【路径生成+轨迹优化+输出控制--移动机器人规划器】DWA_planner
系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
TODO:写完再整理
文章目录
- 系列文章目录
- 前言
- 一、DWA_planner算法基本原理
-
- 1.DWA_planner图例
- 2.DWA_planner输入输出
- 3.DWA算法过程(直观理解)
- 4.DWA_planner源码的主要接口及原理
- 总结
-
- 1.算法部署方面
- 2.算法思想
- 3.算法缺点
- 参考资料
前言
认知有限,望大家多多包涵,有什么问题也希望能够与大家多交流,共同成长!在项目和平时的学习中,我对机器人/无人驾驶的决策规划模块进行了划分,当然划分的方法有很多,我的划分方式仅供参考
(1)动态障碍物行为预测模块(Behavior prediction)–结合感知和高精度地图信息,估计周围障碍物未来运动状态
(2)执行机构的轨迹规划模块(Trajectory_planning)–执行机构如机器人载体上的机械臂、串行云台等的运动轨迹规划
(3)任务决策模块(Mission_planning)–任务决策模块比较偏业务层了,处理机器人/无人驾驶的各种任务,主要分为三个方面:车底盘航线业务决策(交规、横向换道等等)、执行应用机构业务决策(机械臂、人机交互等等)、不同场景的导航方案切换决策(组合导航、融合导航)
(4)前端路径探索模块(path_finding)–全局路径规划算法难度不算复杂,找到一条可通行的(必须满足)、考虑动力学的(尽可能满足)、可以是稀疏的路径base_waypoints【由于其只考虑了环境几何信息,往往忽略了无人机本身的运动学与动力学模型。因此,其得到的轨迹往往显得比较“突兀”,并不适合直接作为无人机的控制指令】
(5)后端轨迹处理模块(motion_planning)–我主要归纳整理为三个方向:(1)对base_waypoints进行简单处理及生成方向、(2)对base_waypoints轨迹优化方向【一般是二次优化,这里用的较多的事优化方面的知识】、(3)进行对应功能的replan方向(replan之前的预处理、进入replan的条件、停障replan、避障replan、纠偏replan、换道replan、自动泊车replan、穿过狭窄道路replan等等),这部分内容使用的方法比较专
(6)路径跟踪模块(trajectory_following)–这个模块就得针对机器人载体了,如无人驾驶使用得阿克曼模型可以采用几何的pure pursuit纯追踪算法,更好的可以用模型预测控制MPC方法,还有强化学习做的(效果怎样我就没验证过了);当然也可能事麦克纳姆轮车、差速车PID、还有无人机的三维轨迹跟踪等等
(7)碰撞检测模块
(8)集群多机器人规划模块
当然,这种划分方式是我权衡了原理和功能粗略划分的,在实际产品研发过程中,需要理解了各个算法的功能和定位的基础上融汇贯通,不能生搬硬套,如全段通过hybrid A探索出来的路径与A、RRT*探索出来的路径更平滑,后端轨迹优化的任务就不用这么重了;又如,机器人/无人驾驶项目研发的需求业务还没发展到能响应很多功能阶段,任务决策使用简单的状态机(fsm)就可以对现有任务进行状态转移了
本文先对DWA_planner做个简单的介绍,具体内容后续再更,其他模块可以参考去我其他文章
提示:以下是本篇文章正文内容
一、DWA_planner算法基本原理
1.DWA_planner图例
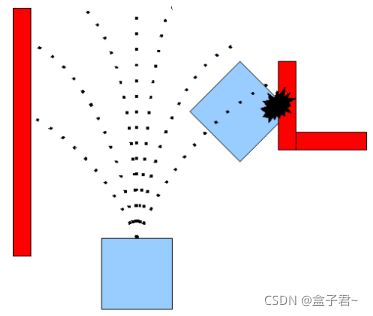
在每一个控制周期搜索最佳的局部路径规划。首先局部规划器会生成一些候选轨迹。其次在检测生成的轨迹是否会与障碍物碰撞。如果没有,规划器就会评价且比较选择出最好的轨迹
简单来说,TrajectorySampleGenerator产生一系列轨迹,然后TrajectoryCostFunction遍历轨迹打分,TrajectorySearch找到最好的轨迹拿来给小车导航;由于小车不是一个质点,【防盗标记–盒子君hzj】worldModel会检查小车有没有碰到障碍物
DWA整体流程和base_local_planner相似,只是重新写了computeVelocityCommands的实现
2.DWA_planner输入输出
(1)输入如下
全局路径global_plan ( nav_msgs/Path)
局部代价地图Costmap2D
机器人的状态(当前速度)odom ( nav_msgs/Odometry)
(2)输出差速机器人底盘的twist指令
(规划和控制集成一体–基于控制状态采样)
3.DWA算法过程(直观理解)
步骤一:在机器人控制空间进行速度控制量离散采样(dx,dy,theta)【防盗标记–盒子君hzj】
步骤二:对每一个采样速度执行前向模拟,看看使用该采样速度(v,w)移动一小段时间后会发生什么
