强化学习用 Sarsa 算法与 Q-learning 算法实现FrozenLake-v0
基础知识
关于Q-learning 和 Sarsa 算法, 详情参见博客 强化学习(Q-Learning,Sarsa)
Sarsa 算法框架为
Q-learning 算法框架为

关于FrozenLake-v0环境介绍, 请参见https://copyfuture.com/blogs-details/20200320113725944awqrghbojzsr9ce

此图来自 强化学习FrozenLake求解
需要注意的细节
训练时
- 采用 ϵ \epsilon ϵ 贪心算法;
# 贪婪动作选择,含嗓声干扰
a = np.argmax(Q_all[s, :] + np.random.randn(1, env.action_space.n) * (1. / (i + 1)))
- 对 Q-learning 算法
# 更新Q表
# Q-learning
Q_all[s, a] = Q_all[s, a] + alpha * (r + gamma * np.max(Q_all[s1, :]) - Q_all[s, a])
- 对 Sarsa 算法
# sarsa
# 更新Q表
a_ = np.argmax(Q_all[s1, :] + np.random.randn(1, env.action_space.n) * (1. / (i + 1)))
Q_all[s, a] = Q_all[s, a] + alpha * (r + gamma * Q_all[s1, a_] - Q_all[s, a])
测试时
- 不采用 ϵ \epsilon ϵ 贪心算法;
a = np.argmax(Q_all[s, :])
- 不更新Q表
# # 不更新Q表
# Q_all[s, a] = Q_all[s, a] + alpha * (r + gamma * np.max(Q_all[s1, :]) - Q_all[s, a])
寻找模型中最优的 α \alpha α, γ \gamma γ
我们计算一下不同参数下的学习率, 如下图所示
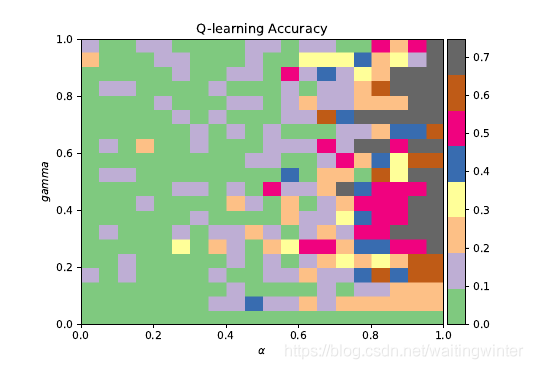

比较两种算法的准确率, 我们用Q-learning算法的准确率减掉Sarsa的准确率, 得到
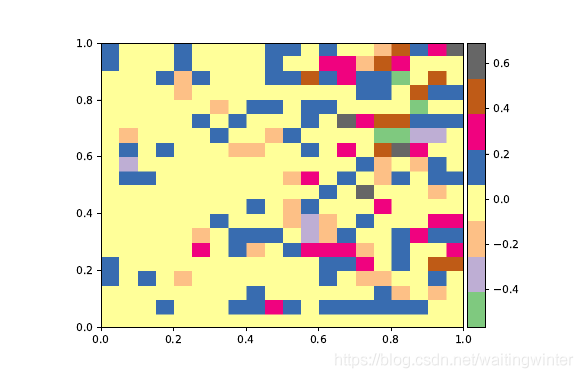
从图中可以看到, 大于0的点均表明在此点对应的 α , γ \alpha,\gamma α,γ下, Q-learning 准确率高于Sarsa.
Python代码
import gym
import numpy as np
import random
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
# gym创建冰湖环境
env = gym.make('FrozenLake-v0')
env.render() # 显示初始environment
# 初始化Q表格,矩阵维度为【S,A】,即状态数*动作数
Q_all = np.zeros([env.observation_space.n, env.action_space.n])
# 设置参数,
# 其中α\alpha 为学习速率(learning rate),γ\gamma为折扣因子(discount factor)
alpha = 0.8
gamma = 0.95
num_episodes = 2000
#
Alpha = np.arange(0.75, 1, 0.02)
Gamma = np.arange(0.1, 1, 0.05)
#Alpha = np.ones_like(Gamma)*0.97
# Training
correct_train = np.zeros([len(Alpha), len(Gamma)])
correct_test = np.zeros([len(Alpha), len(Gamma)])
for k in range(len(Alpha)):
for p in range(len(Gamma)):
alpha = Alpha[k]
gamma = Gamma[p]
# training
rList = []
for i in range(num_episodes):
# 初始化环境,并开始观察
s = env.reset()
rAll = 0
d = False
j = 0
# 最大步数
while j < 99:
j += 1
# 贪婪动作选择,含嗓声干扰
a = np.argmax(Q_all[s, :] + np.random.randn(1, env.action_space.n) * (1. / (i + 1)))
# 从环境中得到新的状态和回报
s1, r, d, _ = env.step(a)
# 更新Q表
# Q-learning
Q_all[s, a] = Q_all[s, a] + alpha * (r + gamma * np.max(Q_all[s1, :]) - Q_all[s, a])
# sarsa
a_ = np.argmax(Q_all[s1, :] + np.random.randn(1, env.action_space.n) * (1. / (i + 1)))
Q_all[s, a] = Q_all[s, a] + alpha * (r + gamma * Q_all[s1, a_] - Q_all[s, a])
# 累加回报
rAll += r
# 更新状态
s = s1
# Game Over
if d:
break
rList.append(rAll)
correct_train[k, p] = (sum(rList) / num_episodes)
# test
rList = []
for i in range(num_episodes):
# 初始化环境,并开始观察
s = env.reset()
rAll = 0
d = False
j = 0
# 最大步数
while j < 99:
j += 1
# 贪婪动作选择,含嗓声干扰
a = np.argmax(Q_all[s, :])
# 从环境中得到新的状态和回报
s1, r, d, _ = env.step(a)
# # 更新Q表
# Q_all[s, a] = Q_all[s, a] + alpha * (r + gamma * np.max(Q_all[s1, :]) - Q_all[s, a])
# 累加回报
rAll += r
# 更新状态
s = s1
# Game Over
if d:
break
rList.append(rAll)
correct_test[k, p] = sum(rList) / num_episodes
# print("Score over time:" + str(sum(rList) / num_episodes))
# print("打印Q表:", Q_all)
# Test
plt.figure()
ax = plt.subplot(1, 1, 1)
h = plt.imshow(correct_train, interpolation='nearest', cmap='rainbow',
extent=[0.75, 1, 0, 1],
origin='lower', aspect='auto')
divider = make_axes_locatable(ax)
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(h, cax=cax)
plt.show()
参考文献
【1】https://blog.csdn.net/kyolxs/article/details/86693085
【2】 强化学习(Q-Learning,Sarsa)
【3】 强化学习FrozenLake求解
【4】https://copyfuture.com/blogs-details/20200320113725944awqrghbojzsr9ce