python数据分析的钥匙——pandas库
目录
一. 关于pandas库:
二. pandas库的安装
三. pandas的两种基本数据结构——Series 与 DataFrame
3.1 Series主要用于存储一个序列这样一种数据:
3.2 DataFrame作为更复杂的数据结构,则用于存储多维数据:
3.3 Series 和 DataFrame 知识总结
四. pandas库的应用
4.1 pandas数据读写:
4.2 pandas数据处理
4.2.1 数据准备
4.2.2 数据转换
4.2.3 数据聚合
5. 总结
一. 关于pandas库:
pandas库是一个专门用来解决数据分析的库,主要有以下两大优势:
1)速度快:快速处理大型数据集;
2)效率高:提供大量高效处理数据的函数和方法;
二. pandas库的安装
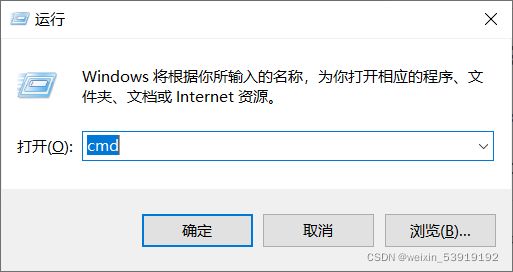
1.打开命令行
按住快捷键:Win+R,即可打开“运行”窗口,在“运行”窗口中输入:cmd,回车,即可打开命令行。
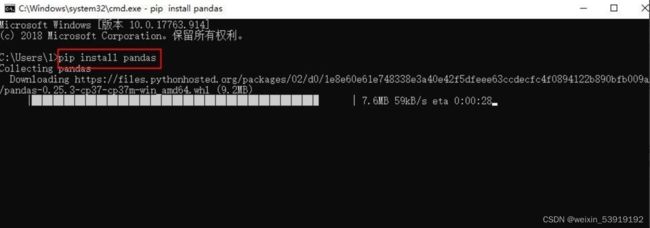
2.执行安装命令
在命令行中输入命令:python install pandas,回车。等待,即可安装完成Pandas库。
三. pandas的两种基本数据结构——Series 与 DataFrame
3.1 Series主要用于存储一个序列这样一种数据:
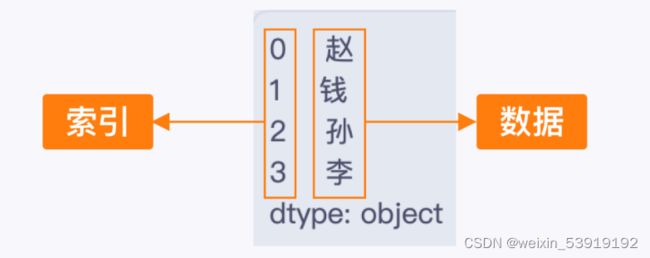
Series 主要由一组数据及其对应的索引组成:
# 插入pandas库,以pd代称
import pandas as pd
#声明一个Series对象
datas = pd.Series([1,0,2,1,2,3], index = ['white','white','blue','green','green','yellow'])
#找出Series对象中所有不同元素
unique_datas = datas.unique()
#找出Series对象中所有不同元素并标记出现的次数
counts_datas = datas.value_counts()
#判断所属关系,返回布尔值
isin_datas = datas.isin([0,3])
#判断所属关系,返回真实值
isin_datas1 = datas[datas.isin([0,3])]
#Series对象可直接转化字典对象
mydict = {'red':2000, 'blue':1000, 'yellow':500, 'orange':1000}
myseries = pd.Series(mydict)
#Series对象之间的运算(只对共有的对象运算,其他的对象的值均为NAN)
mydict1 = {'red':400, 'black':1000, 'yellow':1000, 'green':1000}
myseries1 = pd.Series(mydict1)
add_series = myseries + myseries1 datas
datas
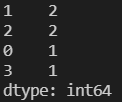 counts_datas
counts_datas 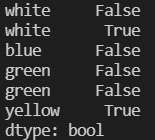 isin_datas
isin_datas  isin_datas1
isin_datas1 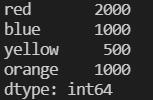 myseries
myseries 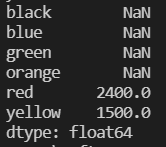 add_series
add_series
3.2 DataFrame作为更复杂的数据结构,则用于存储多维数据:
DataFrame对象是⼀种表格型的数据结构,包含⾏索引、列索引以及⼀组数据 :

# 插入pandas库,以pd代称
import pandas as pd
data = {'color': ['blue', 'green', 'yellow', 'red', 'white'],
'object': ['ball', 'prn', 'pencil', 'paper', 'mug'],
'price': [1.2, 1.0, 0.6, 0.9, 1.7]}
#声明一个DataFrame对象
frame = pd.DataFrame(data)
#选取指定列
frame2 = pd.DataFrame(data, columns=['object','price'])
#给与标签作为DataFrame的索引
index_frame = pd.DataFrame(data, index=['one', 'two', 'three', 'four', 'five'])
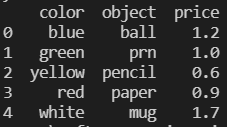 frame
frame 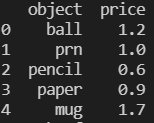 frame2
frame2  index_frame
index_frame  frame_T
frame_T
3.3 Series 和 DataFrame 知识总结

四. pandas库的应用
4.1 pandas数据读写:
数据读写对数据分析非常重要,所以pandas库也有一组被称为I/O API的函数:
这些函数被分为完全对称的两大类:读写函数和写入函数(以下以txt文件举例)
# 插入pandas库,以pd代称
import pandas as pd
# 读取txt文件
datas = pd.read_csv('text.txt', sep ='\D+', header = None, encoding = ' utf-8')
'''
'text.txt'是文件相对路径
sep 是分隔符
header 指表头(header = None表示无表头,读取文件时自动生成表头)
'''
# 生成txt文件
datas.to_csv("result.xlsx")
# 生成excel文件
datas.to_excel("result.xlsx")4.2 pandas数据处理
数据处理可以分为3个阶段:数据准备,数据转换,数据聚合
4.2.1 数据准备
4.2.2 数据转换
4.2.3 数据聚合
5. 总结
以上就是今天要讲的内容,本文简单介绍了pandas库的知识及应用,而数据分析以可以以pandas库为基础进行更多方便有效的分析研究,本文还未完结,希望大家多多支持。
欢迎大家留言一起讨论问题~~~