《计算传播学导论》读书笔记:第七章 数据新闻
目录
第七章 数据新闻
第一节 产生背景
第二节 理论源流
一、计算驱动的新闻报道
二、可视化驱动的新闻报道
三、制作流程
第三节 实战练习
一、维基解密阿富汗战争日志
二、奥运会数据分析和ECharts的使用
本章小结
第七章 数据新闻
数据新闻或数据驱动新闻是计算传播学在新闻生产过程中的应用,强调了运用各种计算方法从数据中寻找故事并进行数据叙事,使信息升华为对公众更有价值的知识,增进公众对社会现实的理解。
数据新闻的生产过程包括确定数据新闻选题、获取数据、分析数据、可视化呈现。首先,数据新闻强调了批判思维、计算思维、可视化思维三种能力的结合,对于新闻生产者提出了更高的要求。数据新闻往往需要数据新闻编辑、程序员、设计师三者的密切合作才能完成。其次,数据尤其是开放数据是数据新闻存在的基础。缺乏数据支撑的数据新闻选题和可视化就会变成“无米之炊”。此外,与精确新闻和计算机辅助报告相比,数据新闻对于数据挖掘和可视化呈现的要求更高。就目前的全球新闻传播学院的数据新闻教学而言,基于编程的数据获取、清晰、过滤、分析和挖掘相对薄弱。
第一节 产生背景
数据新闻产生的根源在于新闻是一种社会知识。新闻传播并非简单的传播信息,更重要的是发掘和传播知识。经典的新闻生产和传播的基本逻辑是收集、编辑和传递信息。然而,当人类进入信息社会之后,尤其是伴随着数字媒体的发展,人类社会的信息规模呈爆炸式增长。与之相对,人们的注意力非常有限。“随着信息的发展,有价值的不是信息,而是注意力。”
伴随着大数据时代到来,公众对于规模巨大的碎片化信息缺乏理解,无法洞察数据的结构和隐藏的意义,无法捕捉到对他们有重要性和相关性的信息,解决这一问题的根源在于让新闻回归其本质。
“在被信息淹没的时代,从‘信息传播’向‘知识传播’转型要求媒体不能仅做片段和碎片式的报道,更要挖掘信息背后的价值,赋予其正确的解释,使受众可以更富有成果地思考,从而让‘信息’升华为对受众更具参考价值的‘知识’。大数据背景下整个社会充斥着数据信息,如果没有媒体作为沟通的桥梁,公众就无法理解这些庞大、零散的信息到底有何意思。媒体有责任帮助公众进行信息的提纯和加工,采用科学的方法分析数据,从纷繁复杂的数据中理出头绪和规律,告知公众这些数据对之意味着什么,与之何联系。”
人类面临的最大挑战是如何应对即将到来的数据风暴。人类认识世界的过程存在一个“数据-信息-知识-智慧金字塔”过程,也被简称为“智慧金字塔”。能够被感知或监测到的任何现象都可以称作信息,其中未被建构的信息代表社会现实,在未被建构的信息和建构后的信息之间存在一条数据鸿沟。数据是对观测现象的记录,实现了对现实的第一次编码。从数据过渡到建构后的信息则需要经过第二次编码,数据被表达为文字、表格、图形等形式,表达数据中隐藏的模式。传播者需要连接外部世界和受众,将未被建构的信息通过数据分析得到建构后的信息。当受众感知和理解传播者建构后的信息时(受众解码),能够获得关于社会现实的新知识。当受众深入理解这些知识后,将知识与个人的经验相结合,知识就可能升华为智慧。在海量的未知和有限的已知之间的缺口日益扩大的今天,我们需要一个专门的“信息架构师”来帮助用户跨越数据与知识间的黑洞,帮助用户远离焦虑。数据新闻正在试图承担这样一个使命。
媒介必须向着提供知识和智慧的方向前进,依赖信息传递为主的媒介在未来将会消亡,媒介即信息成为对未来媒体的诅咒。未来的媒介不能仅仅是信息,数据新闻给出的答案是“知识”和“艺术”。未来的新闻应当服务于公众利益,不应当以娱乐为核心,可以仰赖的生存方式就定位为发掘和传播知识,同时让公众在阅读新闻的过程中满足其艺术审美的需求。因此,数据新闻定位为从数据出发,挖掘知识,发现隐藏在海量信息中的价值;同时需要将信息以艺术的方式表达,彰显创意,吸引眼球。数据新闻与传统新闻相比,它的核心优势恰在于此。
面对21世纪的新闻产业危机,数据新闻代表了一种重要的尝试。数据新闻试图回到挖掘知识和传播知识的本质,并且试图通过可视化的力量来吸引受众的注意力。毫无疑问,数据新闻所代表的这种新闻变革也将重塑我们对于新闻专业主义的理解。
第二节 理论源流
