python自动化测试报告_基于Python的测试报告自动化生成
前言:
日常测试流程中,时常需要将测试结果输出为报告文档予以公示。而如果能够将报告文档生成的过程自动化实现,省去每次编辑表格、格式、图片的时间,无疑是一项可观的效率提升。
针对这一目标,小编了解并尝试了通过python中的docx模块进行word文档自动化生成,于此将其基本方法与实现过程同大家交流分享。
安装:
由于小编使用的是python3,实践过程中发现,如果直接使用pip命令安装模块:
pip install docx
import模块会因版本问题报错,应前往:https://www.lfd.uci.edu/~gohlke/pythonlibs/
下载最新的python_docx-0.8.10-py2.py3-none-any.whl再卸载原版本并重新安装此whl文件:
pip uninstall docx
pip install python_docx-0.8.10-py2.py3-none-any.wh
此时再次尝试import docx则不再有报错提示,即安装成功。
基本方法:
安装成功后,则可以开始着手根据格式、内容需求来生成文档,下面根据文档生成过程中的一些要素来介绍一些docx模块的基本方法。
首先是创建空白文档,其后的所有操作都需要基于文档对象document来进行操作:
from docx import Document
document = Document()
其次则是为文档添加标题、段落这样的基本元素:
document.add_heading('This is my title', 1) #添加1级标题
document.add_paragragh('This is myparagragh') #添加段落
但以此方式添加的标题、段落,其格式只能为docx模块默认格式且内容不易修改,实践中采取了一种更为灵活的方式:
head = document.add_heading(level=1) #添加标题
run = head.add_run('This is my title') #设置标题内容
para = document.add_paragraph() #添加段落
run = para.add_run('This is my paragragh') #设置段落内容
由此,使用run对象进行内容追加,即可于后续直接对其字体等文字属性进行修改,例如:
run.font.name = fontName #设置英文字体
run._element.rPr.rFonts.set(qn('w:eastAsia'), fontName) #设置中文字体
而关于字号、加粗、颜色等其他属性的设置方式和字体设置类似,此处以一个集成函数为例:
from docx.shared import Inches, Pt, RGBColor, Cm
def fontSetup(run, fontName, size, bold=False, rgb=RGBColor(0,0,0)):
run.font.name = fontName
run._element.rPr.rFonts.set(qn('w:eastAsia'), fontName)
if size and isinstance(size,Pt):
run.font.size = size # 设置字号大小,字体单位Pt
if bold and bool(bold):
run.bold = True # 设置文字加粗
if rgb and isinstance(rgb, RGBColor):
run.font.color.rgb = rgb # 设置文字颜色
同样的,也可以修改段落相关属性以契合预期表现效果:
from docx.enum.text import WD_ALIGN_PARAGRAPH
# 设置段落居中
para.paragraph_format.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 设置段落首行缩进
para_section_contents.paragraph_format.first_line_indent = Inches(0.3)
# 段落设置无前后段间距、单倍行距
def paragraphSetup(para, space_before=Pt(0), space_after=Pt(0), line_spaceing=1):
para.paragraph_format.space_before = space_before
para.paragraph_format.space_after = space_after
para.paragraph_format.line_spacing = line_spaceing
在完善了文档中文字、段落的格式之后,还需要针对测试报告中不可或缺的图片与表格进行添加与设置:
# 添加图片并居中,'pic.png'为相对路径,width为图片相对大小
para = document.add_paragraph()
para.paragraph_format.alignment = WD_ALIGN_PARAGRAPH.CENTER
run = para.add_run("")
run.add_picture("pic.png", width=Inches(5))
# 添加表格,rows和cols为行列数、Table Grid为实体边框样式
from docx.enum.table import WD_TABLE_ALIGNMENT
from docx.enum.table import WD_ALIGN_VERTICAL
