pytorch实现手写数字识别 | MNIST数据集(全连接神经网络)
文章目录
- 代码
- 相关说明
-
- 1. 关于MNIST数据集
- 2. 关于二分类与多分类
- 3. 关于神经网络处理过程
- 4. softmax函数
- 5. 关于MNIST数据集的处理举例
- 6. 代码流程
- 7. 关于transforms.ToTensor
- 8. 关于transforms.Normalize
- 9.代码中transform的对应关系
- 10. 关于x.view
- 11. 设计模型
- 12. batch size设置技巧 谈谈batchsize参数
- 13. 关于x.view(-1, 784)
- 14. 关于torch.nn.Linear和relu的举例测试
学习课程: 《PyTorch深度学习实践》完结合集
大佬的专栏笔记: bit452的专栏:PyTorch 深度学习实践
注:本文对应P9,还未使用CNN
代码
import torch
from torchvision import transforms # 对图像进行原始的数据处理的工具
from torchvision import datasets # 获取数据
from torch.utils.data import DataLoader # 加载数据
import torch.nn.functional as F # 与全连接层中的relu激活函数 有关
import torch.optim as optim # 与优化器有关
# prepare dataset
batch_size = 64
# GPU对2的幂次的batch可以发挥更佳的性能,因此设置成16、32、64、128…时往往要比设置为整10、整100的倍数时表现更优
# 在神经网络训练时,常常需要采用批输入数据的方法,为此需要设定每次输入的批数据大小batch_size
transform = transforms.Compose([ # 处理图像
transforms.ToTensor(), # Convert the PIL Image to Tensor
transforms.Normalize((0.1307,), (0.3081,)) # 归一化;0.1307为均值,0.3081为标准差
])
train_dataset = datasets.MNIST(root='./dataset/mnist/', train=True, download=True, transform=transform)
# download=True表示自动下载MNIST数据集(建议科学上网,不然速度很慢,而且可能下载中断)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='./dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
class Net(torch.nn.Module): # design model using class
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784) # -1其实就是自动获取mini_batch
# Tensor.view(*shape) → Tensor:Returns a new tensor with the same data as the self tensor but of a different shape.
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层不做激活,不进行非线性变换
model = Net()
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss() # 构建损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# lr (float) – learning rate学习率 ; momentum (float, optional) – momentum factor (default: 0)动量因子 (默认: 0)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
# 获得一个批次的数据和标签
inputs, target = data
optimizer.zero_grad()
# 获得模型预测结果(64, 10)
outputs = model(inputs)
# 交叉熵代价函数outputs(64,10),target(64)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299: # batch_idx最大值为937;937*64=59968 意味着丢弃了部分的样本
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
# 注:在python中,通过使用%,实现格式化字符串的目的;%d 有符号整数(十进制)
running_loss = 0.0
def test():
correct = 0 # 正确预测的数量
total = 0 # 总数量
with torch.no_grad(): # 测试的时候不需要计算梯度(避免产生计算图)
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度
total += labels.size(0)
correct += (predicted == labels).sum().item() # 张量之间的比较运算
print('accuracy on test set: %d %% ' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ./dataset/mnist/MNIST\raw\train-images-idx3-ubyte.gz
100.1%
Extracting ./dataset/mnist/MNIST\raw\train-images-idx3-ubyte.gz to ./dataset/mnist/MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ./dataset/mnist/MNIST\raw\train-labels-idx1-ubyte.gz
