从理论到工程实践——用户画像入门宝典
用户画像是大数据顶层应用中最重要的一环,搭建一套适合本公司体系的用户画像尤为重要。但是,用户画像的资料往往理论居多,实践少,更少有工程化的实战案例。
本文档结合了常见的用户画像架构,使用Elasticsearch作为底层存储支撑,用户画像的检索和可视化效率得到了大幅度的提升。文档从用户画像的理论到实践均有所涉及,大家可以参照此文档完成用户画像系统从0到1的搭建。
正文共: 30016字
预计阅读时间: 76分钟
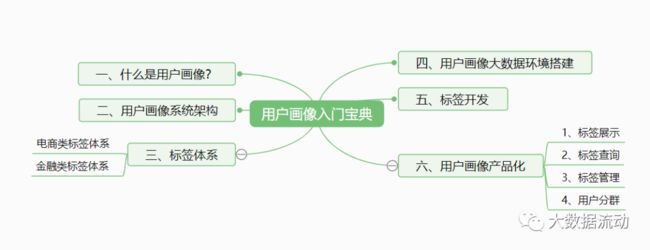
本文档共分为6个部分,层级结构如下图所示。
文档版权为公众号 大数据流动 所有,请勿商用。相关技术问题以及安装包可以联系笔者独孤风加入相关技术交流群讨论获取。
一、什么是用户画像?
用户画像简介
用户画像,作为一种勾画目标用户、联系用户诉求与设计方向的有效工具,用户画像在各领域得到了广泛的应用。
用户画像最初是在电商领域得到应用的,在大数据时代背景下,用户信息充斥在网络中,将用户的每个具体信息抽象成标签,利用这些标签将用户形象具体化,从而为用户提供有针对性的服务。
还记得年底收到的支付宝年度消费账单吗?帮助客户回顾一年的消费细节,包括消费能力、消费去向、信用额度等等,再根据每位客户的消费习惯,量身定制商品推荐列表……这一活动,将数据这个量化的词以形象生动的表现手法推到了大众面前。
这就是用户画像在电商领域的一个应用,随着我国电子商务的高速发展,越来越多的人注意到数据信息对于电商市场的推动作用。基于数据分析的精准营销方式,可以最大限度的挖掘并留住潜在客户,数据统计与分析为电商市场带来的突破不可估量。在大数据时代,一切皆可“量化”,看似普通的小小数字背后,蕴藏着无限商机,也正在被越来越多的企业所洞悉。

如何从大数据中挖掘商机?建立用户画像和精准化分析是关键。
用户画像可以使产品的服务对象更加聚焦,更加的专注。在行业里,我们经常看到这样一种现象:做一个产品,期望目标用户能涵盖所有人,男人女人、老人小孩、专家小白、文青屌丝...... 通常这样的产品会走向消亡,因为每一个产品都是为特定目标群的共同标准而服务的,当目标群的基数越大,这个标准就越低。换言之, 如果这个产品是适合每一个人的,那么其实它是为最低的标准服务的,这样的产品要么毫无特色,要么过于简陋。
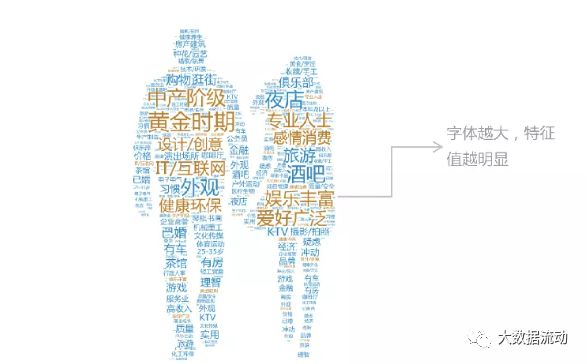
纵览成功的产品案例,他们服务的目标用户通常都非常清晰,特征明显,体现在产品上就是专注、极致,能解决核心问题。比如苹果的产品,一直都为有态度、追求品质、特立独行的人群服务,赢得了很好的用户口碑及市场份额。又比如豆瓣,专注文艺事业十多年,只为文艺青年服务,用户粘性非常高,文艺青年在这里能找到知音,找到归宿。所以,给特定群体提供专注的服务,远比给广泛人群提供低标准的服务更接近成功。 其次,用户画像可以在一定程度上避免产品设计人员草率的代表用户。代替用户发声是在产品设计中常出现的现象,产品设计人员经常不自觉的认为用户的期望跟他们是一致的,并且还总打着“为用户服务”的旗号。这样的后果往往是:我们精心设计的服务,用户并不买账,甚至觉得很糟糕。
在产品研发和营销过程中,确定目标用户是首要任务。不同类型的用户往往有不同甚至相冲突的需求,企业不可能做出一个满足所有用户的产品和营销。因此,通过大数据建立用户画像是必不可少的。
这只是用户画像在电商领域的应用,事实上用户画像已经不知不觉的渗透到了各个领域,在当前最火的抖音,直播等领域,推荐系统在大数据时代到来以后,用户的一切行为都是可以追溯分析的。
用户画像实现步骤
什么是用户画像?用户画像是根据市场研究和数据,创建的理想中客户虚构的表示。创建用户画像,这将有助于理解现实生活中的目标受众。企业创建的人物角色画像,具体到针对他们的目标和需求,并解决他们的问题,同时,这将帮助企业更加直观的转化客户。
用户画像最重要的一个步骤就是对用户标签化,我们要明确要分析用户的各种维度,才能确定如何对用户进行画像。
在建立用户画像上,有很多个步骤:
首先,基础数据收集,电商领域大致分为行为数据、内容偏好数据、交易数据,如浏览量、访问时长、家具偏好、回头率等等。而金融领域又有贷款信息,信用卡,各种征信信息等等。
然后,当我们对用户画像所需要的基础数据收集完毕后,需要对这些资料进行分析和加工,提炼关键要素,构建可视化模型。对收集到的数据进行行为建模,抽象出用户的标签。电商领域可能是把用户的基本属性、购买能力、行为特征、兴趣爱好、心理特征、社交网络大致的标签化,而金融风控领域则是更关注用户的基本信息,风险信息,财务信息等等。
随后,要利用大数据的整体架构对标签化的过程进行开发实现,对数据进行加工,将标签管理化。同时将标签计算的结果进行计算。这个过程中需要依靠Hive,Hbase等大数据技术,为了提高数据的实时性,还要用到Flink,Kafka等实时计算技术。
最后,也是最关键的一步,要将我们的计算结果,数据,接口等等,形成服务。比如,图表展示,可视化展示,

