感知器 Perceptron
现在你看到了一个简单的神经网络如何做决策:输入数据,处理信息,然后给出一个结果作为输出!现在让我们深入这个大学录取的案例,来学习更多输入数据如何被处理。
数据,无论是考试成绩还是评级,被输入到一个相互连接的节点网络中。这些独立的节点被称作感知器 或者神经元。它们是构成神经网络的基本单元。每一个依照输入数据来决定如何对数据分类。 在上面的例子中,输入的评级或者成绩要么通过阈值 (threshold) 要么通不过。这些分类组合形成一个决策 - 例如,如果两个节点都返回 “yes“,这个学生就被学校录取了。
让我们进一步放大来看一个单个感知器如何处理输入数据。
上面的感知器是视频中来决定学生是否被录取的两个感知器中的一个。它决定了学生的评级是否应该被学校录取。你也许会问:“它怎么知道在做录取决定的时候是分数更重要还是评级更重要呢?”。事实上,当我们初始化神经网络的时候,是不知道那个信息对决定更重要的。这需要由神经网络自己学出来 哪个数据更重要,然后来调整它如何使用那个数据。
它通过一个叫做Weights(权值)的东西来做这件事。
Weights(权值)
当数据被输入感知器,它会跟分配给这个输入的制定的 weights 相乘。例如,上面的感知器有两个输入,tests和 grades,所以它有两个与之相关的 weights,并且可以分别调整。这些权重刚开始是随机值,当神经网络学到什么样的输入数据会使得学生被学校录取之后,网络会根据之前 weights 下分类的错误来调整 weights,这也被称作是神经网络的训练。
一个更大的 weights 意味着神经网络认为这个输入比其它输入更重要,小 weights 意味着数据不是那么重要。一个极端的例子是,如果 test 成绩对学生录取没有影响,那么 test 分数的 weight 就会是零,也就是说,它对感知器的输出没有影响。
输入数据加总
所以,每个感知器的输入需要有一个关联的权重代表它的重要性,这个权重是由神经网络的学习过程决定的,也就是训练。接下来,经过加权的输入数据被加总,生成一个单独的直,它会帮助实现最终输出 - 也就是这个学生是否被录取。让我们看一个实际的例子:
我们把 x_test 跟它的权重 w_test 做点乘再与 x_grades 与w_grades 点乘的结果相加。
在写跟神经网络有关的公式的时候,权重总是被各种样式的字母 w 来表示。W通常表示权重矩阵,而w被用来表示单个权重。有时还会有些额外的信息以下标的形式给出(后面会见到更多)。记住你看到字母w,想到权重是不会错的。
在这个例子中,我们用 wgrades 来表示 grades 的权重,wtest 来表示 test 的权重。在上图中,权重是 wgrades=−1,wtest =−0.2。你不用关注它们具体的值,他们的比值更重要。wgrades 是 wtest 的5倍,代表神经网络认为在判断学生是否能被大学录取时, grades 的重要性是 test 的5倍。
感知器把权重和输入做点积并相加再加总的过程叫做 线性组合。在这里也就是
wgrades⋅xgrades+wtest⋅xtest=−1⋅xgrades−0.2⋅xtest.
为了让我们的公式更简洁,我们可以把名称用数字表示。用 1 来表示 grades,2 来表示 tests. 我们的公式就变成了:
w1⋅x1+w2⋅x2
在这个例子中,我们只有两个简单的输入。grades 和 tests。试想如果我们有 m 个不同的输入可以把他们标记成 x1,x2,...,xm。对应x1 的权重是 w1 以此类推。在这里,我们的线性组合可以简洁的写成:
∑i=1mwi⋅xi
这里,希腊字母 Sigma ∑ 用来表示 求和。它意思是求解右边表达式,并把结果加总。也就是说,这里求了. wi⋅xi 的和。
但是我们从哪里找到 wi 和 xi?
