小试国产开源HTAP分布式NewSQL数据库TiDB-v5.3.0
概述
定义
TiDB官网 https://pingcap.com/zh/ 最新版本为5.3.0
TiDB GitHub源码 https://github.com/pingcap/tidb
TiDB是由国内PingCAP公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP,混合事务和分析处理,在同一个数据库系统同时支持OLTP和OLAP) 的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性,迁移便捷,运维成本极低。
目前国产分布式数据库排名前三数据库有TiDB、OceanBase、PolarDB-X;OceanBase为蚂蚁集团完全自主研发,诞生较久早在2010年就开始建设;PolarDB-X则为阿里巴巴自主研发的云原生分布式数据库。TiDB是采用Go语言编写,越来越多开源项目选择Go,TiDB目标是为用户提供一站式 OLTP (Online Transactional Processing-在线事务处理)、OLAP (Online Analytical Processing-在线数据分析)、HTAP 解决方案。TiDB官方提供社区版(开源)和企业版(付费)。
与传统单机数据库对比优势
- 纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容。
- 支持 SQL,对外暴露 MySQL 的网络协议,并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL。
- 默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明。
- 支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账。
- 具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景。
官方工具
- 安装部署
- TiUP
- TiDB Operator
- 数据流转
- 数据迁入 - TiDB Data Migration
- 增量数据迁出 - TiCDC
- 数据导入 - TiDB Lightning
- 数据导出 - Dumpling
- 集群容灾
- Backup & Restore
- 运维和可视化
- TiDB Dashboard
核心特性
- 一键水平扩容或者缩容:得益于 TiDB 存储计算分离的架构的设计,可按需对计算、存储分别进行在线扩容或者缩容,扩容或者缩容过程中对应用运维人员透明。
- 金融级高可用:数据采用多副本存储,数据副本通过 Multi-Raft 协议同步事务日志,多数派写入成功事务才能提交,确保数据强一致性且少数副本发生故障时不影响数据的可用性。可按需配置副本地理位置、副本数量等策略满足不同容灾级别的要求。
- 实时 HTAP:提供行存储引擎 TiKV、列存储引擎 TiFlash 两款存储引擎,TiFlash 通过 Multi-Raft Learner 协议实时从 TiKV 复制数据,确保行存储引擎 TiKV 和列存储引擎 TiFlash 之间的数据强一致。TiKV、TiFlash 可按需部署在不同的机器,解决 HTAP 资源隔离的问题。
- 云原生的分布式数据库:专为云而设计的分布式数据库,通过 TiDB Operator 可在公有云、私有云、混合云中实现部署工具化、自动化。
- 兼容 MySQL 5.7 协议和 MySQL 生态:兼容 MySQL 5.7 协议、MySQL 常用的功能、MySQL 生态,应用无需或者修改少量代码即可从 MySQL 迁移到 TiDB。提供丰富的数据迁移工具帮助应用便捷完成数据迁移。
产品特点
- 融合的数据平台:打破数据壁垒,合而为一。事务性与分析型处理完全基于一体化的数据基座。
- 实时的商业分析:在线数据分析与决策,分秒必争。强一致性保障基于数据的决策,分毫不差。
- 敏捷的业务创新:数据库,亦服务;云原生,高弹性;金融级高可用。
- 开放的生态系统:基于 CNCF 项目的中国领先开源社区。无缝支持多云架构对接丰富的数据工具生态。
应用场景
- 对数据一致性及高可靠、系统高可用、可扩展性、容灾要求较高的金融行业属性的场景。
- 对存储容量、可扩展性、并发要求较高的海量数据及高并发的 OLTP 场景。
- Real-time HTAP 场景。
- 数据汇聚、二次加工处理的场景。
部署
部署规划
单台 Linux 服务器, TiDB最小规模的 TiDB 集群拓扑,模拟生产环境下的部署步骤。
| 实例 | 个数 | IP | 配置 |
|---|---|---|---|
| TiKV | 3 | 192.168.50.95、192.168.50.95、192.168.50.95 | 避免端口和目录冲突 |
| TiDB | 1 | 192.168.50.95 | 默认端口 全局目录配置 |
| PD | 1 | 192.168.50.95 | 默认端口 全局目录配置 |
| TiFlash | 1 | 192.168.50.95 | 默认端口 全局目录配置 |
| Monitor | 1 | 192.168.50.95 | 默认端口 全局目录配置 |
单机部署集群
# 下载并安装 TiUP
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
# 声明全局环境变量,本人使用的是root安装
source /root/.bash_profile
# 安装 TiUP 的 cluster 组件
tiup cluster
# 由于模拟多机部署,需要通过 root 用户调大 sshd 服务的连接数限制,修改 /etc/ssh/sshd_config 将 MaxSessions 调至 20。重启 sshd 服务
service sshd restart
# 创建启动集群的yaml配置文件,内容如下
vi topo.yaml
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/tidb-deploy"
data_dir: "/tidb-data"
# # Monitored variables are applied to all the machines.
monitored:
node_exporter_port: 9100
blackbox_exporter_port: 9115
server_configs:
tidb:
log.slow-threshold: 300
tikv:
readpool.storage.use-unified-pool: false
readpool.coprocessor.use-unified-pool: true
pd:
replication.enable-placement-rules: true
replication.location-labels: ["host"]
tiflash:
logger.level: "info"
pd_servers:
- host: 192.168.50.95
tidb_servers:
- host: 192.168.50.95
tikv_servers:
- host: 192.168.50.95
port: 20160
status_port: 20180
config:
server.labels: { host: "tikv-host-1" }
- host: 192.168.50.95
port: 20161
status_port: 20181
config:
server.labels: { host: "tikv-host-2" }
- host: 192.168.50.95
port: 20162
status_port: 20182
config:
server.labels: { host: "tikv-host-3" }
tiflash_servers:
- host: 192.168.50.95
monitoring_servers:
- host: 192.168.50.95
grafana_servers:
- host: 192.168.50.95
保存内容后下面进行正式部署和启动
# 执行集群部署命令,集群的名称和我们配置文件一致tidb-cluster,集群版本可以通过 tiup list tidb 命令来查看当前支持部署的 TiDB 版本
tiup cluster deploy tidb-cluster v5.3.0 ./topo.yaml --user root -p
# 执行上面的命令出现下面的提示后按照引导,输入”y”及 root 密码,来完成部署

