机器学习的概率统计模型(附代码)
目录
系列文章目录
一. 概率论
1.1 离散随机变量分布
1.2 连续随机变量分布
二. 数理统计基础
2.1 抽样分布
2.2 大数定律
2.3中心极限定理
总结
系列文章目录
第一章:会思考的机器你造嘛——AI技术
第二章:机器学习的概率统计模型(附代码)
第三章:深度学习敲门砖——神经网络
第四章:掌握神经网络的法宝(一)
一. 概率论
1.1 离散随机变量分布
1)伯努利分布
伯努利分布又称为两点分布或0-1分布,指的是对于随机变量X有, 参数为p(0 伯努利分布的概率用python代码绘制如下: 运行结果如下: 2)二项分布 如果把一个伯努利分布独立的重复n次,就得到了一个二次分布。二项分布是最重要的离散型概率分布之一。随机变量X要满足这个分布有两个重要条件: 下面利用python代码模拟抛一枚不均匀的硬币20次,设正面朝上的概率为0.6: 运行结果如下: 3)泊松分布 泊松分布的参数λ是单位时间(或单位面积)内随机事件的平均发生次数。 泊松分布适合于描述单位时间内随机事件发生的次数。当二项分布的n很大而p很小时,泊松分布可作为二项分布的近似,其中λ为np。通常当n≧20,p≦0.05时,就可以用泊松公式近似得计算。事实上,泊松分布正是由二项分布推导而来的。 下面是参数μ=8时的泊松分布python实现,在Scipy中将泊松分布的参数表示为μ: 1)均匀分布 均匀分布也叫矩形分布,它是对称概率分布,在相同长度间隔的分布概率是等可能的。 均匀分布由两个参数a和b定义,它们是数轴上的最小值和最大值,通常缩写为U(a,b)。 在python中用location和scale分别表示起点和区间长度,代码如下: 运行结果如下: 2)指数分布 指数分布(也称为负指数分布)是描述泊松过程中的事件之间的时间的概率分布,即事件以恒定平均速率连续且独立地发生的过程。这表示如果一个随机变量呈指数分布,当s,t>0时有P(T>t+s|T>t)=P(T>s)。即,假如你在排队接受服务的时间长短服从指数分布,那么无论你已经排了多久的队,在排t分钟的概率始终是相同的,代码如下: 运行结果如下: 3)正态分布 1)卡方( 2)t分布 3)F分布 本文为大家重点介绍了与人工智能有关的梳理统计方法,概率统计知识在人工智能领域发挥着非常重要的作用,如深度学习理论,概率图模型等都依赖于概率分布作为框架的基本建模语言,学习了解机器学习的概率统计对你的掌握百利无一害~~ 欢迎大家留言一起讨论问题~~~import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
def bernoulli_pmf(p=0.0):
ber_dist =stats.bernoulli(p)
x = [0, 1]
x_name = ['0', '1']
pmf = [ber_dist.pmf(x[0]),ber_dist.pmf(x[1])]
plt.bar(x, pmf, width = 0.15)
plt.xticks(x,x_name)
plt.ylabel('Probability')
plt.title('Pmf of bernoulli distribution')
plt.show()
bernoulli_pmf(p=0.3)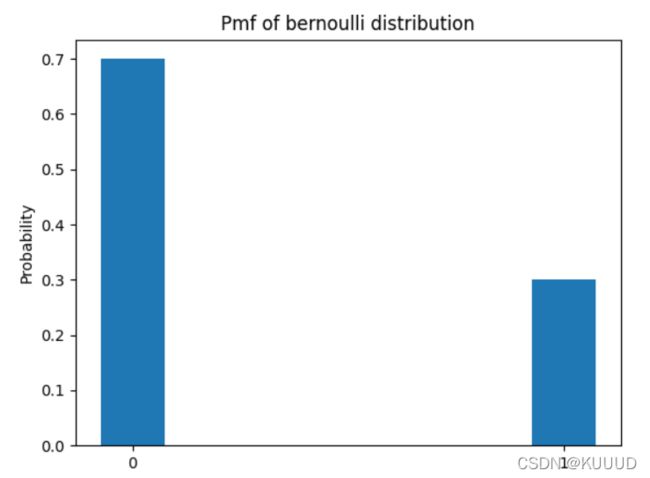
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
def binom_dis(n=1,p=0.1):
binom_dis = stats.binom(n,p)
x = np.arange(binom_dis.ppf(0.0001), binom_dis.ppf(0.9999))
print(x)
fig, ax = plt.subplots(1, 1)
ax.vlines(x, binom_dis.pmf(x), 'bo', label='binom pmf')
ax.legend(loc='best', frameon = False)
plt.ylabel('Probability')
plt.title('PMF of binomial distribution(n={},p={})'.format(n,p))
plt.show()
binom_dis(n=20,p=0.6)
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
def poisson_pmf(mu=3):
poisson_dis= stats.poisson(mu)
x = np.arange(poisson_dis.ppf(0.001), poisson_dis.ppf(0.999))
print(x)
fig, ax = plt.subplots(1, 1)
