目标检测之YOLOv4
目标检测之YOLOv4
- 框架
- 技巧Trick/优化
-
- 1.BoF
- 2.BoS
- YOLO V4
论文地址:YOLOv4: Optimal Speed and Accuracy of Object Detection
源代码:https://github.com/AlexeyAB/darknet,原作者YOLO V4的代码是基于C++的
pytorch实现:
https://github.com/GZQ0723/YoloV4
https://github.com/Tianxiaomo/pytorch-YOLOv4
禁止任何形式的转载!!!
YOLOV4兼顾了速度和精度(文中也说了设计的初心还是保证大家用单张显卡就能完成实验),所以这里先对YOLO V4简单总结一下,后续有时间会把一些内容展开(可以点进蓝色字体的链接get相应的知识)。

框架
文中将检测的框架进行了划分:
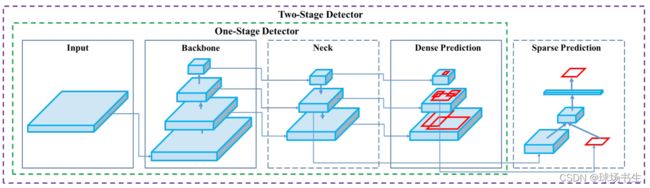
先不讲YOLO V4的具体结构,先把这个框架讲完,YOLO V4无非就是从这个框架里选取出来的。
• Input:Image, Patches, Image Pyramid
• Backbones(提取特征):VGG, ResNet, DenseNet,ResNeXt,CSPResNeXt50,CSPDarknet53(手工设计的适合在GPU上用);SqueezeNet,MobileNet,ShuffleNet,GhostNet,MixNet(轻量级网络,CPU上比较友好);此外还有通过自动搜索得到的网络结构SpineNet, EfficientNet-B0/B7 , EfficientNet V2
• Neck(收集提取到的特征):
- Additional blocks:通常为注意力模块(SE,SAM );多尺度模块(SPP, ASPP,DCN,RFB)多尺度模块小结
- Path-aggregation blocks:聚合不同的特征FPN, PAN,NAS-FPN, Fully-connected FPN, BiFPN, ASFF, SFAM (小结1,小结2)
• Heads(输出检测结果):单阶段是在整个特征图上进行预测,最终会输出很多检测结果,所以是Dense Prediction;两阶段是在候选框的基础上再预测,结果就相对较少,Sparse Prediction。
- Dense Prediction (one-stage):
◦ RPN, SSD, YOLO, RetinaNet(anchor based)
◦ CornerNet, CenterNet, MatrixNet, FCOS(anchor free) - Sparse Prediction (two-stage):
◦ Faster R-CNN, R-FCN, Mask RCNN(anchor based)
◦ RepPoints(anchor free)
技巧Trick/优化
BoF与BoS可以理解为一些涨点的Trick,BoF不影响测试的时间,会影响训练的时间;BoS会牺牲一部分的测试时间。
1.BoF
一般来说都是在输入,输出和训练方式做文章,而不是对网络做更改,只有这样才不会影响推理时间。
数据增强:
基本的一些请看【数据增强综述】(这个人讲得超棒);没有涉及到的这里单列一下
Random erasing,随机擦除随机选择图像中的一个矩形区域,并用随机值擦除其像素。
Cutout,原论文有两种方法,简单方式选择一个固定大小的正方形区域,然后将该区域填充为0即可;有针对性的方法,专门从图像的输入中删除图像的重要特征,具体是:在训练的epoch过程中,保存每张图片输出的最大特征激活点,在下一回合,对最大激活图上采样到和原图一样大,使用阈值划分为二值图,盖在原图上再输入cnn中训练。
hide-and-seek ,不再通过随机位置确定patch的位置,而是将原图划分为若干份,然后对划分的每一份依概率进行隐藏。如果简单的将像素值替换为0,暴力填黑,会造成训练和测试数据分布不一致问题。因此,作者采用整个数据集的均值来处理【不是单张图像的均值】
GridMask:

正则化:Dropout、Dropconnect、Dropblock。对于全连接,DropOut是将神经元激活输出随机置0,而DropConnect是作用于输入神经元的权重,以一定概率将与其相连的输入权重清0。对于卷积,卷积层的特征是空间强相关的,即使有DropOut,信息仍能传送到下一层。DropBlock的本质其实就是将Cutout方法应用于CNN的每一个特征图。