数据新闻的历史来源受益于新闻产业和新闻传播学研究的发展,同时更多地受到了社会科学、统计学、计算机科学、数据科学以及可视化技术的影响。跨学科的影响通过“精确新闻”、“计算机辅助报道”、新闻可视化、数据科学和开放数据运动等形式持续推动了数据新闻的发展。我们将数据新闻的历史源流概括为两条主要的脉络:第一条是计算驱动的新闻报道,集中体现了社会科学、统计学、计算机科学、数据科学等科学逻辑的影响,以精确新闻和计算机辅助报道为代表;第二条是可视化驱动的新闻报道,主要体现了可视化理论和技术,体现了艺术设计的思路。这两条脉络的逻辑交汇点在于通过数据讲故事,即数据叙事。但是,不应该忘记数据叙事的根本目标在于提供新的知识,增进公众对于社会现实的理解,促进群体的智慧。如果仅仅停留在讲故事的层面,数据新闻与其他新闻形式就没有本质的区别。
一、计算驱动的新闻报道
社会科学研究方法和统计学方法构成了数据新闻发展的早期推动力,它们对数据新闻的影响集中体现在“精确新闻”的提出和发展。
精确新闻引起媒体关注的一个重要原因来源于媒体试图摆脱对于政客和商业利益的过度依赖。精确新闻报道就是科学的新闻学,科学方法仍然是人类创造出来的一种应对偏见、痴心妄想和感性忽略的好办法。新闻学确定需要这些方法,现在比以网上更需要,因为这些技能在努力保持着新闻的特性,以免成为“娱乐和广告的变体”。
精确新闻的本质是了解如何处理数据。精确新闻对数据处理的流程包括数据收集、数据存储、数据检索、数据分析、数据清洗和最后的传播。这种对于精确新闻的描述方式与现在的数据新闻工作流程惊人地一致。作为科学的新闻,将理解和解释社会事实作为最重要的目标。数据新闻继承了精确新闻对于社会科学研究方法和数据的高度重视。
二、可视化驱动的新闻报道
数据可视化是数据新闻的另外一种主要的历史源流。如果说数据驱动的新闻报道的思路体现了科学研究的逻辑的话,可视化驱动的新闻报道则体现了新闻报道对于视觉之美的追求。数据新闻就理论而言依然是一种传播形式,需要关注传播效果的问题,而可视化传播或视觉传播提供了一条理想的道路。视觉传播的首要目的是“作为协助我们的眼睛和大脑发掘现象背后隐藏信息的一种工具”。
数据可视化是一种高效的信息传播方式,可以利用很小的视觉空间实现最小的视线移动和鼠标滚动,并达到展示一组数据的目的。从受众的角度来讲,数据可视化之所以有效,主要归功于人类高效的模式识别能力和趋势发现能力。一个具有清晰模式的图像往往具有很强的局部特征,而人类的神经网络可以较好的捕捉这种局部特征,实现快速的模式识别。图形化的符号可将用户注意力引导到重要的目标,高效地传递信息。但是人类执行高效视觉搜索的过程通常只能保持几分钟,因而需要通过一系列的图标说明和丰富的文字说明来进行弥补。
数据可视化对于统计分析而言同样非常重要。

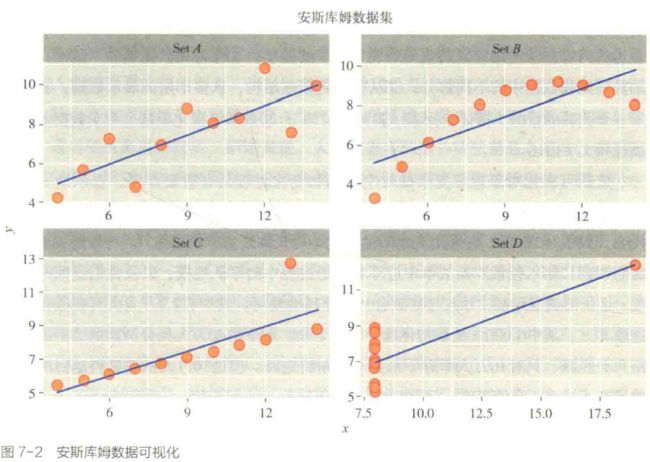
作为视觉传播的可视化建构了受众阅读的文本,这种文本如同其他的传播内容一样,也具有自身的框架;受众作为观察者,花费时间来理解图像传达的信息,通过与图像文本互动而产生了对于信息的理解。因为文本本身就已经有了叙事框架,就有可能偏离社会真实情况,因而任何数据可视化都可能是有偏见的。
数据可视化可以分为探索性可视化和解释性可视化。探索性可视化主要应用于数据分析阶段,数据分析研究人员通过可视化手段快速发现数据中的信号、特征、模式、趋势、异常;解释性可视化则主要存在于视觉呈现阶段,传播者采用可视化工具和手段将已经发现的知识传递给公众。
优秀的可视化致力于使用有限的空间清晰、准确、高效地传播复杂的想法。

新闻选题、计算、可视化三者相结合构成了数据新闻的基本工作流程。
三、制作流程
从数据新闻的生产过程来看,一般由四个步骤组成:第一步,确定数据新闻选题;第二步,数据的收集和整理;第三步,数据的分析和解读;第四步,数据新闻写作与可视化呈现。数据新闻生产的核心是数据驱动。

这有两方面的原因构成:第一,重大新闻选题需要有高质量数据的支撑才能够更好地实现;第二,有一部分数据新闻的选题是在探索数据的过程中逐步产生的。因此,数据新闻生产过程并非一个简单的线性进行的过程。基于数据新闻的类型差异,所选择的具体制作流程也会有差异。因此,数据新闻生产流程更应当被看成是一种网络,即任意两个步骤之间都存在前馈和反馈的关系。
数据驱动的数据新闻生产是一个数据价值提升的过程,它从数据开始,经过过滤与可视化后,最终形成故事。从数据价值的角度来看,原始数据杂乱无章,很少有读者会愿意逐条读取每一项干巴巴的原始数据;经过清晰过滤之后的数据,虽然变得有序,但仍停留在了表象层面;经过可视化的处理,读者可以简单了解到数据背后的模式和不同影响因素之间的关联,可是依然无法明白整个故事的前因后果;只有到最后成文的数据可视化报道才能最大化数据的价值,使读者最终了解事实背后的机制。经过这一过程,数据对公众的价值提升。需要指出的是,我们认为劳伦斯的模型弱化了数据分析在数据新闻生产过程中的作用,仅仅采用数据过滤和可视化是不够的。