∑i=1m 意思是遍历所有 i 值, 1 到 m。
这些都组合在一起 ∑i=1mwi⋅xi 表示:
- 求 w1⋅x1 并记住结果
- 让 i=2
- 求 w2⋅x2 的值并把它加到 w1⋅x1
- 重复这个过程直到 i=m,m 是输入的个数
最后,无论是我们这里还是你自己的阅读中,你都会看到公式有很多种写法。例如:你会看到 ∑i 而不是 ∑i=1m。第一个只是第二个的简写。也就是说你看到一个求和没有截止点,意思就是把它们都加起来。有时候,如果遍历的值可以被推断,你可能会看到一个单独的 ∑。记住,它们都是相同的:∑i=1mwi⋅xi=∑iwi⋅xi=∑wi⋅xi
计算激活函数的输出
最后,感知器求和的结果会被转换成输出信号,这是通过把线性组合传给 激活函数 来实现的。
当输入给到节点,激活函数可以决定节点的输出。因为它决定了实际输出,我们也把层的输出,称作“激活”。
最简单的激活函数之一是单位阶跃函数(Heaviside step function)。如果线性组合小于0,函数返回0,如果线性组合等于或者大于0,函数返回1。单位阶跃函数(Heaviside step function) 如下图, h 是线性组合的结果:
单位阶跃函数 Heaviside Step Function
在上面这个大学录取的例子中,我们用了 wgrades=−1,wtest =−0.2 作为权重。因为 wgrades 都是负值 wtest 激活函数只有在 grades 和 test 都是0的时候返回1。这是由于用这些权重和输入做线性组合的取值范围是 (−∞,0] (负无穷到0,包括0)。
用个两维的数据看起来最容易。在下面这幅图中,想象线上的任何一点以及阴影部分,代表所有可能对节点的输入。y轴表示对输入和合适的权重的线性组合的结果。这个结果作为激活函数的输入。
记得我们说过,单位阶跃函数对任何大于等于0的输入,都返回 1 像你在图中看到的,只有一个点的 y 值大于等于0: 就是 (0,0)原点:
当然,我们想要更多可能的 grade/test 组合在录取组里,所以我们需要对我们的激活函数做调整是的它对更多的输入返回 1 特别是,我们要找到一种办法,让所有我们希望录取的人输入和权重的线性组合的值大于等于0。
使得我们函数返回更多 1 1 的一种方式是往我们线性组合的结果里加上一个 偏置项(bias)。
偏置项在公式中用 b 来表示,让我们移动一下各个方向上的值。
例如,下图蓝色部分代表先前的假设函数加了 +3 的偏置项。蓝色阴影部分表示所有激活的值。注意,这个结果的输入,跟之前灰色部分的输入是一样的,只是加了偏置项之后,它变得更高了。
现在,我们并不能实现知道神经网络改如何选择偏置项。但没关系,偏置项跟权重一样,可以在训练神经网络的时候更新和改变。增加了权重之后,我们有了一个完整的感知器公式:
Perceptron Formula
输入 (x1,x2,...,xm) 如果属于被录取的学生,公式返回 1 if the input (x1,x2,...,xm) 不被录取的学生,公式返回 0。输入是由一个或多个实数组成,每一个由xi 代表,m 则代表总共有多少个输入。
然后神经网络开始学习!起初,权重 ( wi) 和偏置项 (b) 是随机值,它们用一种学习算法来更新。权重和偏置项的更新使得下一个训练样本更准确地被归类,数据中蕴含的模式,也就被神经网络“学”出来了。
现在你对感知器有了很好的理解,让我们把学到的只是予以应用。接下来,你将从之前神经网络的视频中来学习通过设定权重和偏置项来创建一个 AND 感知器。
AND 感知器练习
AND 感知器的权重和偏置项是什么?
把权重 (weight1, weight2) 和偏置项 bias 设置成正确的值,使得 AND 可以实现上图中的运算。
在这里,在上图中可以看出有两个输入(我们把第一列叫做input1,第二列叫做 input2),在感知器公式的基础上,我们可以计算输出。
首先,线性组合就是权重与输入的点积:linear_combination = weight1*input1 + weight2*input2,然后我们把值带入单位阶跃函数与偏置项相结合,给到我们一个(0 或 1)的输出:
最简单的神经网络
目前为止,我们接触的感知器的输出是非 0 即 1。输入到输出经过一个激活函数 f(h) 例如这里的阶跃函数。
阶跃激活函数
输出单位返回的是 f(h) 的结果, h 是输出单位的输入:
h=∑iwixi+b
下面的图表展示了一个简单的神经网络。权重,输入和偏置项的线性组合 h 通过激活函数 f(h),给出感知器最终的输出,标记为 y。
神经网络示意图,圈代表单位,方块是操作。
这个架构最酷的一点就是,也是神经网络可以做到的,就是激活函数 f(h) 可以是 任何函数,并不只是上面提到的阶跃函数。
例如,如果让 f(h)=h,输出等与输入,那网络的输出就是:
y=∑iwixi+b
你应该非常熟悉这个公式,它跟线性回归模型是一样的!
其它常见激活函数还有对数几率(又称作 sigmoid),tanh 和 softmax。这节课中我们主要使用 sigmoid 函数:
sigmoid(x)=1/(1+e−x)
sigmoid 函数
sigmoid 函数值域是 0 到 1之间,它的输出还可以被解释为成功的概率。实际上,用 sigmoid 函数作为激活函数的结果,跟对数几率回归是一样的。
这就是感知器到神经网络的改变,在这个简单的网络中,跟通常的线性模型例如对数几率模型相比,神经网络还没有展现出任何优势。
如你之前所见,在 XOR 感知器中,把感知器组合起来可以让我们对线性不可分的数据建模。
但是,如你所见,在 XOR 感知器中,虽然把感知器组合起来可以对线性不可分的数据建模,但是却无法对回归模型建模。
你一旦开始用连续且可导的激活函数后,就能够运用梯度下降来训练网络,这就是你接下来将要学到的。
简单网络练习
接下来你要用 NumPy 来计算一个简单网络的输出,它有两个输入,一个输出,激活函数是 sigmoid。你需要做的有:
- 实现 sigmoid 激活函数
- 计算神经网络输出
sigmoid 函数公式是:
sigmoid(x)=1/(1+e−x)
指数你可以使用 NumPy 的指数函数 np.exp。
这个网络的输出为:
y=f(h)=sigmoid(∑iwixi+b)
点积你可以让元素相乘再相加,或者使用 NumPy 的 点乘函数.