事实上,在构建用户画像过程中,注重提取数据的多元性而不是单一性,譬如针对不同类型的客户提取不同的数据,又或者针对线上线下的客户分析其中差异。总而言之,保证数据的丰富性、多样性、科学性,是建立精准用户画像的前提。
当用户画像基本成型后,接下来就可以对其进行形象化、精准化的分析。此时一般是针对群体的分析,如可以根据用户价值来细分出核心用户、评估某一群体的潜在价值空间,以此作出针对性的产品结构、经营策略、客户引导的调整。因此,突出研发和展示此类型的产品,又在家具的整体搭配展示中进行相关的主题设计,以此吸引目标人群的关注和购买。
毫无疑问,大数据在商业市场中的运用效果已经突显,在竞争激烈的各个行业,谁能抓住大数据带来的优势,谁才更有机会引领行业的未来。
用户画像的实时性
现在大数据应用比较火爆的领域,比如推荐系统在实践之初受技术所限,可能要一分钟,一小时,甚至更久对用户进行推荐,这远远不能满足需要,我们需要更快的完成对数据的处理,而不是进行离线的批处理。
现在企业对于数据的实时要求越来越高,已经不满足于T+1的方式,有些场景下不可能间隔一天才反馈出结果。特别是推荐,风控等领域,需要小时,分钟,甚至秒级别的实时数据响应。而且这种秒级别响应的不只是简单的数据流,而且经过与离线计算一样的,复杂的聚合分析之后的结果,这种难度其实非常大。
幸好实时计算框架的崛起足够我们解决这些问题,近年来Flink,Kafka等实时计算技术的框架与技术越来越稳定,足够我们支撑这些使用场景。
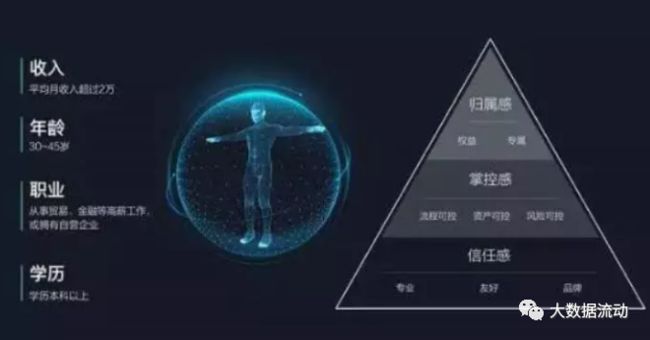
在实时用户画像的构建中,通过对实时数据的不断迭代计算,逐渐的不断完善出用户画像的全貌,这也正符合数据传输的本质,这整体架构中,淡化离线计算在之前特别重的作用,只留做归档和历史查询使用,更多的数据通过实时计算进行输出,最终达到对用户画像的目的。
在实时计算的过程需要对数据实时聚合计算,而复杂的标签也需要实时的进行机器学习,难度巨大,但是最终对于画像的实时性有着重大的意义。

二、用户画像系统架构
前文中我们已经知道用户画像对于企业的巨大意义,当然也有着非常大实时难度。那么在用户画像的系统架构中都有哪些难度和重点要考虑的问题呢?
挑战
挑战(一)——大数据
随着互联网的崛起和智能手机的兴起,以及物联网带来的各种可穿戴设备,我们能获取的每一个用户的数据量是非常巨大的,而用户量本身更是巨大的,我们面临的是TB级,PB级的数据,所以我们必须要一套可以支撑大数据量的高可用性,高扩展性的系统架构来支撑用户画像分析的实现。毫无疑问,大数据时代的到来让这一切都成为可能,近年来,以Hadoop为代表的大数据技术如雨后春笋般迅速发展,每隔一段时间都会有一项新的技术诞生,不断驱动的业务向前,这让我们对于用户画像的简单统计,复杂分析,机器学习都成为可能。所以整体用户画像体系必须建立在大数据架构之上。

挑战(二)——实时性
在Hadoop崛起初期,大部分的计算都是通过批处理完成的,也就是T+1的处理模式,要等一天才能知道前一天的结果。但是在用户画像领域,我们越来越需要实时性的考虑,我们需要在第一时间就得到各种维度的结果,在实时计算的初期只有Storm一家独大,而Storm对于时间窗口,水印,触发器都没有很好的支持,而且保证数据一致性时将付出非常大的性能代价。但Kafka和Flink等实时流式计算框架的出现改变了这一切,数据的一致性,事件时间窗口,水印,触发器都成为很容易的实现。而实时的OLAP框架Druid更是让交互式实时查询成为可能。这这些高性能的实时框架成为支撑我们建立实时用户画像的最有力支持。

