李宏毅老师2022机器学习课程笔记 02 卷积神经网络(CNN)
02 卷积神经网络(CNN)
CNN介绍

上图是CNN的完整结构图,先放在这里,下面会以图像分类任务为例,逐步对其进行介绍。
CNN的设计动机
CNN是专门为图像设计的网络结构,结合了许多图像才会有的特性。
CNN在图像分类中的使用
基本结构信息
输入
CNN的输入一般的图片,且图片一般是一个三维的张量,包括图片的宽、图片的高和图片的信道数。图片的宽和高之积即为图片的像素数目,如果图片是彩色图片,那么有RGB三个信道,如果是黑白图片则只有一个信道,相当于此时图片退化为二维的矩阵。
有一个很普遍的前提假设是:所有待分类的图片(即模型的输入)都有相同的大小。在实际应用中,如果图片大小不一致,会对其进行缩放。
输出
CNN的输出是一个 n n n维向量,维数等于设定的类别数,且向量中某个元素的数值越大,代表分类为该类别的可能性越高。
目标标签采用one-hot编码,向量中只有代表相应目标类别的一个元素为1,其他元素均为0。
损失函数
对于分类问题,CNN采用的损失函数一般是交叉熵。
由于数据的标签即为one-hot编码,并且正确分类对应的元素值为1,所以将模型经过softmax函数之后的值与数据的标签进行交叉熵运算,然后用优化算法使得交叉熵最小。
全连接网络的问题(模型参数的个数与数据量关系的问题)
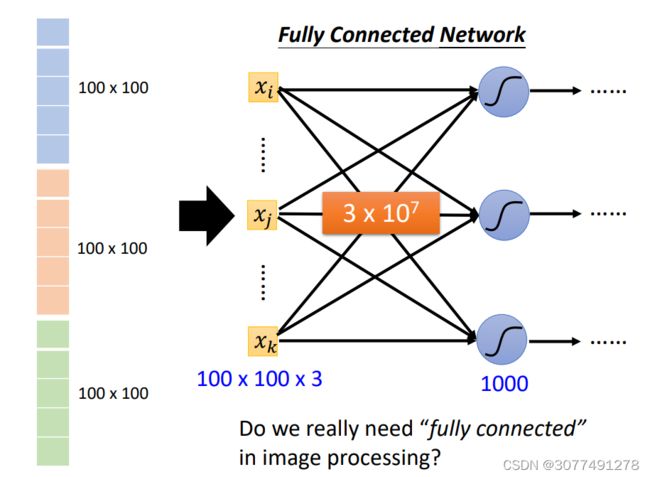
如上图所示,如果在图片分类中使用的是全连接网络(即每个输入都与所有神经元相连),那么未知参数的数量是很庞大的,而这会使得运算量较大,并且会增加过拟合的风险。
更加普适性的说,模型的参数越多,那么模型的弹性越大、能力更强,但是在数据量比较少时容易过拟合,且训练复杂度高。而如果模型参数较小,则模型不容易过拟合,但是无法从更多的数据量中学习到有用的信息。所以,在数据量比较少的时候,用参数少的模型好,在数据量比较大的时候,用参数多的模型好。
图片本身的特性
观察1:特定模式大小是比较小的->设置感受野
CNN在进行图像识别的时候,重点是关注图片中的重要模式(pattern)而非整张图片。
因此,如下图所示,可以仅仅只需要将图片的一小部分(感受野)输入给对应的神经元。这样的好处时大大减少了未知参数的数量。