第三节 实战练习
一、维基解密阿富汗战争日志
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
df = pd.read_excel('ExplodedIED.xls')
df.head()
print(len(df))
print(df.columns)
df['time'] = [str(i)[:8] + '01' for i in df.DateOccurred]
df['time'] = [i if '200' in i else np.nan for i in df.time]
df['time'] = pd.to_datetime(df.time, format = '%Y-%m-%d')
df['year'] = [str(i)[:4] for i in df.DateOccurred]
df['year'] = [int(i) if '200' in i else np.nan for i in df.year]
df = df.dropna(subset = ['Latitude', 'Longitude'])
plt.figure(figsize=(8, 8))
explode = (0.1, 0.1, 0.2, 0.1, 0.2, 0.3)
df.Region.value_counts().plot(kind='pie', explode=explode, autopct='%0.1f%%', pctdistance=0.5, shadow=True)
plt.show()7527
Index(['ReportKey', 'DateOccurred', 'Type', 'Category', 'TrackingNumber',
'Title', 'Summary', 'Region', 'AttackOn', 'ComplexAttack',
'ReportingUnit', 'UnitName', 'TypeOfUnit', 'FriendlyWIA', 'FriendlyKIA',
'HostNationWIA', 'HostNationKIA', 'CivilianWIA', 'CivilianKIA',
'EnemyWIA', 'EnemyKIA', 'EnemyDetained', 'MGRS', 'Latitude',
'Longitude', 'OriginatorGroup', 'UpdatedByGroup', 'CCIR', 'Sigact',
'Affiliation', 'DColor'],
dtype='object')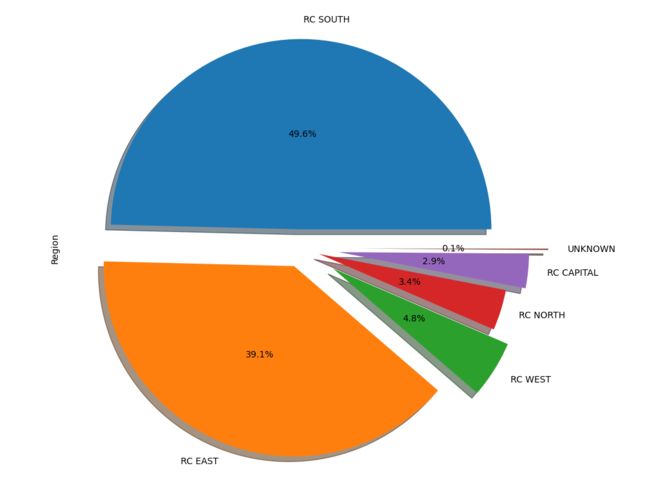
df.time.value_counts().plot(kind='line', figsize=(15, 5))
xmax = df.time.value_counts().idxmax()
ymax = df.time.value_counts().max()
plt.vlines(x=xmax, ymin=0, ymax=ymax, color='r')
plt.annotate('The presidential election \n 2018 Aug 20', xytext=(pd.Timestamp('2007-06-01 00:00:00'), ymax), xy=(xmax, ymax), arrowprops=dict(facecolor='green', shrink=0.05), fontsize=20)
plt.show()
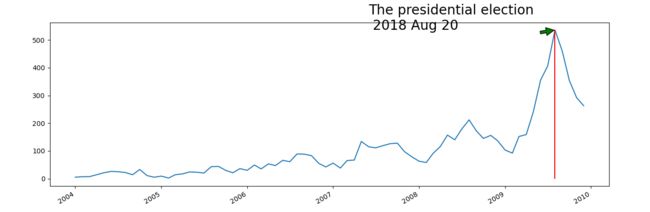
对于袭击事件发生地区的分析揭示了袭击事件在空间分布方面的不均匀性,对于袭击事件的时间序列分析揭示了在时间上同样存在不均匀的特性。接下来我们尝试将每一年的袭击事件通过地图的形式进行更为具体的分析。我们将使用到的一个主要的工具是geopandas。这个工具需要通过pip install geopandas代码在电脑终端进行安装。