import numpy as np
def sigmoid(x):
# TODO: Implement sigmoid function
return 1/(1 + np.exp(-x))
inputs = np.array([0.7, -0.3])
weights = np.array([0.1, 0.8])
bias = -0.1
# TODO: Calculate the output
output = sigmoid(np.dot(weights, inputs) + bias)
print('Output:')
print(output)
权重学习
你了解了如何使用感知器来构建 AND 和 XOR 的操作,但它们的权重都是人为设定的。但如果有一个操作,例如预测大学录取结果,你不知道正确的权重是什么怎么办?你要从样本中学习权重,然后用这些权重来做预测。
要了解我们如何找到这些权重,可以从我们的目标开始考虑。我们想让网络做出的预测与真实值尽可能接近。为了能够衡量,我们需要有一个指标来了解预测有多差,也就是误差。一个普遍的指标是误差平方和 sum of the squared errors (SSE):
E=21∑μ∑j[yjμ−y^jμ]2
这里 y^ 是预测值 y 是真实值。一个和是所有输出的和 j,另一个是所有数据点的和 μ。这里看上去很复杂,但你一旦理解了这些符号之后,你就能明白这是怎么回事了。
首先是里面 j 部分的和。变量 j 代表网络输出。所以这里面的和是指每一个输出 y^,与真实值 y 之间的差的平方,再加总。
另一个和 μ 指所有的数据点。也就是说,对每一个数据点,你计算它输出的方差,然后把这些方差和在一起。这就是你整个输出的总误差。
SSE 是一个很好的选择有几个原因:误差的平方总是正的,对大误差的惩罚大于小的误差。同时,它对数学运算也更友好。
记住神经网络的输出,也就是预测,取决于权重
y^jμ=f(∑iwijxiμ)
相应的,误差也取决于权重
E=21∑μ∑j[yjμ−f(∑iwijxiμ)]2
我们想让网络预测的误差尽可能小,权重是让我们能够实现这个目的调节旋钮。我们的目的是寻找权重 wij 使得误差平方 E 最小。通常来说神经网络通过梯度下降来实现这一点。
梯度是改变率或者斜度的另一个称呼。如果你需要回顾这个概念,可以看下可汗学院对这个问题的讲解。
要计算变化率,我们要转向微积分,具体来说是导数。一个函数 f(x) 的导函数 f′(x) 给到你的是 f(x) 在 x 这一点的斜率。例如 x2 ,x2 的导数是 f′(x)=2x。所以,在 x=2 这个点斜率 f′(2)=4。画出图来就是:

Example of a gradient
梯度就是对多变量函数导数的泛化。我们可以用微积分来寻找误差函数中任意一点的梯度,它与输入权重有关,下一节你可以看到如何推导梯度下降的步骤。
下面我画了一个神经网络误差示例,它有两个输入,相应的有两个权重。你可以像读地形图那样读它,每条线代表相同的误差,深色的线对应大的误差。
在每一步,你计算误差和梯度,然后用它们来决定如何改变权重。重复这个步骤直到你最终找到接近误差函数最小值的权重,也就是中间这个黑色的点。
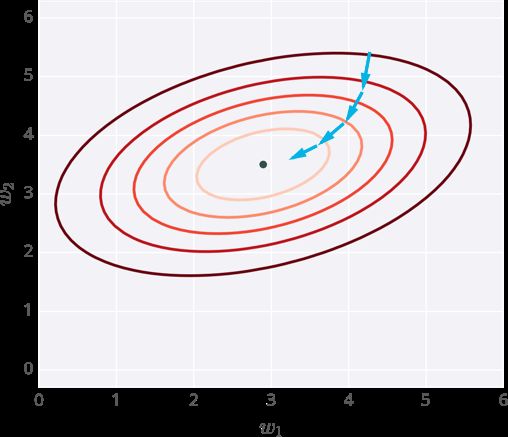
Gradient descent steps to the lowest error
注意
因为权重会走向梯度带它去的位置,他们有可能停留在误差小,但不是最小的地方。这个点被称作局部最低点。如果权重初始值有错,梯度下降可能会使得权重陷入局部最优,例如下图所示。

梯度下降引向局部最低点
有方法可以避免这一点,被称作 momentum.