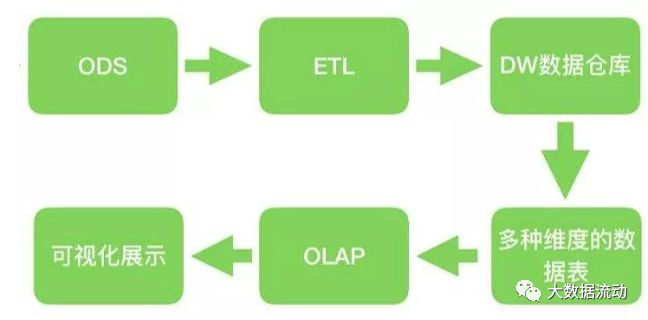
挑战(三)——与数仓的结合
数据仓库的概念由来已久,在我们得到海量的数据以后,如何将数据变成我们想要的样子,这都需要ETL,也就是对数据进行抽取(extract)、转换(transform)、加载(load)的过程,将数据转换成想要的样子储存在目标端。毫无疑问,Hive是作为离线数仓的不二选择,而hive使用的新引擎tez也有着非常好的查询性能,而最近新版本的Flink也支持了hive性能非常不错。但是在实时用户画像架构中,Hive是作为一个按天的归档仓库的存在,作为历史数据形成的最终存储所在,也提供了历史数据查询的能力。而Druid作为性能良好的实时数仓,将共同提供数据仓库的查询与分析支撑,Druid与Flink配合共同提供实时的处理结果,实时计算不再是只作为实时数据接入的部分,而真正的挑起大梁。
所以,两者的区别仅在于数据的处理过程,实时流式处理是对一个个流的反复处理,形成一个又一个流表,而数仓的其他概念基本一致。
数仓的基本概念如下:
-
Extract,数据抽取,也就是把数据从数据源读出来。
Transform,数据转换,把原始数据转换成期望的格式和维度。如果用在数据仓库的场景下,Transform也包含数据清洗,清洗掉噪音数据。
Load 数据加载,把处理后的数据加载到目标处,比如数据仓库。
DB 是现有的数据来源(也称各个系统的元数据),可以为mysql、SQLserver、文件日志等,为数据仓库提供数据来源的一般存在于现有的业务系统之中。
ETL的是 Extract-Transform-Load 的缩写,用来描述将数据从来源迁移到目标的几个过程:
ODS(Operational Data Store) 操作性数据,是作为数据库到数据仓库的一种过渡,ODS的数据结构一般与数据来源保持一致,便于减少ETL的工作复杂性,而且ODS的数据周期一般比较短。ODS的数据最终流入DW
DW (Data Warehouse)数据仓库,是数据的归宿,这里保持这所有的从ODS到来的数据,并长期保存,而且这些数据不会被修改。
DM(Data Mart) 数据集市,为了特定的应用目的或应用范围,而从数据仓库中独立出来的一部分数据,也可称为部门数据或主题数据。面向应用。
在整个数据的处理过程中我们还需要自动化的调度任务,免去我们重复的工作,实现系统的自动化运行,Airflow就是一款非常不错的调度工具,相比于老牌的Azkaban 和 Oozie,基于Python的工作流DAG,确保它可以很容易地进行维护,版本化和测试,当然最终提供的服务不仅仅是可视化的展示,还有实时数据的提供,最终形成用户画像的实时服务,形成产品化。
至此我们所面临的问题都有了非常好的解决方案,下面我们设计出我们系统的整体架构,并分析我们需要掌握的技术与所需要的做的主要工作。
架构设计
依据上面的分析与我们要实现的功能,我们将依赖Hive和Druid建立我们的数据仓库,使用Kafka进行数据的接入,使用Flink作为我们的流处理引擎,对于标签的元数据管理我们还是依赖Mysql作为把标签的管理,并使用Airflow作为我们的调度任务框架,并最终将结果输出到Mysql和Hbase中。对于标签的前端管理,可视化等功能依赖Springboot+Vue.js搭建的前后端分离系统进行展示,而Hive和Druid的可视化查询功能,我们也就使用强大的Superset整合进我们的系统中,最终系统的架构图设计如下:
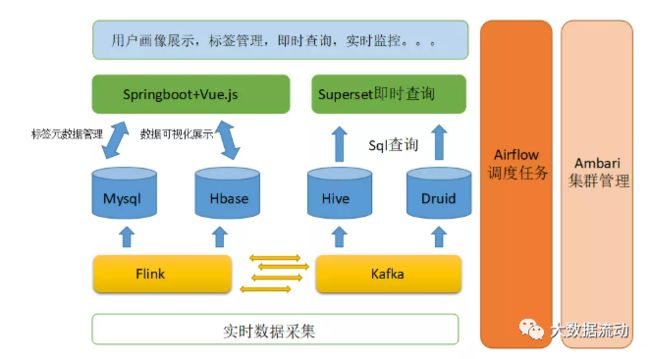
相对于传统的技术架构,实时技术架构将极大的依赖于Flink的实时计算能力,当然大部分的聚合运算我们还是可以通过Sql搞定,但是复杂的机器学习运算需要依赖编码实现。而标签的存储细节还是放在Mysql中,Hive与Druid共同建立起数据仓库。相对于原来的技术架构,只是将计算引擎由Spark换成了Flink,当然可以选择Spark的structured streaming同样可以完成我们的需求,两者的取舍还是依照具体情况来做分析。
传统架构如下:
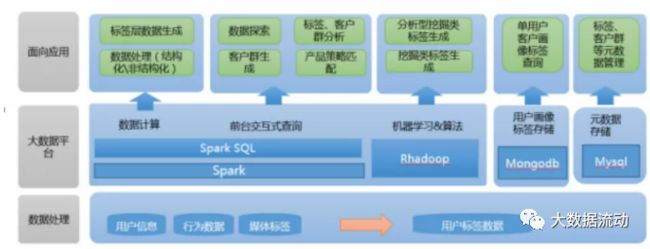
这样我们就形成,数据存储,计算,服务,管控的强有力的支撑,我们是否可以开始搭建大数据集群了呢?其实还不着急,在开工之前,需求的明确是无比重要的,针对不同的业务,电商,风控,还是其他行业都有着不同的需求,对于用户画像的要求也不同,那么该如何明确这些需求呢,最重要的就是定义好用户画像的标签体系,这是涉及技术人员,产品,运营等岗位共同讨论的结果,也是用户画像的核心所在。
三、标签体系
什么是标签?
用户画像的核心在于给用户“打标签”,每一个标签通常是人为规定的特征标识,用高度精炼的特征描述一类人,例如年龄、性别、兴趣偏好等,不同的标签通过结构化的数据体系整合,就可与组合出不同的用户画像。
梳理标签体系是实现用户画像过程中最基础、也是最核心的工作,后续的建模、数据仓库搭建都会依赖于标签体系。
为什么需要梳理标签体系,因为不同的企业做用户画像有不同的战略目的,广告公司做用户画像是为精准广告服务,电商做用户画像是为用户购买更多商品,内容平台做用户画像是推荐用户更感兴趣的内容提升流量再变现,金融行业做用户画像是为了寻找到目标客户的同时做好风险的控制。
所以第一步,我们要结合所在的行业,业务去分析我们用户画像的目的。这其实就是战略,我们要通过战略去指引我们最终的方向。
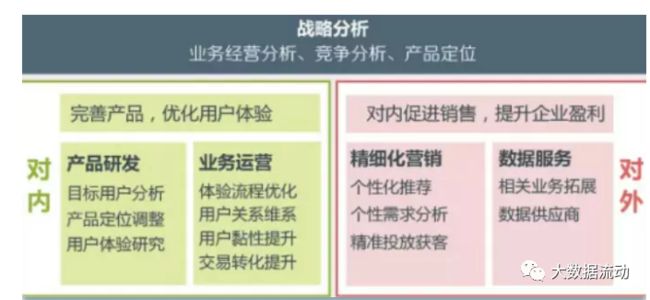
对于电商企业来说,可能最重要的两个问题就是:
现有用户- 我的现存用户是谁?为什么买我的产品?他们有什么偏好?哪些用户价值最高?
潜在客户- 我的潜在用户在哪儿?他们喜欢什么?哪些渠道能找到他们?获客成本是多少?
而对于金融企业,还要加上一条:
用户风险—用户的收入能力怎么样?他们是否有过贷款或者信用卡的逾期?他们的征信有问题吗?
我们做用户画像的目的也就是根据我们指定的战略方向最终去解决这些问题。
在梳理标签的过程还要紧密的结合我们的数据,不能脱离了数据去空想,当然如果是我们必须要的数据,我们可能需要想办法去获取这些数据,这就是数据采集的问题,我们之后会深入的讨论。
先展示两种常见的标签体系,随后我们将按步骤建立我们的标签体系。
电商类标签体系

可以看到电商类的标签体系,更关注用户的属性,行为等等信息。那么我们需要的数据也就来源于用户可提供的基本信息,以及用户的行为信息,这些我们可以通过埋点获取,而用户的订单情况也是非常的重要的标签。
金融类标签体系

对于金融行业,最明显的区别是增加了用户的价值和用户风险的信息。这些信息在用户申请贷款时一般都可以提供,还有很多信息需要通过征信获取。
最终,不管是电商还是金融或者其他领域,我们都可以通过数据对用户进行画像,最终建立标签体系,影响我们的业务,最终实现战略目的。
下面我们来具体看一下如何一步步的分析建立整体标签体系。
标签的维度与类型
在我们建立用户标签时,首先要明确基于哪种维度去建立标签。
一般除了基于用户维度(userid)建立用户标签体系外,还有基于设备维度(cookieid)建立相应的标签体系,当用户没有登录设备时,就需要这个维度。当然这两个维度还可以进行关联。
而两者的关联就是需要ID-Mapping算法来解决,这也是一个非常复杂的算法。更多的时候我们还是以用户的唯一标识来建立用户画像。
而标签也分为很多种类型,这里参照常见的分类方式,
从对用户打标签的方式来看,一般分为三种类型:1、基于统计类的标签;2、基于规则类的标签、3、基于挖掘类的标签。下面我们介绍这三种类型标签的区别:
统计类标签:这类标签是最为基础也最为常见的标签类型,例如对于某个用户来说,他的性别、年龄、城市、星座、近7日活跃时长、近7日活跃天数、近7日活跃次数等字段可以从用户注册数据、用户访问、消费类数据中统计得出。该类标签构成了用户画像的基础;
规则类标签:该类标签基于用户行为及确定的规则产生。例如对平台上“消费活跃”用户这一口径的定义为近30天交易次数>=2。在实际开发画像的过程中,由于运营人员对业务更为熟悉、而数据人员对数据的结构、分布、特征更为熟悉,因此规则类标签的规则确定由运营人员和数据人员共同协商确定;
机器学习挖掘类标签:该类标签通过数据挖掘产生,应用在对用户的某些属性或某些行为进行预测判断。例如根据一个用户的行为习惯判断该用户是男性还是女性,根据一个用户的消费习惯判断其对某商品的偏好程度。该类标签需要通过算法挖掘产生。
标签的类型是对标签的一个区分,方便我们了解标签是在数据处理的哪个阶段产生的,也更方便我们管理。
标签分级分类
标签需要进行分级分类的管理,一方面使得标签更加的清晰有条件,另一方面也方便我们对标签进行存储查询,也就是管理标签。

