BeautifulSoup的基本使用方法
find()与find_all()的区别
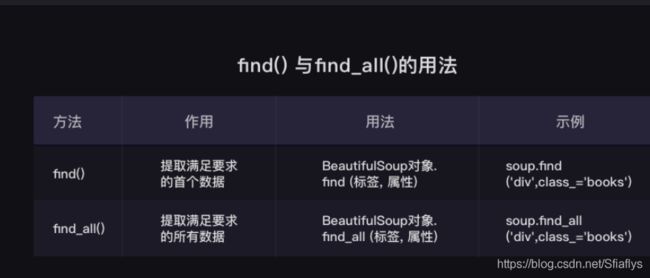
首先,请看举例中括号里的class_,这里有一个下划线,是为了和python语法中的类 class区分,避免程序冲突。当然,除了用class属性去匹配,还可以使用其它属性,比如style属性等。
其次,括号中的参数:标签和属性可以任选其一,也可以两个一起使用,这取决于我们要在网页中提取的内容。
如果只用其中一个参数就可以准确定位的话,就只用一个参数检索。如果需要标签和属性同时满足的情况下才能准确定位到我们想找的内容,那就两个参数一起使用。
Tag对象的三种常用属性与方法

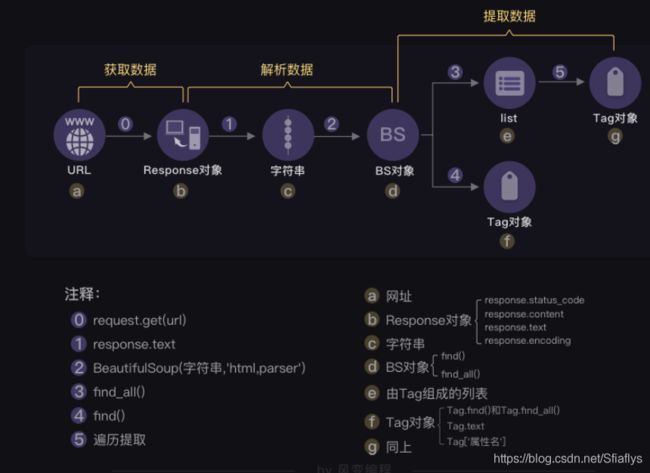
BeautifulSoup提取信息的流程
练习1 博客爬虫
你需要爬取的是博客【人人都是蜘蛛侠】中,《未来已来(四)——Python学习进阶图谱》的所有文章评论,并且打印。
文章URL:
https://wordpress-edu-3autumn.localprod.oc.forchange.cn/all-about-the-future_04/
from bs4 import BeautifulSoup
url='wordpress-edu-3autumn.localprod.oc.forchange.cn/all-about-the-future_04/'
for i in range(300):#抓取前300页的所有评论
r=requests.get(url+str(i))
r.raise_for_status()
r.encoding=r.apparent_encoding
soup=BeautifulSoup(r.text,'html.parser')
items=soup.find_all('div',class_='comment-content')
for item in items:#遍历每一页的所有评论
print(item.text)
练习2 书店寻宝(一)
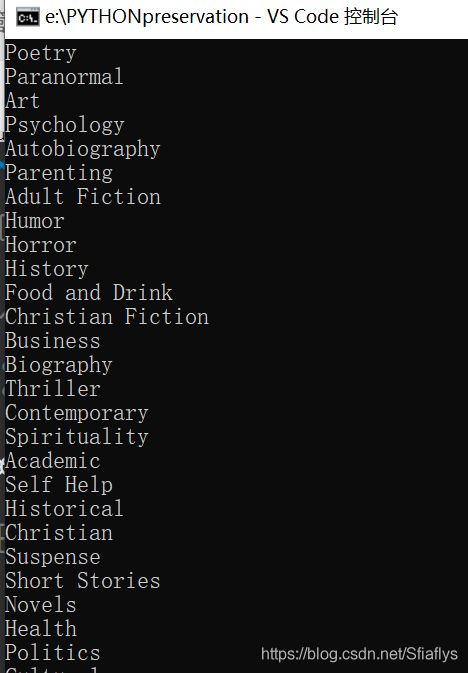
题目要求:你需要爬取的是网上书店Books to Scrape中所有书的分类类型,并且将它们打印出来。
网页URL:http://books.toscrape.com/
它的位置就在网页的左侧,如:Travel,Mystery,Historical Fiction…等。
import requests
from bs4 import BeautifulSoup
url='http://books.toscrape.com/catalogue/category/books/mystery_3/index.html'
r=requests.get(url)
r.encoding=r.apparent_encoding
soup=BeautifulSoup(r.text,'html.parser')
items=soup.find('ul',class_='nav nav-list').find('li').find_all('li')
for item in items:
print(item.text.strip())#strip()可以清除文本首位的空格
运行结果
如果不加strip(),运行结果为:
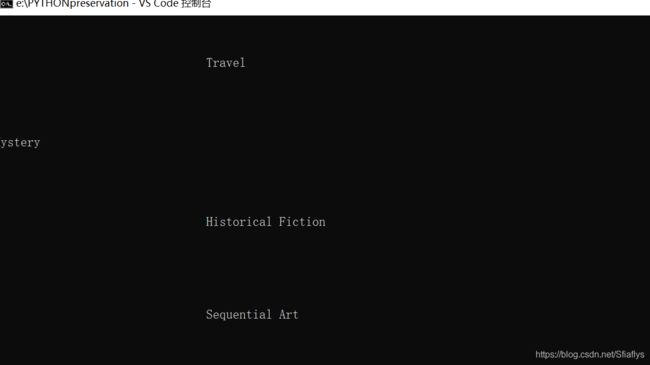
为什么mystery没有格式呢?这是网页的原因:

练习2 书店寻宝(二)
题目要求:你需要爬取的是网上书店Books to ScrapeTravel这类书中,所有书的书名、评分、价格三种信息,并且打印提取到的信息。
网页URL:http://books.toscrape.com/catalogue/category/books/travel_2/index.html
import requests
from bs4 import BeautifulSoup
url='http://books.toscrape.com/catalogue/category/books_1/page-'
n=3#搜索n页内容
print('{0:^36}\t{1:^10}\t{2:^10}'.format('书名','评分','价格'))
for i in range(n):
r=requests.get(url+str(i+1)+'.html')
r.encoding=r.apparent_encoding
html=r.text
soup=BeautifulSoup(html,'html.parser')
items=soup.find_all('article',class_="product_pod")
for item in items:
name=item.find('h3').find('a')['title']
pingfen=item.find('p')['class']
price=item.find('p',class_='price_color')
print('{0:<36}\t{1:>10}\t{2:>10}'.format(name,pingfen[1],price.text))
练习4 博客文章
题目要求:你需要爬取的是博客人人都是蜘蛛侠,首页的四篇文章信息,并且打印提取到的信息。
提取每篇文章的:
文章标题
发布时间
文章链接
网页URL:https://spidermen.cn/
import requests
from bs4 import BeautifulSoup
url='https://wordpress-edu-3autumn.localprod.oc.forchange.cn/'
r=requests.get(url)
r.encoding=r.apparent_encoding
html=r.text
soup=BeautifulSoup(html,'html.parser')
items=soup.find_all('article')
for item in items:
biaoti=item.find('h2').find('a')
lianjie=item.find('h2').find('a')['href']
time=item.find('time',class_='entry-date published')
print(biaoti.text,'\t',time.text,'\n',lianjie)