11 * 11、5 * 5 、3 * 3的大小。在VGGNet中每层卷积层中包含2~4个卷积操作,卷积核的大小是3 *3 ,卷积步长是1,池化核是2 * 2,步长为2,。VGGNet最明显的改进就是降低了卷积核的尺寸,增加了卷积的层数。
2个3x3卷积堆叠等于1个5x5卷积,3个3x3堆叠等于1个7x7卷积,感受野大小不变,而采用更多层、更小的卷积核可以引入更多非线性(更多的隐藏层,从而带来更多非线性函数),提高决策函数判决力,并且带来更少参数。

使用简单网络训练好的参数初始化复杂网络
训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度。
Multi-Scale
首先对原始图片进行等比例缩放,使得短边要大于224,然后在图片上随机提取224x224窗口,进行训练。由于物体尺度变化多样,所以多尺度(Multi-scale)可以更好地识别物体。
- 方法1:在不同的尺度下,训练多个分类器:
参数S为短边长。训练S=256和S=384两个分类器,其中S=384的分类器用S=256的进行初始化,且将步长调为10e-3 - 方法2:直接训练一个分类器,每次数据输入的时候,每张图片被重新缩放,缩放的短边S随机从[256,512]中选择一个。
Multi-scale其实本身不是一个新概念,学过图像处理的同学都知道,图像处理中已经有这个概念了,我们学过图像金字塔,那就是一种多分辨率操作。
只不过VGG网络第一次在神经网络的训练过程中提出也要来搞多尺寸。目的是为了提取更多的特征信息。像后来做分割的网络如DeepLab也采用了图像金字塔的操作。
注: 因为训练数据的输入为224x224,从而图像的最小边S,不应该小于224
在训练中,VGGNet还使用了Multi-Scale的方法做数据增强,将原始图像缩放到不同尺寸S,然后再随机裁切224*224的图片,这样能增加很多数据量,对于防止模型过拟合有很不错的效果。
实践中,作者令S在[256,512]这个区间内取值,比固定的S=256与S=512的结果显著提升,使用Multi-Scale获得多个版本的数据,并将多个版本的数据合在一起进行训练。
multi-scale训练确实很有用,因为卷积网络对于缩放有一定的不变性,通过multi-scale训练可以增加这种不变性的能力。
参考:https://blog.csdn.net/weixin_42535423/article/details/103700277
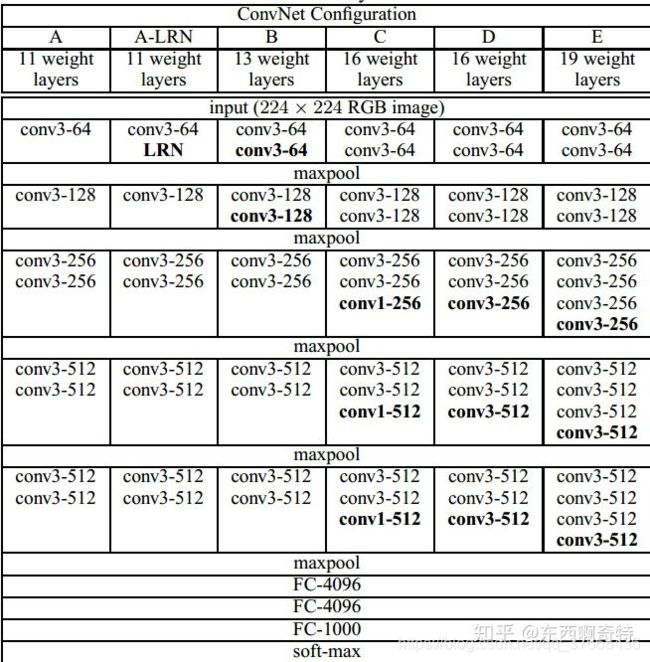
结构

代码
实现参考pytorch官方vgg代码:https://github.com/pytorch/vision/tree/master/torchvision/models
项目地址:
https://github.com/xmy0916/DLNetwork
class VGG(nn.Module):
def __init__(
self,
features: nn.Module,
num_classes: int = 1000,
init_weights: bool = True
) -> None:
super(VGG, self).__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _initialize_weights(self) -> None:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
运行命令:
python3 train.py --model vggnet
配置文件如下:
"vggnet": {
"model": VggNet,
"name": "vgg16",
"pretrained": True,
"epoch": 5,
"num_class": 10,
"save_path": "params/vgg.pth",
"input_size": (112, 112), # 224跑不动...
"batch_size": (8, 1000),
"lr": 0.0001
}
name参数一共支持:
list = [
'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn',
'vgg19_bn', 'vgg19']
注意一点论文的inputsize是224,224这个跑起来服务器12G的显存就爆了,改了112可以跑动