用户画像体系和标签分类从两个不同角度来梳理标签,用户画像体系偏战略和应用,标签分类偏管理和技术实现侧。
把标签分成不同的层级和类别,一是方便管理数千个标签,让散乱的标签体系化;二是维度并不孤立,标签之间互有关联;三可以为标签建模提供标签子集。
梳理某类别的子分类时,尽可能的遵循MECE原则(相互独立、完全穷尽),尤其是一些有关用户分类的,要能覆盖所有用户,但又不交叉。比如:用户活跃度的划分为核心用户、活跃用户、新用户、老用户、流失用户,用户消费能力分为超强、强、中、弱,这样按照给定的规则每个用户都有分到不同的组里。
标签命名
标签的命名也是为了我们可以对标签进行统一的管理,也更好识别出是什么标签。

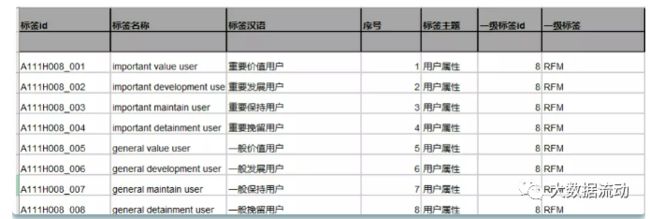
这是一种非常好的命名方式,解释如下:
标签主题:用于刻画属于那种类型的标签,如用户属性、用户行为、用户消费、风险控制等多种类型,可用A、B、C、D等 字母表示各标签主题; 标签类型:标签类型可划为分类型和统计型这两种类型,其中分类型用于刻画用户属于哪种类型,如是男是女、是否是会员、 是否已流失等标签,统计型标签用于刻画统计用户的某些行为次数,如历史购买金额、优惠券使用次数、近30日登陆次数等 标签,这类标签都需要对应一个用户相应行为的权重次数; 开发方式:开发方式可分为统计型开发和算法型开发两大开发方式。其中统计型开发可直接从数据仓库中各主题表建模加工 而成,算法型开发需要对数据做机器学习的算法处理得到相应的标签; 是否互斥标签:对应同一级类目下(如一级标签、二级标签),各标签之间的关系是否为互斥,可将标签划分为互斥关系和 非互斥关系。例如对于男、女标签就是互斥关系,同一个用户不是被打上男性标签就是女性标签,对于高活跃、中活跃、低 活跃标签也是互斥关系; 用户维度:用于刻画该标签是打在用户唯一标识(userid)上,还是打在用户使用的设备(cookieid)上。可用U、C等字 母分别标识userid和cookieid维度。
最终形成得标签示例:
对于用户是男是女这个标签,标签主题是用户属性,标签类型属于分类型,开发方式为统计型,为互斥关系,用户 维度为userid。这样给男性用户打上标签“A111U001_001”,女性用户打上标签“A111U001002”,其中 “A111U”为上面介绍的命名方式,“001”为一级标签的id,后面对于用户属性维度的其他一级标签可用“002”、 “003”等方式追加命名,“”后面的“001”和“002”为该一级标签下的标签明细,如果是划分高、中、低活跃 用户的,对应一级标签下的明细可划分为“001”、“002”、“003”。
标签存储与管理
Hive与Druid数仓存储标签计算结果集
因为数据非常大,所以跑标签出来的结果必须要通过hive和druid数仓引擎来完成。
在数据仓库的建模过程中,主要是事实表和维度表的开发。
事实表依据业务来开发,描述业务的过程,可以理解为我们对原始数据做ETL整理后业务事实。
而维度表就是我们最终形成的用户维度,维度表是实时变化的,逐渐的建立起用户的画像。
比如用户维度标签:
首先我们根据之前讨论的用户指标体系,将用户按照人口,行为,消费等等建立相关中间表,注意表的命名。
同样的,其他的也按这种方式进行存储,这种属性类的计算很容易筛选出来。
然后,我们将用户的标签查询出来,汇总到用户身上:
最终用户的标签就形成了
当然,对于复杂的规则和算法类标签,就需要在计算中间表时做更复杂的计算,我们需要在Flink里解决这些复杂的计算,未来开发中我们会详细的讨论,这一部分先根据标签体系把相应的表结构都设计出来。
Mysql存储标签元数据
Mysql对于小数据量的读写速度更快,也更适合我们对标签定义,管理。我们也可以在前端开发标签的管理页面。
我们在mysql存储的字段,在页面上提供编辑等功能,在开发标签的过程中,就可以控制标签的使用了。
这样,我们的标签体系已经根据实际的业务情况建立起来了,在明确了标签体系以后,也就明确了我们的业务支撑,从下一章开始我们将正式开始搭建大数据集群,接入数据,进行标签开发。
四、用户画像大数据环境搭建
本章我们开始正式搭建大数据环境,目标是构建一个稳定的可以运维监控的大数据环境。我们将采用Ambari搭建底层的Hadoop环境,使用原生的方式搭建Flink,Druid,Superset等实时计算环境。使用大数据构建工具与原生安装相结合的方式,共同完成大数据环境的安装。
Ambari搭建底层大数据环境
Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop和Hcatalog等。
Apache Ambari 支持HDFS、MapReduce、Hive、Pig、Hbase、Zookeepr、Sqoop和Hcatalog等的集中管理。也是顶级的hadoop管理工具之一。
本文使用的Ambari的版本为2.7,支持的组件也越来越丰富。
Hadoop的发行版本有很多,有华为发行版,Intel发行版,Cloudera发行版(CDH),MapR版本,以及HortonWorks版本等。所有发行版都是基于Apache Hadoop衍生出来的,产生这些版本的原因,是由于Apache Hadoop的开源协议决定的:任何人可以对其进行修改,并作为开源或商业产品发布和销售。
收费版本:收费版本一般都会由新的特性。国内绝大多数公司发行的版本都是收费的,例如Intel发行版本,华为发行版本等。
免费版本:不收费的版本主要有三个(都是国外厂商)。Cloudera版本(Cloudera’s Distribution Including Apache Hadoop)简称”CDH“。Apache基金会hadoop Hontonworks版本(Hortonworks Data Platform)简称“HDP”。按照顺序代表了国内的使用率,CDH和HDP虽然是收费版本,但是他们是开源的,只是收取服务费用,严格上讲不属于收费版本。
Ambari基于HDP安装,但是他们不同版本之间有不同的对应关系。
也就是支持最新的版本为HDP 3.1.5 而HDP包含了大数据的基本组件如下:
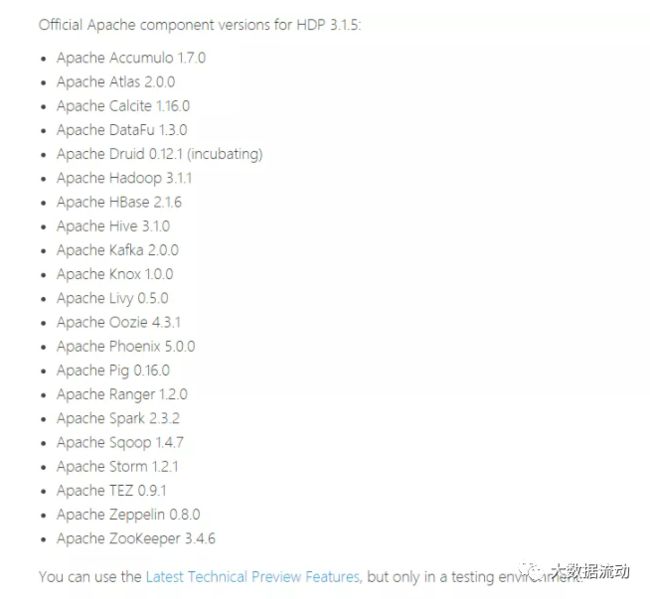
已经非常的丰富了,下面我们开始Ambari的安装。
前期准备
前期准备分为四部分
主机,数据库,浏览器,JDK
主机
请先准备好安装Ambari的主机,开发环境可以三台就ok,其他环境依据公司机器规模而确定。
假设开发环境的三台机器为:
192.168.12.101 master 192.168.12.102 slave1 192.168.12.103 slave2
主机的最低要求如下:
软件要求
在每个主机上:
yum和rpm(RHEL / CentOS / Oracle / Amazon Linux)zypper和php_curl(SLES)apt(Debian / Ubuntu)scp, curl, unzip, tar,wget和gcc*OpenSSL(v1.01,内部版本16或更高版本)
Python(带python-devel *)
Ambari主机应至少具有1 GB RAM,并具有500 MB可用空间。
要检查任何主机上的可用内存,请运行:
free -m本地仓库
如果网速不够快,我们可以将包下载下来,建立本地仓库。网速够快可以忽略这步。
先下载安装包
安装httpd服务
yum install yum-utils createrepo
[root@master ~]# yum -y install httpd
[root@master ~]# service httpd restart
Redirecting to /bin/systemctl restart httpd.service
[root@master ~]# chkconfig httpd on随后建立一个本地yum源
mkdir -p /var/www/html/将刚刚下载的包解压到这个目录下。
随后通过浏览器 访问 成功
createrepo ./
制作本地源 修改文件里边的源地址
vi ambari.repo
vi hdp.repo
#VERSION_NUMBER=2.7.5.0-72
[ambari-2.7.5.0]
#json.url = http://public-repo-1.hortonworks.com/HDP/hdp_urlinfo.json
name=ambari Version - ambari-2.7.5.0
baseurl=https://username:[email protected]/p/ambari/centos7/2.x/updates/2.7.5.0
gpgcheck=1
gpgkey=https://username:[email protected]/p/ambari/centos7/2.x/updates/2.7.5.0/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
[root@master ambari]# yum clean all
[root@master ambari]# yum makecache
[root@master ambari]# yum repolist软件准备
为了方便以后的管理,我们要对机器做一些配置
安装JDK
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
rpm -ivh jdk-8u161-linux-x64.rpm
java -version
通过vi /etc/hostname 进行修改机器名 这里主要是为了可以实现通过名称来查找相应的服务器
各个节点修改成相应的名称,分别为master,slave1.slave2
vi /etc/hosts
192.168.12.101 master
192.168.12.102 slave1
192.168.12.103 slave2
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master(其他的节点也对应修改)
关闭防火墙
[root@master~]#systemctl disable firewalld
[root@master~]#systemctl stop firewalld
ssh免密
ssh-keygen
ssh-copy-id -i ~/.ssh/id_rsa.pub remote-host不同的环境会有不同的问题存在,大家可以参考官网手册进行相应的安装。
安装ambari-server
ambariserver将最终带我们完成大数据集群的安装
yum install ambari-server
Installing : postgresql-libs-9.2.18-1.el7.x86_64 1/4
Installing : postgresql-9.2.18-1.el7.x86_64 2/4
Installing : postgresql-server-9.2.18-1.el7.x86_64 3/4
Installing : ambari-server-2.7.5.0-124.x86_64 4/4
Verifying : ambari-server-2.7.5.0-124.x86_64 1/4
Verifying : postgresql-9.2.18-1.el7.x86_64 2/4
Verifying : postgresql-server-9.2.18-1.el7.x86_64 3/4
Verifying : postgresql-libs-9.2.18-1.el7.x86_64 4/4
Installed:
ambari-server.x86_64 0:2.7.5.0-72
Dependency Installed:
postgresql.x86_64 0:9.2.18-1.el7
postgresql-libs.x86_64 0:9.2.18-1.el7
postgresql-server.x86_64 0:9.2.18-1.el7
Complete!启动与设置
设置
ambari-server setup不推荐直接用内嵌的postgresql,因为其他服务还要用mysql
安装配置 MySql
yum install -y wget
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
rpm -ivh mysql57-community-release-el7-10.noarch.rpm
yum -y install mysql-community-server
systemctl enable mysqld
systemctl start mysqld.service
systemctl status mysqld.service
grep "password" /var/log/mysqld.log
mysql -uroot -p
set global validate_password_policy=0;
set global validate_password_length=1;
set global validate_password_special_char_count=0;
set global validate_password_mixed_case_count=0;
set global validate_password_number_count=0;
select @@validate_password_number_count,@@validate_password_mixed_case_count,@@validate_password_number_count,@@validate_password_length;
ALTER USER 'root'@'localhost' IDENTIFIED BY 'password';
grant all privileges on . to 'root'@'%' identified by 'password' with grant option;
flush privileges;
exit
yum -y remove mysql57-community-release-el7-10.noarch
下载mysql驱动,放到三台的
/opt/ambari/mysql-connector-java-5.1.48.jar
初始化数据库
mysql -uroot -p
create database ambari;
use ambari
source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