# 启动集群:
tiup cluster start tidb-cluster
#查看当前已经部署的集群列表
tiup cluster list
# 查看集群的拓扑结构和状态
tiup cluster display tidb-cluster

# 由于我本机已安装mysql,所以可以直接运行mysql客户端,访问 TiDB 数据库,密码为空
mysql -h 192.168.50.95 -P 4000 -u root

访问TiDB的Grafana监控监控页面,默认用户名和密码均为admin, http://192.168.50.95:3000
访问TiDB集群Dashboard监控页面, 默认用户名为root,密码为空,http://192.168.50.95:2379/dashboard

体验HTAP
基本概念
- HTAP 存储引擎:行存 (Row-store) 与列存 (columnar-store) 同时存在,自动同步,保持强一致性。行存为在线事务处理 OLTP 提供优化,列存则为在线分析处理 OLAP 提供性能优化。
- HTAP 数据一致性:作为一个分布式事务型的键值数据库,TiKV 提供了满足 ACID 约束的分布式事务接口,并通过Raft协议保证了多副本数据一致性以及高可用。TiFlash 通过 Multi-Raft Learner 协议实时从 TiKV 复制数据,确保与 TiKV 之间的数据强一致。
- HTAP 数据隔离性:TiKV、TiFlash 可按需部署在不同的机器,解决 HTAP 资源隔离的问题。
- MPP 计算引擎:从 v5.0 版本起,TiFlash 引入了分布式计算框架MPP,允许节点之间的数据交换并提供高性能、高吞吐的 SQL 算法,可以大幅度缩短分析查询的执行时间。
体验
# 启动 TiDB 集群
tiup playground
# 使用以下命令安装数据生成工具
tiup install bench
# 使用以下命令生成数据,当命令行输出Finished时,表示数据生成完毕。
tiup bench tpch --sf=1 prepare
适用场景
TiDB HATP 可以满足企业海量数据的增产需求、降低运维的风险成本、与现有的大数据栈无缝结合,从而实现数据资产价值的实时变现,以下是三种 HTAP 典型适用场景:
- 混合负载场景:当将 TiDB 应用于在线实时分析处理的混合负载场景时,开发人员只需要提供一个入口,TiDB 将自动根据业务类型选择不同的处理引擎。
- 实时流处理场景:当将 TiDB 应用于实时流处理场景时,TiDB 能保证源源不断流入系统的数据实时可查,同时可兼顾高并发数据服务与 BI 查询。
- 数据中枢场景:当将 TiDB 应用于数据中枢场景时,TiDB 作为数据中枢可以无缝连接数据业务层和数据仓库层,满足不同业务的需求。
架构
总体架构

- TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
- PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。
- 存储节点
- TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
- TiFlash:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
- TiSpark 作为 TiDB 中解决用户复杂 OLAP 需求的主要组件,将 Spark SQL 直接运行在 TiDB 存储层上,同时融合 TiKV 分布式集群的优势,并融入大数据社区生态。至此,TiDB 可以通过一套系统,同时支持 OLTP 与 OLAP,免除用户数据同步的烦恼。

-
TiKV 的选择是 Key-Value 模型,并且提供有序遍历方法
- 巨大的 Map,也就是存储的是 Key-Value Pairs(键值对)。
- Map 中的 Key-Value pair 按照 Key 的二进制顺序有序,也就是可以 Seek 到某一个 Key 的位置,然后不断地调用 Next 方法以递增的顺序获取比这个 Key 大的 Key-Value。
-
本地存储
- TiKV把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责, RocksDB 是由 Facebook 开源的一个非常优秀的单机 KV 存储引擎,可以满足 TiKV 对单机引擎的各种要求。这里可以简单的认为 RocksDB 是一个单机的持久化 Key-Value Map。
-
Raft协议
-
通过单机的 RocksDB,TiKV 可以将数据快速地存储在磁盘上;通过 Raft,将数据复制到多台机器上,以防单机失效。数据的写入是通过 Raft 这一层的接口写入,而不是直接写 RocksDB。通过实现 Raft,TiKV 变成了一个分布式的 Key-Value 存储,少数几台机器宕机也能通过原生的 Raft 协议自动把副本补全,可以做到对业务无感知。

-
-
Region
- 按照 Key 分 Range,某一段连续的 Key 都保存在一个存储节点上,将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,将每一段叫做一个 Region,并且会尽量保持每个 Region 中保存的数据不超过一定的大小,目前在 TiKV 中默认是 96MB。每一个 Region 都可以用 [StartKey,EndKey) 这样一个左闭右开区间来描述。
- 以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多。
- 以 Region 为单位做 Raft 的复制和成员管理。
- 以 Region 为单位做数据的分散和复制,TiKV 就成为了一个分布式的具备一定容灾能力的 KeyValue 系统,不用再担心数据存不下,或者是磁盘故障丢失数据的问题。

