Java实现常见的排序算法
排序的基本概念与分类
排序是我们生活中经常会面对的问题。同学们做操时会按照从矮到高排列;老师查看上课出勤情况时,会按学生学号顺序点名;高考录取时,会按成绩总分降序依次录取等。那排序的严格定义是什么呢?
假设含有 n 个记录的序列为{r1,r2,......,rn}, 其相应的关键字分别为{k1,k2,......,kn} ,需确定 1, 2……, n 的一种排列 p1,p2,.......,使其相应的关键字满足 kp1<=kp2<=…… <=kpn (非递减或非递增) 关系,即使得序列成为一个按关键字有序的序列{rp1,rp2,.......,rpn}, 这样的操作就称为排序 。
1.1排序的稳定性
也正是由于排序不仅是针对主关键字,那么对于次关键字,因为待排序的记录序列中可能存在两个或两个以上的关键字相等的记录,排序结果可能会存在不唯一的情况,我们给出了稳定与不稳定排序的定义。
假设 ki=kj ( 1<=i<=n,1<=j<=n,i≠j) ,且在排序前的序列中 ri领先于 rj (即 i
简单选择排序法 (Simple Selection Sort) 就是通过 n - i 次关键字间的比较,从n-i + 1 个记录中选出关键字最小的记录,并和第 i ( 1 <= i <=n) 个记录交换之。
我们来看代码。
顾名思义,从名称上也可以知道它是一种插入排序的方法。我们来看直接插入排序法的代码。
当最好的情况,也就是要排序的表本身就是有序的,比如拿到后就是{ 2,3,4,5}时, 那么我们比较次数,其实就是代码中a[i]和a[i-1]比较,共比较了n-1)次,由于每次都是都是a[i-1]
可惜的是,这样的操作并没有把每一趟的比较结果保存下来 ,在后一趟的比较中,有许多比较在前一趟已经做过了,但由于前一趟排序时未保存这些比较结果,所以后一趟排序时又重复执行了这些比较操作,因而记录的比较次数较多。
如果可以做到每次在选择到最小记录的同时,并根据比较结果对其他记录做出相应的调整 ,那样排序的总体效率就会非常高了。 而堆排序(Heap Sort) ,就是对简单选择排序进行的一种改进,这种改进的效果是非常明显的。堆排序算法是 Floyd 和Williams在1964年共同发明的,同时,他们发明了"堆"这样的数据结构。
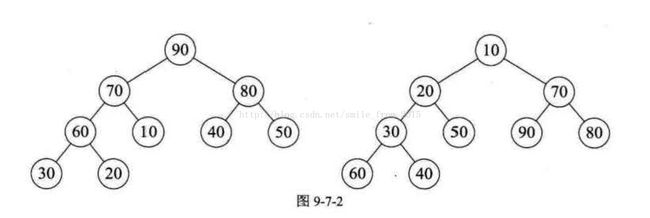
叠罗汉运动是把人堆在一起,而我们这里要介绍的“堆”结构相当于把数字符号堆成一个塔型的结构。当然,这绝不是简单的堆砌。大家看图9-7-2所示,能够找到什么规律吗?


假设 ki=kj ( 1<=i<=n,1<=j<=n,i≠j) ,且在排序前的序列中 ri领先于 rj (即 i
1.2内排序和外排序
根据在排序过程中待排序的记录是否全部被放置在内存中,排序分为:内排序和外排序。
内排序是在排序整个过程中,待排序的所有记录全部被放置在内存中。外排序是由于排序的记录个数太多,不能同时放置在内存,整个排序过程需要在内外存之间多次交换数据才能进行。我们这里主要就介绍内排序的多种方法。
内排序是在排序整个过程中,待排序的所有记录全部被放置在内存中。外排序是由于排序的记录个数太多,不能同时放置在内存,整个排序过程需要在内外存之间多次交换数据才能进行。我们这里主要就介绍内排序的多种方法。
对于内排序来说,排序算法的性能主要是受 3 个方面影响:
1.时间性能
排序是数据处理中经常执行的一种操作,往往属于系统的核心部分,因此排序算法的时间开销是衡量其好坏的最重要的标志。在内排序中,主要进行两种操作: 比较和移动。比较指关键字之间的比较,这是要做排序最起码的操作。移动指记录从一个位置移动到另一个位置,事实上,移动可以通过改变记录的存储方式来予以避免(这个我们在讲解具体的算法时再谈)。总之,高效率的内排序算法应该是具有尽可能少的关键字比较次数和尽可能少的记录移动次数。2. 辅助空间
评价排序算法的另一个主要标准是执行算法所需要的辅助存储空间。辅助存储空间是除了存放待排序所占用的存储空间之外,执行算法所需要的其他存储空间 。3. 算法的复杂性
注意这里指的是算法本身的复杂度,而不是指算法的时间复杂度。显然算法过于复杂也会影响排序的性能。
根据排序过程中借助的主要操作,我们把 内排序分为:插入排序、交换排序、选择排序和归并排序。可以说,这些都是比较成熟的排序技术,已经被广泛地应用 于许许多多的程序语言或数据库当中,甚至它们都已经封装了关于排序算法的实现代码。
因此,我们 学习这些排序算法的目的更多并不是为了去在现实中编程排序算法,而是通过学习来提高我们编写算法的能力,以便于去解决更多复杂和灵活的应用性问题。
本章一共要讲解七种排序的算法,按照算法的复杂度分为两大类,冒泡排序 、简单选择排序和直接插入排序属于简单算法,而希尔排序、堆排序、归并排序、快速排序属于改进算法。 后面我们将依次讲解 。
因此,我们 学习这些排序算法的目的更多并不是为了去在现实中编程排序算法,而是通过学习来提高我们编写算法的能力,以便于去解决更多复杂和灵活的应用性问题。
本章一共要讲解七种排序的算法,按照算法的复杂度分为两大类,冒泡排序 、简单选择排序和直接插入排序属于简单算法,而希尔排序、堆排序、归并排序、快速排序属于改进算法。 后面我们将依次讲解 。
1.3冒泡排序
冒泡排序 (Bubble Sort) 一种交换排序,它的基本思想是:两两比较相邻记录的关键字,如果反序则交换,直到没有反序的记录为止。冒泡的实现在细节上可以有很多种变化,我们将分别就 3 种不同的冒泡实现代码,来讲解冒泡排序的思想。 这里,我们就先来看看比较容易理解的一段。public class BubbleSort {
public static void main(String[] args) {
int[] array = { 3, 9, 1, 4, 8, 6, 7, 5, 2, 0 };
