机器学习笔记 - 杂记二
1、最新tensorflow检测GPU是否可用
import tensorflow as tf
tf.config.list_physical_devices('GPU')
2、Weka
Weka3:Java 机器学习软件
Weka 是用于数据挖掘任务的机器学习算法的集合。 它包含用于数据准备、分类、回归、聚类、关联规则挖掘和可视化的工具。
Weka 只在新西兰的岛屿上发现,是一种不会飞的鸟,具有好奇的天性。 名字是这样发音的,鸟声是这样的。
Weka 是在 GNU 通用公共许可证下发布的开源软件。
官网地址:Data Mining: Practical Machine Learning Tools and Techniques
3、IOU指标计算
IOU指标是目标检测中重要的评价指标,即交集与并集的比值。
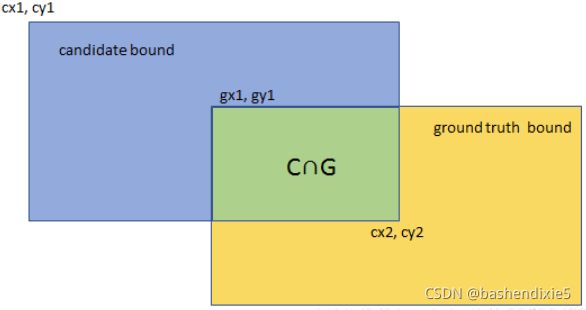
IOU的计算公式如下:![]()
# 真实框的坐标,宽高
gt_box = [gt_x, gt_y,gt_w,gt_h] = 1,1,4,5
# 预测框的坐标,宽高
c_box = [c_x, c_y,c_w,c_h] = 3,2,3,6
# IOU 计算函数
def IOU(gt_box, c_box):
W = (min((gt_box[0]+gt_box[2]), (c_box[0]+c_box[2])) - max(gt_box[0], c_box[0]))
H = (min((gt_box[1]+gt_box[3]), (c_box[1]+c_box[3])) - max(gt_box[1], c_box[1]))
inter = W * H
iou = inter / (gt_box[2] * gt_box[3] + c_box[2] * c_box[3] - inter)
print('iou is {}'.format(iou))
return iou
if __name__ = '__main__':
IOU(gt_box, c_box)
结果是:
iou is 0.266666666666666664、BLAS 线性代数库简介
参考:BLAS 简介 - 小时百科
BLAS(basic linear algebra subroutine) 是一系列基本线性代数运算函数的接口(interface)标准. 这里的线性代数运算是指例如矢量的线性组合, 矩阵乘以矢量, 矩阵乘以矩阵等. 接口在这里指的是诸如哪个函数名实现什么功能, 有几个输入和输出变量, 分别是什么.
BLAS 被广泛用于科学计算和工业界, 已成为业界标准. 在更高级的语言和库中, 即使我们不直接使用 BLAS 接口, 它们也是通过调用 BLAS 来实现的(如 Matlab 中的各种矩阵运算).
BLAS 原本是用 Fortran 语言写的, 但后来也产生了 C 语言的版本 cBLAS, 接口与 Fortran 的略有不同(例如使用指针传递数组), 但大同小异.
注意 BLAS 是一个接口的标准而不是某种具体实现(implementation). 简单来说, 就是不同的作者可以各自写出不同版本的 BLAS 库, 实现同样的接口和功能, 但每个函数内部的算法可以不同. 这些不同导致了不同版本的 BLAS 在不同机器上运行的速度也不同.