- 按照 Key 分 Range,某一段连续的 Key 都保存在一个存储节点上,将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,将每一段叫做一个 Region,并且会尽量保持每个 Region 中保存的数据不超过一定的大小,目前在 TiKV 中默认是 96MB。每一个 Region 都可以用 [StartKey,EndKey) 这样一个左闭右开区间来描述。
-
MVCC:TiKV 的 MVCC 实现是通过在 Key 后面添加版本号来实现。
-
分布式事务:TiKV 的事务采用的是 Google 在 BigTable 中使用的事务模型。
计算
-
表数据与 Key-Value 的映射关系
-
索引数据和 Key-Value 的映射关系
-
元数据管理
- TiDB 中每个
Database和Table都有元信息,也就是其定义以及各项属性。这些信息也需要持久化,TiDB 将这些信息也存储在了 TiKV 中。
- TiDB 中每个
-
SQL层
-
TiDB 的 SQL 层,即 TiDB Server,负责将 SQL 翻译成 Key-Value 操作,将其转发给共用的分布式 Key-Value 存储层 TiKV,然后组装 TiKV 返回的结果,最终将查询结果返回给客户端。
-
SQL计算
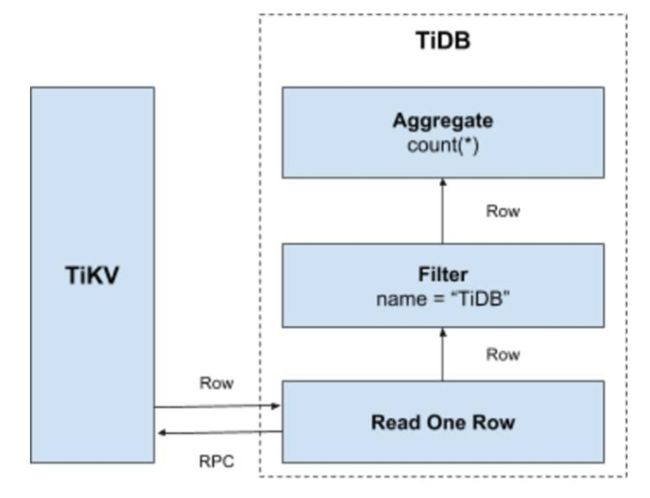
-
计算应该需要尽量靠近存储节点,以避免大量的 RPC 调用。首先,SQL 中的谓词条件
name = "TiDB"应被下推到存储节点进行计算,这样只需要返回有效的行,避免无意义的网络传输。然后,聚合函数Count(*)也可以被下推到存储节点,进行预聚合,每个节点只需要返回一个Count(*)的结果即可,再由 SQL 层将各个节点返回的Count(*)的结果累加求和。
-
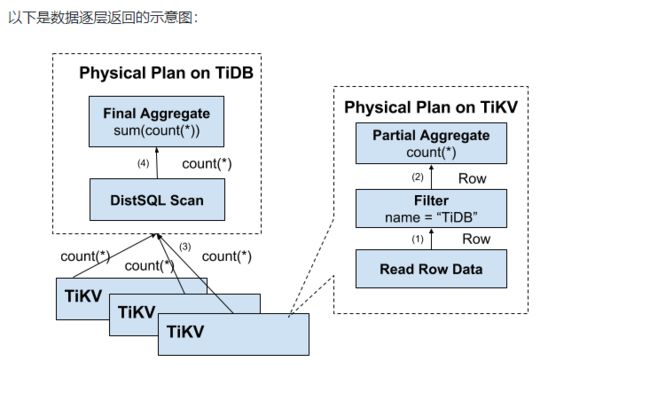
-
SQL 层架构
- 用户的 SQL 请求会直接或者通过 Load Balancer 发送到 TiDB Server,TiDB Server 会解析 MySQL Protocol Packet,获取请求内容,对 SQL 进行语法解析和语义分析,制定和优化查询计划,执行查询计划并获取和处理数据。数据全部存储在 TiKV 集群中,所以在这个过程中 TiDB Server 需要和 TiKV 交互,获取数据。最后 TiDB Server 需要将查询结果返回给用户。