梯度下降:代码
之前我们看到一个权重的计算是:
Δwi=ηδxi
这里 error term δ 是指
δ=(y−y^)f′(h)=(y−y^)f′(∑wixi)
记住,上面公式中 (y−y^) 是输出误差,f′(h) 是激活函数 f(h) 的导函数,我们把这个导函数称做输出的梯度。
现在假设只有一个输出,我来把这个写成代码。我们还是用 sigmoid 来作为激活函数 f(h)。
# Defining the sigmoid function for activations
# 定义 sigmoid 激活函数
def sigmoid(x):
return 1/(1+np.exp(-x))
# Derivative of the sigmoid function
# 激活函数的导数
def sigmoid_prime(x):
return sigmoid(x) * (1 - sigmoid(x))
# Input data
# 输入数据
x = np.array([0.1, 0.3])
# Target
# 目标
y = 0.2
# Input to output weights
# 输入到输出的权重
weights = np.array([-0.8, 0.5])
# The learning rate, eta in the weight step equation
# 权重更新的学习率
learnrate = 0.5
# the linear combination performed by the node (h in f(h) and f'(h))
# 输入和权重的线性组合
h = x[0]*weights[0] + x[1]*weights[1]
# or h = np.dot(x, weights)
# The neural network output (y-hat)
# 神经网络输出
nn_output = sigmoid(h)
# output error (y - y-hat)
# 输出误差
error = y - nn_output
# output gradient (f'(h))
# 输出梯度
output_grad = sigmoid_prime(h)
# error term (lowercase delta)
error_term = error * output_grad
# Gradient descent step
# 梯度下降一步
del_w = [ learnrate * error_term * x[0],
learnrate * error_term * x[1]]
# or del_w = learnrate * error_term * x
实现梯度下降
现在我们知道了如何更新我们的权重:
Δwij=ηδjxi,
你看到的是如何实现一次更新,那我们如何把代码转化为能够计算多次权重更新,使得我们的网络能够真正学习呢?
我们拿一个研究生学院录取数据来用梯度下降训练一个网络。数据可以在这里找到。数据有三个输入特征,GRE分数,GPA,和本科院校排名(从1到4)。数字1代表最好,数字4代表最差。
我们的目标是基于这些特征来预测一个学生能否被研究生院录取。这里,我们用有一个输出层的网络。用 sigmoid 做为激活函数。
数据清理
你也许认为有三个输入特征,但是首先我们要做数据转换。rank 是类别特征,数字并不包含任何想对的值。排名第 2 并不是排名第 1 的两倍;排名第 3 也不是排名第 2 的 1.5 倍。因此,我们需要用 dummy variables 来对rank进行编码。把数据分成 4 个新列,用 0 或 1 表示。排名第一的行 rank 1那一列的值是 1 ,其它是 0;排名第二的行 rank 2 那一列的值是 1 ,其它是 0,以此类推。
我们还需要把 GRE 和 GPA 分数标准化,也就是说使得他们的平均值是 0,标准差是 1。因为 sigmoid 函数会挤压很大或者很小的输入,所以这一步是必要的。很大或者很小输入的梯度是 0 意味着梯度下降的步长也会是 0。因为 GRE 和 GPA 的值都相对较大,我们在初始化权重的时候要非常小心,否则梯度下降就会死亡,网络也没发训练了。如果我们对数据做了标准化处理,我们能更容易地对权重进行初始化。
这只是一个简单介绍,你之后还会学到如何预处理数据,如果你想了解我是怎么做的,可以查看下面编程练习中的 data_prep.py 文件。
经过转换后的10行数据
现在数据已经准备好了,我们看到有六个输入特征:gre, gpa,和四个rank 的虚拟变量 (dummy variables)。
均方差
这里我们要对如何计算误差做一点小改变。除了SSE,我们这里用误差平方的平均数(mean of the square errors,MSE)。现在我们要处理很多数据,把所有权重更新加起来会导致很大的更新,使得梯度下降无法收敛。为了避免这种情况,你需要一个很小的学习率。这里我们还可以除以数据点的数量 m 来取平均。这样,无论我们有多少数据,我们的学习率通常会在 0.01 to 0.001 之间。我们用 MSE(下图)来计算梯度,结果跟之前一样,只是取了平均而不是取和。
这是用梯度下降来更新权重的算法概述:
- 权重更新初始为 0: Δwi=0
- 训练数据中的每一条记录:
- 通过网络做正向传播,计算输出 y^=f(∑iwixi)
- 计算输出的 error term, δ=(y−y^)∗f′(∑iwixi)
- 更新权重步长 Δwi=Δwi+δxi
- 更新权重 wi=wi+ηΔwi/m。 η 是学习率, m 是数据点个数。 这里我们对权重步长做了平均,为的是降低训练数据中大的变化。
- 重复 e 代(epoch)。
你也可以选择每一个记录更新一下权重,而不是把所有记录都训练过之后再取平均。
这里我们还是使用 sigmoid 作为激活函数
f(h)=1/(1+e−h)
sigmoid 的梯度是:f′(h)=f(h)(1−f(h))
h 是输出单元的输入
h=∑iwixi
用 NumPy 来实现
这里大部分都可以用 NumPy 很方便的实现。
首先你需要初始化权重。我们希望它们比较小,这样输入在 sigmoid 函数那里可以在接近 0 的位置,而不是最高或者最低处。很重要的一点是要随机地初始化它们,这样它们有不同的值,是发散且不对称的。所以我们从一个中心为 0 的正态分布来初始化权重。一个好的标准差的值是 1/√n,这里 n 是输入的个数。这样就算是输入个数变多,进到 sigmoid 的输入还能保持比较小。
weights = np.random.normal(scale=1/n_features**.5, size=n_features)
NumPy 提供了一个可以让两个序列做点乘的函数,它可以让我们方便地计算 h。点乘是把两个序列的元素对应位置相乘之后再相加。
# input to the output layer
output_in = np.dot(weights, inputs)
最后我们更新 Δwi 和 wi,weights += ... 是 weights = weights + ... 的简写。
提示
因为这里我们用 sigmoid 函数。它有一个特性是 f′(h)=f(h)(1−f(h))。也就是说一旦你有了 f(h),你就可以用它来计算误差的梯度了。
实现隐藏层
先修要求
接下来我们会讲神经网络在多层感知器里面的数学部分。讲多层感知器我们会用到向量和矩阵。你可以通过下列讲解对此做个回顾:
- Khan Academy's introduction to vectors.
