求职后端--美团一面记录
1.自我介绍
2.项目
项目的介绍,其中包含那个项目比较难,说一说其中的细节,你干了啥。针对其中的一个项目,某一个功能进行解释。
3.基础问题
3.1 HTTP的交互方法
GET 的语义是从服务器获取指定的资源,这个资源可以是静态的文本、页面、图片视频等。GET 请求的参数位置一般是写在 URL 中,URL 规定只能支持 ASCII,所以 GET 请求的参数只允许 ASCII 字符 ,而且浏览器会对 URL 的长度有限制(HTTP协议本身对 URL长度并没有做任何规定)。
POST 的语义是根据请求负荷(报文body)对指定的资源做出处理,具体的处理方式视资源类型而不同。POST 请求携带数据的位置一般是写在报文 body 中, body 中的数据可以是任意格式的数据,只要客户端与服务端协商好即可,而且浏览器不会对 body 大小做限制。
Delete可以删除数据。可通过Get/Post来实现,删除某一个资源。
Put是增加、放置数据,此方法比较少见,可以通过Get/Post来实现。PUT和POST极为相似,但它们之间有一个重要区别,PUT通常指定了资源的存放位置,而POST则没有,POST的数据存放位置由服务器自己决定。
3.2 Get和Post的区别
安全和幂等的概念:
在 HTTP 协议里,所谓的「安全」是指请求方法不会「破坏」服务器上的资源。
所谓的「幂等」,意思是多次执行相同的操作,结果都是「相同」的。
如果从 RFC 规范定义的语义来看:
GET 方法就是安全且幂等的,因为它是「只读」操作,无论操作多少次,服务器上的数据都是安全的,且每次的结果都是相同的。所以,可以对 GET 请求的数据做缓存,这个缓存可以做到浏览器本身上(彻底避免浏览器发请求),也可以做到代理上(如nginx),而且在浏览器中 GET 请求可以保存位书签。
POST 因为是「新增或提交数据」的操作,会修改服务器上的资源,所以是不安全的,且多次提交数据就会创建多个资源,所以不是幂等的。所以,浏览器一般不会缓存 POST 请求,也不能把 POST 请求保存为书签。
3.3 短连接和长连接
短连接
连接->传输数据->关闭连接
HTTP是无状态的,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。
也可以这样说:短连接是指SOCKET连接后发送后接收完数据后马上断开连接。
长连接
连接->传输数据->保持连接 -> 传输数据-> 。。。 ->关闭连接。
长连接指建立SOCKET连接后不管是否使用都保持连接,但安全性较差。
3.4 MySQL的事务
事务可由一条非常简单的SQL语句组成,也可以由一组复杂的SQL语句组成。在事务中的操作,要么都执行修改,要么都不执行,这就是事务的目的,也是事务模型区别于文件系统的重要特征之一。
事务需遵循ACID四个特性:
A(atomicity),原子性。原子性指整个数据库事务是不可分割的工作单位。只有使事务中所有的数据库操作都执行成功,整个事务的执行才算成功。事务中任何一个SQL语句执行失败,那么已经执行成功的SQL语句也必须撤销,数据库状态应该退回到执行事务前的状态。
C(consistency),一致性。一致性指事务将数据库从一种状态转变为另一种一致的状态。在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
I(isolation),隔离性。事务的隔离性要求每个读写事务的对象与其他事务的操作对象能相互分离,即该事务提交前对其他事务都不可见,这通常使用锁来实现。
D(durability) ,持久性。事务一旦提交,其结果就是永久性的,即使发生宕机等故障,数据库也能将数据恢复。持久性保证的是事务系统的高可靠性,而不是高可用性。
3.5 ACID
A(atomicity),原子性。原子性指整个数据库事务是不可分割的工作单位。只有使事务中所有的数据库操作都执行成功,整个事务的执行才算成功。事务中任何一个SQL语句执行失败,那么已经执行成功的SQL语句也必须撤销,数据库状态应该退回到执行事务前的状态。
C(consistency),一致性。一致性指事务将数据库从一种状态转变为另一种一致的状态。在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