113.5%
Extracting ./dataset/mnist/MNIST\raw\train-labels-idx1-ubyte.gz to ./dataset/mnist/MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ./dataset/mnist/MNIST\raw\t10k-images-idx3-ubyte.gz
100.4%
Extracting ./dataset/mnist/MNIST\raw\t10k-images-idx3-ubyte.gz to ./dataset/mnist/MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ./dataset/mnist/MNIST\raw\t10k-labels-idx1-ubyte.gz
180.4%
Extracting ./dataset/mnist/MNIST\raw\t10k-labels-idx1-ubyte.gz to ./dataset/mnist/MNIST\raw
Processing...
Done!
[1, 300] loss: 2.146
[1, 600] loss: 0.746
[1, 900] loss: 0.412
accuracy on test set: 89 %
[2, 300] loss: 0.311
[2, 600] loss: 0.264
[2, 900] loss: 0.231
accuracy on test set: 94 %
[3, 300] loss: 0.192
[3, 600] loss: 0.166
[3, 900] loss: 0.153
accuracy on test set: 96 %
[4, 300] loss: 0.132
[4, 600] loss: 0.122
[4, 900] loss: 0.120
accuracy on test set: 96 %
[5, 300] loss: 0.100
[5, 600] loss: 0.090
[5, 900] loss: 0.098
accuracy on test set: 96 %
[6, 300] loss: 0.077
[6, 600] loss: 0.078
[6, 900] loss: 0.076
accuracy on test set: 97 %
[7, 300] loss: 0.061
[7, 600] loss: 0.066
[7, 900] loss: 0.064
accuracy on test set: 97 %
[8, 300] loss: 0.049
[8, 600] loss: 0.051
[8, 900] loss: 0.055
accuracy on test set: 97 %
[9, 300] loss: 0.040
[9, 600] loss: 0.045
[9, 900] loss: 0.040
accuracy on test set: 97 %
[10, 300] loss: 0.033
[10, 600] loss: 0.035
[10, 900] loss: 0.034
accuracy on test set: 97 %
相关说明
Softmax Classifiter 分类器解决多分类问题
1. 关于MNIST数据集
-
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
-
MNIST 包括6万张28x28的训练样本,1万张测试样本,很多教程都会对它”下手”,几乎成为一个 “典范”,可以说它就是计算机视觉里面的Hello World
-
MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取, 它包含了四个部分:
- Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
- Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
- Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
- Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
2. 关于二分类与多分类
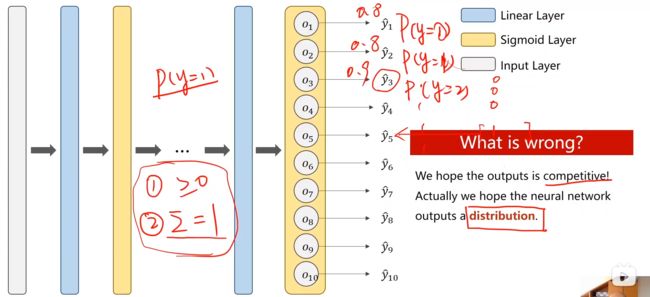
把每一个类别都当成一个二分类的问题,但是各个分类输出的可能性之间要有相互抑制的关联(比如当为1的可能性足够大的时候,那么其他数字的可能性就会很小)
-
所以十个分类中所有的输出要求(才能满足离散分布的要求):
-
所有的输出都大于0;
-
所有的输出之和为1;
-
3. 关于神经网络处理过程
此问题的对应的神经网络前面的这些层对应的还是使用Sigmod函数,最后输出的这一层不使用Sigmod(使用Sigmod得不到想要的结果)
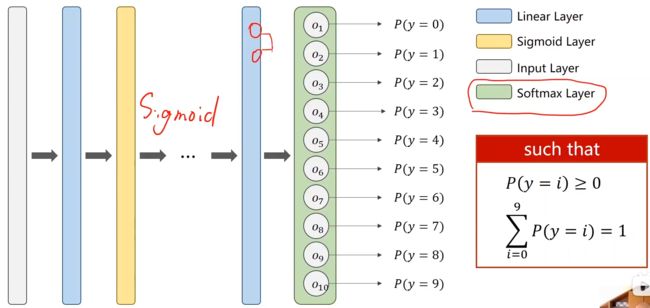
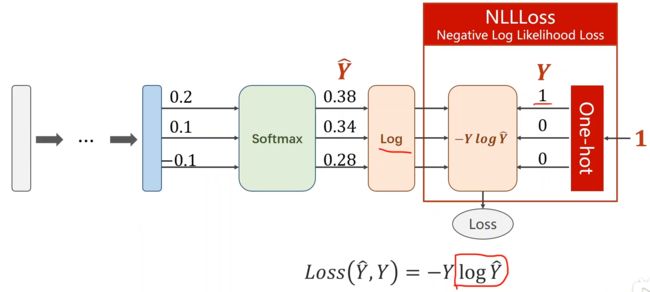
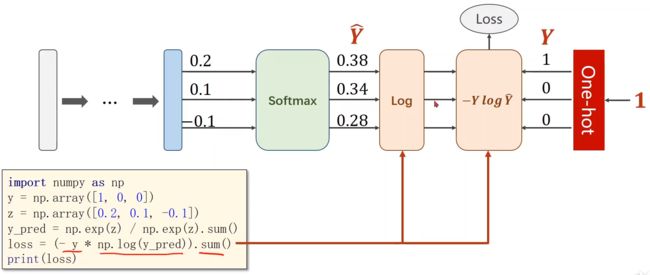
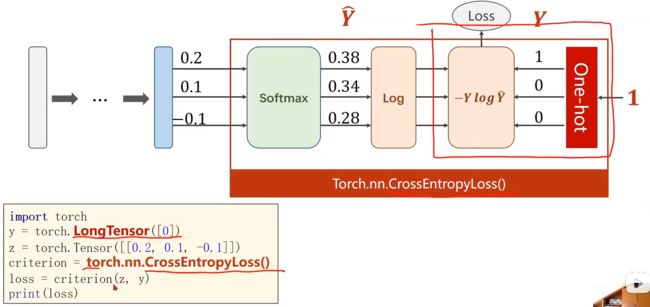
4. softmax函数
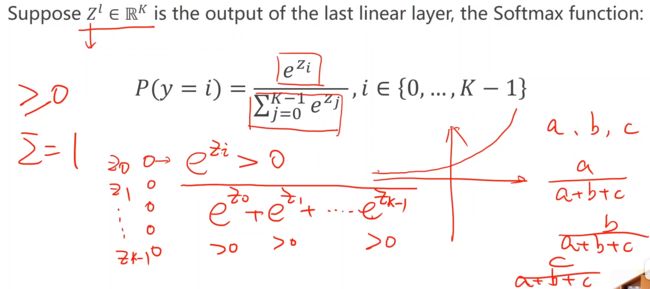
-
举例(以及softmax 和 NLLLoss 和 CrossEntropyLoss()交叉熵损失 之间的区别):
-
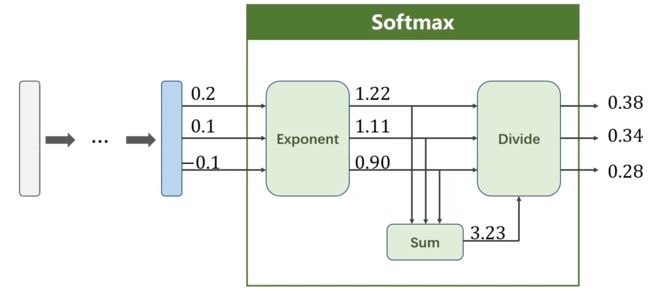
-
-
-
-
运算示例:
-
torch.Tensor([0.1,0.2,0.9],…) 表示原始的线性层的输出,还没有经过softmax,还不是概率分布;表示第一个样本是数字2 的“可能性”是0.9,是数字1的“可能性”是0.2,是数字0的“可能性”是0.1;(这里mini-batch 中的batch_size是3,表示三个样本作为一组一起计算)