- Khan Academy's introduction to matrices.
由来
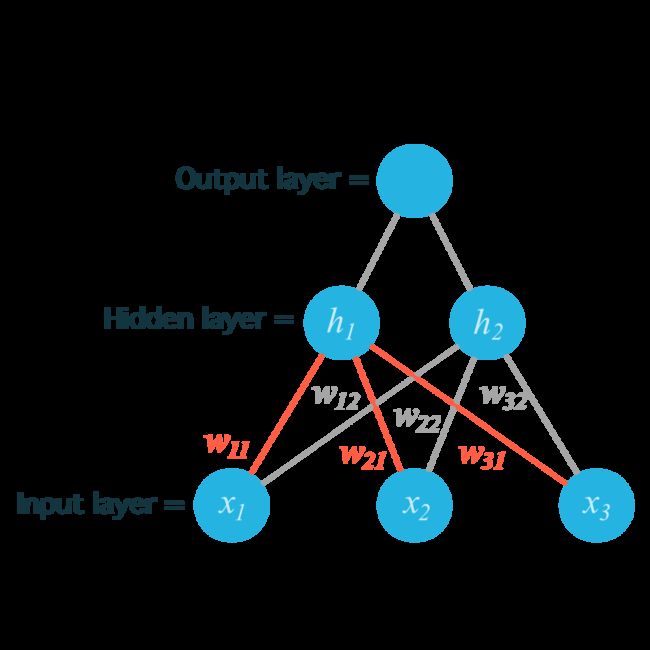
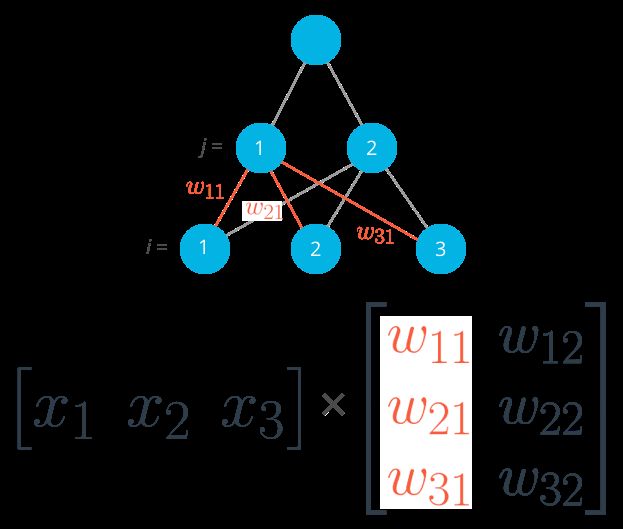
之前我们研究的是有一个输出节点网络,代码也很直观。但是现在我们有不同的输入,多个隐藏层,他们的权重需要有两个索引 wij,i 表示输入单位,j 表示隐藏单位。
例如在下面这个网络图中,输入被标注为 x1,x2, x3,隐藏层节点是 h1 和 h2。

指向 h1 的权重被标成了红色,这样更好区分。
为了定位权重,我们把输入节点的索引 i 和输出节点的索引 j 结合,得到:
w11
代表从 x1 到 h1 的权重;
w12
代表从 x1 到 h2 的权重。
下图包括了从输入层到隐藏层用 wij 来标注的所有权重:
之前我们可以把权重写成序列,标记为 wi。
现在,权重被储存在矩阵中,由 wij 来标记。每一行表示从输入层发出的权重,每一列表示从输入到隐藏层的权重。这里我们由三个输入,两个因此节点,权重矩阵标示为:
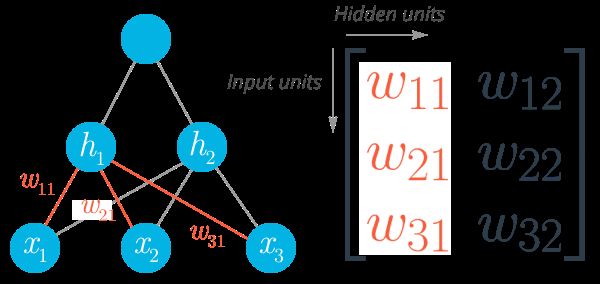
三个输入两个隐藏
记得比较一下上面的示意图来确定你了解不同的权重在矩阵中神经网络中的对应关系。
用 NumPy 来初始化权重,我们需要提供矩阵的维度,如果特征是包含输入的二维序列:
# Number of records and input units
# 数据点以及每个数据点有多少输入的个数
n_records, n_inputs = features.shape
# Number of hidden units
# 隐藏层个数
n_hidden = 2
weights_input_to_hidden = np.random.normal(0, n_inputs**-0.5, size=(n_inputs, n_hidden))
这样创建了一个 名为 weights_input_to_hidden 的 2D 序列,维度是 n_inputs 乘 n_hidden。记住,输入到隐藏层是所有输入乘以隐藏层权重的和。所以对每一个隐藏层节点 hj,我们需要计算:
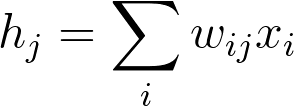
为了实现这点,我们需要运用矩阵乘法,如果你对线性代数有点忘了,我们建议你看下之前先修部分的资料。这里你只需要了解矩阵如何相乘。
在这里,我们把输入(一个行向量)与权重相乘。要实现这个,要把输入点乘(内积)以权重矩阵的每一列。例如要计算到第一个隐藏节点的输入 j=1,你需要把这个输入与权重矩阵的第一列做点乘:
用输入与权重矩阵的第一列相乘得出到隐藏层第一个节点的输入
