YOLOv5-yolov5s TensorRT部署准备之ONNX导出(第一篇)
下面的内容是对 YOLOv5-yolov5s TensorRT部署前的准备之导出可用的ONNX。
之前已经写过部分内容,但是还不够详细。
1. YOLOv5-6.0版本
以下内容以 6.0 版本为准。
修改导出文件:
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv2d
# 修改1:对于任何用到shape、size返回值的参数时,为了避免pytorch 导出 onnx 时候,对size 进行跟踪,跟踪时候会生成gather、shape的节点。使用 map 加上int转换。
bs, _, ny, nx = map(int,x[i].shape) # x(bs,255,20,20) to x(bs,3,20,20,85)
# 修改2:对于reshape、view操作时,-1的指定请放到batch维度。其他维度可以计算出来即可。batch维度禁止指定为大于-1的明确数字。所以这里 bs 改为 -1.
x[i] = x[i].view(-1, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
# export.py:model.train() if train else model.eval() # 264行: train=False, # model.train() mode 所以这里是 model.eval()模式, self.training 为 False,所以推理使用以下代码
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
# inplace 操作是直接在 y 上进行操作(5.0 版本中使用该操作)
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
# 非 inplace 操作,新建 xy, wh 变量,cat后赋值给 y
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
# (1, 3(na), 80, 80, 2) + (1, 3(na), 80, 80, 2) * 8
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
# (1, 3(na), 80, 80, 2) * (1, 3(na), 80, 80, 2)
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1) # -1 最后一个维度拼接 bs,3,80,80,85
# 修改3:原因同 修改2。bs为-1,int(y.size(1)*y.size(2)*y.size(3)) 为 3*80*80或3*40*40或3*20*20
z.append(y.view(-1, int(y.size(1)*y.size(2)*y.size(3)), self.no)) # -1,3*80*80,85 no = 85
# 修改4:去掉下面的x, 节省内存,最终模型输出一个节点
return x if self.training else torch.cat(z, 1)
# grid 网格 如 3*3 网格
def _make_grid(self, nx=20, ny=20, i=0):
d = self.anchors[i].device # 设备 cpu 或 'cuda:...'
# yv = [0, 0, 0
# 1, 1, 1
# 2, 2, 2]
# xv = [0, 1, 2
# 0, 1, 2
# 0, 1, 2]
yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])
# nx,ny,2 -> 1, na, nx,ny,2 # 参考:https://www.cnblogs.com/yanghailin/p/14329117.html
grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()
# 把 anchors * stride 得到 anchor_grid 还原到原图大小 一个head:shape: na(3),2 -> 1, na, 1, 1, 2 -> 1, na, ny,nx,2
anchor_grid = (self.anchors[i].clone() * self.stride[i]) \
.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()
return grid, anchor_grid导出 onnx 文件: 为了看模型各节点输出尺寸,我们加上 --simplify
python export.py --include onnx --simplify
YOLOv5有3个head,假设输入图像大小为640,那么 输出为:
Bs *128*80*80;Bs*256*40*40;Bs*512*20*20;
如下图中Detect所示:


注:这里onnx图中,Bs = 1。
Bs*128*80*80; Bs*256*40*40; Bs*512*20*20; ------》》》
Bs*3*80*80*85; Bs*3*40*40*85; Bs*3*20*20*85;
注:3为每个cell 的Anchors数目,85 = x, y, w, h, obj, 80类 (排序就是这样)。
推理模式:
export.py:264: train=False, # model.train() mode
295:model.train() if train else model.eval() # training mode = no Detect() layer grid construction # 这里是 model.eval()
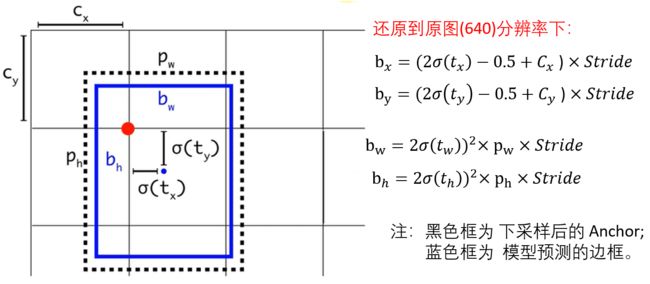