BLAS 的官网是http://www.netlib.org/blas/ http://www.netlib.org/blas/, 可以浏览完整的说明文档以及下载源代码. 这个版本的 BLAS 被称为 reference BLAS, 运行速度较慢, 通常被其他版本用于衡量性能. 对于 Intel CPU 的计算机, 性能最高的是 Intel 的 MKL (Math Kernel Library) 中提供的 BLAS. MKL 虽然不是一个开源软件, 但目前可以免费下载使用. 如果想要免费开源的版本, 可以尝试 OpenBLAS : An optimized BLAS librarySlate is a responsive theme for GitHub Pageshttps://www.openblas.net/ 或者 Automatically Tuned Linear Algebra Soft. download | SourceForge.nethttps://sourceforge.net/projects/math-atlas/
http://www.netlib.org/blas/, 可以浏览完整的说明文档以及下载源代码. 这个版本的 BLAS 被称为 reference BLAS, 运行速度较慢, 通常被其他版本用于衡量性能. 对于 Intel CPU 的计算机, 性能最高的是 Intel 的 MKL (Math Kernel Library) 中提供的 BLAS. MKL 虽然不是一个开源软件, 但目前可以免费下载使用. 如果想要免费开源的版本, 可以尝试 OpenBLAS : An optimized BLAS librarySlate is a responsive theme for GitHub Pageshttps://www.openblas.net/ 或者 Automatically Tuned Linear Algebra Soft. download | SourceForge.nethttps://sourceforge.net/projects/math-atlas/
5、常用深度学习图像/视频数据标注工具
(1)LabelImg - 支持VOC2012格式与tfrecord自动生成https://github.com/tzutalin/labelImg https://github.com/tzutalin/labelImg(2)Labelme - 支持对象检测、图像语义分割数据标注,实现语言为Python与QT。https://github.com/wkentaro/labelmehttps://github.com/wkentaro/labelme
https://github.com/tzutalin/labelImg(2)Labelme - 支持对象检测、图像语义分割数据标注,实现语言为Python与QT。https://github.com/wkentaro/labelmehttps://github.com/wkentaro/labelme
(3)RectLabel - 支持导出YOLO、KITTI、COCOJSON与CSV格式https://rectlabel.com/https://rectlabel.com/
(4)OpenCV/CVAT - 高效的计算机视觉标注工具,支持图像分类、对象检测框、图像语义分割、实例分割数据标注在线标注工具。支持图像与视频数据标注,最重要的是支持本地部署。GitHub - openvinotoolkit/cvat: Powerful and efficient Computer Vision Annotation Tool (CVAT)https://github.com/opencv/cvat
(5)VOTT - 微软发布的基于WEB方式本地部署的视觉数据标注工具GitHub - microsoft/VoTT: Visual Object Tagging Tool: An electron app for building end to end Object Detection Models from Images and Videos.https://github.com/microsoft/VoTT
(6)LableBox - WEB方式的标注工具https://github.com/Labelbox/Labelboxhttps://github.com/Labelbox/Labelbox
(7)VIA-VGG Image Annotator - VGG发布的基于WEB的图像标注工具
Visual Geometry Group - University of Oxfordhttp://www.robots.ox.ac.uk/~vgg/software/via/(8)PixelAnnotationTool - 图像语义分割与实例分割标注神器