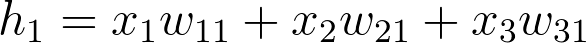
针对第二个隐藏节点的输入,你需要计算输入与第二列的点积,以此类推。
在 NumPy 中,你可以直接使用 np.dot
hidden_inputs = np.dot(inputs, weights_input_to_hidden)
你可以定义你的权重矩阵是 n_hidden 乘 n_inputs 然后把输入作为竖向量相乘:

注意:
这里权重的索引在上图中做了改变,与之前图片并不匹配。这是因为,在矩阵标注时行索引永远在列索引之前,所以用之前的方法做标识会引起误导。你只需要了解这跟之前的权重矩阵是一样的,只是做了转换,之前的第一列现在是第一行,之前的第二列现在是第二行。如果用之前的标记,权重矩阵是下面这个样子的:
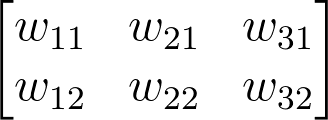
用之前的标记标注的权重矩阵
切记,上面标注方式是不正确的,这里只是为了让你更清楚这个矩阵如何跟之前神经网络的权重匹配。
矩阵相乘最重要的是他们的维度相匹配。因为它们在点乘时需要有相同数量的元素。在第一个例子中,输入向量有三列,权重矩阵有三行;第二个例子中,权重矩阵有三列,输入向量有三行。如果维度不匹配,你会得到:
# Same weights and features as above, but swapped the order
hidden_inputs = np.dot(weights_input_to_hidden, features)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
in ()
----> 1 hidden_in = np.dot(weights_input_to_hidden, X)
ValueError: shapes (3,2) and (3,) not aligned: 2 (dim 1) != 3 (dim 0)
3x2 的矩阵跟 3 个元素序列是没发相乘的。因为矩阵中的两列与序列中的元素个数并不匹配。能够相乘的矩阵如下:
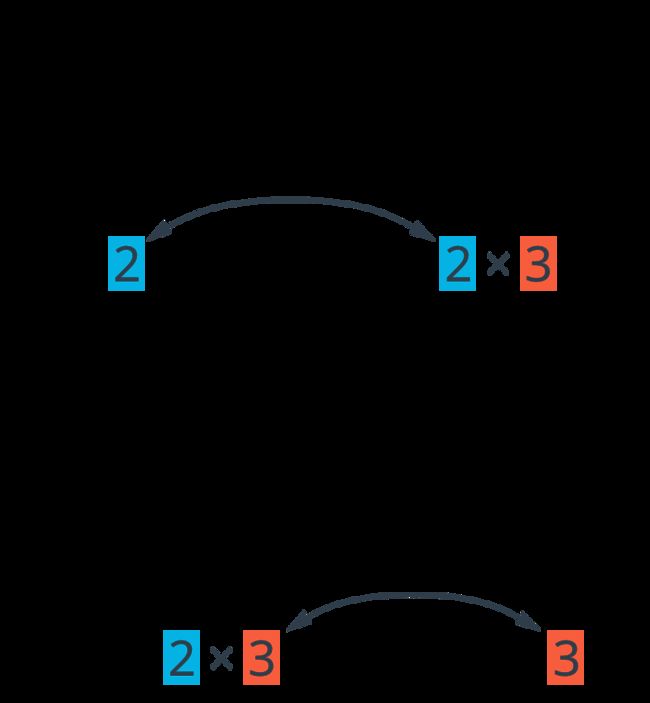
这里的规则是,如果是序列在左边,序列的元素个数必须与右边矩阵的行数一样。如果矩阵在左边,那么矩阵的列数,需要与右边向量的行数匹配。
构建一个列向量
看上面的介绍,你有时会需要一个列向量,尽管 NumPy 默认是行向量。你可以用 arr.T 来对序列进行转制,但对一维序列来说,转制还是行向量。所以你可以用 arr[:,None] 来创建一个列向量:
print(features)
> array([ 0.49671415, -0.1382643 , 0.64768854])
print(features.T)