System.out.println(Arrays.toString(bubbleSort0(array)));
}
/** 冒泡排序初级版 */
static int[] bubbleSort0(int[] a) {
for (int i = 0; i < a.length; i++) {
for (int j = 0; j < a.length - 1; j++) {
if (a[j] > a[j + 1]) {
swap(a, j, j + 1);
}
}
}
return a;
}
/** 交换a数组中的下标为 i 和 j 的值 */
static void swap(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
我们来看看正宗的冒泡算法,有没有什么改进的地方。
/** 对数组a进行排序 */
static int[] bubbleSort1(int[] a) {
for (int i = 0; i < a.length - 1; i++) {
for (int j = a.length - 2; j >= i; j--) {// j从后往前循环
if (a[j] > a[j + 1]) {// 若前一个元素大于后一个元素,则交换
swap(a, j, j + 1);// 交换a[j]和a[j+2]的值
}
}
}
return a;
}/** 改进后对数组a进行排序 */
static int[] bubbleSort2(int[] a) {
boolean flag = true; //设置一个标记
for (int i = 0; i < a.length - 1 && flag; i++) {//当flag为false时,有序,退出循环
flag = false;
for (int j = a.length - 2; j >= i; j--) {// j从后往前循环
if (a[j] > a[j + 1]) {// 若前一个元素大于后一个元素,则交换
swap(a, j, j + 1);// 交换a[j]和a[j+2]的值
flag = true;//如果有数据交换,则设置为true,继续循环
}
}
}
return a;
}冒泡排序复杂度分析
分析一下它的时间复杂度。当最好的情况,也就是要排序的表本身就是有序的,那么我们比较次数,根据最后改进的代码,可以推断出就是n-1次的比较,没有数据交换,时间复杂度为O(n)。当最坏的情况,即待排序表是逆序的情况, 此时需要比较1+2+3+…+ (n-1) =n(n-1)/2次,并作等数量级的记录移动。因此,总的时间复杂度为 O(n²)。1.4选择排序
选择排序的基本思想是每一趟在n-i+1(i=1,2,…...,n-1)个记录中选取关键字最小的记录作为有序序列的第i个记录。我们这里先介绍的是简单选择排序法。简单选择排序法 (Simple Selection Sort) 就是通过 n - i 次关键字间的比较,从n-i + 1 个记录中选出关键字最小的记录,并和第 i ( 1 <= i <=n) 个记录交换之。
我们来看代码。
/** 简单选择排序 */
static int[] bubbleSort0(int[] a) {
int min;
for (int i = 0; i < a.length - 1; i++) {
min = i;//将当前下标定义为最小值
for (int j = i + 1; j < a.length; j++) {
if (a[min] > a[j]) {//如果有小于当前的关键字,将下标赋值给min
min = j;
}
}
if(min != i){//若min不等于i,则找到最小值,并交换
swap(a,min,i);
}
}
return a;
}简单选择排序复杂度分析
从简单选择排序的过程来看,它最大的特点就是交换移动数据次数相当少 , 这样也就节约了相应的时间。分析它的时间复杂度发现,无论最好最差的情况,其比较次数都是一样的多,第 i 趟排序需要进行 n-i 次关键字的比较,此时需要比较n - 1+ n - 2+......... 1=n(n-1)/2次。 而对于交换次教而言,当最好的时候,交换为0次,最差的时候,也就初始降序时,交换次数为 n - 1 次,基于最终的排序时间是比较与交换的次数总和, 因此,总的时间复杂度依然为 O(n²) 。
应该说,尽管与冒泡排序同为 O(n²), 但简单选择排序的性能上还是要略优于冒泡排序。
应该说,尽管与冒泡排序同为 O(n²), 但简单选择排序的性能上还是要略优于冒泡排序。
1.5直接插入排序
直接插入排序(Straight Insertion Sort) 的基本操作是将一个记录插入到已经排好序的有序表中,从而得到一个新的、记录数增1的有序表。顾名思义,从名称上也可以知道它是一种插入排序的方法。我们来看直接插入排序法的代码。
/** 插入排序 */
static int[] insertSort(int[] a) {
int j;// 单独定义,用于记录第二层for循环退出时候的j值
for (int i = 1; i < a.length; i++) {
if (a[i] < a[i - 1]) {// 如果后一个值比前一个小,则交换
int temp = a[i];// 临时变量,存放循环的条件
for (j = i - 1; j >= 0 && a[j] > temp; j--) {
a[j + 1] = a[j];// 将比temp大的值,依次后移
}
a[j + 1] = temp;//将跳出循环的后一个记录赋值为temp
}
}
return a;
}直接插入排序复杂度分析