(但是很有可能会遇到问题,可参考下面这位老哥的办法)anaconda3 安装geopandas,以及依赖包shapely、gdal、pyproj、fiona_旋转小马的博客-CSDN博客_anaconda安装geopandas版本号:Windows 10专业版anaconda3 python 3.8.8开始时的报错信息没有保存下来,pip install 和conda install 都同样安装报错,好像是如下报错信息:conda install geopandasCollecting package metadata (current_repodata.json): doneSolving environment: failed with initial frozen solve. Retrying ..https://blog.csdn.net/u014543416/article/details/121160778
import geopandas as gpd
import matplotlib.pyplot as plt
from shapely.geometry import Point
country = gpd.GeoDataFrame.from_file('afghanistan_district398.shx')
country.plot(figsize=(15, 15), color='grey')
plt.show()
import geopandas as gpd
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from shapely.geometry import Point
df = pd.read_excel('ExplodedIED.xls')
df['time'] = [str(i)[:8] + '01' for i in df.DateOccurred]
df['time'] = [i if '200' in i else np.nan for i in df.time]
df['time'] = pd.to_datetime(df.time, format = '%Y-%m-%d')
df['year'] = [str(i)[:4] for i in df.DateOccurred]
df['year'] = [int(i) if '200' in i else np.nan for i in df.year]
df = df.dropna(subset = ['Latitude', 'Longitude'])
country = gpd.GeoDataFrame.from_file('afghanistan_district398.shx')
country.plot(figsize=(15, 15), color='grey')
plt.show()
def plot_points_on_shapefile(year, ax):
country = gpd.GeoDataFrame.from_file('afghanistan_district398.shp')
# Create a DataFrame with some cities, including their location
places = df[['TrackingNumber', 'Latitude', 'Longitude', 'year']][df.year == year]
# Create the geometry column from the coordinates
# Remember that longitude is east-west(i.e.X) and latitude is north-south(i.e.Y)
places['geometry'] = places.apply(lambda row: Point(row['Longitude'], row['Latitude']), axis=1)
del(places['Latitude'], places['Longitude'], places['year'])
# Convert to a GeoDataFrame
places = gpd.GeoDataFrame(places, geometry='geometry')