比如对于一张3*100*100的图片,1000个神经元的全连接网络的输入层,未知参数个数应该为30000*1000。而对于一张3*100*100的图片,按照经典的CNN设定,感受野是3*3,每次移动的步长stride是2,则感受野的数量是50*50(最右和最下边的感受野会有padding填充),若每个感受野只对应一个神经元,那么神经元的数量也是2500,而总的未知参数的个数为9*2500,可见未知参数数量有大幅减少。
当然,由于pattern可能会分布在图片的任何一部分,所以所有的感受野加起来必须要将整张图片完全覆盖。
观察2:相同的模式可能会出现在图片的不同区域->共享参数
由于相同的模式可能会出现在图片的不同区域,因此没有必要对于不同的区域使用不同的参数的神经元进行pattern的侦测,可以考虑将每一个神经元的参数进行共享,即将所有神经元的参数设置为同一套参数。
这样,在前一步的中描述的模型未知参数数量将变为一个感受野的大小,即3*3。当然,一般经典的设定是将一个感受野与64个神经元对应,即未知参数数量是3*3*64。每一个神经元对应的3*3个数量的未知参数也叫一个filter。
当然需要说明的是,虽然每一个神经元的参数都是相同的,但是并不意味着对不同感受野的训练是重复的,因为图片不同区域的输入是不同的,因此经过相同神经元的输出也是不同的。
从filter的角度理解侦测pattern的原理
filter的角度理解侦测pattern的步骤:
- 首先将第一个filter放在图片的左上角,然后将filter中的数值与图片中对应的数值相乘并求和,然后再加上偏置量bias。
- 将filter移动一个步长stride,重复步骤1中运算,直至遍历完整张图片,得到一个新的矩阵(Feature Map)。
- 对所有的filter执行步骤1和步骤2的操作。
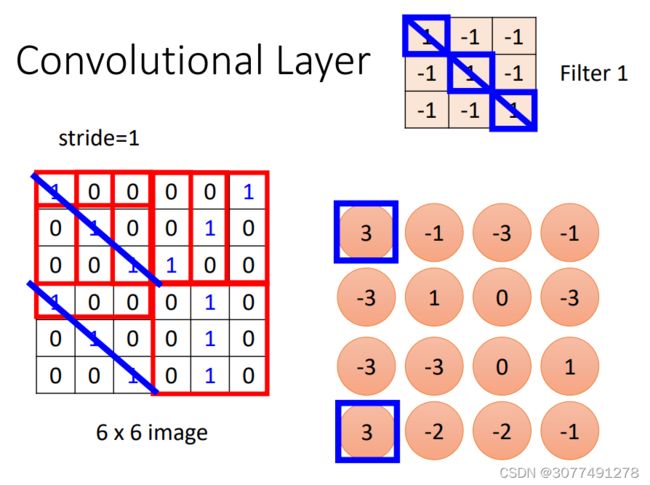
如上图所示,如果感受野中出现了和filter中相近的pattern,那么对应输出的值是比较大的。那么可以认为数值最大的位置,就是可能出现了pattern的位置。
观察3:把图片缩小并不会改变图片中的物体->池化
比如把图片中的奇数列或偶数行去掉,尽管图片会变为原来的 1 / 4 1/4 1/4,但是基本不影响对图片内容的判断,因此可以考虑将每个Feature Map的信息进行分组,然后每组选择一个代表,从而降低其维数,这就是池化(Pooling)。
池化有许多不同的类型,比如Max Pooling是取每一组中数值最大的那一个作为代表。
池化的主要目的是为了降低模型的复杂度,减少运算量,所以当计算资源足够多是池化并不是一个必须要进行的操作。但同时,池化操作会降低模型的精度,尤其是当侦测一些比较细微的模型时,所以现在的很多模型放弃了池化的操作,而是设计full convolution的网络。
当然需要说明的是,池化并不是神经网络的一层,因为池化操作并不涉及到任何未知参数的学习,仅仅是执行固定好的行为,因此池化的作用更加类似于激活函数的作用。
卷积层的设计
每一个卷积层的未知参数由若干个filter构成(严格来说还要加上bias),每个filter中未知参数的个数是感受野的大小*输入数据的通道数。对卷积层训练的过程即对filter中未知参数的学习。
用到卷积层的神经网络就叫做卷积神经网络。
卷积层与全连接层的关系
全连接层包含卷积层,卷积层可以看作是将filter感受野范围之外的未知参数均设置为0,且有许多神经元的未知参数是相同的全连接层。(即全连接层+感受野+参数共享=卷积层)
卷积层与全连接层的优劣
卷积层与全连接层相比,全连接层弹性很大,但容易过拟合。卷积层不容易过拟合,但模型偏差更大。
换言之,全连接层的普适性更强,可以在任何任务上都表现得比较好,但是无法在特定任务上做得更好;而卷积层是专门为图像设计的,所以在图像上能做得更好,但是当把卷积层应用到其他领域时,如果其他领域没有类似于图像中的设计,那么卷积层可能就表现得不好。
CNN的设计
叠加多个卷积层

将图片输入到一个卷积层,卷积层中的每一个filter会对其进行扫描,得到一个Feature Map。
所有的filter得到的Feature Map构成了一张新的通道数为当前卷积层filter个数的“图片”,并将其作为下一个卷积层的输入。
将卷积层与池化结合

在实际应用中往往进行若干次卷积,然后进行一次池化,二者交替进行。
CNN的整体结构

卷积和池化操作完毕之后,会进行flatten。flatten指的是把矩阵中的数据拉直排列成一个向量。然后将flatten之后的向量放入全连接层,并对输出附加一个softmax函数,得到最终的结果。
CNN在其他场景中的使用
α \alpha α Go中的使用
将棋盘看作是像素为19*19的图片,每一个位置用48通道来描述,比如可以在某个通道中对每一个像素用不同的数值来表示有黑子、白子或无子。输出为下一手在哪个位置更好的分类。
CNN之所以能用于下围棋,是因为围棋与图片有许多相似的特征,比如pattern在整张图片中的占比都很小,比如不同的pattern会出现在图片的不同位置。
其他应用
根据具体场景的特性,CNN还被用于语音处理、文字处理中。
CNN的局限性
CNN无法直接对缩放或旋转后的图片进行正确的分类。
只有在训练时,用缩放或旋转后的图片对CNN进行训练,才能使CNN对相关图片的处理有较好的性能。