我们来分析一下这个算法,从空间上来看,它只需要一个记录的辅助空间,因此关键是看它的时间复杂度。当最好的情况,也就是要排序的表本身就是有序的,比如拿到后就是{ 2,3,4,5}时, 那么我们比较次数,其实就是代码中a[i]和a[i-1]比较,共比较了n-1)次,由于每次都是都是a[i-1]
当最坏的情况,即待排序表是逆序的情况,比如 {6,5,4,3,2},此时需要比较步2+3+......+n =(n+2)(n-1) /2次,而记录的移动次数也达到最大值(n+4)(n-1)/2次。
如果排序记录是随机的,那么根据概率相同的原则,平均比较和移动次数约为 n²/4次。因此,我们得出直接插入排序法的时间复杂度为 O(n²) 。 从这里也看出,同样的O(n²)时间复杂度,直接插入排序法比冒泡和简单选择排序的性能要好一些。
不过别急,有条件当然是好,条件不存在,我们创造条件也是可以去做的。于是科学家希尔研究出了一种排序方法,对直接插入排序改进后可以增加效率。
如何让待排序的记录个数较少呢?很容易想到的就是将原本有大量记录数的记录进行分组。分割成若干个子序列,此时每个子序列待排序的记录个数就比较少了,然后在这些子序列内分别进行直接插入排序,当整个序列都基本有序时,注意只是基本有序时,再对全体记录进行一次直接插入排序。
所谓的基本有序,就是小的关键字基本在前面,大的基本在后面,不大不小的基本在中间,像{2,1,3,6,7,8,9}这样可以称为基本有序了。但像{1,5,9,3,8,2,6}这样的 9 在第三位, 2 在倒数第三位就谈不上基本有序。
因此,我们需要采取跳跃分割的策略 :将相距某个‘增量'的记录组成一个子序列,这样才能保证在子序列内分别进行直接插入排序后得到的结果是基本有序而不是局部有序。
希尔排序算法代码如下。
如果排序记录是随机的,那么根据概率相同的原则,平均比较和移动次数约为 n²/4次。因此,我们得出直接插入排序法的时间复杂度为 O(n²) 。 从这里也看出,同样的O(n²)时间复杂度,直接插入排序法比冒泡和简单选择排序的性能要好一些。
1.6希尔排序
我们前一节讲的直接插入排序,应该说,它的效率在某些时候是很高的,比如,我们的记录本身就是基本有序的,我仍只需要少量的插入操作,就可以完成整个记录集的排序工作,此时直接插入很高效。还有就是记录数比较少时,直接插入的优势也比较明显。可问题在于,两个条件本身就过于苛刻,现实中记录少或者基本有序都属于特殊情况。不过别急,有条件当然是好,条件不存在,我们创造条件也是可以去做的。于是科学家希尔研究出了一种排序方法,对直接插入排序改进后可以增加效率。
如何让待排序的记录个数较少呢?很容易想到的就是将原本有大量记录数的记录进行分组。分割成若干个子序列,此时每个子序列待排序的记录个数就比较少了,然后在这些子序列内分别进行直接插入排序,当整个序列都基本有序时,注意只是基本有序时,再对全体记录进行一次直接插入排序。
所谓的基本有序,就是小的关键字基本在前面,大的基本在后面,不大不小的基本在中间,像{2,1,3,6,7,8,9}这样可以称为基本有序了。但像{1,5,9,3,8,2,6}这样的 9 在第三位, 2 在倒数第三位就谈不上基本有序。
因此,我们需要采取跳跃分割的策略 :将相距某个‘增量'的记录组成一个子序列,这样才能保证在子序列内分别进行直接插入排序后得到的结果是基本有序而不是局部有序。
希尔排序算法代码如下。
/** 希尔排序 */
static int[] shelltSort(int[] a) {
int j;
int increment = a.length;
do {
increment = increment / 3;//增量序列
for (int i = increment + 1; i < a.length; i++) {
if (a[i] < a[i - increment]) {
int temp = a[i];
for (j = i - increment; j >= 0 && a[j] > temp; j = j - increment) {
a[j + increment] = a[j];// 记录后移 .查找插入位置
}
a[j + increment] = temp;
}
}
} while (increment > 1);
return a;
}希尔排序复杂度分析
这里"增量"的选取就非常关键了 。我们在代码中对increment/3 的方式选取增量的,可究竞应该选取什么样的增最才是最好,目前还是一个数学难题,迄今为止还没有人找到一种最好的增量序列。dlta[k]=2^( t-k+1)-1 ( 0<=k<=t<=log2(n+1) )时,可以获得不错的效率, 其时间复杂度为 O(n^3/2),要好于直接排序的 O(n²)。需要注意的是, 增量序列的最后一个增量值必须等于 1 才行。 另外由于记录是跳跃式的移动,希尔排序并不是一种稳定的排序算法。
1.7堆排序
我们前面讲到简单选择排序,它在待排序的 n 个记录中选择一个最小的记录需要比较 n - 1 次。本来这也可以理解,查找第一个数据需要比较这么多次是正常的,否则如何知道它是最小的记录。可惜的是,这样的操作并没有把每一趟的比较结果保存下来 ,在后一趟的比较中,有许多比较在前一趟已经做过了,但由于前一趟排序时未保存这些比较结果,所以后一趟排序时又重复执行了这些比较操作,因而记录的比较次数较多。
如果可以做到每次在选择到最小记录的同时,并根据比较结果对其他记录做出相应的调整 ,那样排序的总体效率就会非常高了。 而堆排序(Heap Sort) ,就是对简单选择排序进行的一种改进,这种改进的效果是非常明显的。堆排序算法是 Floyd 和Williams在1964年共同发明的,同时,他们发明了"堆"这样的数据结构。
叠罗汉运动是把人堆在一起,而我们这里要介绍的“堆”结构相当于把数字符号堆成一个塔型的结构。当然,这绝不是简单的堆砌。大家看图9-7-2所示,能够找到什么规律吗?