> array([ 0.49671415, -0.1382643 , 0.64768854])
print(features[:, None])
> array([[ 0.49671415],
[-0.1382643 ],
[ 0.64768854]])
当然,你可以创建一个二维序列,然后用 arr.T 得到列向量。
np.array(features, ndmin=2)
> array([[ 0.49671415, -0.1382643 , 0.64768854]])
np.array(features, ndmin=2).T
> array([[ 0.49671415],
[-0.1382643 ],
[ 0.64768854]])
反向传播
现在我们来到了如何让多层神经网络学习的问题上。之前我们了解了如何用梯度下降来更新权重。反向传播算法是它的一个延伸,用链式法则来找到误差与输入层到输入层链接的权重(两层神经网络)。
要更新输入到隐藏层的权重,你需要知道隐藏层节点的误差对最终输出的影响是多大。输出是由两层之间的权重决定的,这个误差是输入跟权重在网络中正向传播的结果。既然我们知道输出误差,我们可以用权重来反向传播到隐藏层。
例如,输出层的话,在每一个输出节点 k 的误差是 δko 。隐藏节点 j 的误差来自输出层和隐藏层之间的权重(以及梯度)。
梯度下降跟之前一样,只是用新的误差:
wij 是输入和隐藏层之间的权重, xi 是输入值。这个形式可以表示任意层数。权重更新步长等与步长乘以层输出误差再乘以这层的输入值。
这里,你有了输出误差,δoutput,从高层反向传播这些误差。Vin 是对这一层的输入,经过隐藏层激活后到输出节点。
通过一个实际案例学习
让我们一起过一遍计算一个简单的两层网络权重的更新过程。假设有两个输入值,一个隐藏节点,一个输出节点,隐藏层和输出层的激活函数都是 sigmoid 。下图描述了这个网络。(注意:输入在这里显示为图最下方的节点,网络的输出标记为顶端的 y^,输入本身不算做层,这也是为什么这个网络结构被称作两层网络。)
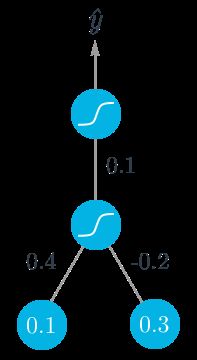
假设我们试着输入一些二分类数据,目标是 y=1。我们从正向传导开始,首先计算输入到隐藏层
h=∑iwixi=0.1×0.4−0.2×0.3=−0.02
隐藏层的输出
a=f(h)=sigmoid(−0.02)=0.495.
把它作为输出层的输入,神经网络的输出是:
y^=f(W⋅a)=sigmoid(0.1×0.495)=0.512.
有了这个输出,我们就可以开始反向传播来计算两层的权重更新了。sigmoid 函数特性 f′(W⋅a)=f(W⋅a)(1−f(W⋅a)),输出误差是:
δo=(y−y^)f′(W⋅a)=(1−0.512)×0.512×(1−0.512)=0.122.