注:这里 Stride 为 模型下采样的倍数,YOLOv5 3个head 下采样为:8(80);16(40);32(20)。
上图中的 C_x与C_y 对应代码中的 self.grid;p_w*Stride和p_h*Stride对应代码中的 anchor_grid。
上图中的操作:
代码中是 for 循环三个head输出。下面以 80*80 head 为例说明:
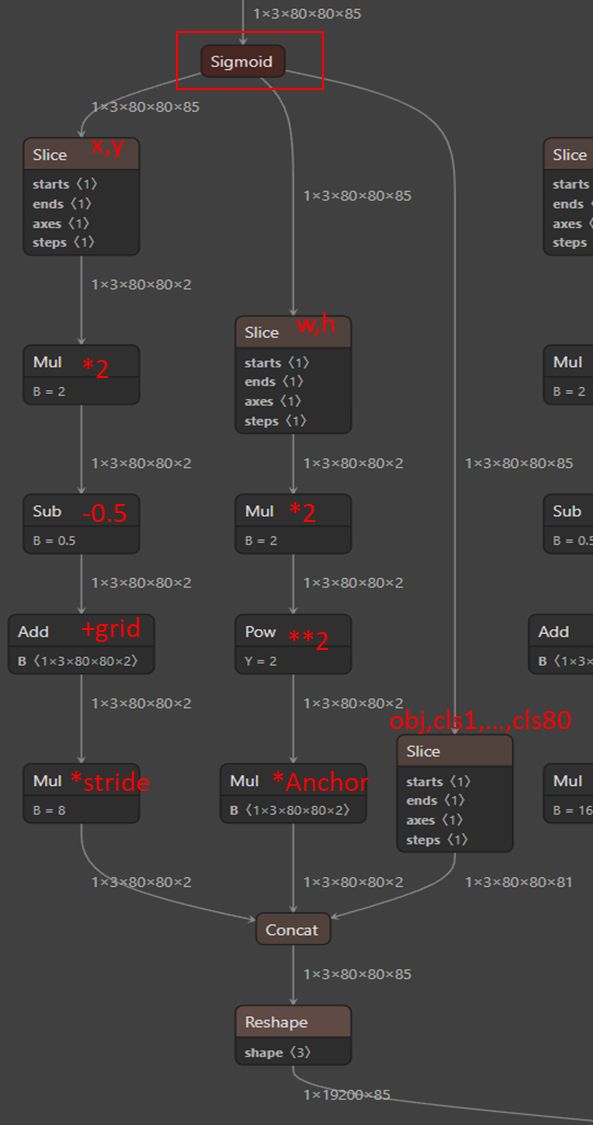
问题:这里 w, h 为什么没有乘 Stride ? 原因:anchor_grid 已经是 640 尺度下的,故 anchor_grid大小隐含了 Stride(上面代码中: self.anchors[i].clone() * self.stride[i])。
所以,最后每个head输出:

上图中的操作放到 onnx 中做, 在C++ 推理decode该张量的时候就会很简单。后面C++代码中只需要 for 循环 25200次, 每次取出满足条件的;然后再 NMS,就结束了。
补充:避免使用inplace操作,例如y[…, 0:2] = y[…, 0:2] * 2 - 0.5
代码中:
# 训练时候没影响,导出onnx问题很大,v6.0 默认使用的 非inplace 操作
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh导出时候如果:export.py
m.inplace = inplace
parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
python export.py --include onnx --inplace
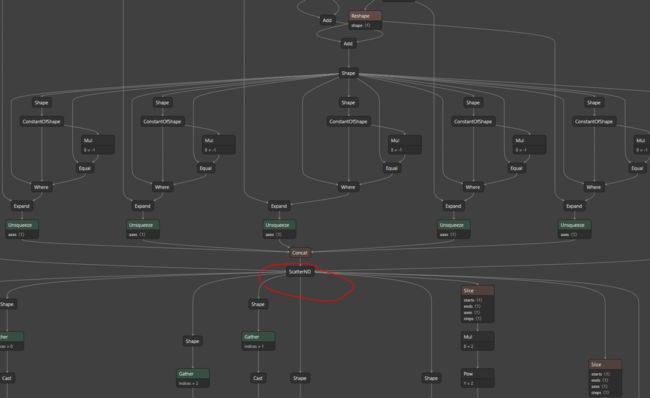
上图可知,多了很多节点,并且还有 ScatterND节点,这种需要插件支持,这么复杂推理时候容易失败,所以不能 --inplace 导出。
目前未理解问题:yolo.py 中的 if self.grid[i].shape[2:4] != x[i].shape[2:4] : 是啥意思?
未解决:我尝试debug 找到 grid 在哪里进行的初始化,但是我并没有找到,只找到了:
models/experimental.py: model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().fuse().eval()) # FP32 model ->
models/yolo.py: m = self.model[-1] # Detect()
然后被初始化为:
x : [1, 255, 4, 4],[1, 256, 2, 2],[1, 512, 1, 1]
self.grid: [1, 1, 84, 44, 2],[1, 1, 42, 22, 2],[1, 1, 21, 11, 2]
84, 44 != 4, 4,就画网格。
真正推理时候:x : [1, 3, 80, 80, 85], [1, 3, 40, 40, 85], [1, 3, 20, 20, 85]
84, 44 != 80, 80;42, 22 != 40,40;21, 11 != 20,20;
然后就画网格呗。
得到: self.grid[i]:1, na, ny, nx, 2;self.anchor_grid[i] : 1, na, ny, nx, 2
# nx,ny,2 -> 1, na, ny,nx,2
grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()
# 把 anchors * stride 得到 anchor_grid 还原到原图大小 一个head:shape: na(3),2 -> 1, na, 1, 1, 2 -> 1, na, ny, nx, 2
anchor_grid = (self.anchors[i].clone() * self.stride[i]) \
.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()上面代码的维度变换的目的是为了能够和输出维度对应起来便于操作。
2. YOLOv5-5.0版本
YOLOv5-5.0版本 的默认onnx 导出没有进行上面的操作,也就是执行 python models/export.py 会得到3个输出。想得到 合并后的输出可以使用:
python models/export.py --grid
原因:
self.training |= self.export parser.add_argument('--grid', action='store_true', help='export Detect() layer grid')
model.model[-1].export = not opt.grid # set Detect() layer grid export然后按 6.0v 修改4处class Detect。
再使用上面命令导出,出现了 inplace 问题。修改代码如下,然后导出即可。
# y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
# y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
# z.append(y.view(bs, -1, self.no))
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(-1, int(y.size(1)*y.size(2)*y.size(3)), self.no))
return x if self.training else torch.cat(z, 1)注: self.anchor_grid[i].view(1, self.na, 1, 1, 2) 做了维度变换才能和前面的相乘。
参考:
详解TensorRT的C++/Python高性能部署,实战应用到项目_哔哩哔哩_bilibili