调度
PD (Placement Driver) 是 TiDB 集群的管理模块,同时也负责集群数据的实时调度。本文档介绍一下 PD 的设计思想和关键概念。
第一类:作为一个分布式高可用存储系统,必须满足的需求,包括几种
- 副本数量不能多也不能少
- 副本需要根据拓扑结构分布在不同属性的机器上
- 节点宕机或异常能够自动合理快速地进行容灾
第二类:作为一个良好的分布式系统,需要考虑的地方包括
- 维持整个集群的 Leader 分布均匀
- 维持每个节点的储存容量均匀
- 维持访问热点分布均匀
- 控制负载均衡的速度,避免影响在线服务
- 管理节点状态,包括手动上线/下线节点
满足上面需求首先需要收集足够的信息,比如每个节点的状态、每个 Raft Group 的信息、业务访问操作的统计等;其次需要设置一些策略,PD 根据这些信息以及调度的策略,制定出尽量满足前面所述需求的调度计划;最后需要一些基本的操作,来完成调度计划。
调度依赖于整个集群信息的收集,简单来说,调度需要知道每个 TiKV 节点的状态以及每个 Region 的状态。TiKV 集群会向 PD 汇报两类消息,TiKV 节点信息和 Region 信息。
- 调度策略
- 一个 Region 的副本数量正确
- 一个 Raft Group 中的多个副本不在同一个位置
- 副本在 Store 之间的分布均匀分配
- Leader 数量在 Store 之间均匀分配
- 访问热点数量在 Store 之间均匀分配
- 各个 Store 的存储空间占用大致相等
- 控制调度速度,避免影响在线服务
- 调度的实现
- PD 不断地通过 Store 或者 Leader 的心跳包收集整个集群信息,并且根据这些信息以及调度策略生成调度操作序列。每次收到 Region Leader 发来的心跳包时,PD 都会检查这个 Region 是否有待进行的操作,然后通过心跳包的回复消息,将需要进行的操作返回给 Region Leader,并在后面的心跳包中监测执行结果。
存储引擎
TiKV
TiKV 是一个分布式事务型的键值数据库,提供了满足 ACID 约束的分布式事务接口,并且通过Raft协议保证了多副本数据一致性以及高可用。TiKV 作为 TiDB 的存储层,为用户写入 TiDB 的数据提供了持久化以及读写服务,同时还存储了 TiDB 的统计信息数据。
- Region 与 RocksDB:虽然 TiKV 将数据按照范围切割成了多个 Region,但是同一个节点的所有 Region 数据仍然是不加区分地存储于同一个 RocksDB 实例上,而用于 Raft 协议复制所需要的日志则存储于另一个 RocksDB 实例。这样设计的原因是因为随机 I/O 的性能远低于顺序 I/O,所以 TiKV 使用同一个 RocksDB 实例来存储这些数据,以便不同 Region 的写入可以合并在一次 I/O 中。
- Region 与 Raft 协议:Region 与副本之间通过 Raft 协议来维持数据一致性,任何写请求都只能在 Leader 上写入,并且需要写入多数副本后(默认配置为 3 副本,即所有请求必须至少写入两个副本成功)才会返回客户端写入成功。
- RocksDB是由 Facebook 基于 LevelDB 开发的一款提供键值存储与读写功能的 LSM-tree 架构引擎。用户写入的键值对会先写入磁盘上的 WAL (Write Ahead Log),然后再写入内存中的跳表(SkipList,这部分结构又被称作 MemTable)。LSM-tree 引擎由于将用户的随机修改(插入)转化为了对 WAL 文件的顺序写,因此具有比 B 树类存储引擎更高的写吞吐。内存中的数据达到一定阈值后,会刷到磁盘上生成 SST 文件 (Sorted String Table),SST 又分为多层(默认至多 6 层),每一层的数据达到一定阈值后会挑选一部分 SST 合并到下一层,每一层的数据是上一层的 10 倍(因此 90% 的数据存储在最后一层)。RocksDB 允许用户创建多个 ColumnFamily ,这些 ColumnFamily 各自拥有独立的内存跳表以及 SST 文件,但是共享同一个 WAL 文件,这样的好处是可以根据应用特点为不同的 ColumnFamily 选择不同的配置,但是又没有增加对 WAL 的写次数。
TiFlash
TiFlash 是 TiDB HTAP 形态的关键组件,它是 TiKV 的列存扩展,在提供了良好的隔离性的同时,也兼顾了强一致性。列存副本通过 Raft Learner 协议异步复制,但是在读取的时候通过 Raft 校对索引配合 MVCC 的方式获得 Snapshot Isolation 的一致性隔离级别。这个架构很好地解决了 HTAP 场景的隔离性以及列存同步的问题。

上图为 TiDB HTAP 形态架构,其中包含 TiFlash 节点。
TiFlash 提供列式存储,且拥有借助 ClickHouse 高效实现的协处理器层。除此以外,它与 TiKV 非常类似,依赖同样的 Multi-Raft 体系,以 Region 为单位进行数据复制和分散。
TiFlash 主要有异步复制、一致性、智能选择、计算加速等几个核心特性。
- 异步复制:TiFlash 中的副本以特殊角色 (Raft Learner) 进行异步的数据复制。这表示当 TiFlash 节点宕机或者网络高延迟等状况发生时,TiKV 的业务仍然能确保正常进行。这套复制机制也继承了 TiKV 体系的自动负载均衡和高可用:并不用依赖附加的复制管道,而是直接以多对多方式接收 TiKV 的数据传输;且只要 TiKV 中数据不丢失,就可以随时恢复 TiFlash 的副本。
- 一致性:TiFlash 提供与 TiKV 一样的快照隔离支持,且保证读取数据最新(确保之前写入的数据能被读取)。这个一致性是通过对数据进行复制进度校验做到的。每次收到读取请求,TiFlash 中的 Region 副本会向 Leader 副本发起进度校对(一个非常轻的 RPC 请求),只有当进度确保至少所包含读取请求时间戳所覆盖的数据之后才响应读取。
- 智能选择:TiDB 可以自动选择使用 TiFlash 列存或者 TiKV 行存,甚至在同一查询内混合使用提供最佳查询速度。这个选择机制与 TiDB 选取不同索引提供查询类似:根据统计信息判断读取代价并作出合理选择。
- 计算加速:TiFlash 对 TiDB 的计算加速分为两部分:列存本身的读取效率提升以及为 TiDB 分担计算。其中分担计算的原理和 TiKV 的协处理器一致:TiDB 会将可以由存储层分担的计算下推。能否下推取决于 TiFlash 是否可以支持相关下推
**本人博客网站 **IT小神 www.itxiaoshen.com