## Declare the coordinate system for the places GeoDataFrame
# GeoPandas doesn't do any transformations automatically
# CRS(WGS84) transformation is needed
places.crs = {'init': 'epsg:4326'}
country.crs = {'init': 'epsg:4326'}
## Perform the spatial join
country.plot(ax=ax, color='#cccccc')
places.plot(ax=ax, markersize=5, color='#cc0000')
plt.axis('off')
plt.title(str(year))
fig = plt.figure(figsize=(12, 8), facecolor='white')
year = [2004 + i for i in range(6)]
for k, i in enumerate(year):
ax = fig.add_subplot(2, 3, k+1)
plot_points_on_shapefile(i, ax)
plt.tight_layout()二、奥运会数据分析和ECharts的使用
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
game = pd.read_csv('summer.csv')
country = pd.read_csv('dictionary.csv')
game['gold'] = 0
game['silver'] = 0
game['bronze'] = 0
game['score'] = 0
game['gold'][game['Medal']=='Gold'] = 1
game['silver'][game['Medal']=='Silver'] = 1
game['bronze'][game['Medal']=='Bronze'] = 1
game['score'][game['Medal']=='Gold'] = 4
game['score'][game['Medal']=='Silver'] = 2
game['score'][game['Medal']=='Bronze'] = 1
gsb = game.groupby(['Country']).sum()[['gold', 'silver', 'bronze', 'score']]
gsb = gsb.sort_values(['score'], ascending=False)
print(gsb[:20])
gold silver bronze score
Country
USA 2235 1252 1098 12542
URS 838 627 584 5190
GBR 546 621 553 3979
ITA 476 416 404 3140
FRA 408 491 497 3111
GER 452 378 475 3039
HUN 412 316 351 2631
AUS 312 405 472 2530
SWE 349 367 328 2458
GDR 329 271 225 2083
CHN 290 296 221 1973
NED 233 279 339 1829
RUS 239 238 291 1723
JPN 213 272 303 1699
NOR 209 200 145 1381
CAN 155 232 262 1346
ROU 157 195 288 1306
KOR 158 204 167 1207
DEN 150 197 160 1154
FRG 143 167 180 1086def gini_coefficient(v):
bins = np.linspace(0., 100., 11)
total = float(np.sum(v))
yvals = []
for b in bins:
bin_vals = v[v <= np.percentile(v,b)]
bin_fraction = (np.sum(bin_vals) / total) * 100.0
yvals.append(bin_fraction)