很明显,我们可以发现它们都是二叉树,如果观察仔细些,还能看出它们都是完全二叉树。左图中根结点是所有元素中最大的,右图的根结点是所有元素中最小的。再细看看,发现左图每个结点都比它的左右孩子要大,右图每个结点都比它的左右孩子要小。这就是我们要讲的堆结构。
堆是具有下列性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆 (例如图 9-7-2 左图所示) ; 或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆(例如图 9-7-2 右图所示)。
这里需要注意从堆的定义可知,根结点一定是堆中所有结点最大(小)者。较大(小)的结点靠近根结点(但也不绝对,比如右图小顶堆中 60 、 40 均小于70 ,但它们并没有 比70更靠近根结点)。
如果按照层序遍历的方式给结点从 1 开始编号,则结点之间满足如下关系 :

这里需要注意从堆的定义可知,根结点一定是堆中所有结点最大(小)者。较大(小)的结点靠近根结点(但也不绝对,比如右图小顶堆中 60 、 40 均小于70 ,但它们并没有 比70更靠近根结点)。
如果按照层序遍历的方式给结点从 1 开始编号,则结点之间满足如下关系 :
这里为什么 i 要小子等于n/2呢?相信大家可能都忘记了二叉树的性质5,其实忘记也不奇怪,这个性质在我们讲完之后,就再也没有提到过它。可以说,这个性质仿佛就是在为堆准备的。性质 5 的第一条就说一棵完全二叉树,如果 i=1,则结点 i是二叉树的根,无双亲 ;如果i>1, 则其双亲是结点 i/2。那么对于有 n 个结点的二叉树而言,它的 i 值自然就是小于等于 n/2了。性质 5 的第二、三条,也是在说明下标 i 与 2i 和 2i+1的双亲子女关系。如果完全忘记的同学不妨去复习一下 。
如果将图 9-7-2 的大顶堆和小顶堆用层序遍历存人数组,则一定满足上面的关系表达 ,如图 9-7-3 所示。
我们现在讲这个堆结构,其目的就是为了堆排序用的。
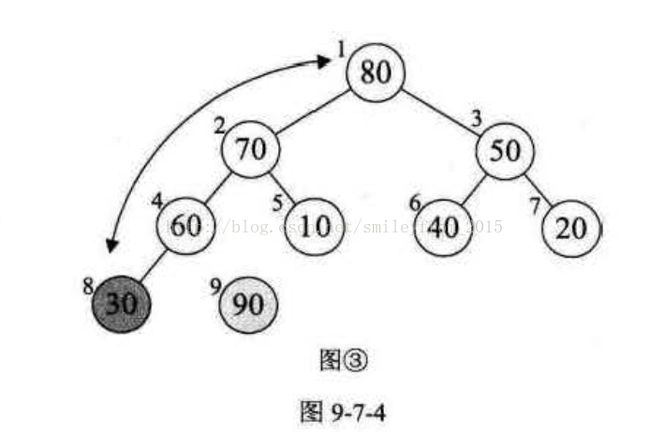
堆排序 (Heap Sort) 就是利用堆(假设利用大顶堆)进行排序的方法。它的基本思想是, 将待排序的序列构造成一个大顶堆。此时,整个序列的最大值就是堆顶的根结点。将它移走(其实就是将其与堆数组的末尾元素交换,此时末尾元素就是最大值) 。然后将剩余的 n - 1 个序列重新构造成一个堆,这样就会寻到 n 个元素中的次小值。如此反复执行, 便能得到一个有序序列了。
例如图 9-7-4 所示,图①是一个大顶堆 , 90 为最大值,将 90 与 20 (末尾元素)互换,如图②所示,此时 90 就成了整个堆序列的最后一个元素,将 20 经过调整,使得除 90 以外的结点继续满足大顶堆定义(所有结点都大于等于其子孩子) ,见图③,然后再考虑将 30 与 80 互换……
相信大家有些明白堆排序的基本思想了,不过要实现它还需要解决两个问题:
1. 如何由一个无序序列构建成一个堆?
2 . 如果在输出堆顶元素后,调整剩余元素成为一个新的堆?
要解释清楚它们,让我们来看代码。
假设我们要排序的序列是{50,10,90,30,70,40,80,60,20},那么 a.length=9,第一个 for 循环,i 是从 =4 开始, 4→ 3→ 2→1 的变量变化。为什么不 是从1 到 9 或者从 9 到 1,而是从 4 到 1 呢?其实我们看了图 9-7-5 就明白了,它们都有什么规律?它们都是有孩子的结点。注意灰色结点的下标编号就是 1、 2、 3 、 4。
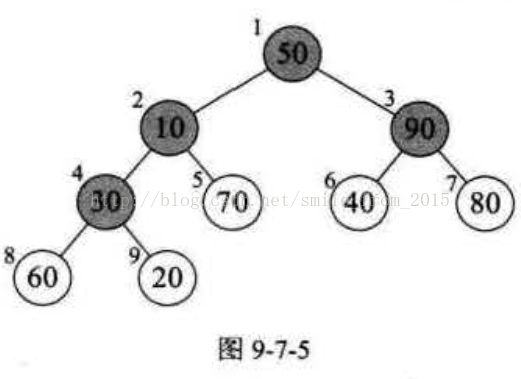 我们所谓的将待排序的序列构建成为一个大顶堆,其实就是从下往上、从右到左,将每个非终端结点(非叶结点)当作根结点,将其和其子树调整成大顶堆。i 的 4→3→2→1 的变量变化,其实也就是 30,90 , 10,50的结点调整过程。
我们所谓的将待排序的序列构建成为一个大顶堆,其实就是从下往上、从右到左,将每个非终端结点(非叶结点)当作根结点,将其和其子树调整成大顶堆。i 的 4→3→2→1 的变量变化,其实也就是 30,90 , 10,50的结点调整过程。
1. 如何由一个无序序列构建成一个堆?