I(isolation),隔离性。事务的隔离性要求每个读写事务的对象与其他事务的操作对象能相互分离,即该事务提交前对其他事务都不可见,这通常使用锁来实现。
D(durability) ,持久性。事务一旦提交,其结果就是永久性的,即使发生宕机等故障,数据库也能将数据恢复。持久性保证的是事务系统的高可靠性,而不是高可用性。
3.6 一致性的意思
一致性是事务追求的最终目标。前面提到的原子性、持久性和隔离性,都是为了保证数据库状态的一致性。此外,除了数据库层面的保障,一致性的实现也需要应用层面进行保障。实现一致性的措施包括:
1)保证原子性、持久性和隔离性,如果这些特性无法保证,事务的一致性也无法保证。
2)数据库本身提供保障,例如不允许向整形列插入字符串值、字符串长度不能超过列的限制等。
3)应用层面进行保障,例如如果转账操作只扣除转账者的余额,而没有增加接收者的余额,无论数据库实现的多么完美,也无法保证状态的一致。
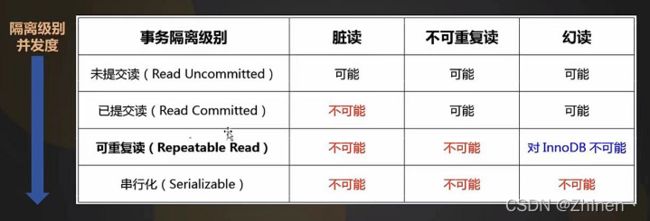
3.7 隔离级别
3.8 锁
排他锁:又称为写锁,排他锁不能与其他锁并存,如一个事务获取了一个数据行的排他锁,其他事务就不能获取该行的锁,只有获取了排他锁的事务是可以对数据行进行读取和修改。
共享锁:又称为读锁,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
3.9 redis
它是内存数据库,使得所有的操作都在内存上进行之外,还有一个重要因素,它实现的数据结构,使得我们对数据进行增删查改操作时,Redis 能高效的处理。
注意,Redis 数据结构并不是指 String(字符串)对象、List(列表)对象、Hash(哈希)对象、Set(集合)对象和 Zset(有序集合)对象,因为这些是 Redis 键值对中值的数据类型,也就是数据的保存形式,这些对象的底层实现的方式就用到了数据结构。
3.10 STL
STL描述
3.11 多线程和多进程
1)一个线程从属于一个进程;一个进程可以包含多个线程。
2)一个线程挂掉,对应的进程挂掉,多线程也挂掉;一个进程挂掉,不会影响其他进程,多进程稳定。
3)进程系统开销显著大于线程开销;线程需要的系统资源更少。
4)多个进程在执行时拥有各自独立的内存单元,多个线程共享进程的内存,如代码段、数据段、扩展段;但每个线程拥有自己的栈段和寄存器组。
5)多进程切换时需要刷新TLB并获取新的地址空间,然后切换硬件上下文和内核栈;多线程切换时只需要切换硬件上下文和内核栈。
6)通信方式不一样。
7)多进程适应于多核、多机分布;多线程适用于多核
4.手撕代码
删除链表中重复的结点:
在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针。 例如,链表 1->2->3->3->4->4->5 处理后为 1->2->5
数据范围:链表长度满足0≤n≤1000 ,链表中的值满足1≤val≤1000
进阶:空间复杂度 O(n) ,时间复杂度 O(n)
例如输入{1,2,3,3,4,4,5}时,对应的输出为{1,2,5},对应的输入输出链表如下图所示:

示例1
输入:{1,2,3,3,4,4,5}
返回值:{1,2,5}
示例2
输入:{1,1,1,8}
返回值:{8}
代码:
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};
*/
class Solution {
public:
ListNode* deleteDuplication(ListNode* pHead) {
if(pHead==nullptr||pHead->next==nullptr)
return pHead;
ListNode *newHead=new ListNode(-1);
newHead->next=pHead;
ListNode *p=newHead,*q=pHead;
while(q){
if(q->next&&q->next->val==q->val){
q=q->next;
while(q->next&&q->next->val==q->val){
q=q->next;
}
q=q->next;
p->next=q;
}else{
p=q;
q=q->next;
}
}
return newHead->next;
}
};