步骤三:评价前向模拟中每个轨迹,评价准则如: 靠近障碍物,靠近目标,贴近全局路径和速度;丢弃非法轨迹(如哪些靠近障碍物的轨迹)
步骤四:挑出得分最高的模拟轨迹对应的速度控制量并发送相应速度给移动底座
重复上面步骤
4.DWA_planner源码的主要接口及原理
(1)initialize()初始化
(2)setPlan()负责获取全局路径
DWAPlannerROS::setPlan获取后,转发给DWAPlanner::setPlan,恢复振荡标志位再转发给LocalPlannerUtil::setPlan,这样层层叠叠的调用很有层次感,【防盗标记–盒子君hzj】这样每当产生一个新的全局路径都第一时间提供给全局——局部转化以及剪裁功能使用
(3)computeVelocityCommands()计算本次控制速度
1、costmap_ros_->getRobotPose(current_pose_)先确定小车当前在全局中位置,负责将小车自身的位姿用tf转化为全局位姿
2、LocalPlannerUtil::getLocalPlan根据小车当前位置裁剪前方一小段路径,将全局路径转化到局部路径,位于base_local_planner包local_planner_util.cpp中
3、DWAPlanner::findBestPath会查找最优局部轨迹,首先调用SimpleTrajectoryGenerator::initialise进行速度采样,然后利用SimpleScoredSamplingPlanner::findBestTrajectory根据速度采样空间进行轨迹产生、打分、筛选,从而得到最优局部轨迹
4、DWAPlanner::updatePlanAndLocalCosts函数调用了MapGridCostFunction即根据栅格地图产生一系列打分项
5、调用LatchedStopRotateController::isPositionReached判断是否到终点了,只是通过判断终点和当前位置的算术距离
6、若到终点了,调用LatchedStopRotateController::computeVelocityCommandsStopRotate函数,使小车旋转至最终姿态;否则继续调用dwaComputeVelocityCommands函数计算下发速度
(4)bool isGoalReached()判断是否达到目标点
总结
1.算法部署方面
(1)DWA_planning是move_base默认的局部规划器
(2)该算法思想比较简单,且ROS已经封装成以一个功能包,【防盗标记–盒子君hzj】比较容易部署与移植
(3)将路径规划器和机器人车底盘控制器集成在一起,其中车底盘模型默认是差速车底盘
(4)算法地图支持,DWA_planning非常依赖于局部地图,特别是局部地图的更新频率和膨胀区的设置
(5)算法定位支持,DWA_planning根本不需要定位信息,仅仅通过odom里程计拿到车辆的速度就行,所以自然都不用对odom里程计进行积分产生漂移了,适合部署,仿真拿定位还要多一步搞到定位信息了
2.算法思想
算法优化的代价函数统筹好【防盗标记–盒子君hzj】追踪全局路径、朝向代价、速度代价、障碍物代价几个评价标准,利用评价函数挑选模拟采样的最优的前向轨迹,进而根据最优的前向模拟轨迹反推确定发送给底座的速度(dx,dy,dtheta)
但没有用到图搜索思想、状态采样思想、也没有用到动力学思想,运动纯靠控制状态采样的,偏向短期的局部应激规划,整体运动效果不太好,先给一个速度看看效果,移动后再通过动态窗口看看下一步应该给什么速度,见步走步,像一个玩具的移动机器人一样,没有远见性,运动可能时一卡一卡的,【防盗标记–盒子君hzj】因为没有考虑轨迹的平滑性和动力学【在障碍物时移动的情况下,效果更差】
【基于控制量采样和状态量采样的异同】DWA_planning的采样方式是基于控制量进行采样(通过odom获得底盘速度就行),所以输出的是速度控制指令,state_lattice_planner的采样方式是基于状态量进行采样(需要直到全局定位),所以输出的是一条带有状态的轨迹
3.算法缺点
DWA_planning到达目标点后,才通过旋转达到对准朝向,【防盗标记–盒子君hzj】规划的时候不考虑车底盘的朝向的,到了目标点才旋转摆正车身,真正机器人允不允许这么做
参考资料
参考视频
https://www.bilibili.com/video/BV1MQ4y1179T?spm_id_from=333.999.0.0
DWA_planner局部路径规划算法论文阅读
https://www.cnblogs.com/dlutjwh/p/11158233.html
DWA_planner源码github地址
https://github.com/amslabtech/dwa_planner
DWA_planner源码分析
https://www.cnblogs.com/sakabatou/p/8297479.html