5. 关于MNIST数据集的处理举例
每一张图片都是28*28的像素,每一个像素值的取值是0255;如果0255映射到0~1的区间,对应到28 * 28的矩阵;
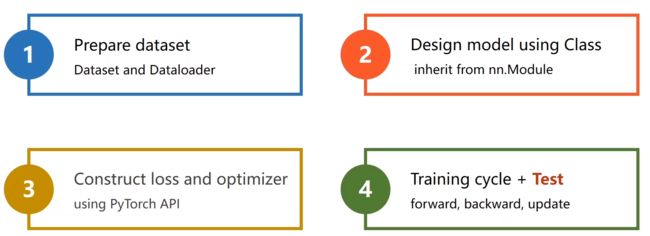
6. 代码流程
7. 关于transforms.ToTensor
为了在pytorch中进行更加高效的图像处理和卷积运算所进行的转换

8. 关于transforms.Normalize

9.代码中transform的对应关系

10. 关于x.view
x.view用于改变张量的形状
输入的样本(N,1,28,28):4阶的张量,每个里面N个样本,每个样本是一维,像素长宽是28 * 28的图像;这里的N可以理解为mini-batch的batch_size的大小;
11. 设计模型
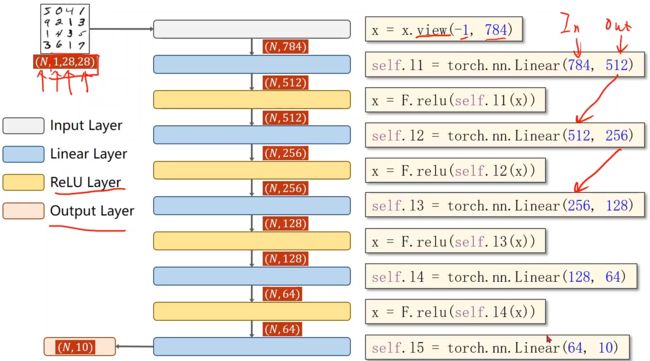
注意最后一层不做激活,直接线性层的输出接到后面的softmax里面