Spatial Dropout常用于NLP中,是对特征层的整个通道drop。
DropPath是将深度学习模型中的多分支结构随机失活的一种正则化策略。

语义分布偏差(如:数据样本类别不平衡;类别间有关联):
-
数据样本类别不平衡:难例挖掘hard negative example mining(通常用于两阶段方法,因为RPN之后的有些负样本很容易被分对);OHEM(正负样本都挖掘,根据损失排序选出难样本,并作为ROI网络的输入);Focal Loss(单阶段网络不像双阶段,双阶段会先选取候选框,把正负样本控制在一定比例);GHM梯度均衡机制(梯度越大,越不好分);IoU bbalance loss(针对正样本的,强化分类和回归的关系,高IoU低socre,低IoU高socre)
-
类别间有关联:Label Smoothing;基于知识蒸馏的soft label
边框回归:IoU GIoU DIoU CIoU Loss
2.BoS
-
往网络里加入一些涨点的模块
增强感受野的多尺度模块:SPP, ASPP,DCN,RFB
注意力机制:SE,SAM
特征聚合:skip connection,hyper-column,FPN, PAN,NAS-FPN, Fully-connected FPN, BiFPN, ASFF, SFAM
激活函数:

-
后处理方法
NMS:是直接删去周围非最大分数的框,将IoU大于阈值的窗口的得分全部置为0。
Soft NMS:核心是降低置信度,而非直接删除。这样可以保留下一些靠得比较密集的目标,只抑制同一物体上重复的框。不过这是理想状况,实际还需要调参。

上面这个线性加权公式是不连续的,导致box集合中的score出现断层,因此就有了下面这个式子(大部分实验中采用的式子)。高斯函数是连续的,而且离得越近函数越高耸,衰减越大,满足在没有重叠时应该没有惩罚,在高重叠时应该有很高的惩罚。
DIoU NMS: DIoU替代IoU 作为NMS的评判准则
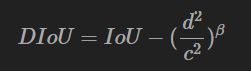
参数β用于控制中心距离所代表的重要性

为什么不用CIOU_nms?因为CIOU,是在DIOU基础上添加形状,包含groundtruth标注框的信息,在训练时用于回归。但在测试过程中,并没有groundtruth的形状信息。除非我们之前事先知道待检测的目标的长宽形状比例,这个时候我们可以事先规定后计算CIOU。
YOLO V4
上面提到那么多的方法,我再来看看究竟如何在“菜单”里面点菜。
先是来一份"硬菜"——主干网络:对分类最优的参考模型并不总是对检测器最优的。与分类器相比,检测器需要满足以下要求:
①更大的网络输入分辨率——用于检测小目标
②更深的网络层——能够覆盖更大面积的感受野
③更多的参数——更好的检测同一图像内不同size的目标
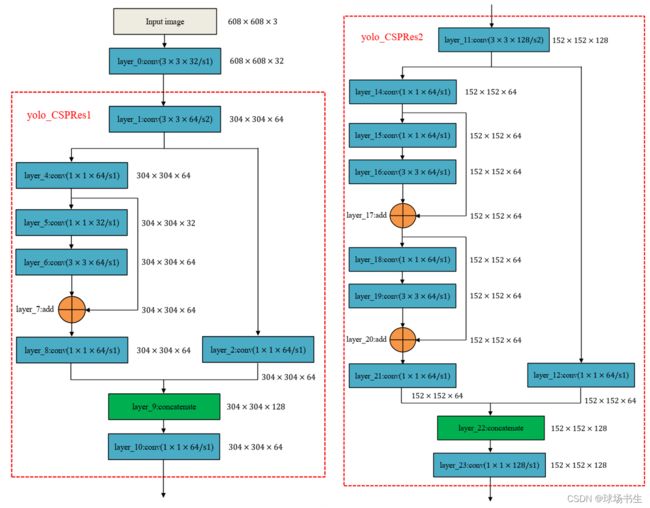
这里选择了CSPDarknet53
再来一些陪衬的"小菜"——一些涨点的模块:SAM、SPP additional module、PANet path-aggregation neck、YOLOv3 head
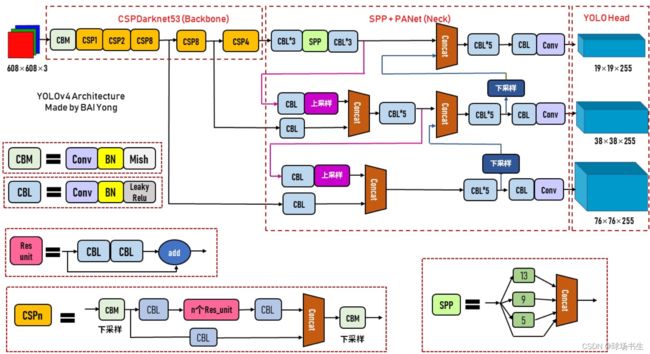
网络结构解读
CSP:Cross Stage Partial,可以增强CNN的学习能力,能够在轻量化的同时保持准确性、降低计算瓶颈、降低内存成本。顾名思义就是将特征分成两部分,一部分的特征直接送到下一阶段,另一部分的特征经过多层Conv。
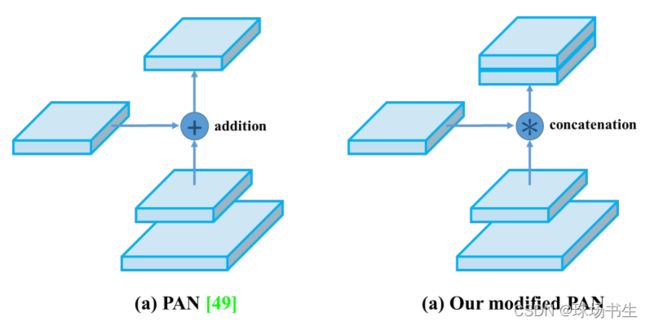
PAN:Neck部分主要用来融合不同尺寸特征图的特征信息。