# perfect equality area
pe_area = np.trapz(bins, x=bins)
# lorenz area
lorenz_area = np.trapz(yvals, x=bins)
gini_val = (pe_area - lorenz_area) / float(pe_area)
return bins, yvals, gini_val
score_all = game.groupby(['Country']).sum()['score']
bins, result, gini_val = gini_coefficient(score_all)
plt.plot(bins, result, label='$observed$')
plt.plot(bins, bins, '--', label='$perfect\;eq.$')
plt.xlabel('$Fraction\;of\;Countries$')
plt.ylabel('$Fraction\;of\;Olympic Scores$')
plt.title('$GINI:%.4f$'%(gini_val))
plt.legend(loc=0)
plt.show()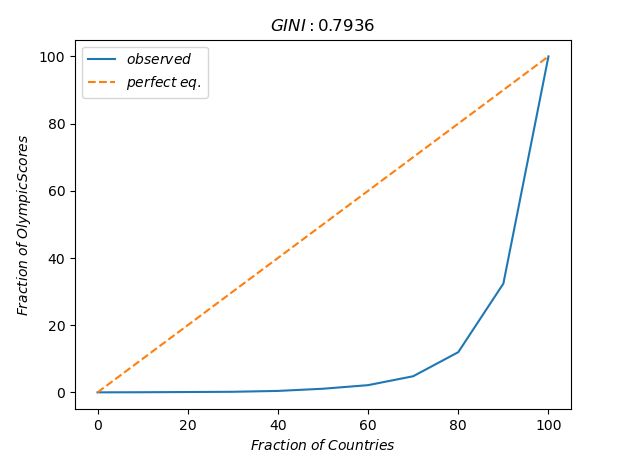
ggy = game.groupby(['Year', 'Country']).sum()['score']
years = game.Year.unique()
gini = [gini_coefficient(ggy[i])[2] for i in years]
fig = plt.figure(figsize=(12, 4), facecolor='white')
plt.plot(years, gini, 'r-o')
plt.ylabel(r'$Gini\;Coefficients$', fontsize=10)
plt.show()
奥运会比赛被垄断程度随时间的变化

本章小结
综上,本章介绍了数据新闻的基本定义、产生背景、理论源流、制作流程和实战练习。需要强调的具备批判思维、计算思维和可视化思维是学习数据新闻的重要方面。数据新闻以数据为核心,需要更多的编程技能、统计知识和数据可视化的能力。在数据新闻的制作过程中,首先,必须找到数据,这可能需要像MySQL或者Python这样的专业技能;其次,能够进行数据分析和挖掘,需要了解统计学的基本知识;最后,使用开源工具进行数据可视化。要有意识地选修社会统计课程、数据分析课程,学习数据科学的编程工具(推荐R和Python),学习网络爬虫的编写,经常写博客积累一些知识,经常使用搜索引擎进行搜索,使用Github保存和分享代码,使用Stack Overflow进行提问。
不同背景的人在学习数据新闻的时候面临的困难是不一样的。计算机背景的同学可能在艺术设计方面有所缺失,或在批判思维的方面有所不足;对新闻学院的同学而言,新闻选题和可视化设计的训练是必修课,计算思维则可能是短板,因而需要花费更多的时间去训练。从计算思维的训练角度来讲,编写代码对于年轻的学习者而言不可避免。首先,虽然有很多打包好的现成的工具可以使用,但是使用者无法修改或者游湖按已经封装好的软件工具。每当我们试图去做一点个性化的改变的时候,编写代码的优势就体现出来了。其次,很多工具需要重复进行,采用编写代码的方式(尤其是Jupyter Notebook编程环境记录下来计算的过程)可以有效地减少这种重复所造成的时间浪费。最后,编写的代码容易分享,也方便记录操作过程,从而有利于检查错误。
数据新闻是一个迅速发展的领域,尤其注重实践练习,需要向业界学习数据新闻生产的经验。学习数据新闻需要经常关注国内外的数据新闻团队的作品,关注每一年颁发的数据新闻获奖作品,分析其设计理念、数据来源、呈现技术、优缺点等方面。数据新闻不是靠一个人就能完成的工作,它涉及新闻选题策划、数据收集、数据清洗、数据分析和可视化等多个方面,需要新闻编辑、数据分析师、可视化设计师组成数据新闻团队,相互协同、一起努力。学习数据新闻需要训练合作意识和分享意识,增强团队协同能力。在数据新闻学习的过程中,可以积极地使用Github开放数据、分享代码、传播数据新闻作品。数据新闻人才是独角兽,非常稀缺,但成长为一个合格的数据新闻人才并不容易。如果你决定要成为一名数据新闻生产者,就要以更高的标准要求自己,需要更勤奋、更专注、更开放。