12. batch size设置技巧 谈谈batchsize参数
参考:batch size设置技巧 谈谈batchsize参数
- batch的size设置的不能太大也不能太小,因此实际工程中最常用的就是mini-batch,一般size设置为几十或者几百。
- 对于二阶优化算法,减小batch换来的收敛速度提升远不如引入大量噪声导致的性能下降,因此在使用二阶优化算法时,往往要采用大batch哦。此时往往batch设置成几千甚至一两万才能发挥出最佳性能。
- GPU对2的幂次的batch可以发挥更佳的性能,因此设置成16、32、64、128…时往往要比设置为整10、整100的倍数时表现更优
13. 关于x.view(-1, 784)
举例说明view()的作用:

代码中的inputs:
单独测试了每次inputs的样本的“size”:
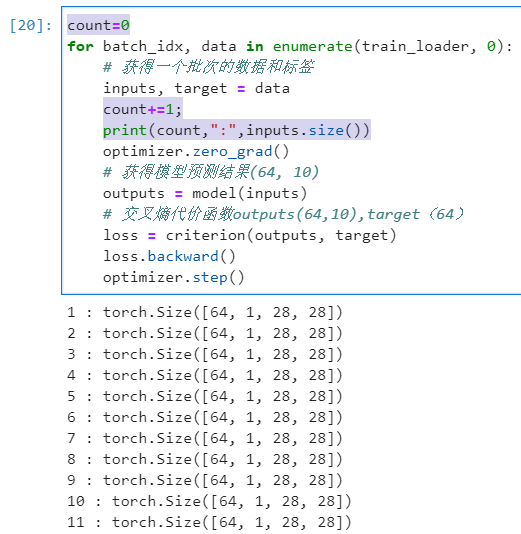

最后一次的时候(for循环运行完毕后)测试关于inputs的测试:


14. 关于torch.nn.Linear和relu的举例测试
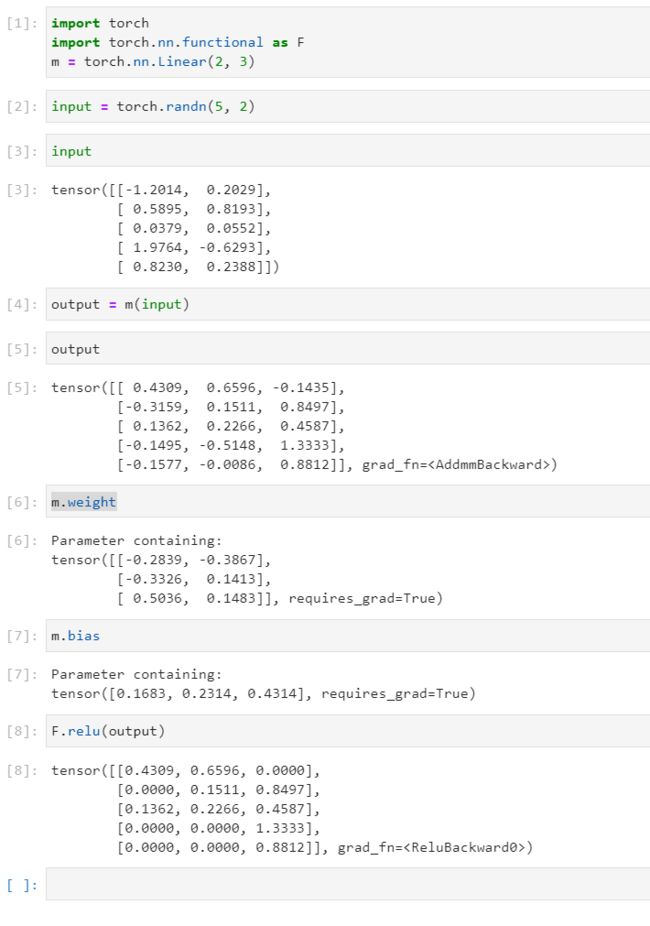
官网(pytorch1.2.0)对于torch.nn.Linear中的 weight 和 bias 的解释:
