python数据分析基础005 -pandas详解_pandas入门这一篇就足够了
文章目录
- 前言
- (一)pandas基础介绍
-
- 1.什么是pandas
- 2.为什么要学习pandas
- 3.pandas的安装
- 4.导入pandas库
- (二)pandas的常用数据类型
-
- 1.Series(一维,带标签数组)
-
- 1.1 创建索引
- 1.2 通过字典创建Series
- 1.3 Series的切片和索引
-
- 1.3.1 显示某个值
- 1.3.2 显示多个不连续的值
- 1.3.3 显示多个连续的值
- 1.3.4 通过索引查找值
- 1.4 Series的索引和值属性
-
- 1.4.1 Series的索引(index)
- 1.4.2 索引遍历
- 1.4.3 Series的值(values)
- 2.DataFrame(二维,Series容器)
-
- 2.1 创建索引
- 2.2 通过字典创建DataFrame
- 2.3 DataFrame的索引和切片
-
- 2.3.1 取前几行
- 2.3.2 取某列
- 2.3.3 取多列
- 2.4 利用DataFrame的loc和iloc方法取值
-
- ☘2.4.1 利用loc获取值
-
- 2.4.1.1 取某行
- 2.4.1.2 取多行
- 2.4.1.3 取某列
- 2.4.1.3 取多列
- 2.4.1.3 取某行某列
- 2.4.1.4 取多行多列
- 2.4.2 利用iloc来获取值
-
- 2.4.2.1 获取行
- 2.4.2.2 获取列
- 2.4.2.3 获取某行某列
- 2.4.2.4 获取多行多列
- 结语
作者简介:苏凉(在python路上)
博客主页:苏凉.py的博客
名言警句:海阔凭鱼跃,天高任鸟飞。
要是觉得博主文章写的不错的话,还望大家三连支持一下呀!!!
关注✨点赞收藏
前言
上期我们学习了numpy的基本使用,我们可以清楚的了解到numpy对于处理数值型数据非常乐观,那么在处理字符串类型的数据时,pandas将是最好的选择!接下来我们就一起进入pandas的学习吧!!
往期回顾:
python数据分析基础001 -matplotlib的基础绘图
python数据分析基础002 -使用matplotlib绘图(散点图,条形图,直方图)
python数据分析基础003 -numpy的使用(详解)
python数据分析基础004 -numpy读取数据以及切片,索引的使用
(一)pandas基础介绍

1.什么是pandas
Pandas 这个名字来源于面板数据(Panel Data)与数据分析(data analysis)这两个名词的组合。Pandas 是一个开源的第三方 Python 库,从 Numpy 和 Matplotlib 的基础上构建而来,享有数据分析“三剑客之一”的盛名(NumPy、Matplotlib、Pandas)。Pandas 已经成为 Python 数据分析的必备高级工具,它的目标是成为强大、灵活、可以支持任何编程语言的数据分析工具。
2.为什么要学习pandas
numpy能够帮我们处理处理数值型数据,但是这还不够。
很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等
比如:我们通过爬虫获取到了存储在数据库中的数据等等。
因此,numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我们处理其他类型的数据。
3.pandas的安装
pip install pandas -i https://pypi.douban.com/simple
4.导入pandas库
import pandas as pd
(二)pandas的常用数据类型
1.Series(一维,带标签数组)
import pandas as pd
a = pd.Series([1,5,4,85,87,512])
print(a,type(a))
结果:
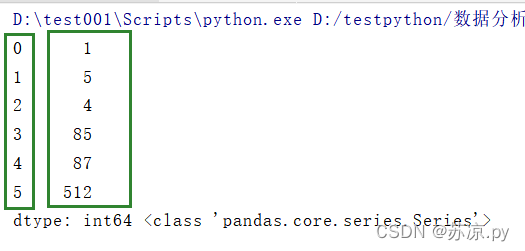
从上述结果中我们可以看到Series创建的对象带有索引。
1.1 创建索引
pd.Series([],index=list(string))
b = pd.Series([1,5,4,2,45,45,24,5],index=list('abcdefgh'))
print(b)
结果:

1.2 通过字典创建Series
通过字典也可以创建Series对象,此时字典的键为索引。
import pandas as pd
dic = {
'name':'苏凉.py',
'age':'22',
'qq_num':'787991021',
}
information = pd.Series(dic)
print(information)
结果:

1.3 Series的切片和索引
Series对象本质上由两个数组构成,一个数组构成对象的键(index,索引),一个数组构成对象的值(values),键->值
1.3.1 显示某个值
import pandas as pd
dic = {
'name':'苏凉.py',
'age':'22',
'qq_num':'787991021',
}
information = pd.Series(dic)
print(information)
print('-'*100)
print(information[0])
结果:
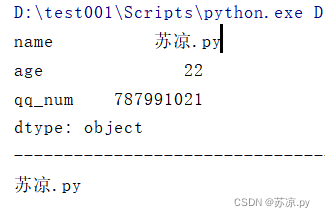
1.3.2 显示多个不连续的值
print(information[[0,2,3]])
结果:

1.3.3 显示多个连续的值
print(information[0:3])
结果:
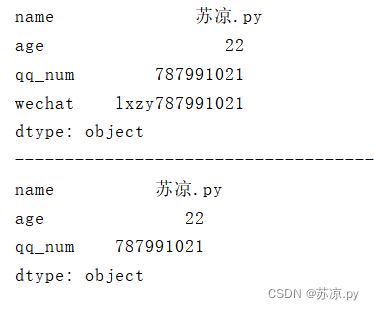
1.3.4 通过索引查找值
print(information[['name','age','wechat']])
结果:

1.4 Series的索引和值属性
对于一个陌生的Series类型,我们可以通过index和values来了解它的索引和值。
1.4.1 Series的索引(index)
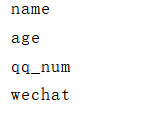
print(information.index)
结果:
![]()
1.4.2 索引遍历
a = information.index
for i in a:
print(i)
结果:
1.4.3 Series的值(values)
print(information.values)
结果:

2.DataFrame(二维,Series容器)
import pandas as pd
import numpy as np
a = pd.DataFrame(np.arange(1,13).reshape(3,4))
print(a)
结果:
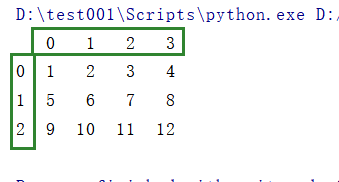
这里可以看到用DataFrame创建数组时存在行索引和列索引。
行索引:表明不同行,横向索引,叫index,0轴,axis=0.
列索引:表明不同列,纵向索引,叫columns,1轴,axis=1.
2.1 创建索引
pd.DataFrame([]),index=list(),columns=list()
a = pd.DataFrame(np.arange(1,13).reshape(3,4),index=list('123'),columns=list('ABCD'))
结果:

2.2 通过字典创建DataFrame
方法一:
import pandas as pd
list = {
'name':['苏凉.py','佚名'],
'age':['22','15'],
'QQ_num':['787991021','01234567'],
'wechat':['lxzy787991021','ym789456']
}
person = pd.DataFrame(list)
print(person)
结果:

方法二:
import pandas as pd
list2 = [
{'name':'苏凉.py','age':'22','QQ_num':'787991021','wechat':'lxzy787991021'},
{'name':'佚名','QQ_num':'01234567','wechat':'ym789456'}
]
person = pd.DataFrame(list2)
print(person)
结果:

这里可以看到当我们对应的位置没有输入值时结果NaN
2.3 DataFrame的索引和切片
注:在dataframe中进行取行或者取列操作时,[]中为数字则取行,[]中为字符串则取列!!
2.3.1 取前几行
print(person[:2])
结果:

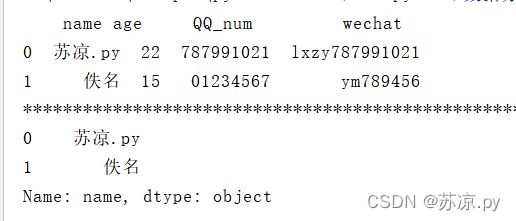
2.3.2 取某列
print(person['name'])
结果:
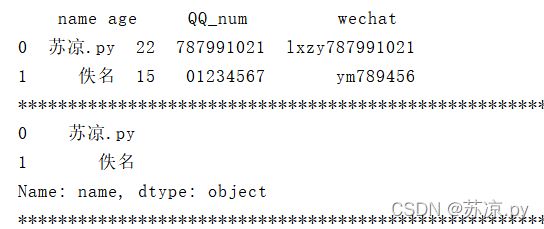
2.3.3 取多列
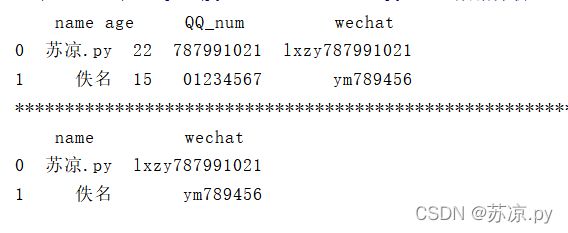
print(person[['name','wechat']])
结果:

2.4 利用DataFrame的loc和iloc方法取值
☘2.4.1 利用loc获取值
loc时通过标签索引来获取值
2.4.1.1 取某行
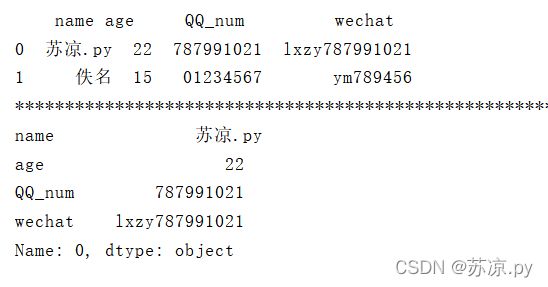
print(person.loc[1,:])
结果:
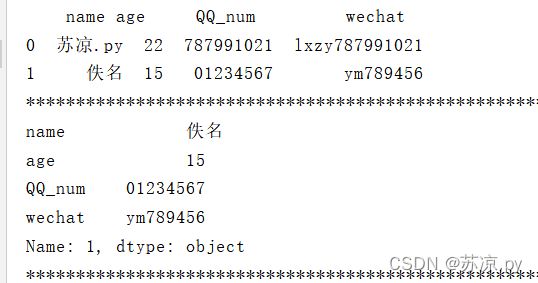
2.4.1.2 取多行
print(person.loc[[0,1]])
结果:

2.4.1.3 取某列
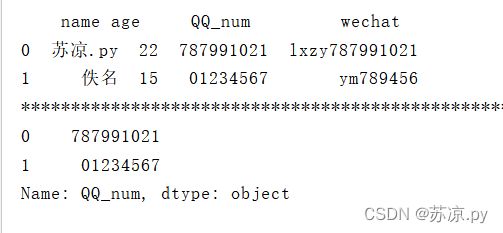
print(person.loc[:,'name'])
结果:
2.4.1.3 取多列
print(person.loc[:,['name','wechat']])
结果:
2.4.1.3 取某行某列
print(person.loc[0,'wechat'])
结果:

2.4.1.4 取多行多列
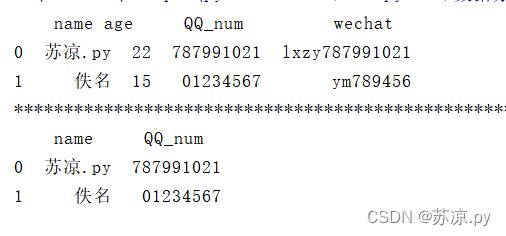
print(person.loc[0:1,['name','QQ_num']])
结果:
2.4.2 利用iloc来获取值
iloc是通过位置来获取值
下面列举四个例子即可:
2.4.2.1 获取行
print(person.iloc[0,])
结果:
2.4.2.2 获取列
print(person.iloc[:,2])
结果:
2.4.2.3 获取某行某列
print(person.iloc[0,3])
结果:

2.4.2.4 获取多行多列
print(person.iloc[[0,1],[0,2,3]])
结果:

结语
今天的内容到这里就结束啦,觉得写的不错的话给个三连支持一下吧!!文章有不足之处还望指出,一起加油进步啊!希望看到此文的小伙伴都有所收获!关注我,咱们下期再见!!