CREATE USER 'ambari'@'localhost' IDENTIFIED BY 'bigdata';
CREATE USER 'ambari'@'%' IDENTIFIED BY 'bigdata';
GRANT ALL PRIVILEGES ON ambari.* TO 'ambari'@'localhost';
GRANT ALL PRIVILEGES ON ambari.* TO 'ambari'@'%';
FLUSH PRIVILEGES;完成ambari的配置
[root@localhost download]# ambari-server setup
Using python /usr/bin/python
Setup ambari-server
Checking SELinux...
SELinux status is 'enabled'
SELinux mode is 'permissive'
WARNING: SELinux is set to 'permissive' mode and temporarily disabled.
OK to continue [y/n] (y)? y
Customize user account for ambari-server daemon [y/n] (n)? y
Enter user account for ambari-server daemon (root):
Adjusting ambari-server permissions and ownership...
Checking firewall status...
Checking JDK...
[1] Oracle JDK 1.8 + Java Cryptography Extension (JCE) Policy Files 8
[2] Custom JDK
==============================================================================
Enter choice (1): 2
WARNING: JDK must be installed on all hosts and JAVA_HOME must be valid on all hosts.
WARNING: JCE Policy files are required for configuring Kerberos security. If you plan to use Kerberos,please make sure JCE Unlimited Strength Jurisdiction Policy Files are valid on all hosts.
Path to JAVA_HOME: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64/jre
Validating JDK on Ambari Server...done.
Check JDK version for Ambari Server...
JDK version found: 8
Minimum JDK version is 8 for Ambari. Skipping to setup different JDK for Ambari Server.
Checking GPL software agreement...
GPL License for LZO: https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
Enable Ambari Server to download and install GPL Licensed LZO packages [y/n] (n)? y
Completing setup...
Configuring database...
Enter advanced database configuration [y/n] (n)? y
Configuring database...
==============================================================================
Choose one of the following options:
[1] - PostgreSQL (Embedded)
[2] - Oracle
[3] - MySQL / MariaDB
[4] - PostgreSQL
[5] - Microsoft SQL Server (Tech Preview)
[6] - SQL Anywhere
[7] - BDB
==============================================================================
Enter choice (1): 3
Hostname (localhost):
Port (3306):
Database name (ambari):
Username (ambari):
Enter Database Password (bigdata):
Configuring ambari database...
Enter full path to custom jdbc driver: /opt/ambari/mysql-connector-java-5.1.48.jar
Copying /opt/ambari/mysql-connector-java-5.1.48.jar to /usr/share/java
Configuring remote database connection properties...
WARNING: Before starting Ambari Server, you must run the following DDL directly from the database shell to create the schema: /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
Proceed with configuring remote database connection properties [y/n] (y)? y
Extracting system views...
.....
Ambari repo file contains latest json url http://public-repo-1.hortonworks.com/HDP/hdp_urlinfo.json, updating stacks repoinfos with it...
Adjusting ambari-server permissions and ownership...
Ambari Server 'setup' completed successfully.随后就可以启动了
ambari-server start
ambari-server status
ambari-server stop访问如下地址
http://:8080 集群安装
接下来进行集群的安装,包括命名,ssh免密,选择版本,规划集群
最终完成集群安装,我们就可以在页面管理我们的集群了。
详细官网安装文档pdf请在关注“实时流式计算” 后台回复ambari
实时计算环境搭建
由于ambari支持的druid版本较低,目前暂不支持flink,所以除kafka外的实时计算组件,需要手动安装,也方便以后的升级。
Linux系统上安装flink
集群安装
集群安装分为以下几步:
1、在每台机器上复制解压出来的flink目录。
2、选择一个作为master节点,然后修改所有机器conf/flink-conf.yaml
jobmanager.rpc.address = master主机名3、修改conf/slaves,将所有work节点写入
work01
work024、在master上启动集群
bin/start-cluster.sh安装在Hadoop
我们可以选择让Flink运行在Yarn集群上。
下载Flink for Hadoop的包
保证 HADOOP_HOME已经正确设置即可
启动 bin/yarn-session.sh
运行flink示例程序
批处理示例:
提交flink的批处理examples程序:
bin/flink run examples/batch/WordCount.jar这是flink提供的examples下的批处理例子程序,统计单词个数。
$ bin/flink run examples/batch/WordCount.jar
Starting execution of program
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
(a,5)
(action,1)
(after,1)
(against,1)
(all,2)
(and,12)
(arms,1)
(arrows,1)
(awry,1)
(ay,1)Druid集群部署
部署建议
集群部署采用的分配如下:
主节点部署 Coordinator 和 Overlord进程
两个数据节点运行 Historical 和 MiddleManager进程
一个查询节点 部署Broker 和 Router进程
未来我们可以添加更多的主节点和查询节点
主节点建议 8vCPU 32GB内存
配置文件位于
conf/druid/cluster/master数据节点建议
16 vCPU 122GB内存 2 * 1.9TB SSD
配置文件位于
conf/druid/cluster/data查询服务器 建议 8vCPU 32GB内存
配置文件位于
conf/druid/cluster/query开始部署
下载0.17.0发行版
解压
tar -xzf apache-druid-0.17.0-bin.tar.gz
cd apache-druid-0.17.0集群模式的主要配置文件都位于:
conf/druid/cluster配置元数据存储
conf/druid/cluster/_common/common.runtime.properties替换
druid.metadata.storage.connector.connectURI
druid.metadata.storage.connector.host例如配置mysql为元数据存储
在mysql中配置好访问权限:
-- create a druid database, make sure to use utf8mb4 as encoding
CREATE DATABASE druid DEFAULT CHARACTER SET utf8mb4;
-- create a druid user
CREATE USER 'druid'@'localhost' IDENTIFIED BY 'druid';
-- grant the user all the permissions on the database we just created
GRANT ALL PRIVILEGES ON druid.* TO 'druid'@'localhost';在druid中配置
druid.extensions.loadList=["mysql-metadata-storage"]
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql:///druid
druid.metadata.storage.connector.user=druid
druid.metadata.storage.connector.password=diurd 配置深度存储
将数据存储配置为S3或者HDFS
比如配置HDFS,修改
conf/druid/cluster/_common/common.runtime.properties
druid.extensions.loadList=["druid-hdfs-storage"]
#druid.storage.type=local
#druid.storage.storageDirectory=var/druid/segments
druid.storage.type=hdfs
druid.storage.storageDirectory=/druid/segments
#druid.indexer.logs.type=file
#druid.indexer.logs.directory=var/druid/indexing-logs
druid.indexer.logs.type=hdfs
druid.indexer.logs.directory=/druid/indexing-logs将Hadoop配置XML(core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml)放在Druid中
conf/druid/cluster/_common/配置zookeeper连接
还是修改
conf/druid/cluster/_common/下的
druid.zk.service.host为zk服务器地址就可以了
启动集群
启动前注意打开端口限制
主节点:
derby 1527
zk 2181
Coordinator 8081
Overlord 8090
数据节点:
Historical 8083
Middle Manager 8091, 8100–8199
查询节点:
Broker 8082
Router 8088
记得将刚才配好的druid复制到各个节点
启动主节点
由于我们使用外部zk 所以使用no-zk启动
bin/start-cluster-master-no-zk-server启动数据服务器
bin/start-cluster-data-server启动查询服务器
bin/start-cluster-query-server这样的话 集群就启动成功了!
至此,我们的大数据环境基本搭建完毕,下一章我们将接入数据,开始进行标签的开发。
五、标签开发
数据接入
数据的接入可以通过将数据实时写入Kafka进行接入,不管是直接的写入还是通过oracle和mysql的实时接入方式,比如oracle的ogg,mysql的binlog
ogg
Golden Gate(简称OGG)提供异构环境下交易数据的实时捕捉、变换、投递。
通过OGG可以实时的将oracle中的数据写入Kafka中。