这YOLOv4里进行过改动:相加改为拼接
SAM改进:将SAM从空间上的attention修改为点上的attention

激活函数: 由于PRELU和SELU的训练难度较大,而ReLU6是专门的量化网络的设计,最后主干网络选择了Mish。在后面输出的部分是用的leaky-ReLU。
结构完成之后,无非就是一些提升性能的方法了:
边界框回归损失: CIoU Loss
类别损失:Class label smoothing
数据增强:CutOut, CutMix
正化方法:DropBlock
后处理:DIoU-NMS
训练策略:余弦退火学习率(Cosine Annealing LR),遗传算法选择超参数,随机多尺寸训练,
自我对抗训练(SAT):在第一阶段,神经网络会更改原始图像,而不是网络权重。这样,神经网络通过改变原始图像,从而创造了一种图像上没有想要目标的假象,对其自身执行了对抗攻击。在第二阶段,训练神经网络以正常方式检测此修改图像上的目标。
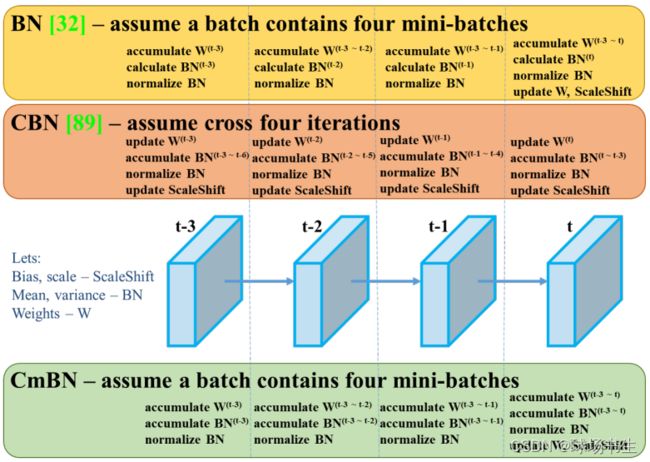
CmBN:CBN解决BN批次太小的问题,batch不想调大,但是有希望能达到batch很大的效果,就采用统计前几个迭代的均值和方差。CBN属于利用不同的iter数据来变相扩大batchsize从而改进模型的效果。而CmBN做的改动是仅收集单个batch中的mini-batches之间的统计信息。具体可以看这里,讲得比较清晰。CmBN是CBN的简化版本,其唯一差别就是在计算第t时刻的BN统计量时候,CBN会考虑前一个mini batch内部的统计量,而CmBN版本,所有计算都是在mini batch内部。
Multiple anchors for a single ground truth:如果IoU(ground truth, anchor) > 阈值,为一个ground truth使用多个anchor。(需要考证)
消除网络敏感性:之前使用sigmoid来偏移,需要tx为极端的值才能使得sigmoid(tx)为0或者1,所以在前面乘一个大于1的数,让他不需要输出极端大或者小的值就能达到网格端点。

MS COCO目标检测实验中,默认的超参数为:
- 训练步骤为500500;
- 采用初始学习速率0.01的步长衰减学习速率策略,在400000步和450000步分别乘以因子0.1;
- momentum衰减为0.9,weight衰减为0.0005。
- 所有的架构都使用一个GPU来执行批处理大小为64的多尺度训练,而小批处理大小为8或4取决于架构和GPU内存限制。
除了使用遗传算法进行超参数搜索实验外,其他实验均使用默认设置。
遗传算法利用YOLOv3-SPP进行带GIoU损失的训练,搜索300个epoch的min-val5k集。
- 遗传算法实验采用搜索学习率0.00261、momentum0.949、IoU阈值分配ground truth
0.213、损失归一化器0.07。
遗传算法这里讲得很简单易懂:
- 就是很多组参数分别进行训练;
- 淘汰里面评价指标很差的参数组合,留下表现最好的部分超参数组合;
- 将保留下来的参数组合,选择出的两个超参数组合进行交叉形成新的超参数组合进入下一个环节(类比于优良基因的交配),父母”超参数组合并不是使用均匀的随机采样,而是基于轮盘赌的算法(按评价指标来进行采样,评价指标越好被采样的概率越大);
- 交叉得到的新的“孩子”超参数组合也需要发生变异,交叉生成新的超参数组合之后,需要在新超参数组合上随机选择若干个超参数,随机修改超参数的值。这样能突破了当前搜索的限制,更有利于算法寻找到更优的解;
- 最后不断的迭代,优胜劣汰,交配繁衍,变异进化。