2 . 如果在输出堆顶元素后,调整剩余元素成为一个新的堆?
要解释清楚它们,让我们来看代码。
/** 堆排序 */
static int[] heapSort(int[] a) {
int[] temp = null;// 定义一个临时数组用于接收调整过的大顶堆
for (int i = a.length / 2; i >= 0; i--) {
temp = heapAdjust(a, i, a.length);// 调整大顶堆
}
for (int i = a.length; i >= 0; i--) {
swap(temp, 0, i - 1);// 将调整好的大顶堆的首尾互换
temp = heapAdjust(a, 0, i - 1);// 调整交换完成后的剩余元素为大顶堆
}
return a;
}
/** 将数组a调整为一个大顶堆 */
static int[] heapAdjust(int[] a, int i, int len) {
int j, temp;
temp = a[i];// 临时变量用于
for (j = 2 * i; j < len && len != 1; j = 2 * j) {// len!=1为了避免陷入死循环,即剩余一个元素不用调整大顶堆
if (j < len - 1 && a[j] < a[j + 1]) {// 如果左孩子小于有孩子,则j++,a[j]指向右孩子
j++;
}
if (temp >= a[j])// 如果结点a[i]值均大于左右孩子结点,则不交换,跳出循环
break;
a[i] = a[j];// 否则 交换 两者位置
i = j;
}
a[i] = temp;
return a;
}
/** 交换a数组中的下标为 i 和 j 的值 */
static void swap(int[] a, int i, int j) {
if (j >= 0 && i >= 0) {// 当 i,j大于等于0时执行交换
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}假设我们要排序的序列是{50,10,90,30,70,40,80,60,20},那么 a.length=9,第一个 for 循环,i 是从 =4 开始, 4→ 3→ 2→1 的变量变化。为什么不 是从1 到 9 或者从 9 到 1,而是从 4 到 1 呢?其实我们看了图 9-7-5 就明白了,它们都有什么规律?它们都是有孩子的结点。注意灰色结点的下标编号就是 1、 2、 3 、 4。
heapAdjust中的循环j值为何要从j = 2*i开始呢?又为什么是 j=2*j 递增呢?原因还是二叉树的性质5,因为我们这棵是完全二叉树,当前结点序号是 i,其左孩子的序号一定是 2i,右孩子的序号一定是2i+1 ,它们的孩子当然也是以 2 的位数序号增加,因此 j 变量才是这样循环。接着j
归并排序是一种比较占用内存,但却效率高且稳定的算法。
 在最优情况下,枢轴关键字每次都划分得很均匀,如果排序 n 个关键字,其递归树的深度就为[log2n]+1 ([X] 表示不大子 X 的最大整数) ,即仅需递归log2n次,需要时间为 T (n) 的话,第一次查找枢轴关键字应该是需要对整个数组扫描一遍,做 n 次比较。
在最优情况下,枢轴关键字每次都划分得很均匀,如果排序 n 个关键字,其递归树的深度就为[log2n]+1 ([X] 表示不大子 X 的最大整数) ,即仅需递归log2n次,需要时间为 T (n) 的话,第一次查找枢轴关键字应该是需要对整个数组扫描一遍,做 n 次比较。
然后,获得的枢轴将数组一分为二,那么各自还需要T(n/2) 的时间(注意是最好情况,所以平分两半) 。于是不断地划分下去,我们就有了下面的不等式 推断,  也就是说,在最优的情况下,快速排序算法的时间复杂度为 O(log2n) 。
也就是说,在最优的情况下,快速排序算法的时间复杂度为 O(log2n) 。
 事实上,目前还没有十全十美的排序算法,有优点就会有缺点,即使是快速排序法,也只是在整体性能上优越,它也存在排序不稳定、需要大量辅助空间、对少量数据排序无优势等不足。因此我们就来从多个角度来剖析一下提到的各种排序的长与短。
事实上,目前还没有十全十美的排序算法,有优点就会有缺点,即使是快速排序法,也只是在整体性能上优越,它也存在排序不稳定、需要大量辅助空间、对少量数据排序无优势等不足。因此我们就来从多个角度来剖析一下提到的各种排序的长与短。
我们将 7种算法的各种指标进行对比,如表 9- 10-1所示。 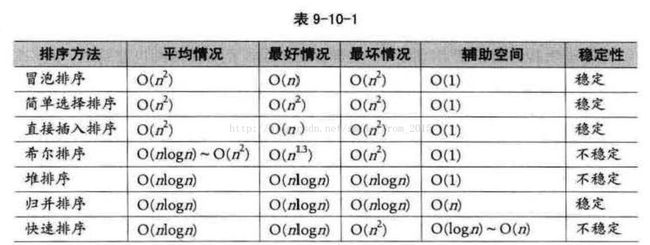 从算法的简单性来看,我们将 7 种算法分为两类:
从算法的简单性来看,我们将 7 种算法分为两类:
• 简单算法:冒泡、简单选择、直接插入。
• 改进算法:希尔、堆、归并、快速。
从平均情况来看,显然最后 3 种改进算法要胜过希尔排序,并远远胜过前 3 种简单算法。
从最好情况看,反而冒泡和直接插入排序要更胜一筹,也就是说,如果你的待排序序列总是基本有序,反而不应该考虑 4 种复杂的改进算法。
从最坏情况看,堆排序与归并排序又强过快速排序以及其他简单排序。从这三组时间复杂度的数据对比中,我们可以得出这样一个认识。堆排序和归并排序就像两个参加奥数考试的优等生,心理素质强,发挥稳定。而快速排序像是很情绪化的天才,心情好时表现极佳,碰到较糟糕环境会变得不尽如人意。但是他们如果都来比赛计算个位数的加减法,它们反而算不过成绩极普通的冒泡和直接插入。
从空间复杂度来说,归并排序强调要马跑得快,就得给马吃个饱。快速排序也有相应的空间要求,反而堆排序等却都是少量索取,大量付出,对空间要求是 O(1)。如果执行算法的软件所处的环境非常在乎内存使用量的多少时,选择归并排序和快速排序就不是一个较好的决策了。
从稳定性来看,归并排序独占整头,我们前面也说过,对于非常在乎排序稳定性的应用中,归并排序是个好算法。
从待排序记录的个数上来说,待排序的个数 n 越小,采用简单排序方法越合适。反之, n 越大,采用改进排序方法越合适。这也就是我们为什么对快速排序优化时,增加了一个阀值,低于阀值时换作直接插入排序的原因。
从表 9-10-1 的数据中,似乎简单选择排序在 3 种简单排序中性能最差,其实也不完全是,比如,如果记录的关键字本身信息量比较大(例如,关键字都是数十位的数字) ,此时表明其占用存储空间很大,这样移动记录所花费的时间也就越多,我们给出3 种简单排序算法的移动次数比较,如表 9-10-2 所示。  你会发现,此时简单选择排序就变得非常有优势,原因也就在于,它是通过大量比较后选择明确记录进行移动,有的放矢。因此对于数据量不是很大而记录的关键字信息最较大的排序要求,简单排序算法是占优的。另外,记录的关键字信息量大小对那四个改进算法影响不大。