现在我们要通过反向传播来计算隐藏层的误差。这里我们吧输出误差与隐藏层到输出层的权重 W 相乘。隐藏层的误差 δjh=∑kWjkδkof′(hj),这里因为只有一个隐藏节点,这就比较简单了
δh=Wδof′(h)=0.1×0.122×0.495×(1−0.495)=0.003
有了误差,就可以计算梯度下降步长了。隐藏层到输出层权重步长是学习率乘以输出误差再乘以隐藏层激活值。
ΔW=ηδoa=0.5×0.122×0.495=0.0302
从输入到隐藏层的权重 wi,是学习率乘以隐藏节点误差再乘以输入值。
Δwi=ηδhxi=(0.5×0.003×0.1,0.5×0.003×0.3)=(0.00015,0.00045)
这个例子你可以看出用 sigmoid 做激活函数的效果。sigmoid 函数最大的导数是 0.25,输出层的误差被至少减少了75%,隐藏层的误差被减少了至少93.75%!你可以看出,如果你有很多层,用 sigmoid 激活函数函数会很快把权重降到靠近输入的细小值。这被称作梯度消失问题。后面的课程中你会学到其它的激活函数在这方面表现比它好,也被用于最新的网络架构中。
用 NumPy 来实现
现在你已经有了大部分用 NumPy 来实现反向传导的知识。
但是之前接触的是一个元素的误差项。现在在权重更新时,我们需要考虑隐藏层每个节点的误差:
Δwij=ηδjxi
首先,这里会有不同数量的输入和隐藏节点,所以试图把误差与输入当作行向量来乘会报错
hidden_error*inputs
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
in ()
----> 1 hidden_error*x
ValueError: operands could not be broadcast together with shapes (3,) (6,)
同时,wij 现在是一个矩阵,所以右侧对应也应该有跟左侧同样的维度。幸运的是,NumPy 这些都能搞定。如果你用一个列向量序列和一个行向量序列乘,它会把列向量的第一个元素与行向量的每个元素相乘,然后第一行是一个二维序列。列向量的每一个元素会这门做,所以你会得到一个二维序列,维度是(len(column_vector), len(row_vector))。
hidden_error*inputs[:,None]
array([[ -8.24195994e-04, -2.71771975e-04, 1.29713395e-03],
[ -2.87777394e-04, -9.48922722e-05, 4.52909055e-04],
[ 6.44605731e-04, 2.12553536e-04, -1.01449168e-03],
[ 0.00000000e+00, 0.00000000e+00, -0.00000000e+00],
[ 0.00000000e+00, 0.00000000e+00, -0.00000000e+00],
[ 0.00000000e+00, 0.00000000e+00, -0.00000000e+00]])
这正好是我们如何计算权重更新的步长。跟以前一样,如果你的输入是一个一行的二维序列,你可以用hidden_error*inputs.T,如果 inputs 是一维序列,就不行了。
实现反向传播
现在我们知道输出层的误差是
δk=(yk−y^k)f′(ak)
输入层误差是
现在我们只考虑一个简单神经网络,他只有一层隐藏层和一个输出节点。这是通过反向传播更新权重的算法概述:
- 把每一层权重更新的初始步长设置为 0
- 输入到隐藏层的权重是 Δwij=0
- 隐藏层到输出层的权重是 ΔWj=0
- 对训练数据当中的每一个点
- 让它正向通过网络,计算输出 y^
- 计算输出节点的误差梯度 δo=(y−y^)f′(z) 这里 z=∑jWjaj 输入到输出节点。
- 误差传播到隐藏层 δjh=δoWjf′(hj)
- 更新权重步长:
- ΔWj=ΔWj+δoaj
- Δwij=Δwij+δjhai
- 更新权重, η 是学习率,m 是数据点的数量:
- Wj=Wj+ηΔWj/m
- wij=wij+ηΔwij/m
- 重复这个过程 e 代。
import numpy as np
from data_prep import features, targets, features_test, targets_test
np.random.seed(21)
def sigmoid(x):
"""
Calculate sigmoid
"""
return 1 / (1 + np.exp(-x))
# Hyperparameters
n_hidden = 2 # number of hidden units
epochs = 900
learnrate = 0.005
n_records, n_features = features.shape
last_loss = None
# Initialize weights
weights_input_hidden = np.random.normal(scale=1 / n_features ** .5,
size=(n_features, n_hidden))
weights_hidden_output = np.random.normal(scale=1 / n_features ** .5,
size=n_hidden)
for e in range(epochs):
del_w_input_hidden = np.zeros(weights_input_hidden.shape)
del_w_hidden_output = np.zeros(weights_hidden_output.shape)
for x, y in zip(features.values, targets):
## Forward pass ##
# TODO: Calculate the output
hidden_input = np.dot(x, weights_input_hidden)
hidden_output = sigmoid(hidden_input)
output = sigmoid(np.dot(hidden_output,
weights_hidden_output))
## Backward pass ##
# TODO: Calculate the network's prediction error
error = y - output
# TODO: Calculate error term for the output unit
output_error_term = error * output * (1 - output)
## propagate errors to hidden layer
# TODO: Calculate the hidden layer's contribution to the error
hidden_error = np.dot(output_error_term, weights_hidden_output)
# TODO: Calculate the error term for the hidden layer
hidden_error_term = hidden_error * hidden_output * (1 - hidden_output)
# TODO: Update the change in weights
del_w_hidden_output += output_error_term * hidden_output
del_w_input_hidden += hidden_error_term * x[:, None]
# TODO: Update weights
weights_input_hidden += learnrate * del_w_input_hidden / n_records
weights_hidden_output += learnrate * del_w_hidden_output / n_records
# Printing out the mean square error on the training set
if e % (epochs / 10) == 0:
hidden_output = sigmoid(np.dot(x, weights_input_hidden))
out = sigmoid(np.dot(hidden_output,
weights_hidden_output))
loss = np.mean((out - targets) ** 2)
if last_loss and last_loss < loss:
print("Train loss: ", loss, " WARNING - Loss Increasing")
else:
print("Train loss: ", loss)
last_loss = loss
# Calculate accuracy on test data
hidden = sigmoid(np.dot(features_test, weights_input_hidden))
out = sigmoid(np.dot(hidden, weights_hidden_output))
predictions = out > 0.5
accuracy = np.mean(predictions == targets_test)
print("Prediction accuracy: {:.3f}".format(accuracy))