ax.plot(x, poisson_dis.pmf(x), 'bo', ms=8, label = 'poisson pmf')
ax.legend(loc = 'best', frameon = False)
plt.ylabel('Probability')
plt.title('PMF of poisson distribution(mu={})'.format(mu))
plt.show()
poisson_pmf(mu=8)
1.2 连续随机变量分布
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
def uniform_distribution(loc=0,scale=1):
uniform_dis = stats.uniform(loc=loc,scale=scale)
x = np.linspace(uniform_dis.ppf(0.01), uniform_dis.ppf(0.99), 100)
fig, ax = plt.subplots(1, 1)
#直接传入参数
ax.plot(x, stats.uniform.pdf(x, loc=2, scale=4), 'r-', lw=5, alpha=0.6, label='uniform pdf')
#从冻结的均匀分布取值
ax.plot(x, uniform_dis.pdf(x), 'k-', lw=2, label='frozen pdf')
#计算ppf分别等于0.001,0.5,0.999时的x值
vals = uniform_dis.ppf([0.001, 0.5, 0.999])
print(vals)#[2.004 4. 5.996]
#检测cdf和ppf的精确度
print(np.allclose([0.001, 0.5, 0.999], uniform_dis.cdf(vals)))#结果为True
r = uniform_dis.rvs(size=10000)
ax.hist(r, density=True, histtype='stepfilled', alpha=0.2)
plt.ylabel('Probability')
plt.title(r'PDF of Unit({}, {})'.format(loc, loc+scale))
ax.legend(loc= 'best', frameon = False)
plt.show()
uniform_distribution(loc=2,scale=4)
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
def exponential_dis(loc=0, scale=1.0):
'''
指数分布按照定义只有一个参数lambda,这里的scale = 1/lambda
param loc:定义域的左端点,相当于将整体分布沿x轴平移loc
param scale:lambda的倒数,loc+scale表示改分布的均值,scale^2表示该分布的方差
'''
exp_dis = stats.expon(loc=loc, scale=scale)
x = np.linspace(exp_dis.ppf(0.000001), exp_dis.ppf(0.999999), 100)
fig, ax = plt.subplots(1, 1)
#直接传入参数
ax.plot(x, stats.expon.pdf(x, loc=loc, scale=scale), 'r-', lw=5, alpha=0.6, label='uniform pdf')
#从冻结的均匀分布取值
ax.plot(x, exp_dis.pdf(x), 'k-', lw=2, label='frozen pdf')
#计算ppf分别等于0.001,0.5,0.999时的x值
vals = exp_dis.ppf([0.001, 0.5, 0.999])
print(vals)#[2.004 4. 5.996]
#检测cdf和ppf的精确度
print(np.allclose([0.001, 0.5, 0.999], exp_dis.cdf(vals)))
r = exp_dis.rvs(size=10000)
ax.hist(r, density=True, histtype='stepfilled', alpha=0.2)
plt.ylabel('Probability')
plt.title(r'PDF of Exp(0.5)')
ax.legend(loc= 'best', frameon = False)
plt.show()
exponential_dis(loc=0, scale=2)
二. 数理统计基础
2.1 抽样分布
![]() )分布
)分布2.2 大数定律
2.3中心极限定理
总结