你会发现,此时简单选择排序就变得非常有优势,原因也就在于,它是通过大量比较后选择明确记录进行移动,有的放矢。因此对于数据量不是很大而记录的关键字信息最较大的排序要求,简单排序算法是占优的。另外,记录的关键字信息量大小对那四个改进算法影响不大。
总之,从综合各项指标来说,经过优化的快速排序是性能最好的排序算法,但是不同的场合我们也应该考虑使用不同的算法来应对它 。
堆排序复杂度分析
它的运行时间主要是消耗在初始构建堆和在重建堆时的反复筛选上。
在构建堆的过程中,因为我们是完全二叉树从最下层最右边的非终端结点开始构建,将它与其孩子进行比较和若有必要的互换,对于每个非终端结点来说,其实最多进行两次比较和互换操作,因此整个构建堆的时间复杂度为O(n)。
在构建堆的过程中,因为我们是完全二叉树从最下层最右边的非终端结点开始构建,将它与其孩子进行比较和若有必要的互换,对于每个非终端结点来说,其实最多进行两次比较和互换操作,因此整个构建堆的时间复杂度为O(n)。
在正式排序时,第 i 次取堆顶记录重建堆需要用 O(logi)的时间(完全二叉树的某个结点到根结点的距离为 log2i+ 1) ,并且需要取 n-1次堆顶记录,因此,重建堆的时间复杂度为 O(nlogn) 。
所以总体来说,堆排序的时间复杂度为 O(nlogn) 。由于堆排序对原始记录的排序状态并不敏感,因此它无论是最好、最坏和平均时间复杂度均为 O(nlogn)。这在性能上显然要远远好过于冒泡、简单选择、 直接插入的 O(n²)的时间复杂度了。
空间复杂度上它只有一个用来交换的暂存单元,也非常的不错。不过由于记录的比较与交换是跳跃式进行,因此堆排序也是一种不稳定的排序方法。
另外,由于初始构建堆所需的比较次数较多,因此,它并不适合待排序序列个数较少的情况。
空间复杂度上它只有一个用来交换的暂存单元,也非常的不错。不过由于记录的比较与交换是跳跃式进行,因此堆排序也是一种不稳定的排序方法。
另外,由于初始构建堆所需的比较次数较多,因此,它并不适合待排序序列个数较少的情况。
1.8归并排序
"归并"一词的中文含义就是合并、并入的意思,而在数据结构中的定义是将两个或两个以上的有序表组合成一个新的有序表。
归并排序 ( Merging Sort) 就是利用归并的思想实现的排序方法。它的原理是假设初始序列含有 n 个记录 , 则可以看成是 n 个有序的子序列,每个子序列的长度为1,然后两两归并,得到[n/2] ([x]表示不小于 x 的最小整数)个长度为 2或 1 的有序子序列;再两两归并,……,如此重复, 直至得到一个长度为 n 的有序序列为止 ,这种排序方法称为2路归并排序。
好了,有了对归并排序的初步认识后,我们来看代码。
好了,有了对归并排序的初步认识后,我们来看代码。
public static int[] data = { 50, 10, 90, 30, 70, 40, 80, 60, 20 };
public static int[] output = new int[9];
public static void main(String[] args) {
// TODO Auto-generated method stub
int index = data.length;
int dataLength = 1;
// 排序前的结果
System.out.print("排序之前数组:");
for (int i = 0; i < data.length; i++) {
System.out.print(" " + data[i] + " ");
}
System.out.println();
while (dataLength < index) {
System.out.println("二分排序数组长度:" + dataLength);
mergeAll(index - 1, dataLength);// 归并排序
dataLength = 2 * dataLength;
}
// 排序后的结果
System.out.print("排序后数组:");
for (int i = 0; i < data.length; i++) {
System.out.print(" " + data[i] + " ");
}
}
/** 将所有分开的数组两两合并 */
public static void mergeAll(int n, int dataLength) {
int i;
i = 0;
// 当还有长度为datalength的小数组可合并
while (i <= (n - 2 * dataLength + 1)) {
// 将[i,i+i + dataLength - 1] 和[i + dataLength,2 * dataLength -
// 1]合并为有序数组
mergeTwo(i, i + dataLength - 1, i + 2 * dataLength - 1);
i = i + 2 * dataLength;
}
if ((i + dataLength - 1) < n) {
mergeTwo(i, i + dataLength - 1, n);
} else {
// 将data剩余元素赋值给output数组
for (int t = i; t <= n; t++) {
output[t] = data[t];
}
}
// 将output数组赋值给data数组
for (int t = 0; t <= n; t++) {
data[t] = output[t];
}
System.out.print("当前排序结果:");
for (i = 0; i <= n; i++) {
System.out.print(" " + output[i] + " ");
}
System.out.println();
}
/**
* 将[i,middle] 和 [middle+1,n] 合并排序(从小到大)
*
* @param i
* @param middle
* @param n
*/
public static void mergeTwo(int i, int middle, int n) {
int j, k;
k = i;
j = middle + 1;
while (i <= middle && j <= n) {