对生产系统影响小:实时读取交易日志,以低资源占用实现大交易量数据实时复制
以交易为单位复制,保证交易一致性:只同步已提交的数据
高性能
智能的交易重组和操作合并
使用数据库本地接口访问
并行处理体系
binlog
MySQL 的二进制日志 binlog 可以说是 MySQL 最重要的日志,它记录了所有的 DDL 和 DML 语句(除了数据查询语句select、show等),以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。binlog 的主要目的是复制和恢复。
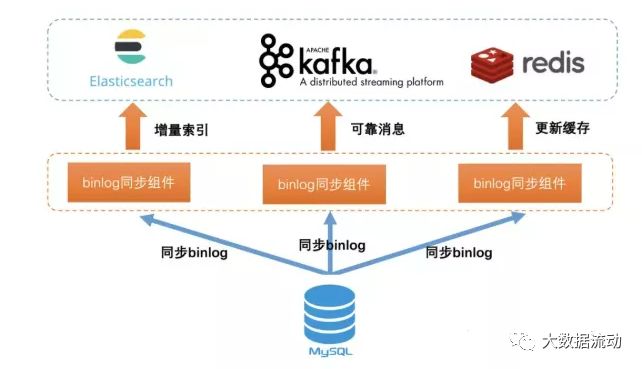
通过这些手段,可以将数据同步到kafka也就是我们的实时系统中来。
Flink接入Kafka数据
Apache Kafka Connector可以方便对kafka数据的接入。
依赖
org.apache.flink flink-connector-kafka_2.11 1.9.0 构建FlinkKafkaConsumer
必须有的:
1.topic名称
2.用于反序列化Kafka数据的DeserializationSchema / KafkaDeserializationSchema
3.配置参数:“bootstrap.servers” “group.id” (kafka0.8还需要 “zookeeper.connect”)
val properties = new Properties()properties.setProperty("bootstrap.servers", "localhost:9092")// only required for Kafka 0.8properties.setProperty("zookeeper.connect", "localhost:2181")properties.setProperty("group.id", "test")stream = env .addSource(new FlinkKafkaConsumer[String]("topic", new SimpleStringSchema(), properties)) .print()时间戳和水印
在许多情况下,记录的时间戳(显式或隐式)嵌入记录本身。另外,用户可能想要周期性地或以不规则的方式发出水印。
我们可以定义好Timestamp Extractors / Watermark Emitters,通过以下方式将其传递给消费者
val env = StreamExecutionEnvironment.getExecutionEnvironment()val myConsumer = new FlinkKafkaConsumer[String](...)myConsumer.setStartFromEarliest() // start from the earliest record possiblemyConsumer.setStartFromLatest() // start from the latest recordmyConsumer.setStartFromTimestamp(...) // start from specified epoch timestamp (milliseconds)myConsumer.setStartFromGroupOffsets() // the default behaviour//指定位置//val specificStartOffsets = new java.util.HashMap[KafkaTopicPartition, java.lang.Long]()//specificStartOffsets.put(new KafkaTopicPartition("myTopic", 0), 23L)//myConsumer.setStartFromSpecificOffsets(specificStartOffsets)val stream = env.addSource(myConsumer)检查点
启用Flink的检查点后,Flink Kafka Consumer将使用主题中的记录,并以一致的方式定期检查其所有Kafka偏移以及其他操作的状态。如果作业失败,Flink会将流式程序恢复到最新检查点的状态,并从存储在检查点中的偏移量开始重新使用Kafka的记录。
如果禁用了检查点,则Flink Kafka Consumer依赖于内部使用的Kafka客户端的自动定期偏移提交功能。
如果启用了检查点,则Flink Kafka Consumer将在检查点完成时提交存储在检查点状态中的偏移量。
val env = StreamExecutionEnvironment.getExecutionEnvironment()env.enableCheckpointing(5000) // checkpoint every 5000 msecsFlink消费Kafka完整代码:
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class KafkaConsumer {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); //构建FlinkKafkaConsumer FlinkKafkaConsumer myConsumer = new FlinkKafkaConsumer<>("topic", new SimpleStringSchema(), properties); //指定偏移量
myConsumer.setStartFromEarliest();
DataStream stream = env
.addSource(myConsumer);
env.enableCheckpointing(5000);
stream.print();
env.execute("Flink Streaming Java API Skeleton");
} 这样数据已经实时的接入我们系统中,可以在Flink中对数据进行处理了,那么如何对标签进行计算呢?标签的计算过程极大的依赖于数据仓库的能力,所以拥有了一个好的数据仓库,标签也就很容易计算出来了。
数据仓库基础知识
数据仓库是指一个面向主题的、集成的、稳定的、随时间变化的数据的集合,以用于支持管理决策的过程。
(1)面向主题 业务数据库中的数据主要针对事物处理任务,各个业务系统之间是各自分离的。而数据仓库中的数据是按照一定的主题进行组织的
(2)集成 数据仓库中存储的数据是从业务数据库中提取出来的,但并不是原有数据的简单复制,而是经过了抽取、清理、转换(ETL)等工作。业务数据库记录的是每一项业务处理的流水账,这些数据不适合于分析处理,进入数据仓库之前需要经过系列计算,同时抛弃一些分析处理不需要的数据。
(3)稳定 操作型数据库系统中一般只存储短期数据,因此其数据是不稳定的,记录的是系统中数据变化的瞬态。数据仓库中的数据大多表示过去某一时刻的数据,主要用于查询、分析,不像业务系统中数据库一样经常修改。一般数据仓库构建完成,主要用于访问