from docx.enum.style import WD_STYLE_TYPE
table = document.add_table(rows=rows, cols=cols, style='Table Grid')
table.alignment = WD_TABLE_ALIGNMENT.CENTER #表格居中
# 表格内容垂直、水平居中
table.cell(row,col).vertical_alignment= WD_ALIGN_VERTICAL.CENTER
table.cell(row,col).paragraphs[0].paragraph_format.alignment=WD_ALIGN_PARAGRAPH.CENTER
最后,考虑到文档的整体样式,可以对其页面进行设置:
#页面设置,A4,窄边距
def pageSetup(document):
sec = document.sections[0]
#边距
page_distance = Inches(0.5)
sec.left_margin = page_distance
sec.right_margin = page_distance
sec.top_margin = page_distance
sec.bottom_margin = page_distance
# A4
sec.page_width =Inches(8.22)
sec.page_height = Inches(11.65)
实现过程:
小编先来列举两个实现过程中的问题以作示例,继而对文档自动化生成的整体思路进行引申。
其一,报告内容中存在着多处需要加粗或改变字体的文字,那么如何便捷地适配每处文字的具体表现呢?此处的方案是先预设一些‘关键词’如:'V5.1'、'高端机'等,再组成适配re.split()的正则表达式去对报告内容进行分割与设置:
# 根据预设关键词拼接正则表达式
bold_match = ''
for bold_content in bold_contents:
if bold_match:
bold_match = bold_match + '|' + bold_content
else:
bold_match = bold_match + bold_content
bold_match = '(' + bold_match + ')'
# 分割段落文字
set_contents = re.split(bold_match, section_content)
split_contents = [x for x in set_contents if x]
# 根据分割情况设置不同的文字属性进行输出
for split_content in split_contents:
run = para.add_run(split_content)
if not split_content in bold_match:
fontSetup(run, u'宋体', Pt(10.5))
elif split_content.find('V') != -1:
fontSetup(run, 'Calibri', Pt(10.5), True)
else:
fontSetup(run, u'宋体', Pt(10.5), True)
其二,考虑到表格着存在不同形式的合并需求,那么如何使其合并方式自动化地适配数据呢?此处的方案为在预设表格数据时,将合并的表格内数据重复写一次,即:
#表格数据——“评测项目”首行1-2列合并则写了2次、”对比产品“首列5-8行合并写了4次
table_data = {
"1stLine_1" : ["评测项目", "评测项目", "V5.XX.X内存占用", "V5.YY.Y内存占用"],
"2ndLine_2" : ["评测时间", "201X-XX-XX", "评测人员", "XXX"],
"3rdLine_3" : ["评测环境", "设备1", "设备信息", "Android 9.0.0\r(高端机)"],
"3rdLine_4" : ["评测环境", "设备2", "设备信息", "Android 5.1.1\r(中端机)"],
"4thLine_5" : ["对比产品", "竞品1", "产品版本", "X.X.X"],
"4thLine_6" : ["对比产品", "竞品2", "产品版本", "XX.X.X"],
"4thLine_7" : ["对比产品", "新版APP", "产品版本", "5.XX.X"],
"4thLine_8" : ["对比产品", "旧版APP", "产品版本", "5.YY.Y"]
}
其后于脚本的表格输出方法中,直接根据所读取到的重复数据项分布方式来决定表格的合并形式,如首行1-2列数据重复,则:
table.cell(0, 0).merge(table.cell(0, 1))
由以上两个问题进行举一反三,实际上整篇文档均是采取了预设数据、读取数据、输出数据这样的流程进行生成的,其中预设数据指的是:

而数据读取环节,则是去遍历content_data.items()中的内容,由此找到报告文档中每一小节中对应的预设内容,再去根据内容标识进行区分使用对应的方法进行数据输出:
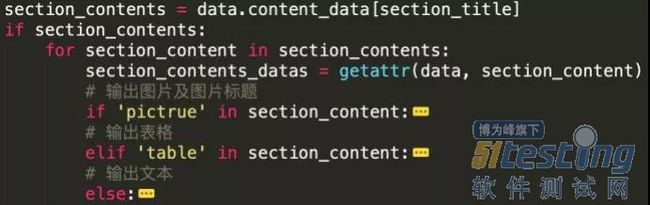
总结:
综上,自动化测试报告生成脚本便完成了,在其后的版本迭代过程中只需更改预设数据中的内容,不同样式或内容的报告即可自动生成,希望本文能够对大家有所帮助,欢迎各位同学一起讨论交流。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理