if (data[i] <= data[j]) {
output[k++] = data[i++];
} else {
output[k++] = data[j++];
}
}
// 将[i,middle]中剩余的元素添加到output数组中
if (j > n) {
for (int t = 0; t <= middle - i; t++)
output[k++] = data[i + t];
}
// 将[middle+1,n]中剩余的元素添加到output数组中
if (i > middle) {
for (int t = 0; t <= n - j; t++)
output[k++] = data[j + t];
}
}归并排序复杂度分析
时间复杂度对长度为n的数据需要进行log2n次二路归并,每次归并的时间为O(N)。故时间复杂度无论是在最好的情况下还是最坏的情况下都是nlog2(N)。
1.9快速排序
快速排序 ( Quick Sort) 的基本思想是:通过 一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另 一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序的目的 。public static void main(String[] args) {
// TODO Auto-generated method stub
int[] data = { 50, 10, 90, 30, 70, 40, 80, 60, 20 };
int len = data.length;
// 排序前的结果
System.out.print("排序之前数组:");
for (int i = 0; i < len; i++) {
System.out.print(" " + data[i] + " ");
}
System.out.println();
quickSort(data, 0, len - 1);// 将data[0,len-1]的数组进行快速排序
// 排序后的结果
System.out.print("排序后数组:");
for (int i = 0; i < len; i++) {
System.out.print(" " + data[i] + " ");
}
}
/**
*
* @param data
* 待排序数组
* @param left
* 枢纽变量的左边数组下标
* @param right
* 枢轴变量的右边数组下标
*/
public static void quickSort(int[] data, int left, int right) {
int i, j;// 用于循环使用的变量
i = left;
j = right;
int pivot = data[left];// 用数组的第一个元素作为枢轴
if (left < right) {
// 获取枢纽元素的小标,用i接收
while (i < j) {
// 当右边值大于枢轴元素值,则右边元素下标j--
while (i < j && data[j] >= pivot) {
j--;
}
// 当小于枢轴值时,将右边元素交换到枢轴左边
swap(data, i, j);
// 当左边值小于枢轴元素值,则左边元素下标i--
while (i < j && data[i] <= pivot) {
i++;
}
// 当左边元素大于枢轴值时,将左边元素交换到枢轴右边
swap(data, i, j);
}
System.out.print("当前排序结果:");
for (int k = 0; k < data.length; k++) {
System.out.print(" " + data[k] + " ");
}
System.out.println();
// 将枢轴左边的元素继续递归排序
quickSort(data, left, i - 1);
// 将枢轴右边的元素继续递归排序
quickSort(data, i + 1, right);
}
}
/** 交换a数组中的下标为 i 和 j 的值 */
static void swap(int[] a, int i, int j) {
if (j >= 0 && i >= 0) {// 当 i,j大于等于0时执行交换
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}快速排序复杂度
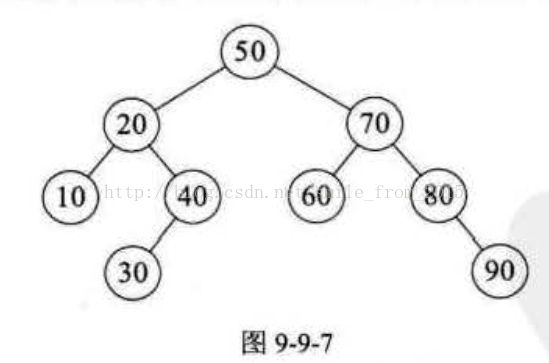
我们来分析一下快速排序法的性能。快速排序的时间性能取决于快速排序递归的深度,可以用递归树来描述递归算法的执行情况。如图 9-9-7所示 , 它是{50,10,90,30,70,40,80,60,20}在快速排序过程中的递归过程 。 由于我们的第一个关键字是 50 ,正好是待排序的序列的中间值,因此递归树是平衡的,此时性能也比较好。
然后,获得的枢轴将数组一分为二,那么各自还需要T(n/2) 的时间(注意是最好情况,所以平分两半) 。于是不断地划分下去,我们就有了下面的不等式 推断,
在最坏的情况下,待排序的序列为正序或者逆序,每次划分只得到一个比上一次划分少)个记录的子序列,注意另一个为空 。 如果递归树画出来,它就是一棵斜树。此时需要执行 n -1 次递归调用,且第 i 次划分需要经过 n-j 次关键字的比较才能找到第 i 个记录,也就是枢轴的位置 , 因此比较次数为n - 1+ n - 2+......+1 =n(n-1)/2,最终其时间复杂度为 O(n2) 。
平均的情况 ,其时间复杂度为O (logn) 。
如果我们选取的枢轴关键字是处于整个序列的中间位置,那么我们可以将整个序列分成小数集合和大数集合了。但是若不在中间,如果在最前面或最后,又会出现相差较大的复杂度。
快速排序优化
1. 优化选取枢轴如果我们选取的枢轴关键字是处于整个序列的中间位置,那么我们可以将整个序列分成小数集合和大数集合了。但是若不在中间,如果在最前面或最后,又会出现相差较大的复杂度。
改进办法,有人提出,应该随机获得一个left与right之间的数middle,让它的关键字left与right交换,此时就不容易出现这样的情况,这被称为随机选取枢轴法。应该说 , 这在某种程度上 ,解决了对于基本有序的序列快速排序时的性能瓶颈 。不过,随机就有些撞大运的感觉,万一没撞成功,随机到了依然是很小或很大的关键字怎么办呢?