OLTP 联机事务处理 OLTP是传统关系型数据库的主要应用,主要用于日常事物、交易系统的处理 1、数据量存储相对来说不大 2、实时性要求高,需要支持事物 3、数据一般存储在关系型数据库(oracle或mysql中)
OLAP 联机分析处理 OLAP是数据仓库的主要应用,支持复杂的分析查询,侧重决策支持 1、实时性要求不是很高,ETL一般都是T+1的数据;2、数据量很大;3、主要用于分析决策;
星形模型是最常用的数据仓库设计结构。由一个事实表和一组维表组成,每个维表都有一个维主键。该模式核心是事实表,通过事实表将各种不同的维表连接起来,各个维表中的对象通过事实表与另一个维表中的对象相关联,这样建立各个维表对象之间的联系 维表:用于存放维度信息,包括维的属性和层次结构;事实表:是用来记录业务事实并做相应指标统计的表。同维表相比,事实表记录数量很多。

雪花模型是对星形模型的扩展,每一个维表都可以向外连接多个详细类别表。除了具有星形模式中维表的功能外,还连接对事实表进行详细描述的维度,可进一步细化查看数据的粒度 例如:地点维表包含属性集{location_id,街道,城市,省,国家}。这种模式通过地点维度表的city_id与城市维度表的city_id相关联,得到如{101,“解放大道10号”,“武汉”,“湖北省”,“中国”}、{255,“解放大道85号”,“武汉”,“湖北省”,“中国”}这样的记录。星形模型是最基本的模式,一个星形模型有多个维表,只存在一个事实表。在星形模式的基础上,用多个表来描述一个复杂维,构造维表的多层结构,就得到雪花模型。

清晰数据结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解 脏数据清洗:屏蔽原始数据的异常 屏蔽业务影响:不必改一次业务就需要重新接入数据 数据血缘追踪:简单来讲可以这样理解,我们最终给业务呈现的是能直接使用的一张业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。把复杂问题简单化。将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。

数据仓库的数据直接对接OLAP或日志类数据, 用户画像只是站在用户的角度,对数据仓库数据做进一步的建模加工。因此每天画像标签相关数据的调度依赖上游数据仓库相关任务执行完成。
在了解了数据仓库以后,我们就可以进行标签的计算了。在开发好标签的逻辑以后,将数据写入hive和druid中,完成实时与离线的标签开发工作。
Flink 与Hive和 Druid集成
Flink+Hive
Flink从1.9开始支持集成Hive,在Flink1.10版本,标志着对 Blink的整合宣告完成,随着对 Hive 的生产级别集成,Hive作为数据仓库系统的绝对核心,承担着绝大多数的离线数据ETL计算和数据管理,期待Flink未来对Hive的完美支持。
而 HiveCatalog 会与一个 Hive Metastore 的实例连接,提供元数据持久化的能力。要使用 Flink 与 Hive 进行交互,用户需要配置一个 HiveCatalog,并通过 HiveCatalog 访问 Hive 中的元数据。
添加依赖
要与Hive集成,需要在Flink的lib目录下添加额外的依赖jar包,以使集成在Table API程序或SQL Client中的SQL中起作用。或者,可以将这些依赖项放在文件夹中,并分别使用Table API程序或SQL Client 的-C 或-l选项将它们添加到classpath中。本文使用第一种方式,即将jar包直接复制到$FLINK_HOME/lib目录下。本文使用的Hive版本为2.3.4(对于不同版本的Hive,可以参照官网选择不同的jar包依赖),总共需要3个jar包,如下:
flink-connector-hive_2.11-1.10.0.jar
flink-shaded-hadoop-2-uber-2.7.5-8.0.jar
hive-exec-2.3.4.jar
添加Maven依赖
org.apache.flink
flink-connector-hive_2.11
1.10.0
provided
org.apache.flink
flink-table-api-java-bridge_2.11
1.10.0
provided
org.apache.hive
hive-exec
${hive.version}
provided
实例代码
package com.flink.sql.hiveintegration;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.catalog.hive.HiveCatalog;
public class FlinkHiveIntegration {
public static void main(String[] args) throws Exception {
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner() // 使用BlinkPlanner
.inBatchMode() // Batch模式,默认为StreamingMode
.build();
//使用StreamingMode
/* EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner() // 使用BlinkPlanner
.inStreamingMode() // StreamingMode
.build();*/
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "myhive"; // Catalog名称,定义一个唯一的名称表示
String defaultDatabase = "qfbap_ods"; // 默认数据库名称
String hiveConfDir = "/opt/modules/apache-hive-2.3.4-bin/conf"; // hive-site.xml路径
String version = "2.3.4"; // Hive版本号
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, version);
tableEnv.registerCatalog("myhive", hive);
tableEnv.useCatalog("myhive");
// 创建数据库,目前不支持创建hive表
String createDbSql = "CREATE DATABASE IF NOT EXISTS myhive.test123";
tableEnv.sqlUpdate(createDbSql);
}
}Flink+Druid
可以将Flink分析好的数据写回kafka,然后在druid中接入数据,也可以将数据直接写入druid,以下为示例代码:
依赖
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.1.8.RELEASE
com.flinkdruid
FlinkDruid
0.0.1-SNAPSHOT
FlinkDruid
Flink Druid Connection
1.8
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter
org.apache.flink
flink-core
1.9.0
org.apache.flink
flink-clients_2.12
1.9.0
org.springframework.boot
spring-boot-maven-plugin
示例代码
@SpringBootApplication
public class FlinkDruidApp {
private static String url = "http://localhost:8200/v1/post/wikipedia";
private static RestTemplate template;
private static HttpHeaders headers;
FlinkDruidApp() {
template = new RestTemplate();
headers = new HttpHeaders();
headers.setAccept(Arrays.asList(MediaType.APPLICATION_JSON));
headers.setContentType(MediaType.APPLICATION_JSON);
}
public static void main(String[] args) throws Exception {
SpringApplication.run(FlinkDruidApp.class, args);
// Creating Flink Execution Environment
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//Define data source
DataSet data = env.readTextFile("/wikiticker-2015-09-12-sampled.json");
// Trasformation on the data
data.map(x -> {
return httpsPost(x).toString();
}).print();
}
// http post method to post data in Druid
private static ResponseEntity httpsPost(String json) {
HttpEntity requestEntity =
new HttpEntity<>(json, headers);
ResponseEntity response =
template.exchange("http://localhost:8200/v1/post/wikipedia", HttpMethod.POST, requestEntity,
String.class);
return response;
}
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
} 标签的开发工作繁琐,需要不断的开发并且优化,但是如何将做好的标签提供出去产生真正的价值呢?下一章,我们将介绍用户画像产品化。
六、用户画像产品化
在开发好用户标签以后,如何将标签应用到实际其实是一个很重要的问题。只有做好产品的设计才能让标签发挥真正的价值,本文将介绍用户画像的产品化过程。
1、标签展示

