PyTorch基础(四)卷积神经网络
为什么要使用卷积神经网络?
对于计算机视觉来说,每一个图像是由一个个像素点构成,每个像素点有三个通道,分别代表RGB三种颜色(不计算透明度),我们以手写识别的数据集MNIST举例,每个图像的是一个长宽均为28,channel为1的单色图像,如果使用全连接的网络结构,即,网络中的神经与相邻层上的每个神经元均连接,那就意味着我们的网络有28 28 =784个神经元(RGB3色的话还要3),hidden层如果使用了15个神经元,需要的参数个数(w和b)就有:28 28 15 * 10 + 15 + 10=117625个,这个数量级到现在为止也是一个很恐怖的数量级,一次反向传播计算量都是巨大的,这还展示一个单色的28像素大小的图片,如果我们使用更大的像素,计算量可想而知。
卷积神经网络结构组成
1. 卷积层
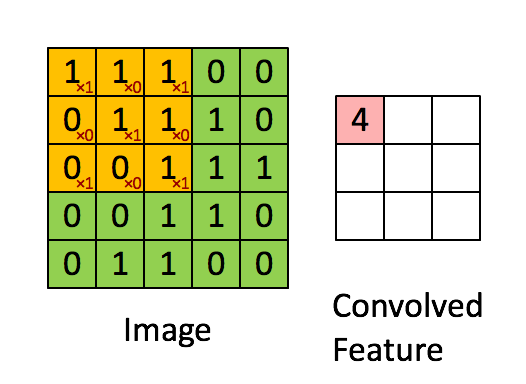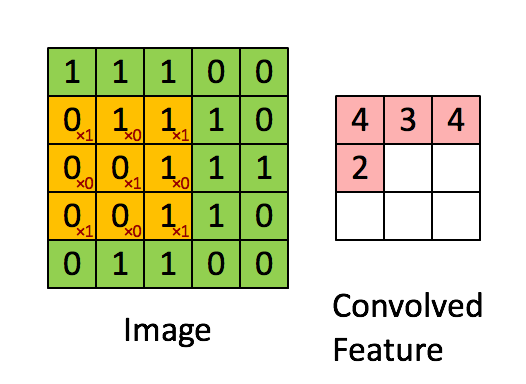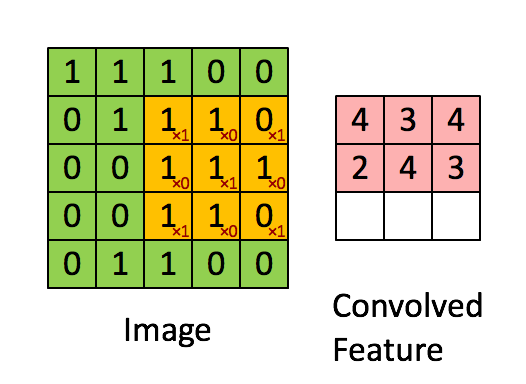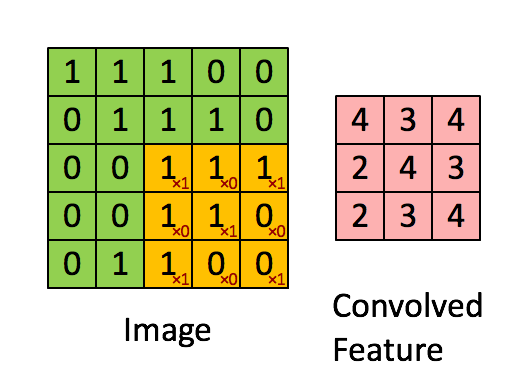
卷积核大小f
边界填充(p)padding: 经过卷积计算后,矩阵大小改变了,如果想要矩阵大小不变,可以先对矩阵进行一个填充,将矩阵周围全部再包围一层,原来5x5的矩阵变为7x7的,然后进行卷积之后计算结果还是5x5
步长(s)tride:从动图上我们能够看到,每次滑动只是滑动了一个距离,如果每次滑动两个距离呢?那要使用步长这个参数。
计算公式:
![]()
2. 激活函数
由于卷积的操作也是线性的,所以也需要进行激活,一般情况下,都会使用relu。
3. 池化层
池化层是CNN的重要组成部分,通过减少卷积层之间的连接,降低运算复杂程度,池化层的操作很简单,就想相当于是合并,我们输入一个过滤器的大小,与卷积的操作一样,也是一步一步滑动,但是过滤器覆盖的区域进行合并,只保留一个值。 合并的方式也有很多种,例如我们常用的两种取最大值maxpooling,取平均值avgpooling
池化层的输出大小公式也与卷积层一样,由于没有进行填充,所以p=0,可以简化为
![]()
4. dropout层
dropout是2014年 Hinton 提出防止过拟合而采用的trick,增强了模型的泛化能力 Dropout(随机失活)是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络,说的通俗一点,就是随机将一部分网络的传播掐断,听起来好像不靠谱,但是通过实际测试效果非常好。 有兴趣的可以去看一下原文Dropout: A Simple Way to Prevent Neural Networks from Overfitting这里就不详细介绍了。
5. 全连接层
全链接层一般是作为最后的输出层使用,卷积的作用是提取图像的特征,最后的全连接层就是要通过这些特征来进行计算,输出我们所要的结果了,无论是分类,还是回归。
我们的特征都是使用矩阵表示的,所以再传入全连接层之前还需要对特征进行压扁,将他这些特征变成一维的向量,如果要进行分类的话,就是用sofmax作为输出,如果要是回归的话就直接使用linear即可。
经典模型
- LeNet-5
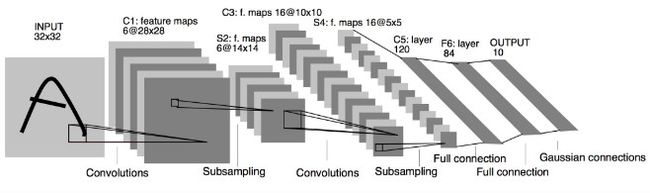
卷积神经网络的开山之作,麻雀虽小,但五脏俱全,卷积层、pooling层,全连接层这些都是现代CNN网络的基本组件
输出:10个类别,分别为0-9数字的概率
Input 32x32,
C1层卷积层,6个卷积核,每个卷积核大小为5x5,经过卷积层处理后变为6个28x28
S2层是pooling层,下采样(2x2)降低网络训练参数及模型的过拟合程度 池化处理后变为6个14x14
C3层是第二个卷积层, 使用16个卷积核,卷积核大小5x5,卷积处理后变为16x10x10
S4层是第二个pooling层,区域:2x2, 池化之后变为16x5x5
C5层是最后一个卷积层,卷积核大小5x5,卷积核种类120
最后使用全连接层,将C5的120个特征进行分类,最后输出0-9的概率
- AlexNet
可以算作LeNet的一个更深和更广的版本,可以用来学习更复杂的对象
改进:
1, 用rectified linear units(ReLU)得到非线性;
2, 使用 dropout 技巧在训练期间有选择性地忽略单个神经元,来减缓模型的过拟合;
3,重叠最大池,避免平均池的平均效果;
4,使用 GPU NVIDIA GTX 580 可以减少训练时间,这比用CPU处理快了 10 倍,所以可以被用于更大的数据集和图像上。

import torchvision
model = torchvision.models.alexnet(pretrained=False) #我们不下载预训练权重
print(model)
- VGG
特点:
1,每个卷积层中使用更小的 3×3 filters,并将它们组合成卷积序列
2,多个3×3卷积序列可以模拟更大的接收场的效果
3,每次的图像像素缩小一倍,卷积核的数量增加一倍