再改进,于是就有了三数取中法。即取三个关键字先进行排序,将中间数作为枢轴, 一般是取左端、右端和中间三个数, 也可以随机选取。 这样至少这个中间数一定不会是最小或者最大的数,从概率来说,取三个数均为最小或最大数的可能性是微乎其微的,因此中间数位于较为中间的值的可能性就大大提高了 。由于整个序列是无序状态,随机选取三个数和从左中右端取三个数其实是一回事,而且随机数生成器本身还会带来时间上的开销,因此随机生成不予考虑。
三数取中对小数组来说有很大的概率选择到一个比较好的枢轴关键字, 但是对于非常大的待排序的序列来说还是不足以保证能够选择出一个好的枢轴关键字, 因此还有个办法是所谓九数取中,它先从数组中分三次取样,每次取三个数, 三个样品各取出中间数,然后从这三个中数当中再取出 一个中数作为枢轴 ,显然这就更加保证了取到的枢轴关键字是比较接近中间值的关键字。
2 .优化不必要的交换
3. 优化小数组时的排序方案
2 .优化不必要的交换
3. 优化小数组时的排序方案
如果数组非常小,其实快速排序反而不如直接插入排序来得更好(直接插入是简单排序中性能最好的)。其原因在于快速排序用到了递归操作,在大量数据排序时,这点性能影响相对于它的整体算法优势而言是可以忽略的,但如果数组只有几个记录需要排序时,这就成了一个大炮打蚊子的大问题。
4 .优化递归操作
总结
根据排序过程中借助的主要操作 , 我们将内排序分为:插入排序、交换排序、选择排序和归并排序四类。之后介绍的 7 种排序法,就分别是各种分类的代表算法。
我们将 7种算法的各种指标进行对比,如表 9- 10-1所示。
• 简单算法:冒泡、简单选择、直接插入。
• 改进算法:希尔、堆、归并、快速。
从平均情况来看,显然最后 3 种改进算法要胜过希尔排序,并远远胜过前 3 种简单算法。
从最好情况看,反而冒泡和直接插入排序要更胜一筹,也就是说,如果你的待排序序列总是基本有序,反而不应该考虑 4 种复杂的改进算法。
从最坏情况看,堆排序与归并排序又强过快速排序以及其他简单排序。从这三组时间复杂度的数据对比中,我们可以得出这样一个认识。堆排序和归并排序就像两个参加奥数考试的优等生,心理素质强,发挥稳定。而快速排序像是很情绪化的天才,心情好时表现极佳,碰到较糟糕环境会变得不尽如人意。但是他们如果都来比赛计算个位数的加减法,它们反而算不过成绩极普通的冒泡和直接插入。
从空间复杂度来说,归并排序强调要马跑得快,就得给马吃个饱。快速排序也有相应的空间要求,反而堆排序等却都是少量索取,大量付出,对空间要求是 O(1)。如果执行算法的软件所处的环境非常在乎内存使用量的多少时,选择归并排序和快速排序就不是一个较好的决策了。
从稳定性来看,归并排序独占整头,我们前面也说过,对于非常在乎排序稳定性的应用中,归并排序是个好算法。
从待排序记录的个数上来说,待排序的个数 n 越小,采用简单排序方法越合适。反之, n 越大,采用改进排序方法越合适。这也就是我们为什么对快速排序优化时,增加了一个阀值,低于阀值时换作直接插入排序的原因。
从表 9-10-1 的数据中,似乎简单选择排序在 3 种简单排序中性能最差,其实也不完全是,比如,如果记录的关键字本身信息量比较大(例如,关键字都是数十位的数字) ,此时表明其占用存储空间很大,这样移动记录所花费的时间也就越多,我们给出3 种简单排序算法的移动次数比较,如表 9-10-2 所示。
总之,从综合各项指标来说,经过优化的快速排序是性能最好的排序算法,但是不同的场合我们也应该考虑使用不同的算法来应对它 。
引用《大话数据结构》作者:程杰