首先是标签展示功能,这个主要供业务人员和研发人员使用,是为了更直观的看见整个的用户标签体系。
不同的标签体系会有不同的层级,那么这个页面的设计就需要我们展示成树状的结构,方便以后的扩展。
在最后一个层级,比如自然性别,可以设计一个统计页面,在进入页面后,可以展示相应的数据统计情况,
可以更直观看见标签中值得比例,也可以为业务提供好的建议,另外可以对标签的具体描述进行展示,起到一个说明的作用,还可以展示标签按天的波动情况,观察标签的变化情况。

这一部分的数据来源呢?之前也提到过,这些标签的元数据信息都存在mysql中,方便我们查询。
所以树状图和标签描述信息需要去mysql中获取,而比例等图表数据则是从Hbase,Hive中查询获取的,当然也有直接通过ES获取的。但是每天的标签历史波动情况,还是要通过每天跑完标签后存在mysql中作为历史记录进行展示。
2、标签查询
这一功能可以提供给研发人员和业务人员使用。
标签查询功能其实就是对用户进行全局画像的过程,对于一个用户的全量标签信息,我们是需要对其进行展示的。

输入用户id后,可以查看该用户的属性信息、行为信息、风控属性等信息。从多方位了解一个具体的用户特征。
这些已经是标签的具体信息了,由于是对单一id的查找,从hive中获取会造成查询速度的问题,所以我们更建议从Hbase或者ES中查询获取,这样查询效率和实时性都能获得极大的提升。
3、标签管理
这一功能是提供给研发人员使用的。
对于标签,不能每一次新增一个标签都进行非常大改动,这样是非常耗费人力的,所以必须要有可以对标签进行管理的功能。
这里定义了标签的基本信息,开发方式,开发人员等等,在完成标签的开发以后,直接在此页面对标签进行录入,就可以完成标签的上线工作,让业务人员可以对标签进行使用。
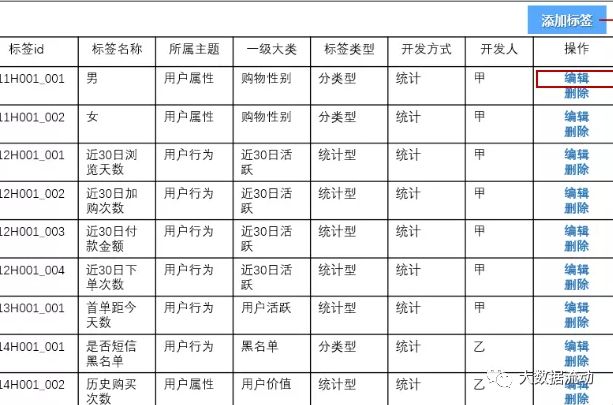
新增和编辑标签的页面,可以提供下拉框或者输入框提供信息录入的功能。

之前已经提到过,这些标签的元数据信息都保存在了Mysql中,只要完成对其的新增和修改就可以了。
4、用户分群
作为用户画像最核心的功能,用户分群功能。是用户画像与业务系统建立联系的桥梁,也是用户画像的价值所在。
这项功能主要供业务人员使用。
此功能允许用户自定义的圈定一部分人员,圈定的规则就是对于标签的条件约束。
在圈定好人群以后,可以对这部分人群提供与业务系统的外呼系统,客服系统,广告系统,Push系统的交互,达到真正的精细化运营的目的。

对于标签规则的判断,需要将记录好的规则存储于Mysql中,在进行人群计算时又需要将规则解析成可计算的逻辑。不管是解析成Sql或者其他的查询语言都难度巨大,这对于研发是一个非常大的挑战。

在此功能中,还可以增加人群对比的功能,对不同人群的不同标签进行圈定,对比。这对于查询性能也是一个巨大的考验。
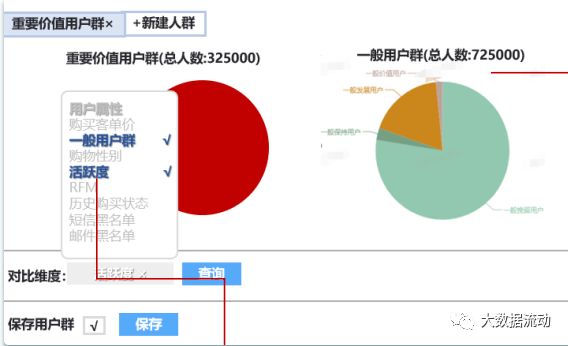
但是,用户分群功能作为用户画像的核心是我们必须要实现的。对于技术架构,Hbase更擅长与KV形式的查询,对于多维度查询性能较差,所以可以采取ES索引,在ES查询出Hbase的Rowkey,再去查询Hbase的方式。也有很多公司选择整体迁移到ES中完成此项工作。
本文档为用户画像入门宝典,介绍了用户画像的理论与系统搭建。也欢迎大数据、用户画像感兴趣的朋友加入学习群进行讨论交流~
如二维码过期请联系公众号大数据流动 作者 独孤风,备注用户画像,申请入群~
点击左下角“阅读原文”查看更多精彩文章,公众号推送规则变了,如果您想及时收到推送,麻烦右下角点个在看或者把本号星标并置顶!