VGG有很多个版本,也算是比较稳定和经典的model。它的特点也是连续conv多计算量巨大,这里我们以VGG16为例:
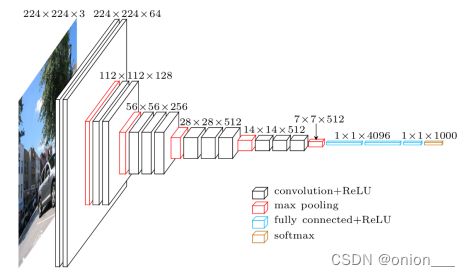
import torchvision
model = torchvision.models.vgg16(pretrained=False) #我们不下载预训练权重
print(model)
- GoogLeNet(Inception)
特点:
1,使用1×1卷积块(NiN)来减少特征数量,这通常被称为“瓶颈”,可以减少深层神经网络的计算负担。
2,每个池化层之前,增加 feature maps,增加每一层的宽度来增多特征的组合性
# inception_v3需要scipy,所以没有安装的话pip install scipy 一下
import torchvision
model = torchvision.models.inception_v3(pretrained=False) #我们不下载预训练权重
print(model)
- ResNet
刚才的GoogLeNet已经很深了,ResNet可以做到更深,通过残差计算,可以训练超过1000层的网络,俗称跳连接
1,退化问题
网络层数增加,但是在训练集上的准确率却饱和甚至下降了。这个不能解释为overfitting,因为overfit应该表现为在训练集上表现更好才对。这个就是网络退化的问题,退化问题说明了深度网络不能很简单地被很好地优化
2,残差网络的解决办法
深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。那现在要解决的就是学习恒等映射函数了。让一些层去拟合一个潜在的恒等映射函数H(x) = x,比较困难。如果把网络设计为H(x) = F(x) + x。我们可以转换为学习一个残差函数F(x) = H(x) - x。 只要F(x)=0,就构成了一个恒等映射H(x) = x. 而且,拟合残差肯定更加容易。
import torchvision
model = torchvision.models.resnet18(pretrained=False) #我们不下载预训练权重
print(model)
resnet18网络结构:
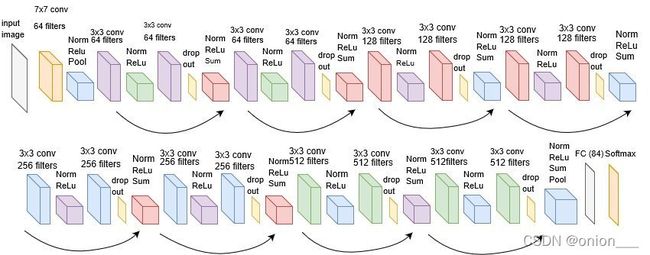
网络选择
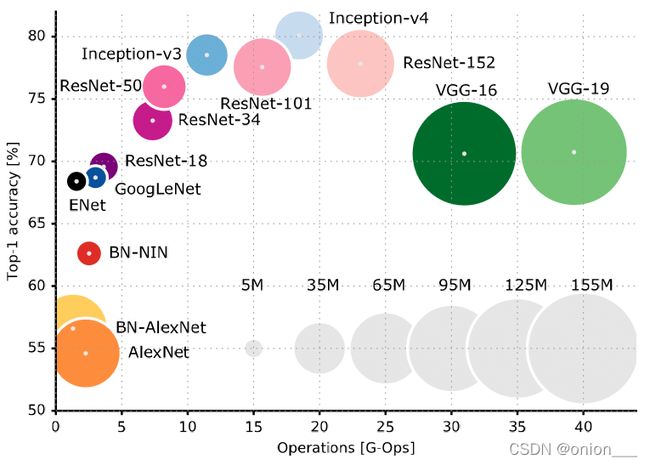
以上表格可以清楚的看到准确率和计算量之间的对比。我的建议是,小型图片分类任务,resnet18基本上已经可以了,如果真对准确度要求比较高,再选其他更好的网络架构。