https://github.com/abreheret/PixelAnnotationToolhttps://github.com/abreheret/PixelAnnotationTool(9)point-cloud-annotation-tool - 3D点云数据标注神器
https://github.com/springzfx/point-cloud-annotation-toolhttps://github.com/springzfx/point-cloud-annotation-tool(10)Boobs - 专属的YOLO BBox标注工具
https://github.com/drainingsun/boobshttps://github.com/drainingsun/boobs
6、Tensorflow中model.fit函数中的verbose
verbose:日志显示
verbose = 0 为不在标准输出流输出日志信息
verbose = 1 为输出进度条记录
verbose = 2 为每个epoch输出一行记录
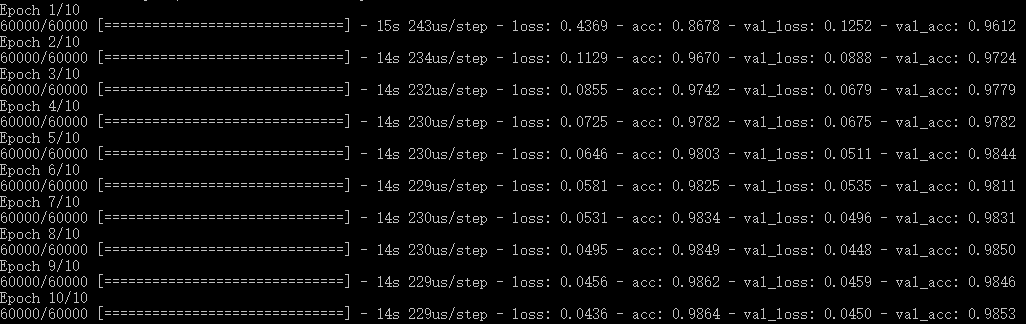 verbose = 1
verbose = 1
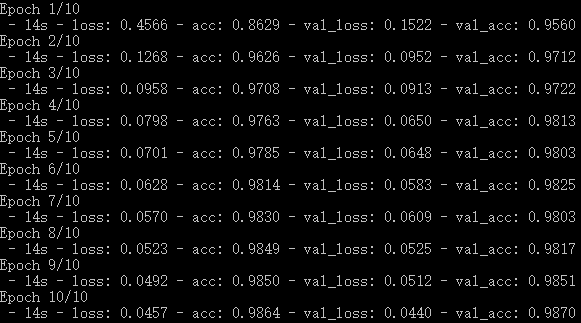 verbose = 2
verbose = 2
7、pandas 对每一列数据进行归一化
>>> import numpy as np
>>> import pandas as pd
Backend TkAgg is interactive backend. Turning interactive mode on.
>>> np.random.seed(1)
>>> df_test = pd.DataFrame(np.random.randn(4,4)* 4 + 3)
>>> df_test
0 1 2 3
0 9.497381 0.552974 0.887313 -1.291874
1 6.461631 -6.206155 9.979247 -0.044828
2 4.276156 2.002518 8.848432 -5.240563
3 1.710331 1.463783 7.535078 -1.399565
>>> df_test_1 = df_test
>>> df_test.apply(lambda x: (x - np.min(x)) / (np.max(x) - np.min(x))) #方法一
0 1 2 3
0 1.000000 0.823413 0.000000 0.759986
1 0.610154 0.000000 1.000000 1.000000
2 0.329499 1.000000 0.875624 0.000000
3 0.000000 0.934370 0.731172 0.739260
>>> (df_test_1 - df_test_1.min()) / (df_test_1.max() - df_test_1.min())#方法二
0 1 2 3
0 1.000000 0.823413 0.000000 0.759986
1 0.610154 0.000000 1.000000 1.000000
2 0.329499 1.000000 0.875624 0.000000
3 0.000000 0.934370 0.731172 0.7392608、神经网络不收敛的 11 个原因
- 忘记对你的数据进行归一化
- 忘记检查输出结果
- 没有对数据进行预处理
- 没有使用任何的正则化方法
- 使用了一个太大的 batch size
- 使用一个错误的学习率
- 在最后一层使用错误的激活函数
- 网络包含坏的梯度
- 网络权重没有正确的初始化
- 使用了一个太深的神经网络
- 隐藏层神经元数量设置不正确
9、对不平衡数据使用类别权重
# sklearn 直接提供了一个函数来计算类别权重:
# 计算类别权重
my_class_weight = class_weight.compute_class_weight('balanced'
,np.unique(train_Y)
,train_Y).tolist()
# 需要转成字典
class_weight_dict = dict(zip([x for x in np.unique(train_Y)], my_class_weight))
# 使用上面的字典
model.fit(class_weight = class_weight_dict )10、处理多分类问题的标签有两种方法
▪ 通过分类编码(也叫one-hot编码)对标签进行编码,然后使用categorical_crossentropy作为损失函数。
▪ 将标签编码为整数,然后使用sparse_categorical_crossentropy损失函数。